Недавно я немного рассказал об эволюции шаблонов микросервисов и о том, как прокси сервисов, такие как Envoy от Lyft, могут помочь снизить ответственность за отказоустойчивость, обнаружение сервисов, маршрутизацию, сбор метрик и т. Д. Ниже уровня приложения. В противном случае мы рискуем надеяться и молиться о том, чтобы различные приложения правильно реализовывали эти критические функции или зависели от конкретных языковых библиотек, чтобы это произошло. Интересно, что эта идея сервисной сетки связана с другими концепциями, о которых знают наши клиенты в корпоративном пространстве, и у меня появилось много вопросов об этих отношениях. В частности, как сетка сервиса связана с такими вещами, как ESB, Message Brokers и API Management? Эти концепции определенно совпадают, так что давайте углубимся . Не стесняйтесь следить за @christianposta в Твиттере, чтобы узнать больше об этой теме!
Четыре предположения
1) Сервисы общаются по сети
Первое, что нужно сделать: мы говорим об услугах, взаимодействующих и взаимодействующих друг с другом по асинхронным сетям с коммутацией пакетов. Это означает, что они работают в своих собственных процессах и в своих «временных границах» (отсюда и понятие асинхронности) и обмениваются данными, отправляя пакеты по сети. К сожалению, нет никаких гарантий об асинхронном сетевом взаимодействии : мы можем закончиться неудачными взаимодействиями, замедленными / скрытыми взаимодействиями и т. Д., И эти сценарии неотличимы друг от друга.
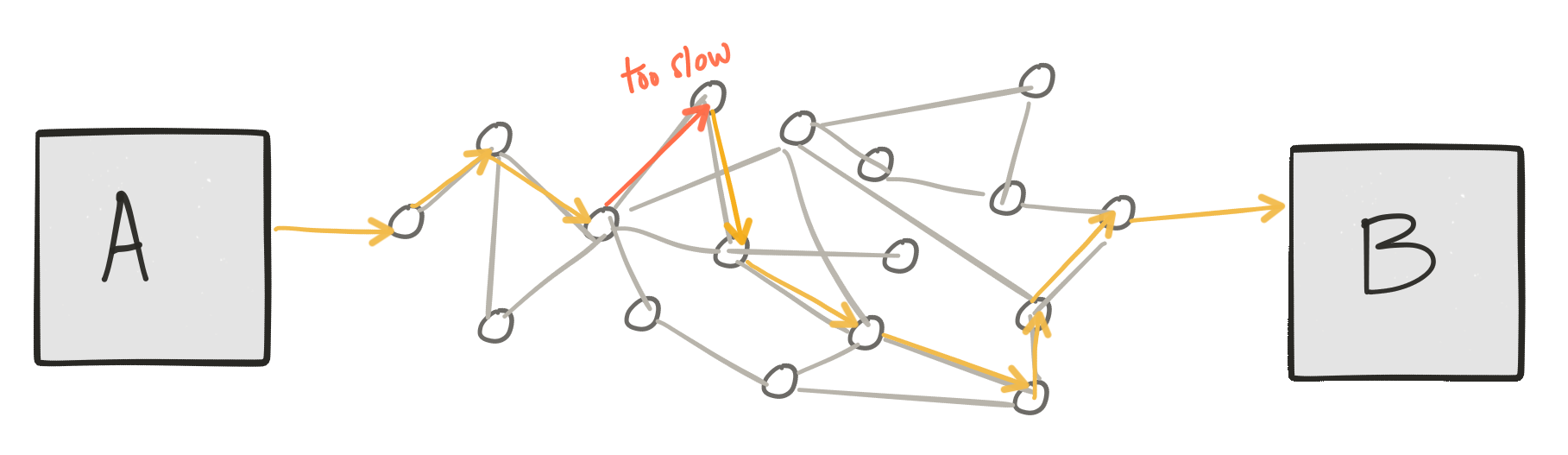
2) Если мы посмотрим внимательно, эти взаимодействия нетривиальны
Второе замечание: как эти сервисы взаимодействуют друг с другом, нетривиально; нам приходится иметь дело с такими вещами, как сбой / частичный успех, повторные попытки, обнаружение дубликатов, сериализация / десериализация, преобразование семантики / форматов, протоколы полиглотов, маршрутизация к нужному сервису для обработки наших сообщений, работа с потоком сообщений, оркестровка сервиса, безопасность последствия и т. д., и т. д. Многие вещи могут и не могут пойти не так.
3) Существует большое значение в понимании сети
Третье: очень важно понять, как приложения взаимодействуют друг с другом, как происходит обмен сообщениями и, возможно, способ контролировать этот трафик; эта точка очень похожа на то, как мы смотрим на сети уровня 3/4; очень важно понять, какие сегменты TCP и IP-пакеты проходят через наши сети, контролировать правила их маршрутизации, что разрешено и т. д.

4) Это в конечном итоге ответственность приложения
И наконец: как мы знаем сквозным аргументом , именно приложения ответственны за безопасность и правильную семантическую реализацию их предполагаемой бизнес-логики — независимо от того, какую надежность мы получаем от базовой инфраструктуры (повторные попытки, транзакции, обнаружение дубликатов и т. Д.) наши приложения должны по-прежнему защищаться от глупых действий пользователя (отправка заказа дважды) — все, что помогает в этом, — это детали реализации / оптимизации. К сожалению, обойти это невозможно.
