Prometheus — это набор инструментов для мониторинга и оповещения системы с открытым исходным кодом. Данные, относящиеся к мониторингу, хранятся в ОЗУ и LevelDB, тем не менее, данные могут храниться в других системах хранения, таких как ElasticSearch, InfluxDb и другие, https://prometheus.io/docs/operating/integrations/#remote-endpoints-and-storage
У Prometheus также могут быть плагины оповещения, которые будут уведомлять заинтересованные лица об определенных событиях, таких как нарушение некоторых SLA (Соглашение об уровне обслуживания). В этом посте мы увидим, как настроить коллекторы Prometheus и их варианты использования.
Вам также может понравиться: Мониторинг с помощью Прометея
Генерал Прометей Развертывание
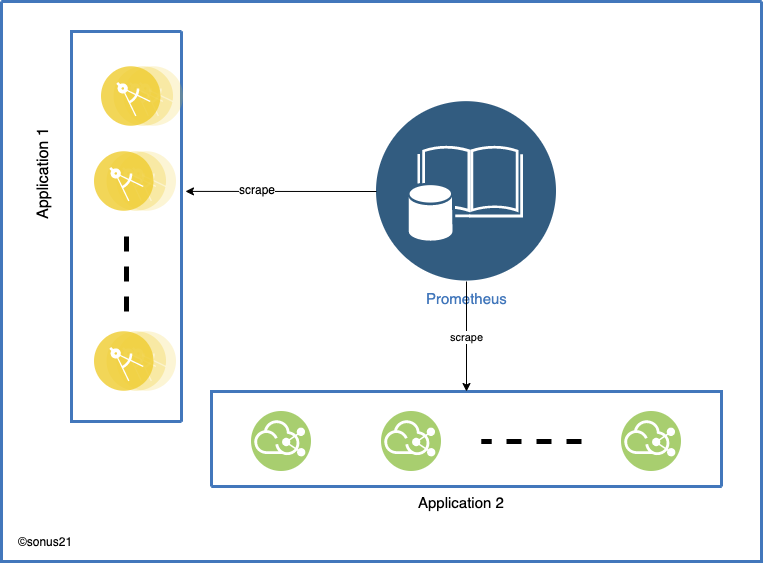
После развертывания Prometheus он настроен на очистку данных от некоторой цели, указанная конечная точка предоставляет данные, относящиеся к метрикам, и предоставляет несколько конфигураций, которые можно использовать для очистки данных с определенного сервера или набора серверов. Например, мы можем настроить использование конфигурации EC2, чтобы Prometheus мог автоматически выполнять автоматическое масштабирование.
Каждый сервер приложений / экземпляр должен хранить данные, относящиеся к этой службе, до вызова API очистки. Конечная точка очистки будет сбрасывать данные в формате, понятном Прометею. Требуется хранение данных в локальном хранилище, что означает, что нам нужно хранить данные, связанные с метриками, в памяти приложения или предоставлять какую-то общую систему хранения. Хранение данных в памяти приложения имеет свои плюсы и минусы
Pros
- Не требует интеграции с другой системой хранения
- Нет коммуникационных накладных расходов
Cons
- При перезапуске приложения данные теряются
- Объем памяти увеличивается с увеличением количества точек данных
Обработка HTTP-запросов
На приведенном выше рисунке клиентский запрос проходит через Интернет и достигает балансировщика нагрузки, который перенаправляет запрос на определенный сервер.
Каждый сервер обрабатывает HTTP-запрос по-разному, в зависимости от языка программирования разработки приложений и серверного программного обеспечения, такого как Apache2, Nginx, Tomcat и т. Д. Существует два основных варианта: Muiltiprocess на сервере может быть заранее запущено N экземпляров приложения, или же он может создать новый процесс по требованию, из-за ограничений ресурсов на сервере после обслуживания запроса экземпляр приложения уничтожается (приложения Python, Php, Ruby и т. д.).
Threading у нас есть только один экземпляр приложения и несколько N потоков обработки запросов, каждый запрос передается одному из потоков обработки запросов, если у нас достаточно ресурсов для обслуживания нового запроса (приложения Java, Go, Ruby и т. д.). Другой может быть комбинацией этих двух, в которой у нас будет N (> 0) число запущенных экземпляров приложения, и каждый из них сможет обработать запрос в определенном потоке.
