Эта статья является частью нашего курса Академии под названием MongoDB — A Scalable NoSQL DB .
В этом курсе вы познакомитесь с MongoDB. Вы узнаете, как установить его и как управлять им через оболочку. Кроме того, вы узнаете, как получить программный доступ к нему через Java и как использовать Map Reduce с ним. Наконец, будут объяснены более сложные понятия, такие как шардинг и репликация. Проверьте это здесь !
Содержание
1. Введение
Sharding — это метод, используемый для разделения большого количества данных между несколькими экземплярами сервера. В настоящее время объемы данных растут в геометрической прогрессии, и один физический сервер часто не может хранить и управлять такой массой. Sharding помогает в решении таких проблем, разделяя весь набор данных на более мелкие части и распределяя их по большому количеству серверов (или сегментов ). В совокупности все сегменты составляют целый набор данных или, с точки зрения MongoDB , единую логическую базу данных.
2. Конфигурация
MongoDB поддерживает сегментирование «из коробки» с использованием конфигураций сегментированных кластеров : серверов конфигурации (три для производственных развертываний), один или несколько сегментов (наборы реплик для производственных развертываний) и один или несколько процессов маршрутизации запросов .
- шарды хранят данные: по причине высокой доступности и согласованности данных каждый шард должен быть набором реплик (подробнее о репликации мы поговорим в части 5. Руководство по репликации MongoDB )
- маршрутизаторы запросов (процессы mongos ) перенаправляют клиентские приложения и направляют операции на соответствующие сегменты или сегменты (в кластере с разделителями может быть несколько маршрутизаторов запросов для балансировки нагрузки)
- серверы конфигурации хранят метаданные кластера: отображение набора данных кластера на сегменты ( маршрутизаторы запросов используют эти метаданные для нацеливания операций на конкретные сегменты ), для высокой доступности у сегментированного производственного кластера должно быть 3 сервера конфигурации, но для целей тестирования кластер с один сервер конфигурации может быть развернут
Данные сегментов (разделов) MongoDB для каждой коллекции. Доступ к защищенным коллекциям в изолированном кластере должен осуществляться только через маршрутизаторы запросов (процессы mongos ). Прямое соединение с осколком дает доступ только к части данных кластера. Кроме того, каждая база данных имеет так называемый основной сегмент, в котором хранятся все неотмеченные коллекции в этой базе данных.
Конфигурационные серверы — это особые экземпляры процессов mongod , в которых хранятся метаданные для одного сегментированного кластера . Каждый кластер должен иметь свои собственные серверы конфигурации . Серверы конфигурации используют протокол двухфазной фиксации для обеспечения согласованности и надежности. Все серверы конфигурации должны быть доступны для развертывания изолированного кластера или для внесения любых изменений в метаданные кластера. Кластеры становятся неработоспособными без метаданных кластера.
3. Схемы разбиения (разбиения)
MongoDB распределяет данные между осколками на уровне коллекции, разбивая данные коллекции по ключу осколка (более подробную информацию см. В официальной документации ).
Ключ Shard — это индексированное простое или составное поле, которое существует в каждом документе в коллекции. Используя разделение на основе диапазона или разделение на основе хеша , MongoDB разделяет значения ключа сегмента на порции и равномерно распределяет эти порции по сегментам . Для этого MongoDB использует два фоновых процесса:
- расщепление : фоновый процесс, который препятствует тому, чтобы куски становились слишком большими. Когда размер определенного чанка превышает указанный размер чанка (по умолчанию 64 Мб ), MongoDB разделяет чанк на половину. Вставки и обновления сегментированной коллекции могут вызывать расщепления.
- балансировщик : фоновый процесс, который управляет миграцией фрагментов. Балансировщик работает на каждом маршрутизаторе запросов в кластере. Когда распределение сегментированного набора в кластере происходит неравномерно, балансировщик перемещает фрагменты из фрагмента, который имеет наибольшее количество фрагментов, в сегмент с наименьшим количеством фрагментов, пока баланс не будет достигнут.
3.1. Sharding на основе диапазона (разбиение)
В сегментации (разбиении) на основе диапазонов MongoDB разделяет набор данных на диапазоны, определяемые значениями ключа сегмента. Например, если ключ шарда является числовым полем, MongoDB разбивает весь диапазон значений поля на меньшие непересекающиеся интервалы (куски).