Сетевые функции приложения
Я думаю, что независимо от того, какую архитектуру сервисов вы предпочитаете (микросервисы, SOA, брокеры запросов к объектам, клиент / сервер и т. Д. И т. Д.), Все эти пункты действительны — однако в прошлом мы размыли границы того, к чему относятся оптимизации. На мой взгляд, существуют горизонтальные сетевые функции приложений, которые являются хорошей игрой для оптимизации наших приложений (и помещаются в инфраструктуру — как мы делаем на более низких уровнях стека), а есть другие, которые более тесно связаны с нашим бизнесом. логика, которую не следует так легко «оптимизировать».
сеть
Давайте сделаем небольшой шаг назад и поймем, как выглядит сеть (на супер тривиальном и высоком уровне :)) под нашими приложениями. Когда мы отправляем «сообщение» из одного сервиса в другой, мы передаем его в сетевой стек нашей операционной системы, который затем выясняет, как поместить его в сеть. Сеть, в зависимости от того, какой уровень имеет дело с единицами передачи (кадры, дейтаграммы, пакеты) и т. Д. Эти блоки передачи обычно состоят из структуры, которая включает в себя «заголовок» и «полезную нагрузку» с «заголовком», содержащим достаточное количество метаданных о блок, который мы можем сделать базовые вещи, такие как маршрутизация, отслеживание AC / дедупликации и т. д.

Эти блоки передачи отправляются через разные точки в сети, которые решают, например, разрешать или нет пропускать блок, направлять ли его в другую сеть или доставлять его предполагаемому получателю. В любой точке пути эти блоки передачи могут быть отброшены, дублированы, переупорядочены или задержаны. У нас есть высокоуровневые функции «надежности», такие как TCP, которые существуют в сетевом стеке нашей ОС, которые могут отслеживать такие вещи, как дубликаты, подтверждения, тайм-ауты, упорядочение, потерянные блоки и т. Д., И могут повторять попытки при сбоях, переупорядочивать пакеты и так далее.
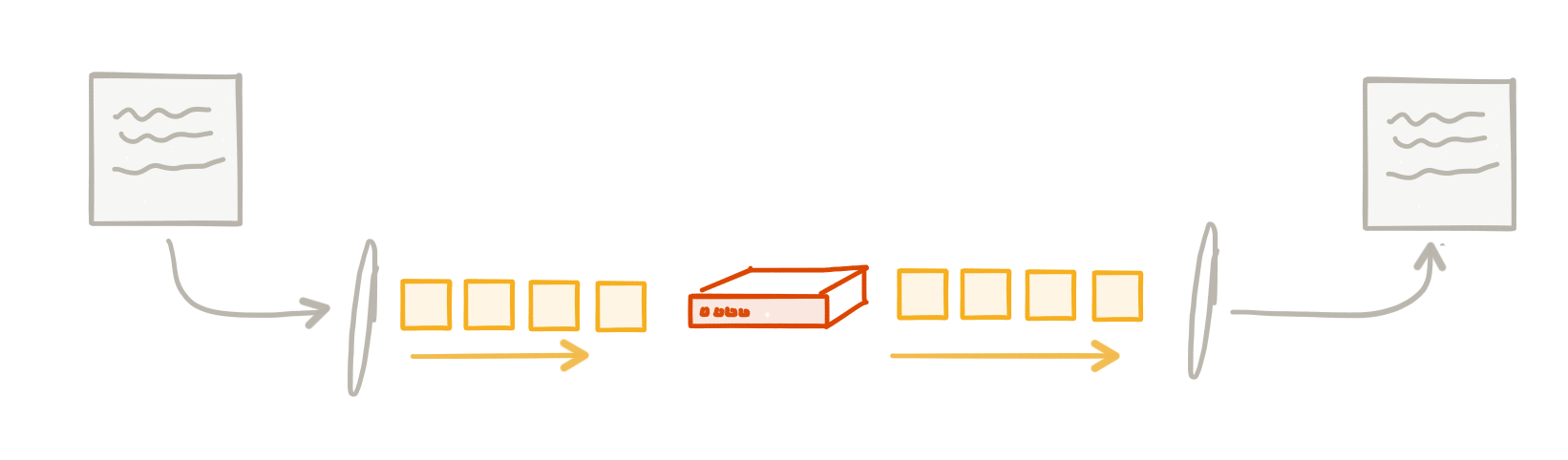
Эти типы функций обеспечиваются инфраструктурой и не смешиваются с бизнес-логикой — и это хорошо масштабируется (интернет-масштаб!) Я только что наткнулся на замечательный блог от Фила Калькадо, который также хорошо это объясняет .
заявка
На уровне приложений мы делаем нечто подобное. Мы разделяем разговоры с нашими сотрудниками на блоки передачи «сообщений» (запросов, событий и т. Д.). Когда мы делаем вызовы по сети, мы должны иметь возможность делать такие вещи, как тайм-аут, повтор, подтверждение, применение противодавления и т. Д. Для сообщений нашего приложения. Это универсальные проблемы на уровне приложений, и они всегда будут возникать при создании архитектур в стиле сервисов. Нам нужно как-то их решить. Нам нужен способ реализации сетевых функций приложения.

Например: в прошлом мы пытались решить эти проблемы с брокерами обмена сообщениями. У нас был централизованный набор промежуточного программного обеспечения, ориентированного на обмен сообщениями (возможно, даже с поддержкой нескольких протоколов, чтобы мы могли преобразовывать полезные нагрузки сообщений и «интегрировать» клиентов), которое отвечало за доставку сообщений между клиентами. Во многих примерах, которые я видел, в основном использовался запрос / ответ (RPC) через систему обмена сообщениями.
