В первой части (часть I) мы представили стратегию по внедрению микросервисов в нашу архитектуру без нарушения текущих потоков запросов и ценности для бизнеса, рассмотрев конкретный пример. Во второй части мы начали изучать сопутствующие технологии, которые соответствуют нашей архитектурной стратегии и целям. В этой третьей части мы продолжим решение из части II, сосредоточившись на том, что делать с добавлением нового сервиса, который может потребоваться для обмена данными с монолитом (по крайней мере на начальном этапе) и в некоторых более сложных сценариях развертывания. Мы также исследуем тестирование потребительских контрактов с Arquillian Algeron и узнаем, как мы можем его использовать, чтобы справиться с изменениями API в нашей архитектуре сервисов.
Следите за новостями ( @christianposta ) в твиттере или на сайте http://blog.christianposta.com, чтобы получать последние обновления и обсуждения.
Вы можете найти Часть I и Часть II .
технологии
Технологии, которые мы будем использовать (в части II, III и IV), чтобы помочь нам в этом путешествии:
- Фреймворки для разработчиков ( Spring Boot , WildFly , WildFly Swarm )
- Дизайн API ( APICur.io )
- Каркасы данных ( Spring Boot Teiid , Debezium.io )
- Инструменты интеграции ( Apache Camel )
- Сетка сервисная ( Istio Service Mesh )
- Инструменты миграции баз данных ( Liquibase )
- Темный запуск / фреймворк с признаками ( FF4J )
- Платформа развертывания / CI-CD ( Kubernetes / OpenShift )
- Инструменты разработчика Kubernetes ( Fabric8.io )
- Инструменты тестирования ( Arquillian , Pact / Arquillian Algeron , Hoverfly , тест Spring-Boot , RestAssured , Arquillian Cube )
Если вы хотите продолжить, пример проекта, который я использую, основан на руководстве TicketMonster на http://developers.redhat.com, но был изменен, чтобы показать эволюцию от монолита к микросервису. Вы можете найти код и документацию (документы еще в разработке!) Здесь, на github: https://github.com/ticket-monster-msa/monolith
Во второй части мы остановились на пути добавления нового микросервиса (Заказы / Бронирование), который будет отделен от нашего монолита. Мы начали этот шаг с изучения соответствующего API, имитируя его с помощью Hoverfly.
Соедините API с реализацией 
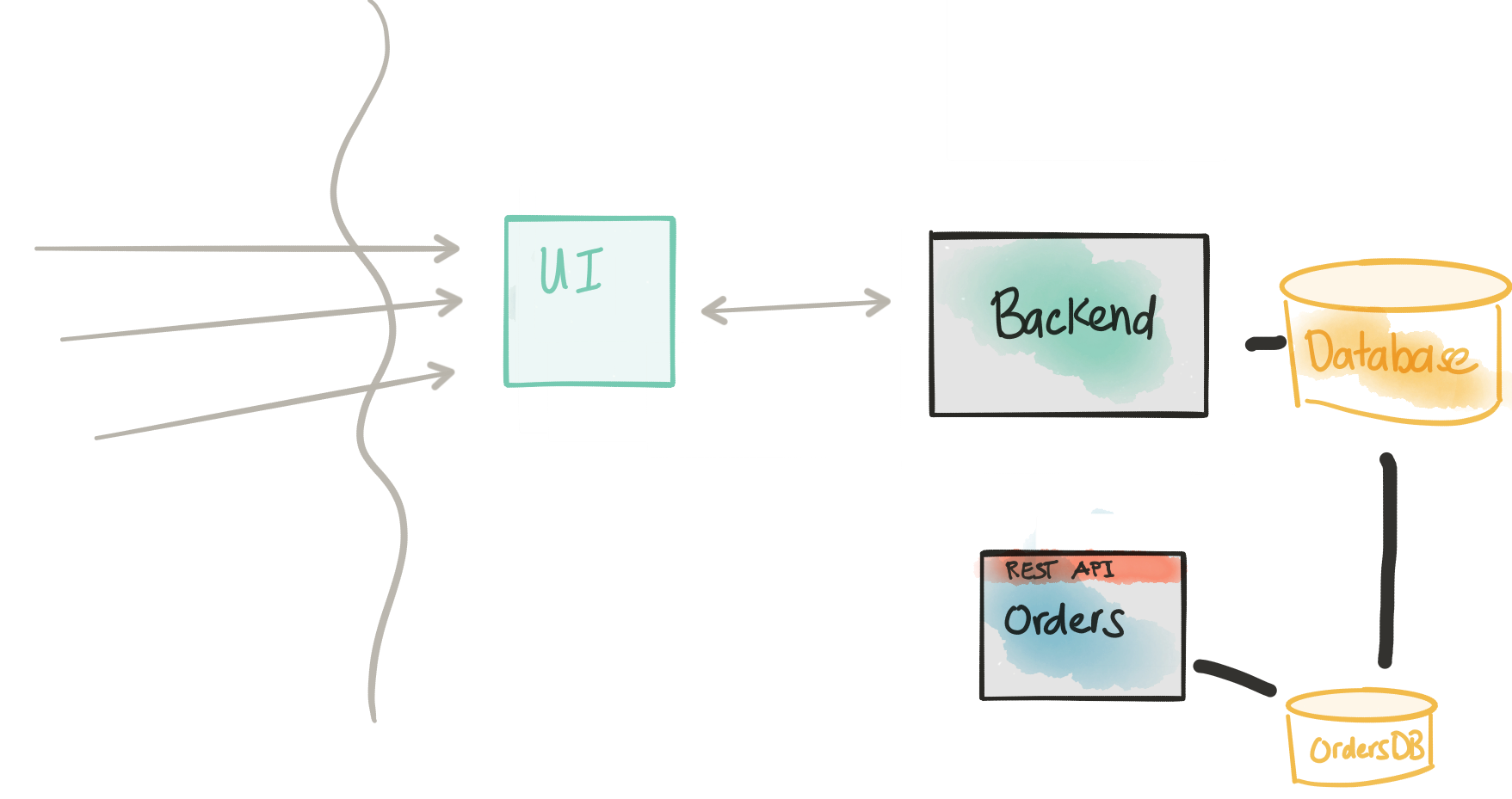
Пересмотреть соображения
- Извлеченный / новый сервис имеет модель данных, которая по определению тесно связана с моделью данных монолита
- Монолит, скорее всего, не предоставляет API на нужном уровне для получения этих данных.