Хотя основанный на диапазоне диапазон (разбиение) поддерживает более эффективные запросы диапазона, это может привести к неравномерному распределению данных.
3.2. Шардинг на основе хеша (разбиение)
В основанном на хеш-шифровании (разделении) MongoDB вычисляет значение хеш-функции ключа шарда, а затем использует эти хэши для разделения данных между шардами . Хеш-секционирование обеспечивает равномерное распределение данных, но приводит к неэффективным запросам диапазона.
4. Добавление / удаление осколков
MongoDB позволяет добавлять и удалять шарды в / из запущенного общего кластера. Когда добавляются новые осколки, это нарушает баланс, поскольку у новых осколков нет кусков. Хотя MongoDB начинает миграцию данных в новые сегменты немедленно, может пройти некоторое время, прежде чем кластер восстановит баланс.
Соответственно, когда осколки удаляются из кластера, балансировщик переносит все куски из этих осколков в другие осколки. Когда миграция завершена, осколки можно безопасно удалить.
5. Настройка Sharded Cluster
Теперь, когда мы понимаем основы сегментирования MongoDB , мы собираемся развернуть небольшой сегментированный кластер с нуля, используя упрощенную (похожую на тест) конфигурацию без наборов реплик и одного экземпляра сервера конфигурации .
Развертывание сегментированного кластера начинается с запуска процесса сервера mongod в режиме сервера конфигурации с использованием аргумента командной строки --configsvr . Каждому серверу конфигурации требуется свой собственный каталог данных для хранения полных метаданных кластера, которые должны предоставляться с использованием --dbpath командной строки --dbpath (который мы уже видели в части 1. Установка MongoDB — Как установить MongoDB ). При этом давайте выполним следующие шаги:
- Создайте папку данных (нам нужно сделать это только один раз):
mkdir configdb - Запустите сервер MongoDB:
bin/mongod --configsvr --dbpath configdb
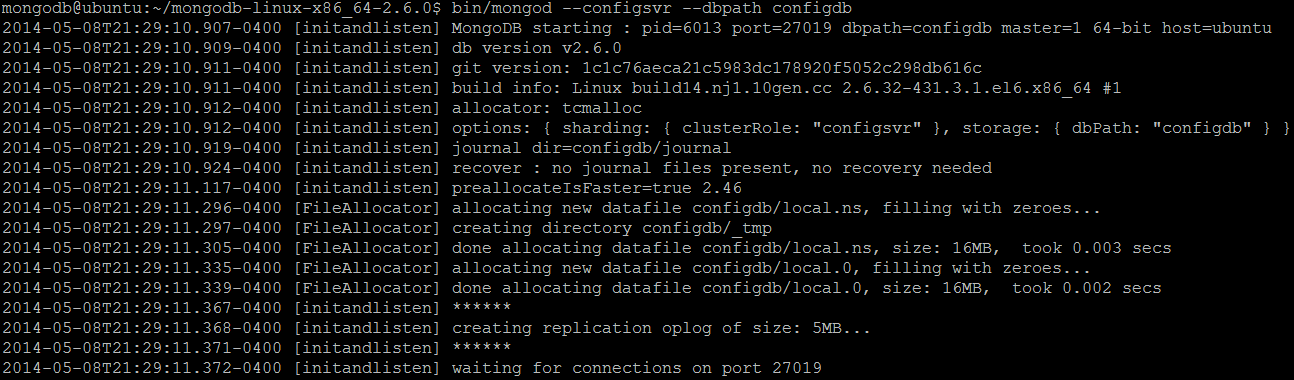
Фото 1 Сервер конфигурации был успешно запущен.
По умолчанию серверы конфигурации прослушивают порт 27019 . Все серверы конфигурации должны быть запущены и запущены до запуска защищенного кластера . В нашем развертывании один сервер конфигурации запускается на хосте с именем ubuntu .