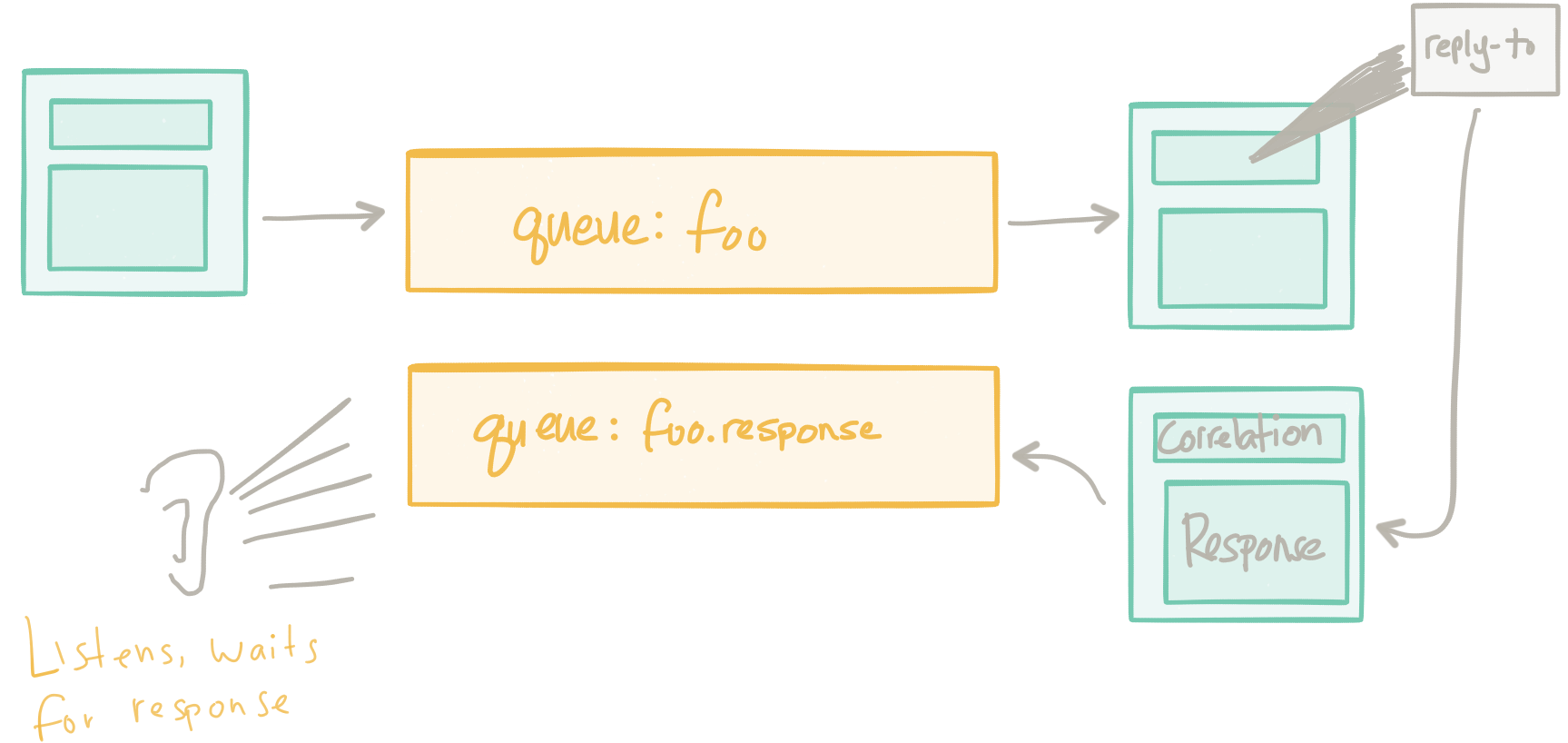
Это молчаливо помогло решить некоторые из этих проблем, связанных с функциональностью сети приложений: такие вещи, как балансировка нагрузки, обнаружение служб, обратное давление, повторные попытки и т. Д., Были делегированы посредникам обмена сообщениями. Поскольку весь трафик предназначался для прохождения через этих брокеров, у нас было центральное место для наблюдения и контроля сетевого трафика. Однако, как указывает @tef_ebooks в твиттере, такой подход довольно сложен. Это также имеет тенденцию быть большим узким местом в архитектуре и на самом деле было не так просто, как мы думали, когда речь шла об управлении трафиком, маршрутизации, применении политик и т. Д.
Поэтому мы тоже пытались это сделать. Мы подумали «ну, давайте просто добавим маршрутизацию, преобразование, управление политикой» к централизованной шине сообщений, которая у нас уже была. На самом деле это была естественная эволюция — мы могли бы использовать магистраль обмена сообщениями для обеспечения централизации / управления и функций сети приложений, таких как обнаружение служб, балансировка нагрузки, повторные попытки и т. Д., — но мы также поставили бы верх над такими вещами, как посредничество протоколов, преобразование сообщений маршрутизация сообщений, оркестровка и т. д. Мы чувствовали, что если бы мы могли протолкнуть эти, казалось бы, горизонтальные вещи в инфраструктуру, наши приложения могли бы быть более легкими / более гибкими / более гибкими и т. д. Эти проблемы были действительно реальными, и ESB развил их, чтобы помочь заполнить их.