- Формирование данных, даже если мы их получим, требует большого количества кода котельной плиты
- Мы можем напрямую подключиться к внутренней базе данных для запросов только для чтения
- Монолит редко (если вообще) меняет свою базу данных
В части I мы намекали на решение, включающее подключение прямо к базе данных монолита. В нашем примере нам нужно сделать это, потому что данные в этой базе данных изначально будут исходными, являющимися жизненной силой нашей новой службы Orders которую мы пытаемся разложить из монолита. Кроме того, мы хотим представить этот новый сервис, позволить ему принимать нагрузку и иметь общее представление о том, что находится в монолите; то есть, мы будем работать оба одновременно в течение некоторого периода времени. Обратите внимание, что это маневрирование наносит удар прямо в сердце нашего разложения: мы не можем просто волшебным образом начать вызывать новый микросервис, который должным образом инкапсулирует всю логику бронирования / заказа, не влияя на текущую нагрузку.
Какие у нас есть альтернативы, если мы не хотим подключаться к монолитной базе данных? Я могу подумать о нескольких… не стесняйтесь комментировать или твитнуть мне, если вы хотите высказать другие предложения:
- Использовать существующий API, предоставляемый монолитом
- Создать новый API специально для доступа к базе данных монолита; называть это в любое время нам нужны данные
- Проведите ETL из монолита в наш новый сервис, чтобы у нас уже были данные
Используя существующий API
Если вы можете сделать это, обязательно изучите это. Однако зачастую существующие API-интерфейсы достаточно грубые, не предназначены для использования на низком уровне и могут нуждаться в большом массиве данных, чтобы получить желаемую модель данных, которую вы хотели бы использовать в своем новом сервисе. Для каждого входящего вызова ваш новый сервис, в этом примере сервис Orders , вам нужно будет запросить (возможно, несколько конечных точек) устаревший / монолитный API и спроектировать ответ по своему вкусу. В этом нет ничего плохого, если только вы не начнете делать короткие пути, которые позволят вашей монолитной / унаследованной API / модели данных сильно повлиять на модель данных вашего нового сервиса. Несмотря на то, что, по крайней мере, в моем примере, модель данных поначалу может быть похожей, мы хотим быстро выполнить итерацию (используя DDD) и получить правильную модель предметной области, а не просто нормализованную модель данных.
Создать новый API нижнего уровня
Если существующий API-интерфейс монолита слишком груб (или вообще не существует), или вы не хотите поощрять его повторное использование, вы можете вместо этого создать собственный API-интерфейс более низкого уровня, который напрямую подключается к базе данных монолита и предоставлять данные на уровне, который может понадобиться новой службе Orders . Это также может быть приемлемым решением. С другой стороны, я столкнулся с тем, что новая служба Orders заканчивает тем, что записывает множество запросов / вызовов API в этот новый интерфейс более низкого уровня и выполняет соединения в памяти для ответов (аналогично предыдущему параметру). Может также возникнуть ощущение, что мы реализуем базу данных. Опять же, в этом нет ничего плохого, но это оставляет много кода для написания сервисной службы Orders — большая его часть используется как временное, временное решение.
Сделайте ETL из монолита в наш новый сервис
В какой-то момент нам действительно может понадобиться это сделать. Однако в тот момент, когда мы работаем над доменной моделью нового сервиса, мы можем не захотеть иметь дело со старой монолитной структурой. Кроме того, мы намерены запускать новые сервисы одновременно с монолитом; мы ожидаем, что оба могут принять трафик. Если мы используем подход ETL, нам понадобится способ поддерживать сервис Orders в актуальном состоянии, поскольку все может быстро выйти из синхронизации. Это становится кошмаром.
Как разработчик новой службы Orders , мы хотим думать с точки зрения модели предметной области (примечание: я не говорил модель данных — есть разница), которая имеет смысл для нашего сервиса. Мы хотим по возможности исключить влияние внешних реализаций, которые могут поставить под угрозу нашу модель предметной области. Различие: модель данных показывает, как фрагменты (статических) данных в нашей системе связаны друг с другом, возможно, давая руководство для того, как вещи хранятся в слое постоянства. Доменные модели используются для описания поведения пространства решений нашего домена и имеют тенденцию больше фокусироваться на поведении сценариев использования / транзакций; то есть понятия или модели, которые мы используем, чтобы сообщить, в чем проблема. У гуру DDD Вона Вернона есть большая серия эссе, которые более подробно раскрывают это различие .
Решение, которое я использовал в службе заказов для службы заказов Ticket Monster, заключается в использовании проекта с открытым исходным кодом под названием Teiid, который помогает сократить / исключить основную модель моделирования данных в нашей идеальной модели предметной области. Teiid традиционно является программным обеспечением для объединения данных, способным принимать разнородные источники данных (реляционные БД, NoSQL, плоские файлы и т. Д.) И представлять их как единое виртуализированное представление. Обычно это используется специалистами по анализу данных для объединения данных в целях составления отчетов и т. Д., Но нас больше интересует, как разработчики могут использовать их для решения вышеуказанной проблемы. К счастью, люди из сообщества Teiid, особенно Рамеш Редди , создали несколько хороших расширений для Teiid и Spring Boot, чтобы помочь устранить плиту котла, которая сопровождает решение этой проблемы.
Представляем Teiid Spring Boot
Снова, чтобы переформулировать проблему: мы должны сосредоточиться на модели домена нашего сервиса, но первоначально данные, которые поддерживают модель домена, все еще будут в нашей базе данных монолита / бэкэнда. Можем ли мы фактически объединить структуру модели данных монолита с нашей желаемой моделью предметной области и исключить код котельной пластины, связанный с объединением этих данных?
Teiid Spring Boot позволяет нам сосредоточиться на нашей модели предметной области, аннотировать их аннотациями JPA @Entity как мы это делаем с любой моделью, и сопоставлять их с нашей собственной новой базой данных, а также виртуально сопоставлять базу данных монолита. Для начала работы с teiid-spring-boot достаточно импортировать следующую зависимость:
|
1
2
3
4
5
|
<dependency> <groupId>org.teiid.spring</groupId> <artifactId>teiid-spring-boot-starter</artifactId> <version>1.0.0-SNAPSHOT</version></dependency> |
Это начальный проект, который подключится к магии автоматического конфигурирования Spring и попытается настроить нашу виртуальную базу данных (при поддержке базы данных монолита и нашей реальной, физической базы данных, принадлежащей этому сервису).