Следующим шагом является запуск экземпляров процессов Mongos . Они легки и требуют только знания расположения серверов конфигурации . Для этого используется аргумент командной строки --configdb , за которым следуют имена серверов конфигурации через запятую (в нашем случае, только один сервер конфигурации на хосте Ubuntu ):
|
1
|
bin/mongos --configdb ubuntu |
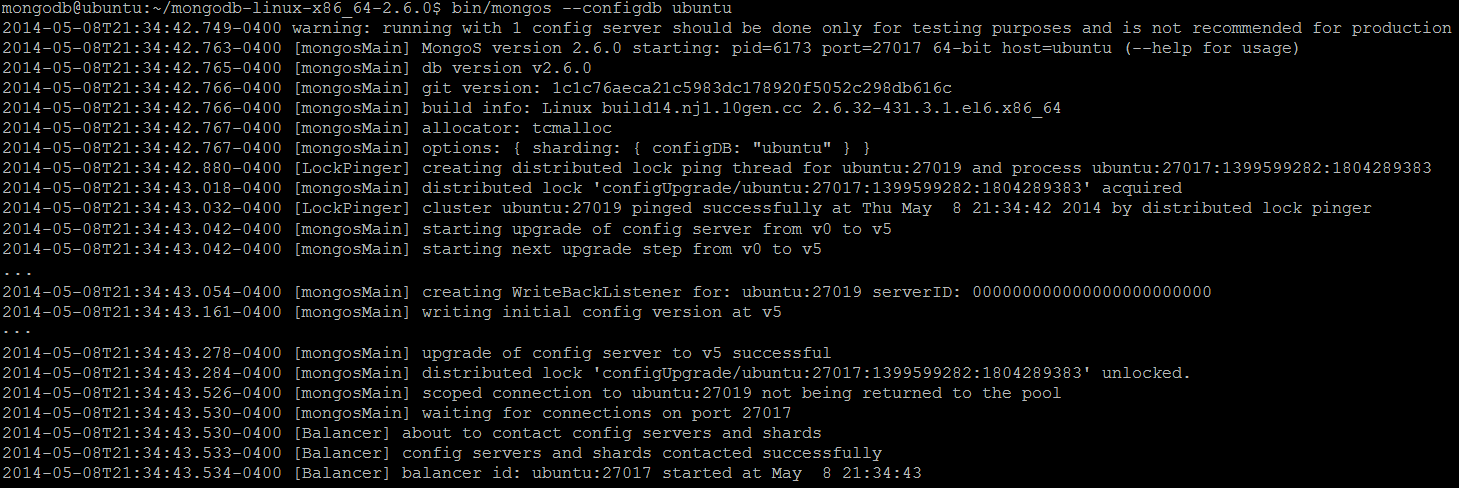
Фото 2 Один экземпляр mongos успешно запущен и подключен к серверу конфигурации .
Процесс прослушивания порта по умолчанию — 27017 , то же самое, что и обычный сервер MongoDB .
Последний шаг — добавить несколько обычных экземпляров сервера MongoDB ( сегменты ) в кластер с разделением на сегменты . Запускаем два экземпляра сервера MongoDB на разных портах, 27000 и 27001 соответственно.
- Запустить первый экземпляр сервера MongoDB ( shard ) на порту 27000
|
1
2
|
mkdir data-shard1bin/mongod --dbpath data-shard1 --port 27000 |
- Запустите второй экземпляр сервера MongoDB ( shard ) на порту 27001
|
1
2
|
mkdir data-shard2bin/mongod --dbpath data-shard2 --port 27001 |
Когда автономные экземпляры сервера MongoDB запущены и запущены, самое время добавить их в сегментированный кластер с помощью оболочки MongoDB . До сих пор мы использовали оболочку MongoDB для подключения к автономным серверам MongoDB . В изолированном кластере процессы mongos являются точками входа для всех клиентов, и поэтому мы собираемся подключиться к той, которую мы только что запустили (работает по умолчанию, порт 27017 ): bin/mongo --port 27017 --host ubuntu

Оболочка MongoDB предоставляет полезную команду sh.addShard() для добавления осколков (для получения дополнительной информации обратитесь к Помощникам команд осколков оболочки ). Давайте выполним эту команду для двух автономных экземпляров сервера MongoDB, которые мы запускали ранее:
|
1
2
|
sh.addShard( "ubuntu:27000" ) sh.addShard( "ubuntu:27001" ) |

Давайте проверим текущую конфигурацию сегментированного кластера, выполнив другую очень полезную команду оболочки MongoDB sh.status() .
