В предыдущей статье мы создали простой код индексации, который забивает ElasticSearch тысячами одновременных запросов. Единственный способ контролировать производительность нашей системы — это протоколирование старой школы:
|
1
2
3
|
.window(Duration.ofSeconds(1)).flatMap(Flux::count).subscribe(winSize -> log.debug("Got {} responses in last second", winSize)); |
Это хорошо, но в производственной системе мы бы предпочли централизованное решение для мониторинга и составления диаграмм для сбора различных метрик. Это становится особенно важным, когда у вас есть сотни различных приложений в тысячах экземпляров. Наличие единой графической панели, объединяющей всю важную информацию, становится критически важным. Нам нужны два компонента, чтобы собрать некоторые метрики:
- метрики публикации
- собирая и визуализируя их
Публикация метрик с использованием Dropwizard Metrics
В Spring Boot 2 метрики Dropwizard были заменены микрометром . В этой статье используется первое, в следующем будет показано последнее решение на практике. Чтобы воспользоваться преимуществами Метрик Dropwizard, мы должны внедрить MetricRegistry или конкретные метрики в наши бизнес-классы.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
import com.codahale.metrics.Counter;import com.codahale.metrics.MetricRegistry;import com.codahale.metrics.Timer;import lombok.RequiredArgsConstructor;import lombok.extern.slf4j.Slf4j; @Component@RequiredArgsConstructorclass Indexer { private final PersonGenerator personGenerator; private final RestHighLevelClient client; private final Timer indexTimer; private final Counter indexConcurrent; private final Counter successes; private final Counter failures; public Indexer(PersonGenerator personGenerator, RestHighLevelClient client, MetricRegistry metricRegistry) { this.personGenerator = personGenerator; this.client = client; this.indexTimer = metricRegistry.timer(name("es", "index")); this.indexConcurrent = metricRegistry.counter(name("es", "concurrent")); this.successes = metricRegistry.counter(name("es", "successes")); this.failures = metricRegistry.counter(name("es", "failures")); } private Flux<IndexResponse> index(int count, int concurrency) { //.... } } |
Столько шаблонов, чтобы добавить некоторые метрики!
-
indexTimerизмеряет распределение времени (среднее значение, медиана и различные процентили) запросов на индексирование -
indexConcurrentизмеряет, сколько запросов в данный моментindexConcurrent(запросов отправлено, ответа пока нет); метрика идет вверх и вниз со временем -
successиfailuresподсчитывает общее количество успешных и неудачных запросов на индексирование соответственно
Мы избавимся от шаблона через секунду, но сначала давайте посмотрим, как он работает в нашем бизнес-коде:
|
1
2
3
4
5
6
7
|
private Mono<IndexResponse> indexDocSwallowErrors(Doc doc) { return indexDoc(doc) .doOnSuccess(response -> successes.inc()) .doOnError(e -> log.error("Unable to index {}", doc, e)) .doOnError(e -> failures.inc()) .onErrorResume(e -> Mono.empty());} |
Приведенный выше вспомогательный метод увеличивает число успехов и неудач при каждом завершении запроса. Кроме того, он регистрирует и поглощает ошибки, так что одна ошибка или тайм-аут не прерывает весь процесс импорта.
|
1
2
3
4
5
|
private <T> Mono<T> countConcurrent(Mono<T> input) { return input .doOnSubscribe(s -> indexConcurrent.inc()) .doOnTerminate(indexConcurrent::dec);} |
Другой приведенный выше метод увеличивает показатель indexConcurrent при indexConcurrent нового запроса и уменьшает его при появлении результата или ошибки. Этот показатель продолжает расти и уменьшаться, показывая количество запросов в полете.