Как отметил мой коллега Вольфрам Рихтер : «Что касается концепции ESB, то в официальном документе IBM от 2005 года, касающемся архитектуры SOA ( http://signallake.com/innovation/soaNov05.pdf, глава 2.3.1 ), ESB определяются следующим образом:»
|
01
02
03
04
05
06
07
08
09
10
|
The enterprise service bus (ESB) is a silent partner in the SOA logical architecture. Its presence in the architecture is transparent to the services of your SOA application. However, the presence of an ESB is fundamental to simplifying the task of invoking services – making the use of services wherever they are needed, independent of the details of locating those services and transporting service requests across the network to invoke those services wherever they reside within your enterprise. |
Выглядит вполне законно! Даже кажется, что некоторые из вещей, которые мы пытаемся сделать с новой технологией, которая появляется. И знаешь, что? Мы!!! Проблемы прошлых лет не просто волшебным образом исчезли , но изменились контекст и ландшафт. Мы надеемся, что сможем извлечь уроки из наших прошлых невыполненных обещаний.
Например, во времена SOA, как предполагали крупные поставщики (написание бесконечных спецификаций по спецификациям через комитет и т. Д., Ребрендинг EAI и т. Д.), Мы обнаружили три вещи, которые способствовали невыполненным обещаниям «ESB»:
- организационная структура (давайте построим еще один бункер!)
- технология была сложной (SOAP / WS- *, JBI, Canonical XML, собственные форматы и т. д.)
- бизнес-логика была необходима для реализации таких вещей, как маршрутизация, преобразование, посредничество, оркестровка и т. д.
Последний пункт — то, что перестаралось. Мы хотели быть гибкими, но мы разделили жизненно важную бизнес-логику от наших сервисов на уровень интеграции, принадлежащий другой команде. Теперь, когда мы хотели внести изменения (гибкие) в наши услуги, мы не смогли; нам пришлось остановиться и значительно синхронизироваться с командой ESB (хрупко). Поскольку эта команда и эта архитектура стали центром вселенной для многих приложений, мы можем понять, как команда ESB наполнилась запросами (гибкими), но не смогла идти в ногу (хрупкими). Таким образом, хотя намерения были хорошими, мы обнаружили, что смешивание основных сетевых функций приложений с функциями, которые в большей степени связаны с бизнес-логикой, не является хорошей идеей. Мы в конечном итоге с раздутием и узкими местами.

Затем произошла революция REST и первое мышление API. Это движение было частично отрицательной реакцией на сложность SOAP / ESB / SOA в сочетании с новым способом думать о том, как вывернуть наши данные наизнанку (через API), чтобы запустить новые бизнес-модели и масштабировать существующие. Мы также представили новую часть инфраструктуры в нашей архитектуре: шлюз управления API. Этот шлюз предоставил нам централизованный способ управления внешним доступом к нашим бизнес-API через ACL безопасности, квоты доступа и планы использования API, сбор метрик, выставление счетов, документирование и т. Д. Однако, как мы видели в предыдущих примерах с брокерами сообщений, когда у нас есть какое-то централизованное управление, мы рискуем достичь слишком многого с ним. Например, поскольку вызовы API проходят через наш шлюз, почему бы нам просто не добавить такие вещи, как маршрутизация, преобразование и оркестровка? Проблема в том, что мы начинаем идти по пути создания ESB, который сочетает в себе сетевые проблемы на уровне инфраструктуры с бизнес-логикой. И это тупик.

Но нам все же пришлось искать точки, перечисленные выше, между нашими сервисами даже для эпохи REST / non-SOAP (не только так называемый трафик «север-юг», но нам нужно было решать трафик «восток-запад»). взаимодействия). Еще сложнее, нам нужно было найти способ использования сред инфраструктуры товарной инфраструктуры (иначе говоря, облачных), которые имели тенденцию усугублять эти проблемы. Традиционные брокеры сообщений, ESB и т. Д. Не очень подходят для этой модели. Вместо этого мы закончили писать сетевые функции приложения в нашей бизнес-логике. … Мы начали видеть такие вещи, как стек Netflix OSS , Twitter Finagle и даже наш собственный Fuse Fabric, чтобы решить некоторые из этих проблем. Как правило, это были библиотеки или платформы, нацеленные на решение некоторых из упомянутых выше вопросов, но они были специфичны для конкретного языка и были включены в нашу бизнес-логику (или нашу бизнес-логику, распространенную по всей нашей инфраструктуре). Были проблемы и с этой моделью. Этот подход требовал огромных инвестиций в каждый язык / среду / среду выполнения. В основном нам приходилось дублировать усилия в разных языках / средах и ожидать, что все различные реализации будут работать эффективно, правильно и согласованно.