Самоуничтожающиеся приложения
Самоуничтожающиеся приложения уничтожаются автоматически, как приложение веб-сервера Multprocess. Процесс может быть остановлен, как только запрос будет обработан сервером.Бессерверное приложение, также называемое FaaS (функция как услуга), является еще одним примером. Бессерверные экземпляры создаются автоматически на основе некоторых триггеров / событий.
События могут быть разных типов, например, при размещении заказа создается приложение без сервера для обработки выполнения, AWS предоставляет множество способов инициировать вызов функции для различных типов событий, например, когда какой-либо элемент изменяется в DynamoDB, затем генерируется событие, при добавлении нового элемента в очередь SQS запускает функцию, запускает функцию в указанное время.
После того, как событие обработано функцией, экземпляр может быть немедленно завершен или может использоваться повторно в течение некоторого времени, например, 10 минут. Как правило, разработчики не контролируют завершение экземпляра без сервера, как в случае обработки HTTP-запроса, когда новый процесс может быть остановлен после обработки запроса клиента.
Приложение, которое имеет только один экземпляр приложения, может обеспечить конечную точку очистки Prometheus без каких-либо проблем, поскольку оно может хранить данные в одном экземпляре приложения и совместно использовать их в нескольких потоках.
Приложение, созданное по требованию, имеет проблему, так как данные будут разбросаны по нескольким экземплярам, и, как мы обсуждали, экземпляр будет уничтожен в какой-то момент времени, что означает, что данные также будут потеряны, в противном случае нам потребуются некие агрегаторы это объединит данные из этих экземпляров и сохранит их в некоторой общей области памяти. Есть много способов решить вторую проблему, например, Prometheus Pushgateway, экспортер Prometheus.
Прометей с пушгейтом
На рисунке выше представлены два типа приложений: Приложение 1 и Приложение 2. Любое из них может быть приложением без сервера или несколькими многопроцессорными веб-приложениями.
Pushgatway хранит данные во внутреннем хранилище данных, и Prometheus удаляет их в соответствии с настройками. Это решает проблему хранения данных приложения, но это приводит к еще одной проблеме единой точки отказа, если настроен только один экземпляр Pushgatway.
В любом случае Pushgatway переходит в плохое состояние, такое как аппаратный сбой, проблема с сетью от клиента к push-шлюзу, или он не может справиться с высокой пропускной способностью, тогда все метрики будут потеряны. Pushgateway следует рассматривать в качестве последнего средства при развертывании, как описано в документе
Мы рекомендуем использовать Pushgateway только в определенных ограниченных случаях. Есть несколько ловушек при слепом использовании Pushgateway вместо обычной модели тяги Прометея для сбора общих метрик:
- При мониторинге нескольких экземпляров через один Pushgateway, Pushgateway становится одновременно единственной точкой отказа и потенциальным узким местом.
- Вы теряете автоматический мониторинг работоспособности Прометея с помощью
upметрики (генерируемой при каждой очистке). - Pushgateway никогда не забудет серию, переданную ему, и будет выставлять их Прометею навсегда, если только эти серии не будут удалены вручную через API Pushgateway.
Ссылка: https://prometheus.io/docs/practices/pushing/
В основном это следует использовать для приложений без серверов, где новые экземпляры запускаются и уничтожаются по требованию, а также для приложений, которые обрабатывают пакетное задание.
Из-за вышеуказанных ограничений нам следует рассмотреть возможность использования других альтернатив, таких как Node exporter , StatsD exporter , Graphite Exporter . Все эти три экспортера развертываются на главном компьютере вместе с кодом приложения, и данные собираются в экземпляре экспортера.
Узел Экспортер
Node exporter является одним из рекомендованных экспортеров, так как он может экспортировать информацию о хост-системе, а также ARP, CPU, использование диска, информацию Mem, текстовый файл. Текстовый файл является интересной частью экспортеров, так как наше приложение должно записывать данные в текстовый файл, и этот текстовый файл будет экспортирован в Прометей.