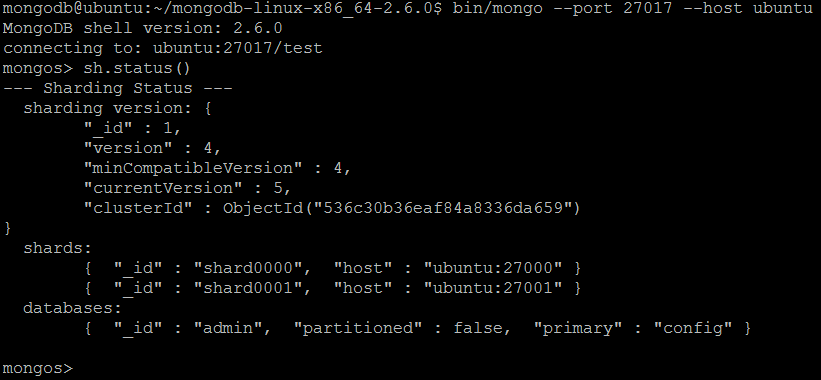
На этом этапе инфраструктура сегментированного кластера настроена, и мы можем продолжить работу с коллекциями баз данных.
Осколки
MongoDB позволяет связывать теги с определенными диапазонами ключа шарда с определенным шардом или подмножеством шардов . Один осколок может иметь несколько тегов, и несколько осколков также могут иметь один и тот же тег. Но любой заданный диапазон ключей шарда может иметь только один назначенный тег. Перекрытие диапазонов не допускается, а также маркировка одного и того же диапазона более одного раза.
Например, давайте назначим теги каждому из сегментов в нашем кластере с использованием команды sh.addShardTag() .
|
1
2
|
sh.addShardTag( "shard0001", "bestsellers" )sh.addShardTag( "shard0000", "others" ) |
Чтобы найти все сегменты, связанные с определенным тегом, необходимо ввести команду для базы данных конфигурации . Например, чтобы найти все фрагменты, помеченные как «бестселлеры», в оболочке MongoDB необходимо ввести следующие команды:
|
1
2
|
use configdb.shards.find( { tags: "bestsellers" } ) |

Фото 6 Поиск всех осколков, помеченных как «бестселлеры» .
Другая коллекция в базе данных конфигурации с именем tags содержит все определения тегов и может запрашиваться обычным способом для всех доступных тегов.
Соответственно, теги могут быть удалены из sh.removeShardTag() с помощью команды sh.removeShardTag() . Например:
|
1
|
sh.removeShardTag( "shard0000", "others" ) |
6. Шардинг базы данных и коллекции
Как мы уже знаем, MongoDB выполняет разбиение на уровне сбора. Но прежде чем коллекцию удастся защитить, она должна быть включена для базы данных коллекции. Включение сегментирования для базы данных не перераспределяет данные, но позволяет разделять коллекции в этой базе данных.
В демонстрационных целях мы собираемся повторно использовать пример книжного магазина из Части 3. Учебное пособие по MongoDB и Java и сделать коллекцию книг доступной. Давайте подключимся к экземпляру mongos , предоставив дополнительно имя базы данных bin/mongo --port 27017 --host ubuntu bookstore (или просто bin/mongo --port 27017 --host ubuntu bookstore команду use bookstore в существующем сеансе оболочки MongoDB ) и вставим пару документов в коллекцию книг .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
db.books.insert( { "title" : "MongoDB: The Definitive Guide", "published" : "2013-05-23", "categories" : [ "Databases", "NoSQL", "Programming" ], "publisher" : { "name" : "O'Reilly" } } )db.books.insert( { "title" : "MongoDB Applied Design Patterns", "published" : "2013-03-19", "categories" : [ "Databases", "NoSQL", "Patterns", "Programming" ], "publisher" : { "name" : "O'Reilly" } } )db.books.insert( { "title" : "MongoDB in Action", "published" : "2011-12-16", "categories" : [ "Databases", "NoSQL", "Programming" ], "publisher" : { "name" : "Manning" } } )db.books.insert( { "title" : "NoSQL Distilled: A Brief Guide to the Emerging World of Polyglot Persistence", "published" : "2012-08-18", "categories" : [ "Databases", "NoSQL" ], "publisher" : { "name" : "Addison Wesley" } } ) |
Как мы упоминали ранее, шардинг еще не включен ни для базы данных книжного магазина, ни для коллекции книг, поэтому весь набор данных попадает в основной шард (как мы упоминали в разделе « Введение »). Давайте включим sharding для базы данных книжного магазина, sh.enableSharding() команду sh.enableSharding() в оболочке MongoDB .

Фото 7 Включить шардинг для базы данных книжного магазина .