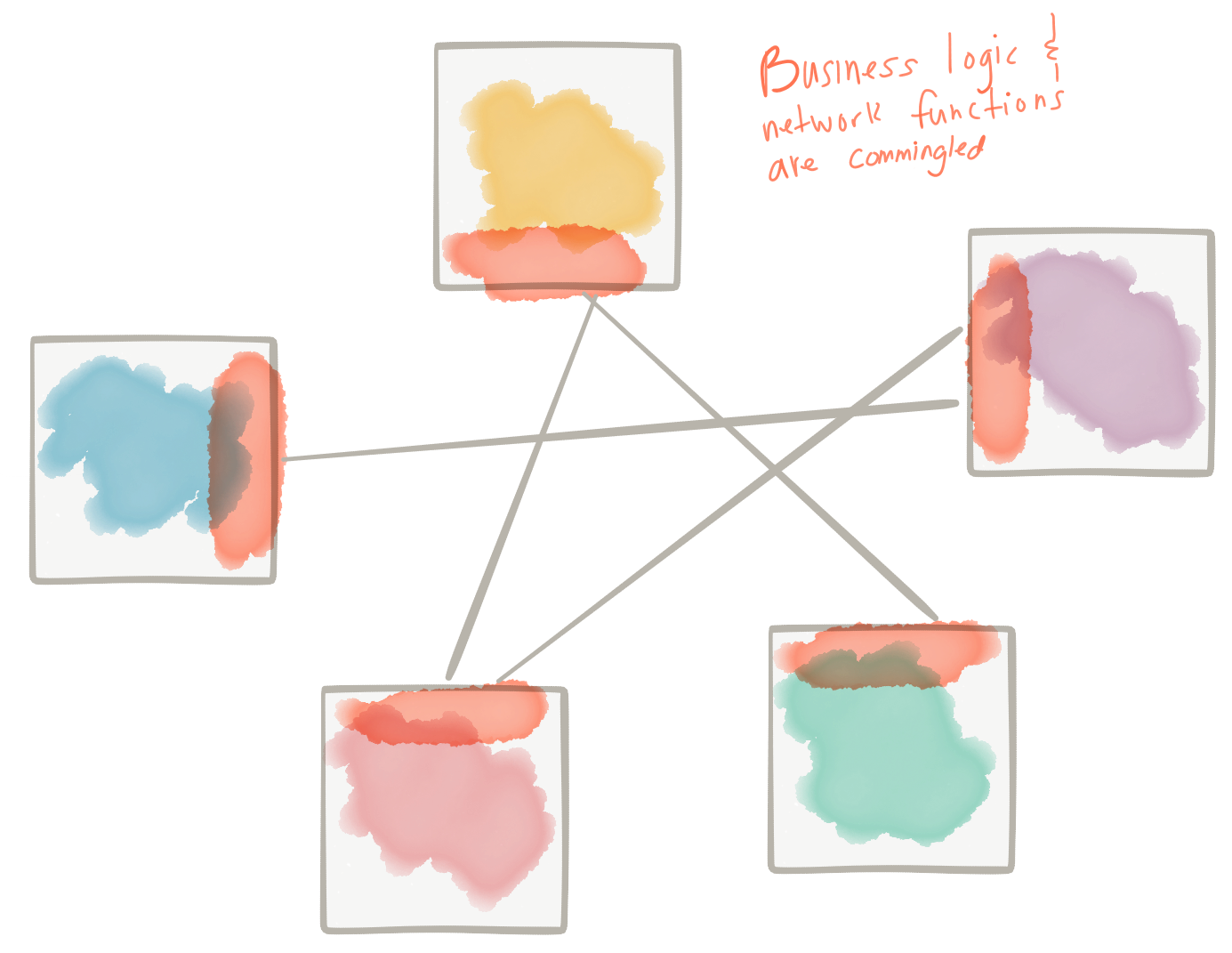
Благодаря этим испытаниям и испытаниям мы можем внедрить сетевые функции приложений в инфраструктуру с минимальными издержками и высокой децентрализацией с возможностью контроля / настройки / мониторинга запросов на уровне приложений, решая некоторые из предыдущих проблем. Мы называем это «сервисной сеткой». Хорошим примером этого является проект istio.io, основанный на Envoy Proxy . Это позволяет нам архитектурно отделить задачи сетевых функций приложений от тех, которые направлены на разграничение бизнес-логики:
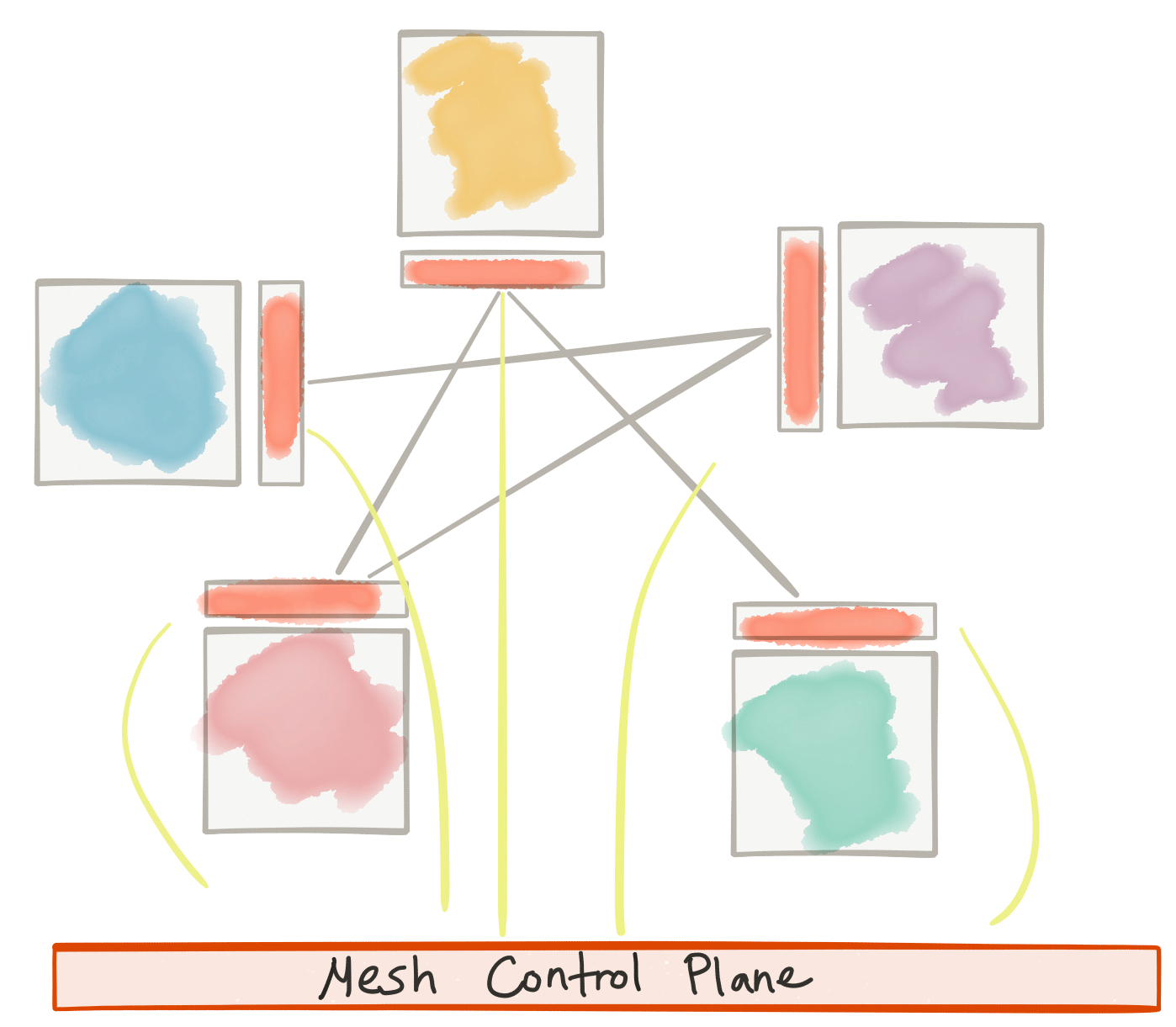
Как объясняет Фил Калькадо , это очень похоже на то, что мы делаем с сетевым уровнем TCP / IP; сетевые функции выталкиваются в операционную систему и не являются непосредственно частью приложения.
Так как это связано с …
С помощью сервисной сетки мы явно отделяем сетевые функции приложения от кода приложения, от бизнес-логики и продвигаем его на уровень (в инфраструктуру — аналогично тому, как мы это делали с сетевым стеком, TCP и т. Д.). .).