Текстовый файл должен соответствовать форматированию текстовых данных Prometheus, код приложения будет продолжать добавлять данные в текстовый файл, которые будут экспортироваться экспортером. Чтобы использовать его, установите —collector.textfile.directory флаг на экспортере узлов. Сборщик проанализирует все файлы в этом каталоге, соответствующие глобусу, *.prom используя текстовый формат.
Ссылка: https://prometheus.io/docs/instrumenting/exposition_formats/#text-format-example
Простой текст
1
# HELP http_requests_total The total number of HTTP requests.
2
# TYPE http_requests_total counter
3
http_requests_total{method="post",code="200"} 1027 1395066363000
4
http_requests_total{method="post",code="400"} 3 1395066363000
5
# Escaping in label values:
7
msdos_file_access_time_seconds{path="C:\\DIR\\FILE.TXT",error="Cannot find file:\n\"FILE.TXT\""} 1.458255915e9
8
# Minimalistic line:
10
metric_without_timestamp_and_labels 12.47
11
# A weird metric from before the epoch:
13
something_weird{problem="division by zero"} +Inf -3982045
14
# A histogram, which has a pretty complex representation in the text format:
16
# HELP http_request_duration_seconds A histogram of the request duration.
17
# TYPE http_request_duration_seconds histogram
18
http_request_duration_seconds_bucket{le="0.05"} 24054
19
http_request_duration_seconds_bucket{le="0.1"} 33444
20
http_request_duration_seconds_bucket{le="0.2"} 100392
21
http_request_duration_seconds_bucket{le="0.5"} 129389
22
http_request_duration_seconds_bucket{le="1"} 133988
23
http_request_duration_seconds_bucket{le="+Inf"} 144320
24
http_request_duration_seconds_sum 53423
25
http_request_duration_seconds_count 144320
26
# Finally a summary, which has a complex representation, too:
28
# HELP rpc_duration_seconds A summary of the RPC duration in seconds.
29
# TYPE rpc_duration_seconds summary
30
rpc_duration_seconds{quantile="0.01"} 3102
31
rpc_duration_seconds{quantile="0.05"} 3272
32
rpc_duration_seconds{quantile="0.5"} 4773
33
rpc_duration_seconds{quantile="0.9"} 9001
34
rpc_duration_seconds{quantile="0.99"} 76656
35
rpc_duration_seconds_sum 1.7560473e+07
36
rpc_duration_seconds_count 2693
StatsD Exporter
Экспортер StatsD говорит по протоколу StatsD, и приложение может общаться с экспортером StatsD, используя сокет TCP / UDP или UNIX . StatsD не может понимать никакие другие данные, кроме своего предопределенного формата, поэтому приложение должно отправлять данные в формате StatsD. Существует множество клиентских библиотек, которые могут отправлять данные в формате StatsD.
Формат данных StatsD
Джава
xxxxxxxxxx
1
<metric_name>:<metric_value>|<metric_type>|<sampling_rate>
Некоторые примеры данных могут выглядеть как
Джава
xxxxxxxxxx
1
# login users count sampled at 50% sampling rate login.users:10|c|.5
Я бы предложил использовать некоторую библиотеку для связи с экспортером StatsD, если вы не готовы рисковать.
Графит Экспортер
Экспортер графита очень похож на экспортер StatsD, но использует протокол графического текста . Использование памяти любым приложением будет увеличиваться, если по какой-то причине оно не будет очищено, что может привести к OOM исключению (Out of Memory).
Чтобы избежать того, что метрики OOM будут собираться мусором через пять минут после их последней отправки экспортеру, тем не менее, это поведение настраивается с помощью —graphite.sample-expiry флага.
В графическом текстовом протоколе данные описываются с использованием: <metric path> <metric value> <metric timestamp>
Graphite также поддерживает тегирование / маркировку метрик, которые могут быть заархивированы путем добавления тегов к пути метрики в виде:
disk.used;datacenter=dc1;rack=a1;server=web01
В этом примере имя серии disk.used и теги datacenter = dc1 , rack= a1и server=web01
Если вы нашли этот пост полезным, поделитесь, оставьте лайк и оставьте комментарий!
Дальнейшее чтение
Настройка и интеграция Prometheus с Grafana для мониторинга
Go Microservices, Часть 15: Мониторинг с помощью Прометея
Мониторинг с использованием Spring Boot 2.0, Prometheus и Grafana (Часть 2 - Использование метрик)