Теперь нам нужно определить источники данных в Spring Boot для каждого бэкенда. В этом примере я использовал две базы данных MySQL, но это только деталь. Мы не ограничены тем, что оба источника данных одинаковы, и мы не ограничены RDBM. Вот пример:
|
1
2
3
4
5
6
7
8
9
|
spring.datasource.legacyDS.url=jdbc:mysql://localhost:3306/ticketmonster?useSSL=falsespring.datasource.legacyDS.username=ticketspring.datasource.legacyDS.password=monsterspring.datasource.legacyDS.driverClassName=com.mysql.jdbc.Driverspring.datasource.ordersDS.url=jdbc:mysql://localhost:3306/orders?useSSL=falsespring.datasource.ordersDS.username=ticketspring.datasource.ordersDS.password=monsterspring.datasource.ordersDS.driverClassName=com.mysql.jdbc.Driver |
Давайте также настроим teiid-spring-boot для сканирования наших моделей доменов на предмет их виртуальных сопоставлений с монолитом. В application.properties давайте добавим это:
|
1
|
spring.teiid.model.package=org.ticketmonster.orders.domain |
Teiid Spring Boot позволяет нам указывать наши отображения как аннотации к нашим определениям @Entity . Вот пример ( см. Полную реализацию и полный набор доменных объектов на github ):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
@SelectQuery("SELECT s.id, s.description, s.name, s.numberOfRows AS number_of_rows, s.rowCapacity AS row_capacity, venue_id, v.name AS venue_name FROM legacyDS.Section s JOIN legacyDS.Venue v ON s.venue_id=v.id;")@Entity@Table(name = "section", uniqueConstraints=@UniqueConstraint(columnNames={"name", "venue_id"}))public class Section implements Serializable { @Id @GeneratedValue(strategy = IDENTITY) private Long id; @NotEmpty private String name; @NotEmpty private String description; @NotNull @Embedded private VenueId venueId; @Column(name = "number_of_rows") private int numberOfRows; @Column(name = "row_capacity") private int rowCapacity; |
В приведенном выше примере мы использовали @SelectQuery для определения соответствия между унаследованным источником данных ( legacyDS.* ) И нашей собственной моделью предметной области. Обратите внимание, что часто эти сопоставления могут содержать множество соединений и т. Д., Чтобы получить данные в нужной форме для нашей модели; лучше написать это СОЕДИНЕНИЕ один раз в аннотации, в которой будет пытаться написать много кода, чтобы справиться с этим через REST API (не только запрос, но и фактическое сопоставление с нашей предполагаемой моделью предметной области). В приведенном выше случае мы просто отобразили данные из монолита в нашу модель предметной области — но что, если нам нужно объединить нашу собственную базу данных? Нечто подобное можно сделать ( см. Полное описание в сущности Ticket.java ):
|
1
2
3
4
5
6
|
@SelectQuery("SELECT id, CAST(price AS double), number, rowNumber AS row_number, section_id, ticketCategory_id AS ticket_category_id, tickets_id AS booking_id FROM legacyDS.Ticket " +"UNION ALL SELECT id, price, number, row_number, section_id, ticket_category_id, booking_id FROM ordersDS.ticket") |
Обратите внимание, что в этом примере мы объединяем оба представления (из базы данных monolith и нашей собственной локальной базы данных Orders ) с ключевым словом UNION ALL . 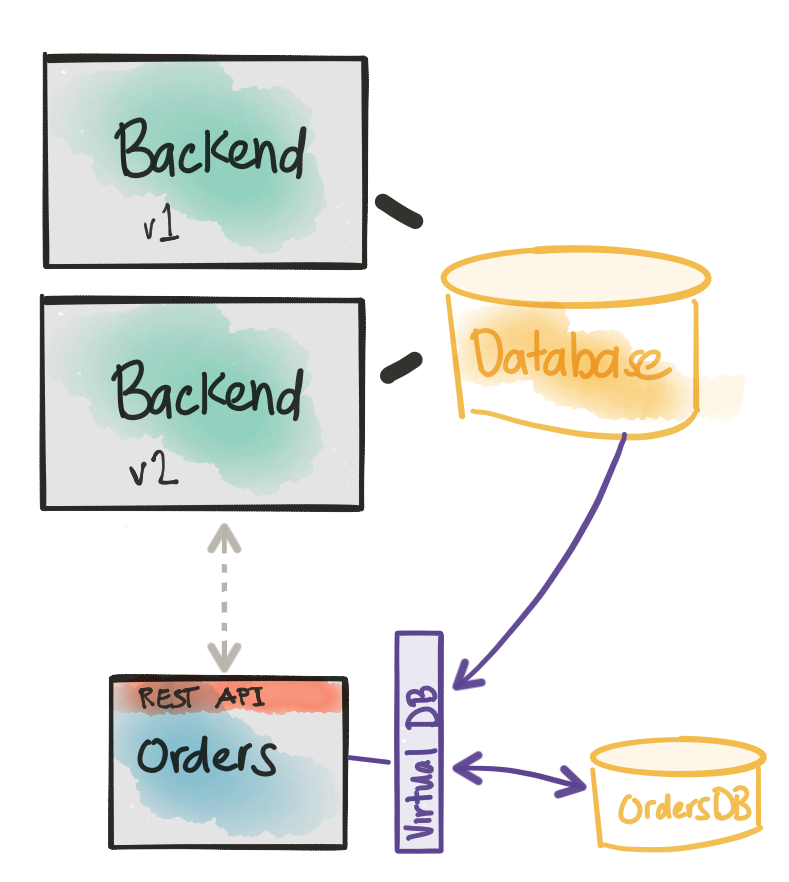
А как насчет обновлений или вставок?
Например, наша служба Orders должна хранить заказы / заказы. Мы можем добавить аннотацию @InsertQuery к сущности / агрегату DDD Booking следующим образом:
|
1
2
3
4
|
@InsertQuery("FOR EACH ROW \n"+ "BEGIN ATOMIC \n" + "INSERT INTO ordersDS.booking (id, performance_id, performance_name, cancellation_code, created_on, contact_email ) values (NEW.id, NEW.performance_id, NEW.performance_name, NEW.cancellation_code, NEW.created_on, NEW.contact_email);\n" + "END") |
См. Документацию для остальных аннотаций teiid-spring-boot, которые мы можем использовать.
Вы можете видеть здесь, когда мы сохраняем новое Booking (JPA, Spring Data и т. Д.), Которое виртуальная база данных знает, чтобы сохранить его в нашей собственной базе данных Orders . Если вы предпочитаете использовать Spring Data , вы все равно можете воспользоваться teiid-spring-boot . Вот пример из образцов teiid-spring-boot :
|
1
2
3
4
5
|
public interface CustomerRepository extends CrudRepository<Customer, Long> { @Query("select c from Customer c where c.ssn = :ssn") Stream<Customer> findBySSNReturnStream(@Param("ssn") String ssn);} |
Если у нас есть правильные аннотации отображения teiid-spring-boot , этот репозиторий spring-data будет правильно понимать наш уровень виртуальной базы данных и просто позволит нам работать с нашей моделью предметной области, как мы и ожидали.