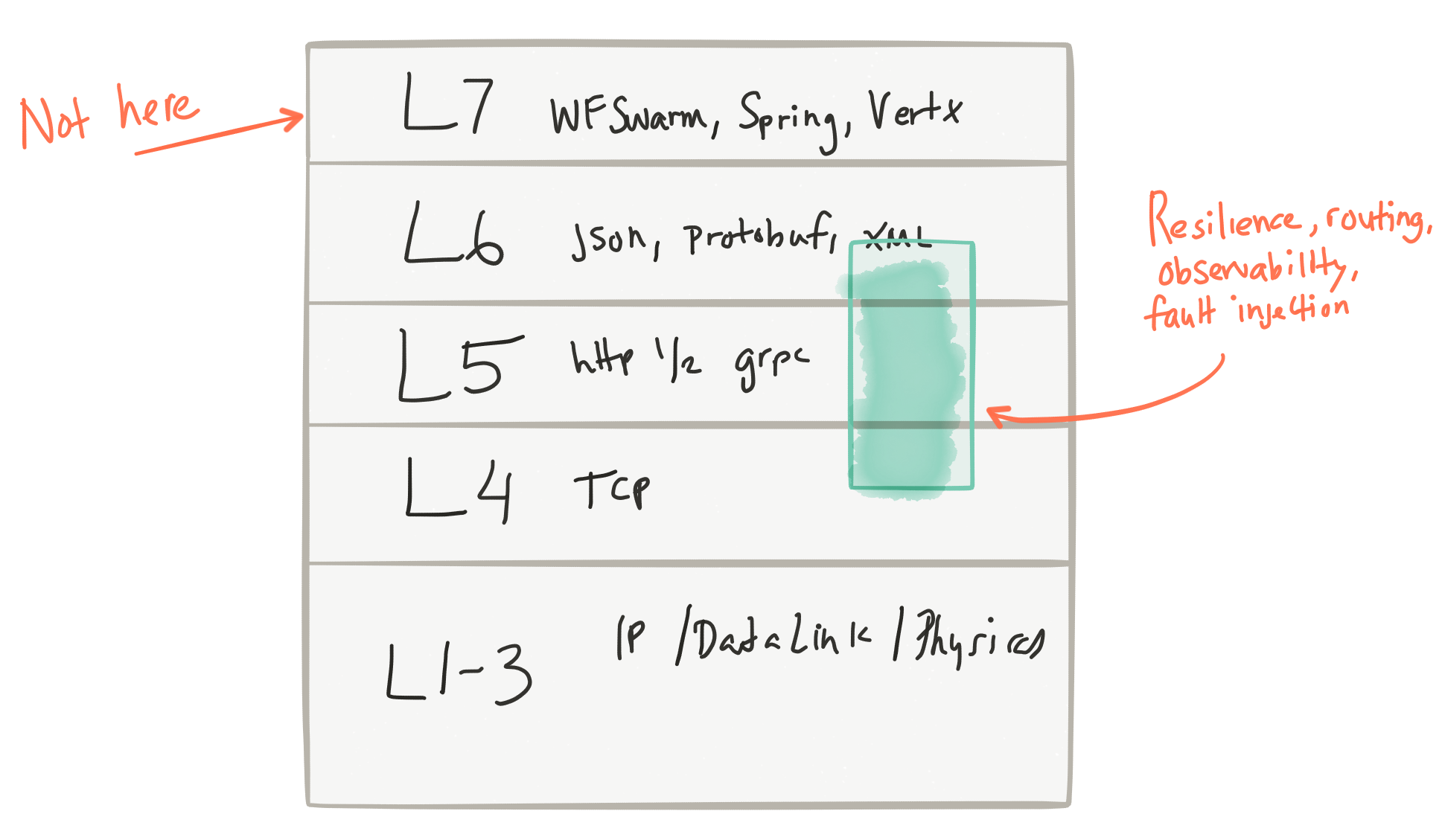
Рассматриваемые функции сети включают в себя:
- простая маршрутизация на основе метаданных
- адаптивное / клиентское распределение нагрузки
- обнаружение службы
- разрыв цепи
- таймауты / попытки / бюджеты
- ограничение скорости
- Метрики / регистрация / трассировка
- инъекция неисправности
- A / B тестирование / формирование трафика / дублирование запросов
Вещи, которые специально НЕ включены (и более уместны в вашей бизнес-логике / приложениях / сервисах, а не в некоторой централизованной инфраструктуре):
- преобразование сообщения
- маршрутизация сообщений (маршрутизация на основе контента)
- сервисная оркестровка
Так чем же отличается сервисная сетка от …
ESBS
- Перекрытие в некоторых сетевых функциях
- Децентрализованные контрольные точки
- Политики для приложений
- Не пытается решать проблемы бизнес-логики (отображение, преобразование, маршрутизация на основе содержимого и т. Д.)