Мы очень близки к тому, чтобы наш осколочный кластер фактически выполнил некоторую работу и начал расщеплять реальные коллекции. Каждая коллекция должна иметь ключ шарда (см. Раздел «Схемы разбиения (разбиение) »), чтобы разделить его на несколько шардов . Давайте определим ключ шардинга на основе хэша (см. Раздел «Шардинг на основе хэша ») для коллекции книг на основе поля «документ _id» .
|
1
|
db.books.ensureIndex( { "_id": "hashed" } ) |
После этого, давайте скажем MongoDB, что нужно sh.shardCollection() коллекцию книг с помощью команды sh.shardCollection() (см. Подробности в командах Sharding и помощниках команд )
|
1
|
sh.shardCollection( "bookstore.books", { "_id": "hashed" } ) |

Фото 8 Включить шардинг для коллекции книг .
И с этим, заколоченный кластер работает и работает! В следующем разделе мы рассмотрим команды, доступные специально для управления затененными развертываниями.
7. Разделение команд и помощников команд
Оболочка MongoDB предоставляет вспомогательные команды и контекстную переменную sh для упрощения управления и развертывания шардинга.
| команда | listShards | ||
| Описание | Выводит список настроенных шардов. Он должен быть запущен в контексте базы данных администратора . | ||
| пример | В оболочке MongoDB давайте выполним команду:
|
||
| Ссылка | http://docs.mongodb.org/manual/reference/command/listShards/ |
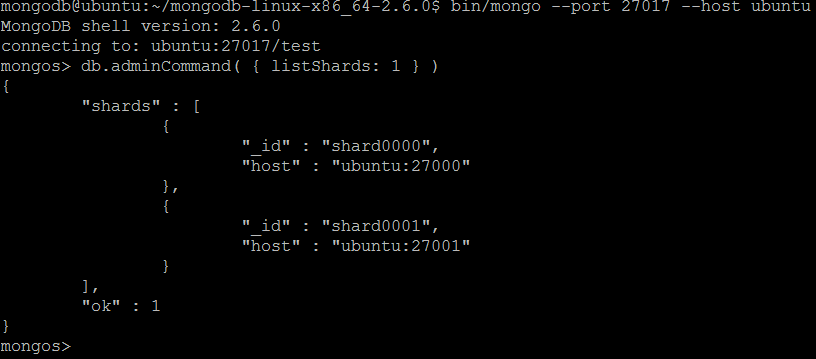
listShards
| команда | shardConnPoolStats | ||
| Описание | Сообщает статистику по пулированным и кэшированным соединениям в пуле защищенных соединений. | ||
| пример | В оболочке MongoDB давайте выполним команду:
|
||
| Ссылка | http://docs.mongodb.org/manual/reference/command/shardConnPoolStats/ |
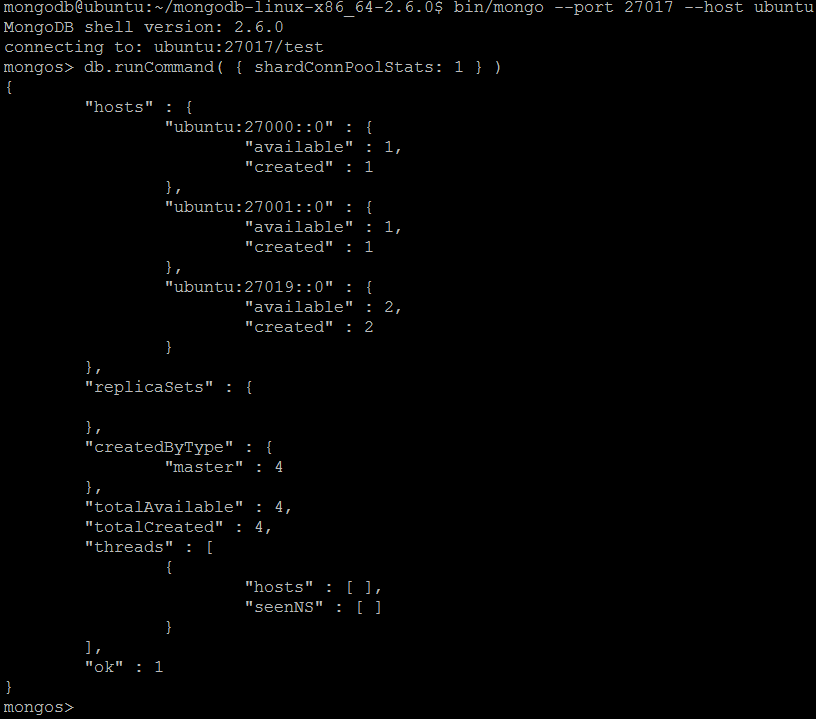
shardConnPoolStats
| команда | connPoolStats | ||
| Описание | Сообщает статистику о количестве открытых соединений с текущим экземпляром базы данных, включая клиентские соединения и межсерверные соединения для репликации и кластеризации. | ||
| пример | В оболочке MongoDB давайте выполним команду:
|
||
| Ссылка | http://docs.mongodb.org/manual/reference/command/connPoolStats/ |
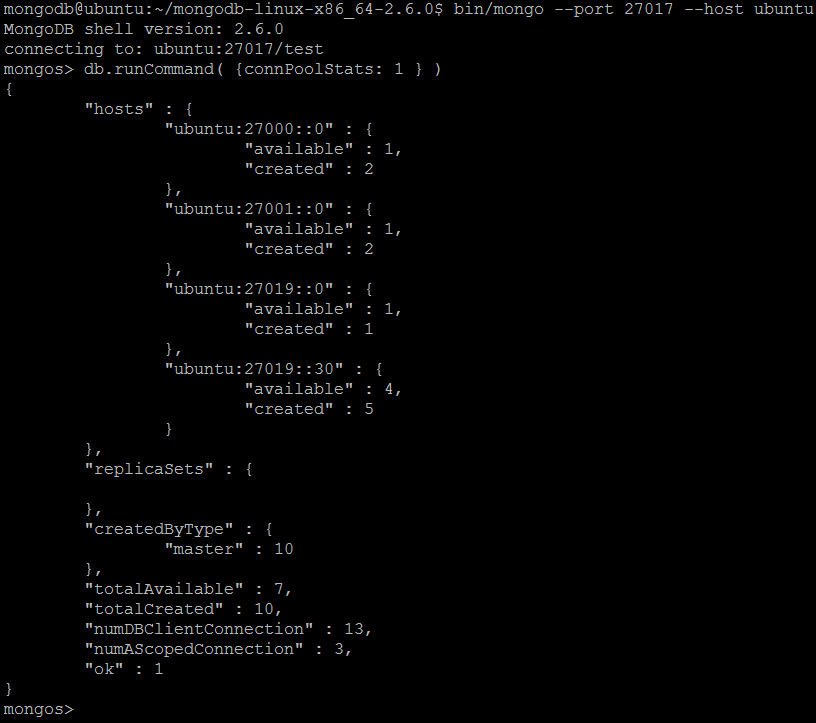
connPoolStats
| команда | isdbgrid | ||
| Описание | Эта команда проверяет, что оболочка MongoDB, к которой подключен процесс, является mongos . | ||