Чтобы повторить; это временное решение для начальных этапов разложения микросервиса; это не предназначено для окончательного решения. Мы все еще повторяем это в нашем примере. Мы намереваемся уменьшить количество элементов, которые могут возникнуть при выполнении картографирования / трансляции и т. Д. Вручную.
Если вы все еще стремитесь поддержать простой API для низкоуровневого доступа к данным в монолитной базе данных (опять же, как временное решение), то teiid-spring-boot по-прежнему ваш друг. Вы можете очень быстро представить этот вид API без кода, используя интеграцию teiid-spring-boot мы имеем с teiid-spring-boot . Пожалуйста, ознакомьтесь с модулем odata для получения дополнительной информации (обратите внимание, мы все еще работаем над большим количеством документов для проекта!)
На этом этапе декомпозиции у нас должна быть реализация нашего сервиса Orders с соответствующим API, моделью домена, подключением к нашей собственной базе данных и временным созданием виртуального сопоставления с нашей монолитной базой данных, которое мы можем использовать внутри нашей модели домена. Далее нам нужно развернуть его в производство и запустить в темноте.
Начать отправку теневого трафика на новый сервис (темный запуск) 

Пересмотреть соображения
- Внедрение новой службы Orders в путь кода создает риск
- Нам нужно отправлять трафик на новый сервис контролируемым образом
- Мы хотим иметь возможность направлять трафик на новый сервис, а также на старый путь кода
- Нам нужно контролировать и контролировать влияние новой услуги
- Нам нужны способы помечать транзакции как «синтетические», чтобы не иметь неприятных проблем с согласованностью бизнеса
- Мы хотим развернуть эту новую функциональность для определенных групп / групп / пользователей
Следуя части I этого раздела, мы собираемся изменить монолит, чтобы позвонить в наш новый сервис Orders . Как описано в первой части, мы будем использовать некоторые приемы из книги Майкла Фезера, чтобы обернуть / расширить существующую логику в нашем монолите для вызова нашей новой службы. Например, наш монолит выглядел так для реализации createBookings :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
@POST@Consumes(MediaType.APPLICATION_JSON)public Response createBooking(BookingRequest bookingRequest) { try { // identify the ticket price categories in this request Set<Long> priceCategoryIds = bookingRequest.getUniquePriceCategoryIds(); // load the entities that make up this booking's relationships Performance performance = getEntityManager().find(Performance.class, bookingRequest.getPerformance()); // As we can have a mix of ticket types in a booking, we need to load all of them that are relevant, // id Map<Long, TicketPrice> ticketPricesById = loadTicketPrices(priceCategoryIds); // Now, start to create the booking from the posted data // Set the simple stuff first! Booking booking = new Booking(); booking.setContactEmail(bookingRequest.getEmail()); booking.setPerformance(performance); booking.setCancellationCode("abc"); // Now, we iterate over each ticket that was requested, and organize them by section and category // we want to allocate ticket requests that belong to the same section contiguously Map<Section, Map<TicketCategory, TicketRequest>> ticketRequestsPerSection = new TreeMap<Section, java.util.Map<TicketCategory, TicketRequest>>(SectionComparator.instance()); for (TicketRequest ticketRequest : bookingRequest.getTicketRequests()) { final TicketPrice ticketPrice = ticketPricesById.get(ticketRequest.getTicketPrice()); if (!ticketRequestsPerSection.containsKey(ticketPrice.getSection())) { ticketRequestsPerSection .put(ticketPrice.getSection(), new HashMap<TicketCategory, TicketRequest>()); } ticketRequestsPerSection.get(ticketPrice.getSection()).put( ticketPricesById.get(ticketRequest.getTicketPrice()).getTicketCategory(), ticketRequest); } |
На самом деле, в этом коде есть намного больше — как и в любом хорошем монолите, есть очень длинные, сложные методы, которые могут быть трудны для понимания того, что происходит. Мы собираемся изменить это на что-то вроде этого:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
|
@POST@Consumes(MediaType.APPLICATION_JSON)public Response createBooking(BookingRequest bookingRequest) { Response response = null; if (ff.check("orders-internal")) { response = createBookingInternal(bookingRequest); } if (ff.check("orders-service")) { if (ff.check("orders-internal")) { createSyntheticBookingOrdersService(bookingRequest); } else { response = createBookingOrdersService(bookingRequest); } } return response;} |
Этот метод намного меньше, более организован и проще в использовании. Но что здесь происходит? Что это за ff.check(...) ?
Ключевым моментом здесь является то, что мы изменяем монолит как можно меньше; в идеале у нас есть модульные / компонентные / интеграционные / системные тесты, чтобы помочь проверить, что наши изменения ничего не сломали. Если нет, рефакторинг тактически, чтобы иметь возможность проводить тесты на месте.
Как часть изменений, которые мы делаем, мы не хотим изменять существующий поток вызовов: мы перемещаем старую реализацию в метод с именем createBookingInternal и оставляем его как есть. Но мы также добавляем новый метод, который будет отвечать за новый путь кода, который вызывает службу Orders . Мы собираемся использовать библиотеку признака-флага , которая позволит нам сделать пару вещей:
- Полный контроль времени выполнения / конфигурации, какую реализацию использовать для заказов
- Отключить новый функционал
- Включить ОБА новые функции и старые функции одновременно
- Полностью переключиться на новую функциональность
- Убить переключатель всех функций
Мы используем Feature Flags 4 Java (FF4j) , но есть альтернативы для других языков, в том числе для SaaS-провайдеров, таких как Launch Darkly . Конечно, вы могли бы написать свой собственный фреймворк для этого, но эти существующие проекты предлагают готовые возможности. Это очень похожий подход к Facebook (и другим) фреймворку для контроля над релизами . Вернитесь к обсуждению разницы между развертыванием и выпуском .