Брокеры сообщений
- Перекрытие (с уровня 30 000 футов) при обнаружении службы, балансировке нагрузки, повторных попытках, противодавлении
- Децентрализованные контрольные точки
- Политики для приложений
- Не несет ответственности за сообщения
Управление API
- Перекрываются в некоторых аспектах контроля политики, ограничения скорости, ACL, квоты безопасности
- Не имеет отношения к бизнес-аспектам API (ценообразование, документация, сопоставление пользователей и планов и т. Д.)
- Похоже в том, что не реализует бизнес-логику
Что касается управления API, то здесь есть некоторые совпадения, но мне нравится думать, что эти вещи дополняют друг друга. Управление API обеспечивает семантику более высокого порядка об API (например, документация, регистрация / доступ пользователей, управление жизненным циклом, планы API для разработчиков, учет выставления счетов и возвратных платежей и т. Д.). Сети приложений более низкого уровня, такие как автоматические выключатели, тайм-ауты, повторные попытки и т. Д., Имеют решающее значение при вызове API, но они хорошо вписываются в слой сервисной сетки. Точки перекрытия, такие как ACL, ограничение скорости, квоты, применение политик и т. Д., Могут быть определены уровнем управления API, но фактически обеспечены уровнем сервисной сетки. Таким образом, мы можем иметь полную сквозную политику и контроль доступа, а также обеспечить устойчивость для трафика Север / Юг и трафика Восток / Запад. Как @ZackButcher (из команды Istio) в твиттере отметил: «По мере того, как вы становитесь больше, трафик восток-запад начинает больше походить на север-юг с точки зрения создания и управления вашим сервисом».

Собираем все вместе
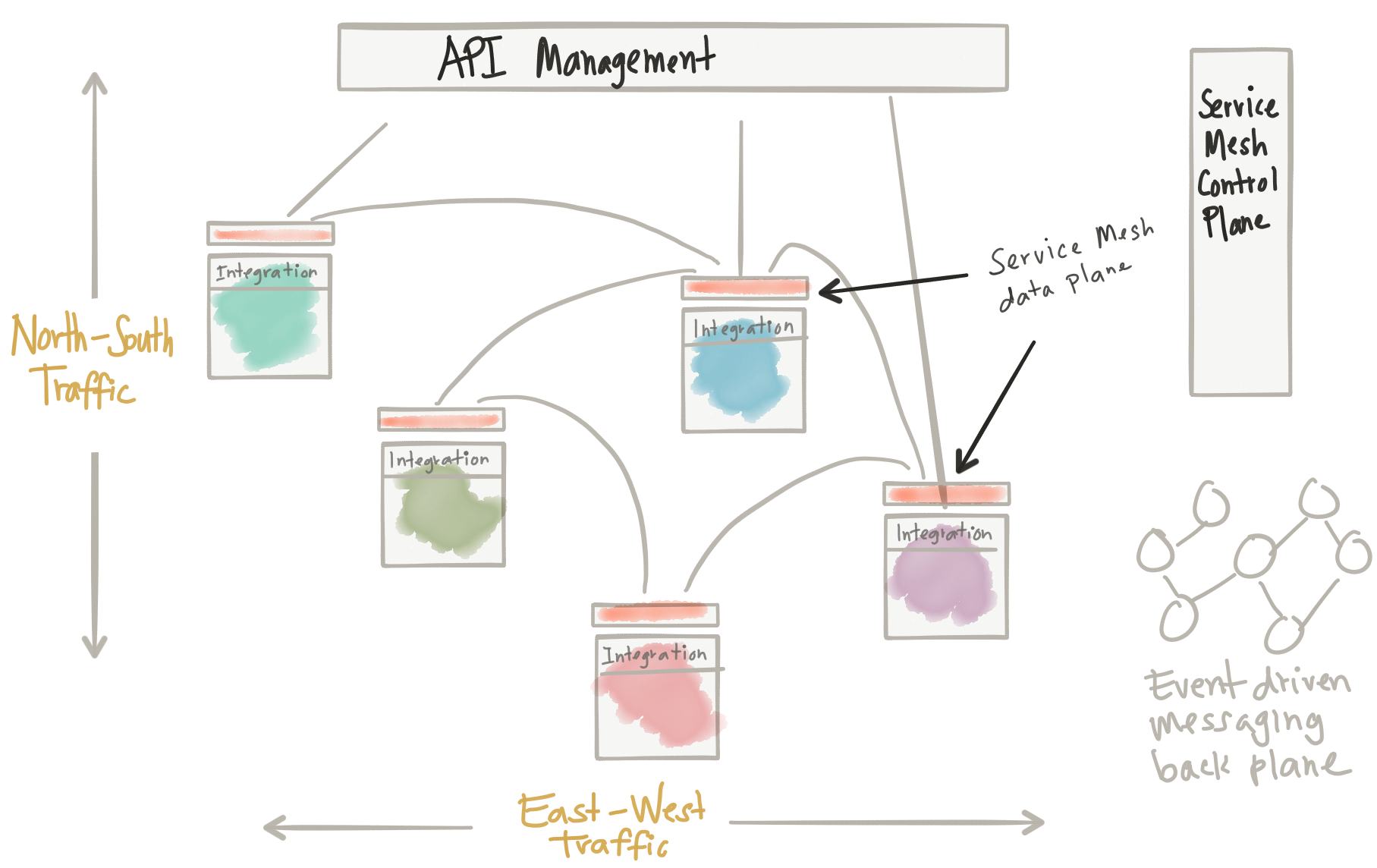
Нажмите, чтобы увидеть полное изображение
{kind=link}
Мы должны использовать API-ориентированный подход к архитектуре наших систем. Мы также должны решить для таких вещей, как устойчивость. Мы также обнаруживаем, что у нас есть проблемы интеграции. И во многих отношениях архитектура, построенная на асинхронной передаче событий и обработке событий в качестве объединительной панели для ваших API и взаимодействий микросервисов, может помочь повысить доступность, отказоустойчивость и уменьшить уязвимость. В прошлом решение этих проблем было непростым делом, поскольку конкурирующие продукты и решения накладывались друг на друга и связывали друг с другом проблемы — когда мы переходим к облачным архитектурам, становится очевидным, что нам нужно разделить эти проблемы и поставить их в правильные места в нашей архитектуре, в противном случае мы ». Я поддамся тем же извлеченным урокам.
Из диаграммы выше мы видим несколько вещей:
- Управление API для входа на север / юг
- Сетка обслуживания (управление + плоскость данных) для функций сети приложений между службами
- В Service Mesh применяются политики управления API для трафика восток / запад
- Интеграция (оркестровка, трансформация, антикоррупционные уровни) как часть приложений