| пример | В оболочке MongoDB давайте выполним команду:
|
||
| Ссылка | http://docs.mongodb.org/manual/reference/command/isdbgrid/ |

isdbgrid
| команда | flushRouterConfig | ||
| Описание | Очищает текущую информацию о сегментированном кластере, кэшированную экземпляром Mongos, и перезагружает все метаданные из сегментированного кластера из базы данных конфигурации. Он должен быть выдан для экземпляра процесса mongos и запущен в контексте базы данных администратора . | ||
| пример | В оболочке MongoDB давайте выполним команду:
|
||
| Ссылка | http://docs.mongodb.org/manual/reference/command/flushRouterConfig/ |

flushRouterConfig
| команда | shardingState | ||||
| Описание | Сообщает, является ли текущий экземпляр сервера MongoDB членом изолированного кластера . Он должен быть запущен в контексте базы данных администратора . | ||||
| пример | Давайте подключимся к любому из автономных экземпляров сервера MongoDB с помощью оболочки MongoDB :
И выполните команду:
|
||||
| Ссылка | http://docs.mongodb.org/manual/reference/command/shardingState/ |
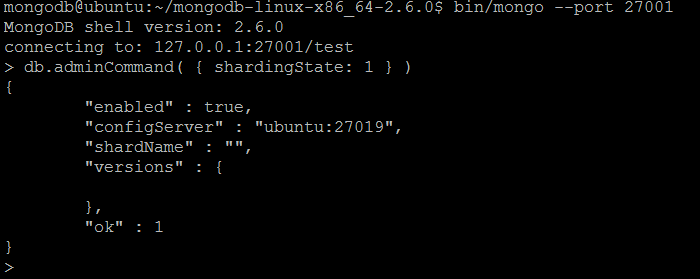
shardingState
| команда | movePrimary | ||
| параметры |
|
||
| Описание | Команда переназначает основной сегмент базы данных, в котором хранятся все неохраняемые коллекции в базе данных, другому фрагменту в кластере . Он должен быть выдан для экземпляра процесса mongos и запущен в контексте базы данных администратора . | ||
| пример | В оболочке MongoDB давайте выполним команду:
|
||
| Ссылка | http://docs.mongodb.org/manual/reference/command/movePrimary/ |

movePrimary
| команда | sh.help () | ||
| Описание | Выводит краткое описание для всех функций оболочки, связанных с sharding. | ||
| пример | В оболочке MongoDB давайте выполним команду:
|
||
| Ссылка | http://docs.mongodb.org/manual/reference/method/sh.help/ |
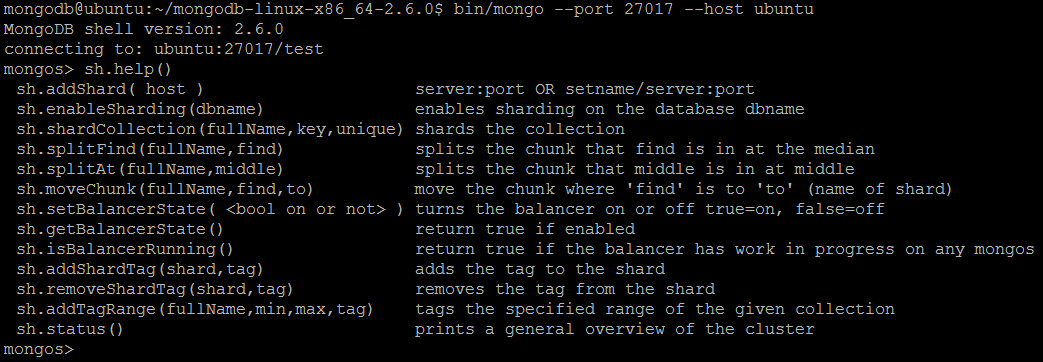
sh.help ()
| команда | addShard | ||
| параметры |
|
||
| обертка | sh.addShard (<хост>) | ||
| Описание | Команда добавляет либо экземпляр базы данных, либо набор реплик в сегментированный кластер . Должны быть проблемы с экземпляром процесса Mongos . | ||
| пример | См. Раздел « Конфигурирование защищенного кластера ». | ||
| Ссылка | http://docs.mongodb.org/manual/reference/command/addShard/