Чтобы использовать FF4j, давайте добавим зависимость в наш pom.xml
|
1
2
3
4
5
|
<dependency> <groupId>org.ff4j</groupId> <artifactId>ff4j-core</artifactId> <version>${ffj4.version}</version></dependency> |
Затем мы можем объявить функции в нашем файле ff4j.xml (и сгруппировать их и т. Д., См. Документацию по ff4j для получения более подробной информации о более сложных функциях / функциях группировки :
|
1
2
3
4
5
6
|
<features> <feature uid="orders-internal" enable="true" description="Continue with legacy orders implementation" /> <feature uid="orders-service" enable="false" description="Call new orders microservice" /></features> |
Затем мы можем создать экземпляр объекта FF4j и использовать его для проверки, включены ли функции в нашем коде:
|
1
2
3
4
5
6
|
FF4j ff4j = new FF4j("ff4j.xml");if (ff4j.check("special-feature")){ doSpecialFeature();} |
ff4j.xml реализация использует ff4j.xml конфигурации ff4j.xml для определения функций. Затем функции можно переключать во время выполнения и т. Д. (См. Ниже), но прежде чем мы продолжим работу, я хочу отметить, что функции и их соответствующий статус (включить / отключить) должны поддерживаться постоянным хранилищем в любом виде. тривиальное развертывание. Пожалуйста, посмотрите документацию FeatureStore на сайте ff4j .
Нам также нужен способ настройки / влияния на состояние функций во время выполнения. FF4j имеет веб-консоль , которую можно развернуть, чтобы просмотреть / повлиять на состояние функций в приложении: 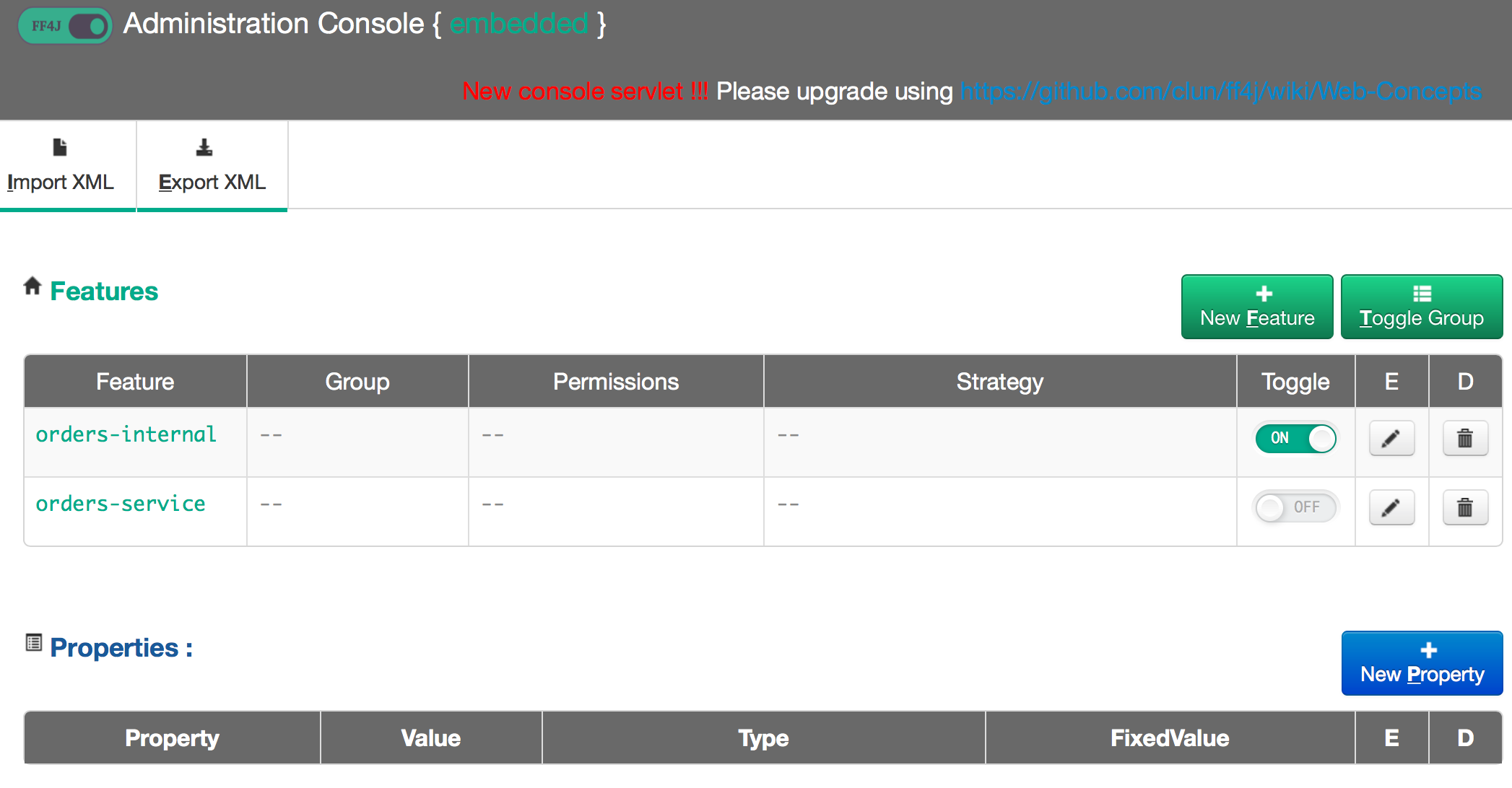
По умолчанию мы будем развертывать только с включенной устаревшей функцией. То есть по умолчанию мы не должны видеть никаких изменений в путях выполнения кода и поведении службы. Затем мы можем отменить это развертывание и использовать флаги функций, чтобы включить ОБА путь к устаревшему коду, а также новый путь, который вызывает наш новый сервис Orders . Для некоторых сервисов нам может не потребоваться уделять больше внимания, чем просто включение второго пути кода. Но для чего-то, что изменяет состояние, нам нужен способ сообщить, что это «тестовая» или «синтетическая» транзакция. В нашем случае, когда мы включаем ОБА и устаревший путь к новому коду одновременно, мы помечаем сообщения, отправленные в службу Orders как «синтетические». Это дает подсказку сервису Orders что мы должны просто обработать его как обычный запрос, а затем отбросить или откатить результат. Это чрезвычайно ценно, чтобы получить представление о том, что делает новый путь кода, и дать нам возможность сравнить со старым путем (то есть сравнить результаты, побочные эффекты, влияние времени / задержки и т. Д.). Если мы ПРОСТО включим новый путь к коду и отключим старый путь к коду, мы будем отправлять живые запросы (без синтетического индикатора / флага).
Указание сервисных контрактов
На этом этапе нам, вероятно, следует написать код для подключения монолита к новому сервису заказов для потоков заказов и заказов. Сейчас настало время для монолита выразить любые требования в отношении контракта или данных, которые могут иметь значение при Orders службы Orders . Конечно, сервис Orders является независимым, автономным сервисом и обещает предоставить определенный набор функций / SLA / SLO и т. Д., Но когда мы начинаем создавать распределенные системы, важно понимать предположения о взаимодействии сервисов и делать их явными.