- Управляемая событиями обратная плоскость для действительно асинхронных / управляемых событиями взаимодействий
Если мы вернемся к четырем предположениям, которые я сделал заранее, вот как мы будем их решать:
- Точка первая: сервисы взаимодействуют по сети — мы используем плоскость данных сервисной сетки / сервисные прокси
- Второй момент: взаимодействия нетривиальны — реализуйте бизнес-интеграцию в самих сервисах
- Третий пункт: контроль и наблюдаемость — используйте API Management + Service Mesh Control plane
- Пункт четвертый: ваша конкретная бизнес-логика; использовать сервисную сетку / обмен сообщениями / и т.д. для оптимизации
Вы действительно можете выделить бизнес-логику?
Я думаю да. Однако будут размытые линии. В сервисной сетке мы говорим, что наше приложение должно знать о сетевых функциях приложения, но они не должны быть реализованы в коде приложения. Есть кое-что, что можно сказать о том, как сделать приложение умнее, о том, что именно делает сетевая функция / слой службы приложения. Я думаю, что мы увидим библиотеки / фреймворки, создающие в этом контексте. Например, если сервисная сетка Istio вызывает прерыватель цепи, повторяет некоторые запросы или дает сбой по определенной причине, было бы хорошо, чтобы приложение получило больше понимания или контекста об этих сценариях. Нам понадобится способ перехватить это и сообщить об этом сервису. Другой пример — распространение контекста трассировки (распределенная трассировка, например OpenTracing) между сервисами, и это делается прозрачно. То, что мы можем видеть, — это тонкие библиотеки, специфичные для приложений / языков, которые могут сделать приложение / сервисы более интеллектуальными и позволить им обращаться за ошибками.
Куда мы отправимся отсюда
Каждая часть этой архитектуры находится на разных уровнях зрелости сегодня. Тем не менее, принципиальный подход к архитектуре наших сервисов является ключевым. Отделите бизнес-логику от сети приложений. Используйте сетку сервисов для реализации сетевого взаимодействия приложений, уровень управления API для решения проблем, связанных с API более высокого порядка, специфическую для бизнеса интеграцию на уровне сервисов, и мы можем создавать системы с интенсивным использованием данных / доступные через объединительную плату, управляемую событиями. Я думаю, что по мере продвижения вперед мы продолжим наблюдать, как эти принципы будут реализовываться в конкретных реализациях технологий. В Red Hat (где я работаю) мы видим такие технологии, как 3Scale , Istio.io для Kubernetes , Apache Camel , и технологии обмена сообщениями, такие как ActiveMQ Artemis / Apache Qpid Dispatch Router (включая технологии, не относящиеся к Red Hat, такие как Apache Kafka IMHO), в качестве сильных строительных блоков для Построить архитектуру своих сервисов, которая придерживается этих принципов.
| Ссылка: | Сетевые функции приложения с ESB, управлением API и сейчас .. Сетка обслуживания? от нашего партнера JCG Кристиана Поста в блоге |