|
1
2
3
4
5
6
7
|
private <T> Mono<T> measure(Mono<T> input) { return Mono .fromCallable(indexTimer::time) .flatMap(time -> input.doOnSuccess(x -> time.stop()) );} |
Последний вспомогательный метод является наиболее сложным. Он измеряет общее время индексации, то есть время между отправляемым запросом и полученным ответом. На самом деле, он довольно общий, он просто вычисляет общее время между подпиской на произвольный Mono<T> и завершением. Почему это выглядит так странно? Ну, основной API Timer очень прост
|
1
|
indexTimer.time(() -> someSlowCode()) |
Он просто принимает лямбда-выражение и измеряет, сколько времени понадобилось, чтобы вызвать его. В качестве альтернативы вы можете создать небольшой объект Timer.Context который запоминает, когда он был создан. Когда вы вызываете Context.stop() он сообщает об этом измерении:
|
1
2
3
|
final Timer.Context time = indexTimer.time();someSlowCode();time.stop(); |
С асинхронными потоками это намного сложнее. Начало задачи (обозначается подпиской) и ее завершение обычно происходит через границы потоков в разных местах кода. Что мы можем сделать — это создать (лениво) новый объект Context (см .: fromCallable(indexTimer::time) ), и когда завернутый поток завершится, завершить Context (см .: input.doOnSuccess(x -> time.stop() ). Вот как вы составляете все эти методы:
|
1
2
3
4
5
|
personGenerator .infinite() .take(count) .flatMap(doc -> countConcurrent(measure(indexDocSwallowErrors(doc))), concurrency); |
Это так, но загрязнение бизнес-кода столькими низкоуровневыми деталями сбора метрик кажется странным. Давайте обернем эти метрики специализированным компонентом:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
@RequiredArgsConstructorclass EsMetrics { private final Timer indexTimer; private final Counter indexConcurrent; private final Counter successes; private final Counter failures; void success() { successes.inc(); } void failure() { failures.inc(); } void concurrentStart() { indexConcurrent.inc(); } void concurrentStop() { indexConcurrent.dec(); } Timer.Context startTimer() { return indexTimer.time(); } } |
Теперь мы можем использовать немного более высокоуровневую абстракцию:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
class Indexer { private final EsMetrics esMetrics; private <T> Mono<T> countConcurrent(Mono<T> input) { return input .doOnSubscribe(s -> esMetrics.concurrentStart()) .doOnTerminate(esMetrics::concurrentStop); } //... private Mono<IndexResponse> indexDocSwallowErrors(Doc doc) { return indexDoc(doc) .doOnSuccess(response -> esMetrics.success()) .doOnError(e -> log.error("Unable to index {}", doc, e)) .doOnError(e -> esMetrics.failure()) .onErrorResume(e -> Mono.empty()); }} |
В следующей статье мы научимся составлять все эти методы еще лучше. И избегайте шаблонов.
Публикация и визуализация метрик
Собирать метрики самостоятельно недостаточно. Мы должны периодически публиковать агрегированные показатели, чтобы другие системы могли их использовать, обрабатывать и визуализировать. Одним из таких инструментов является графит и графана . Но прежде чем мы углубимся в их настройку, давайте сначала опубликуем метрики на консоли. Я считаю это особенно полезным при устранении неполадок в метриках или в процессе разработки.
|
1