Обычно мы рассматриваем контракты с точки зрения провайдера. В этом случае мы смотрим на проблему с точки зрения потребителя. Что потребители на самом деле используют или ценят от поставщика услуг? Можем ли мы предоставить эту обратную связь поставщику, чтобы он мог понять, что на самом деле используется их услугой и о том, что следует соблюдать при внесении изменений в его службу; т.е. мы не хотим нарушать существующую совместимость. Мы собираемся использовать идею контрактов, ориентированных на потребителя, чтобы помочь сделать предположения явными. Мы собираемся использовать проект с именем Pact, который представляет собой независимый от языка формат документации для определения договоров между службами (с акцентом на договоры, ориентированные на потребителя). Я полагаю, что Pact был недавно основан людьми из DiUS, технологической компании в Австралии . 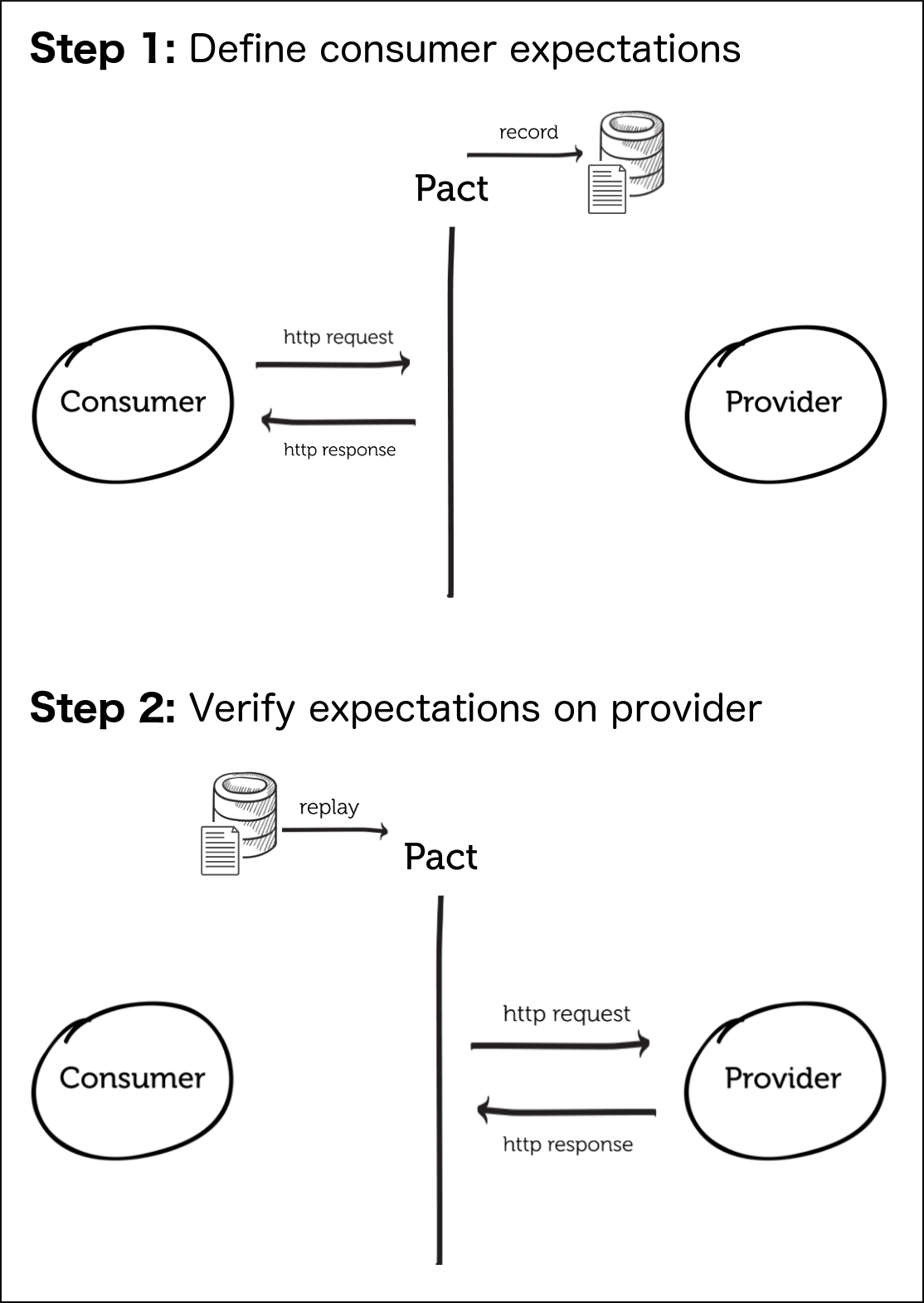
Изображение выше взято из документации Pact
Давайте посмотрим на пример из нашего внутреннего сервиса . Мы собираемся создать правило потребительского контракта для нашего приложения backend-v2 котором изложены ожидания поставщика услуг (сервис Orders ). Когда мы POST HTTP-запрос к /rest/bookings мы можем утверждать некоторые ожидания.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
@Pact(provider="orders_service", consumer="test_synthetic_order")public RequestResponsePact createFragment(PactDslWithProvider builder) { RequestResponsePact pact = builder .given("available shows") .uponReceiving("booking request") .path("/rest/bookings") .matchHeader("Content-Type", "application/json") .method("POST") .body(bookingRequestBody()) .willRespondWith() .body(syntheticBookingResponseBody()) .status(200) .toPact(); return pact;} |
Когда мы вызываем службу провайдера и передаем конкретное тело, мы ожидаем HTTP 200 и ответ, который соответствует нашему контракту. Давайте взглянем. Во-первых, вот как мы указываем тело запроса на бронирование:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
private DslPart bookingRequestBody(){ PactDslJsonBody body = new PactDslJsonBody(); body .integerType("performance", 1) .booleanType("synthetic", true) .stringType("email", "foo@bar.com") .minArrayLike("ticketRequests", 1) .integerType("ticketPrice", 1) .integerType("quantity") .closeObject() .closeArray(); return body;} |
Pact-jvm позволяет нам подключиться к нашей любимой платформе тестирования (в данном случае JUnit) с модулями pact-jvm-junit . Если мы используем Arquillian , которым вы должны быть, для тестов компонентов и интеграции, мы можем подключить Pact к нашим тестам Arquillian с помощью Arquillian Algeron . Alegeron расширяет Pact, делая его простым в использовании из тестов Arquillian, а также добавляет функциональность, которую вам пришлось бы создавать самостоятельно (и это крайне важно для конвейеров CI / CD): способность автоматически публиковать контракты для брокера по контрактам и выполнять контракты. от брокера при тестировании. Я настоятельно рекомендую вам взглянуть на Arquillian и Arquillian Algeron для проведения тестирования потребительских контрактов для ваших приложений Java.