http://docs.mongodb.org/manual/reference/method/sh.addShard/ |
addShard
| команда | db.printShardingStatus () |
| Описание | Команда выводит отформатированный отчет о конфигурации сегментирования и информацию о существующих фрагментах в кластере с разделением . Поведение по умолчанию подавляет подробную информацию о чанках, если общее количество чанков больше или равно 20. |
| пример | См. Раздел « Конфигурирование защищенного кластера ». |
| Ссылка | http://docs.mongodb.org/manual/reference/method/sh.status/ |
db.printShardingStatus ()
sh.status ()
| команда | enableSharding | ||
| параметры |
|
||
| обертка | sh.enableSharding (база данных) | ||
| Описание | Включение шардинга в указанной базе данных. Он не разделяет автоматически какие-либо коллекции, но позволяет начинать проверку коллекций с помощью команды sh.shardCollection () . | ||
| пример | Пожалуйста, смотрите раздел Sharding баз данных и коллекций . | ||
| Ссылка | http://docs.mongodb.org/manual/reference/command/enableSharding/
http://docs.mongodb.org/manual/reference/method/sh.enableSharding/ |
enableSharding
| команда | shardCollection | ||
| параметры |
|
||
| обертка | sh.shardCollection (пространство имен, ключ, уникальный) | ||
| Описание | Команда разрешает использование шардинга для коллекции и позволяет MongoDB начать распределение данных между шардами . Перед выполнением этой команды необходимо включить разбиение на уровне базы данных с помощью команды sh.enableSharding () . | ||
| пример | Пожалуйста, смотрите раздел Sharding баз данных и коллекций . | ||
| Ссылка | http://docs.mongodb.org/manual/reference/command/shardCollection/
http://docs.mongodb.org/manual/reference/method/sh.shardCollection/ |
shardCollection
| команда | sh.getBalancerHost () | ||
| Описание | Команда возвращает имя монго, ответственного за процесс балансировки. | ||
| пример | В оболочке MongoDB давайте выполним команду:
|
||
| Ссылка | http://docs.mongodb.org/manual/reference/method/sh.getBalancerHost/ |

sh.getBalancerHost ()
| команда | sh.getBalancerState () | ||
| Описание | Команда возвращает true, если балансировщик включен, и false, если балансировщик отключен. | ||
| пример | В оболочке MongoDB давайте выполним команду:
|
||