2
3
4
5
6
7
8
9
|
import com.codahale.metrics.MetricRegistry;import com.codahale.metrics.Slf4jReporter; @BeanSlf4jReporter slf4jReporter(MetricRegistry metricRegistry) { final Slf4jReporter slf4jReporter = Slf4jReporter.forRegistry(metricRegistry.build(); slf4jReporter.start(1, TimeUnit.SECONDS); return slf4jReporter;} |
Этот простой фрагмент кода берет существующую MetricRegistry и регистрирует Slf4jReporter . Каждую секунду вы будете видеть все показатели, напечатанные в ваших журналах (Logback и т. Д.):
|
1
2
3
4
5
6
|
type=COUNTER, name=es.concurrent, count=1type=COUNTER, name=es.failures, count=0type=COUNTER, name=es.successes, count=1653type=TIMER, name=es.index, count=1653, min=1.104664, max=345.139385, mean=2.2166538118720576, stddev=11.208345077801448, median=1.455504, p75=1.660252, p95=2.7456, p98=5.625456, p99=9.69689, p999=85.062713, mean_rate=408.56403102372764, m1=0.0, m5=0.0, m15=0.0, rate_unit=events/second, duration_unit=milliseconds |
Но это просто или устранение неполадок, чтобы опубликовать наши показатели во внешнем экземпляре Graphite, нам нужен GraphiteReporter :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
import com.codahale.metrics.MetricRegistry;import com.codahale.metrics.graphite.Graphite;import com.codahale.metrics.graphite.GraphiteReporter; @BeanGraphiteReporter graphiteReporter(MetricRegistry metricRegistry) { final Graphite graphite = new Graphite(new InetSocketAddress("localhost", 2003)); final GraphiteReporter reporter = GraphiteReporter.forRegistry(metricRegistry) .prefixedWith("elastic-flux") .convertRatesTo(TimeUnit.SECONDS) .convertDurationsTo(TimeUnit.MILLISECONDS) .build(graphite); reporter.start(1, TimeUnit.SECONDS); return reporter;} |
Здесь я сообщаю localhost:2003 где мой образ Docker с Graphite + Grafana оказался. Раз в секунду все метрики отправляются на этот адрес. Позже мы можем визуализировать все эти показатели на Графане:
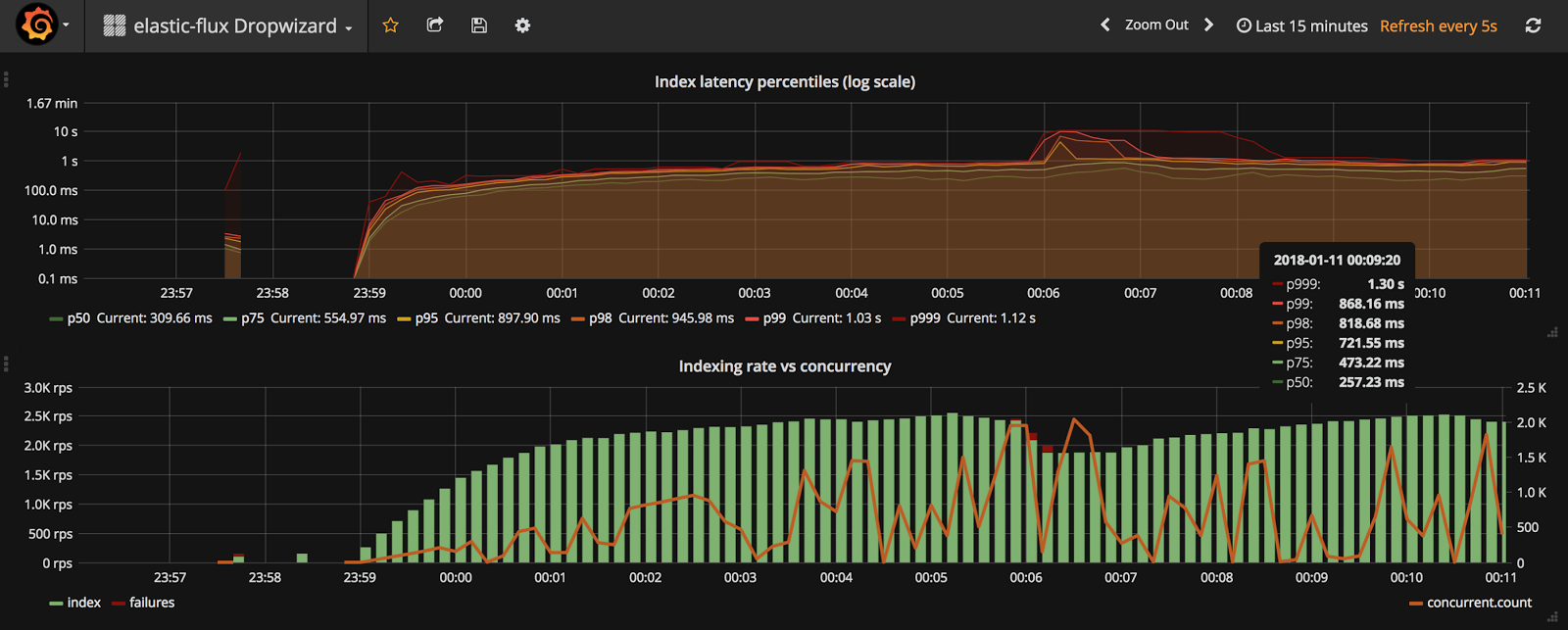
На верхней диаграмме показано распределение времени индексации (от 50-го до 99,9-го процентиля). Используя эту диаграмму, вы можете быстро узнать, какова типичная производительность (P50), а также (почти) производительность в худшем случае (P99.9). Логарифмическая шкала необычна, но в этом случае позволяет нам видеть как низкий, так и высокий процентили. Нижняя диаграмма еще интереснее. Он объединяет три метрики:
- скорость (количество запросов в секунду) успешных операций с индексами
- частота неудачных операций (красная полоса, сложенная поверх зеленой)
- текущий уровень параллелизма (правая ось): номер запроса в полете
Эта диаграмма показывает пропускную способность системы (RPS), сбои и параллелизм. Слишком много сбоев или необычно высокий уровень параллелизма (многие операции ожидают ответа) могут быть признаком некоторых проблем в вашей системе. Определение панели доступно в репозитории GitHub.
В следующей статье мы узнаем, как перейти с метрик Dropwizard на микрометр. Очень приятный опыт!
| Опубликовано на Java Code Geeks с разрешения Томаша Нуркевича, партнера нашей программы JCG. Смотрите оригинальную статью здесь: Мониторинг и измерение реактивного приложения с помощью Dropwizard Metrics
Мнения, высказанные участниками Java Code Geeks, являются их собственными. |