Мы можем создать фрагменты PactDslJsonBody и просто использовать семантику «подстановочный знак» или «пропустить что-нибудь в этом поле». Например, body.integerType("attr_name", default_value) позволяет нам указать, что «будет атрибут с именем X со значением по умолчанию». Если мы оставим параметр значения по умолчанию вне поля, тогда значение может быть действительно любым. В этом фрагменте мы просто указываем структуру запроса. Обратите внимание, мы указываем атрибут с именем synthetic и для запросов, где это свойство имеет значение true , мы ожидаем ответ, который имеет определенную структуру.
И вот где мы объявляем наш потребительский контракт (ответ):
|
1
2
3
4
5
6
|
private DslPart syntheticBookingResponseBody() { PactDslJsonBody body = new PactDslJsonBody(); body .booleanType("synthetic", true); return body;} |
Это довольно простой пример: для этого теста мы ожидаем, что ответ будет иметь атрибут synthetic: true . Это важно, потому что когда мы отправляем искусственные заказы, мы хотим убедиться, что служба Orders признает, что это действительно обрабатывалось как синтетический запрос. Если мы запустим этот тест, и он успешно завершится, мы получим этот договор Pact в нашей целевой директории сборки (т.е. в моем случае он перейдет в ./target/pacts
|
001
002
003
004
005
006
007
008
009
010
011
012
013
014
015
016
017
018
019
020
021
022
023
024
025
026
027
028
029
030
031
032
033
034
035
036
037
038
039
040
041
042
043
044
045
046
047
048
049
050
051
052
053
054
055
056
057
058
059
060
061
062
063
064
065
066
067
068
069
070
071
072
073
074
075
076
077
078
079
080
081
082
083
084
085
086
087
088
089
090
091
092
093
094
095
096
097
098
099
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
|
{ "provider": { "name": "orders_service" }, "consumer": { "name": "test_synthetic_order" }, "interactions": [ { "description": "booking request", "request": { "method": "POST", "path": "/rest/bookings", "headers": { "Content-Type": "application/json" }, "body": { "synthetic": true, "performance": 1, "ticketRequests": [ { "quantity": 100, "ticketPrice": 1 } ], "email": "foo@bar.com" }, "matchingRules": { "header": { "Content-Type": { "matchers": [ { "match": "regex", "regex": "application/json" } ], "combine": "AND" } }, "body": { "$.performance": { "matchers": [ { "match": "integer" } ], "combine": "AND" }, "$.synthetic": { "matchers": [ { "match": "type" } ], "combine": "AND" }, "$.email": { "matchers": [ { "match": "type" } ], "combine": "AND" }, "$.ticketRequests": { "matchers": [ { "match": "type", "min": 1 } ], "combine": "AND" }, "$.ticketRequests[*].ticketPrice": { "matchers": [ { "match": "integer" } ], "combine": "AND" }, "$.ticketRequests[*].quantity": { "matchers": [ { "match": "integer" } ], "combine": "AND" } }, "path": { } }, "generators": { "body": { "$.ticketRequests[*].quantity": { "type": "RandomInt", "min": 0, "max": 2147483647 } } } }, "response": { "status": 200, "headers": { "Content-Type": "application/json; charset=UTF-8" }, "body": { "synthetic": true }, "matchingRules": { "body": { "$.synthetic": { "matchers": [ { "match": "type" } ], "combine": "AND" } } } }, "providerStates": [ { "name": "available shows" } ] } ], "metadata": { "pact-specification": { "version": "3.0.0" }, "pact-jvm": { "version": "" } }} |
Отсюда мы можем поместить наш контракт в Git , Contract Broker или в общую файловую систему . На стороне поставщика (служба Orders ) мы можем создать компонентный тест, который проверяет, действительно ли служба поставщика соответствует ожиданиям в потребительском контракте. Обратите внимание, что у вас может быть много потребительских контрактов, и мы можем протестировать их все (особенно, если мы вносим изменения в сервис провайдера — мы можем провести импакт-тест, чтобы увидеть, на каких последующих пользователей нашего сервиса это может повлиять).
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
|
@RunWith(PactRunner.class)@Provider("orders_service")@PactFolder("pact/")public class ConsumerContractTest { private static ConfigurableApplicationContext applicationContext; @TestTarget public final Target target = new HttpTarget(8080); @BeforeClass public static void startSpring() { applicationContext = SpringApplication.run(Application.class); } @State("available shows") public void testDefaultState() { System.out.println("hi"); }} |
Обратите внимание, что в этом простом примере мы ./pacts контракты из папки в файловой системе в ./pacts
После того, как мы проведем тестирование по контракту, ориентированное на потребителя, мы сможем более комфортно вносить изменения в наш сервис. Смотрите примеры для сервиса backend-v2, а также для службы заказов провайдера .
Canary / Rolling Release для новой услуги 
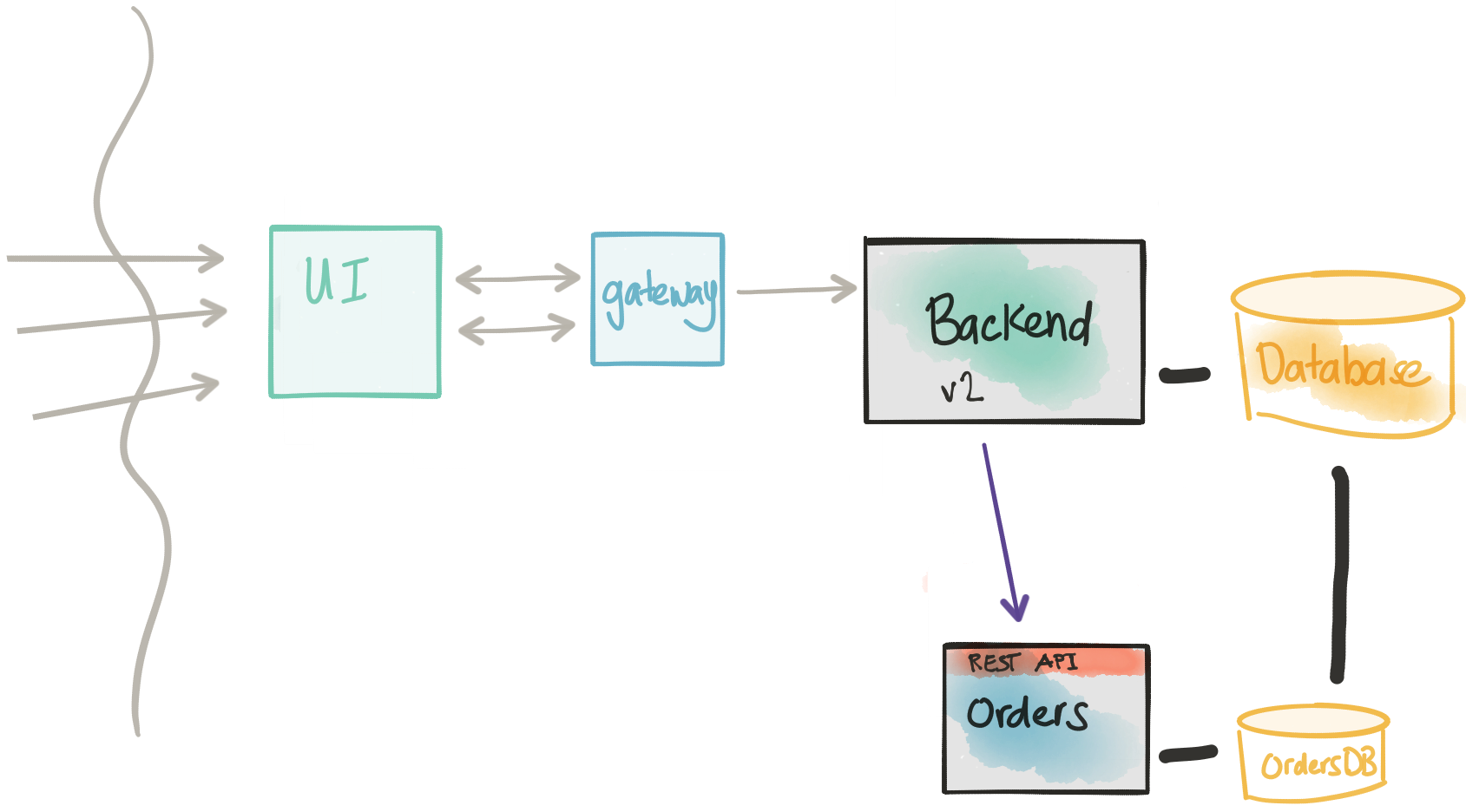
Пересмотреть соображения
- Мы можем идентифицировать группы когорт и отправлять трафик транзакций в реальном времени на наш новый микросервис
- Нам по-прежнему необходимо прямое подключение базы данных к монолиту, потому что будет период времени, когда транзакции будут по-прежнему идти на оба пути кода.
- Как только мы переместим весь трафик на наш микросервис, мы сможем отказаться от старой функциональности
- Обратите внимание, что как только мы отправляем живой трафик на новый сервис, мы должны учитывать тот факт, что откат к старому пути кода потребует некоторых трудностей и координации.
Другой важной частью этого сценария является то, что нам нужен способ просто отправить часть трафика через это новое развертывание, имеющее флаги функций. Мы можем использовать Istio, чтобы точно контролировать, какой именно сервер вызывается . Например, у нас развернут backend-v1 который полностью освобожден и принимает производственную нагрузку. Когда мы развернем backend-v2 которого есть флаги функций, управляющие нашим новым путем к коду, мы можем откорректировать этот выпуск с Istio аналогично тому, как это делалось в предыдущем посте . Мы можем просто отправить 1% трафика и медленно увеличивать (5%, 25% и т. Д.) И наблюдать эффект. Мы также можем переключать функции, чтобы включить как устаревшие пути кода, так и новые пути кода. Это очень мощный метод, который позволяет нам значительно снизить риск наших изменений и перехода на микросервисную архитектуру. Вот пример правила маршрута Istio, которое делает это для нас:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
apiVersion: config.istio.io/v1alpha2kind: RouteRulemetadata: name: backend-v2spec: destination: name: backend precedence: 20 route: - labels: version: v1 weight: 99 - labels: version: v2 weight: 1 |
Некоторые вещи, на которые следует обратить внимание: на этом этапе мы можем включить как устаревшие пути, так и пути с новым кодом, если новая служба Orders принимает искусственные транзакции. Описанная выше канарейка будет применяться к 1% трафика независимо от того, кто они. Может быть полезно сначала просто предоставить информацию внутренним пользователям или небольшому сегменту внешних пользователей и фактически отправить их через службу активных Orders (т. Е. Несинтетический трафик). Благодаря комбинации хирургической маршрутизации на основе конфигурации пользователя и конфигурации FF4j, объединяющей пользователей в когорты, мы можем включить полный путь кода к новой службе Orders (живой трафик, несинтетическая транзакционная рабочая нагрузка). Ключом к этому, однако, является то, что как только пользователь был направлен на путь действующего кода для Orders они всегда должны отправляться таким образом для будущих вызовов. Это связано с тем, что после размещения заказа с новой службой он не будет отображаться в базе данных монолита. Все запросы / обновления к этому заказу для этого пользователя должны теперь всегда проходить через новый сервис.
На этом этапе мы можем наблюдать шаблоны трафика / поведение службы и принимать решения для увеличения апертуры релиза. В итоге мы получаем 100% трафика, идущего на новый сервис.
Что делать с данными, которых нет в монолите? Вы можете ничего не делать — новый сервис Orders теперь является законным владельцем логики заказов / бронирования + данные. Если вы чувствуете, что вам нужна некоторая интеграция между монолитом для этих новых заказов, вы можете опубликовать события из вашего нового сервиса Orders с деталями заказа. Монолит может затем захватить эти события и сохранить их в базе данных монолита. Другие службы также могут участвовать в этих событиях и реагировать на них. Механизм публикации событий был бы полезен.
Опять же, это сообщение в блоге стало слишком длинным! Осталось два раздела: «ETL / миграция автономных данных» и «Отключение / разъединение хранилищ данных». Я хочу, чтобы эти разделы были обработаны должным образом, поэтому я должен закончить здесь и сделать эту часть IV! Часть V будет веб-трансляцией / видео / демонстрацией, показывающей всю эту работу.
| Смотрите оригинальную статью здесь: Монолит с низким уровнем риска для Microservice Evolution Часть III
Мнения, высказанные участниками Java Code Geeks, являются их собственными. |