| Ссылка | http://docs.mongodb.org/manual/reference/method/sh.getBalancerState/ |

sh.getBalancerState ()
| команда | sh.isBalancerRunning () | ||
| Описание | Команда возвращает истину, если процесс балансировки в данный момент выполняется и переносит чанки, и ложь, если процесс балансировки не запущен. | ||
| пример | В оболочке MongoDB давайте выполним команду:
|
||
| Ссылка | http://docs.mongodb.org/manual/reference/method/sh.isBalancerRunning/ |

sh.isBalancerRunning ()
| команда | setBalancerState (true | false) | ||
| Описание | Команда включает или отключает балансировщик в изолированном кластере . | ||
| пример | В оболочке MongoDB давайте выполним команду:
|
||
| Ссылка | http://docs.mongodb.org/manual/reference/method/sh.disableBalancing/ |

setBalancerState (true | false)
| команда | sh.startBalancer (тайм-аут, интервал) | ||
| Описание | Команда включает балансировщик в изолированном кластере и ожидает начала балансировки. | ||
| пример | В оболочке MongoDB давайте выполним команду:
|
||
| Ссылка | http://docs.mongodb.org/manual/reference/method/sh.startBalancer/ |

sh.startBalancer (тайм-аут, интервал)
| команда | sh.stopBalancer (тайм-аут, интервал) | ||
| Описание | Команда отключает балансировщик в изолированном кластере и ожидает завершения балансировки. | ||
| пример | В оболочке MongoDB давайте выполним команду:
|
||
| Ссылка | http://docs.mongodb.org/manual/reference/method/sh.stopBalancer/ |

sh.stopBalancer (тайм-аут, интервал)
| команда | дб. <коллекция> .getShardDistribution () | ||||
| Описание | Выводит статистику распределения данных для сегментированного набора в кластере с разделением . | ||||
| пример | В оболочке MongoDB давайте выполним команды:
|
||||
| Ссылка | http://docs.mongodb.org/manual/reference/method/db.collection.getShardDistribution/ |
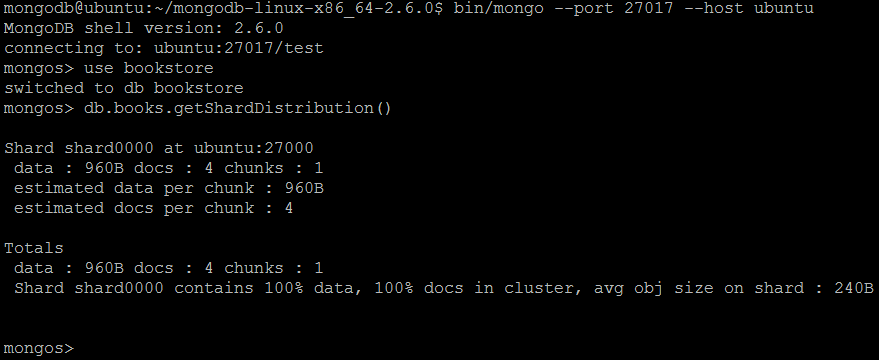
db..getShardDistribution ()
| команда | removeShard | ||
| параметры |
|
||
| Описание | Команда удаляет осколок из осколочного кластера . После запуска MongoDB перемещает куски осколка в другие осколки в кластере и только затем удаляет осколок . Он должен быть запущен в контексте базы данных администратора . | ||
| пример | В оболочке MongoDB давайте выполним команду:
|
||
| Ссылка | http://docs.mongodb.org/manual/reference/command/removeShard/ |
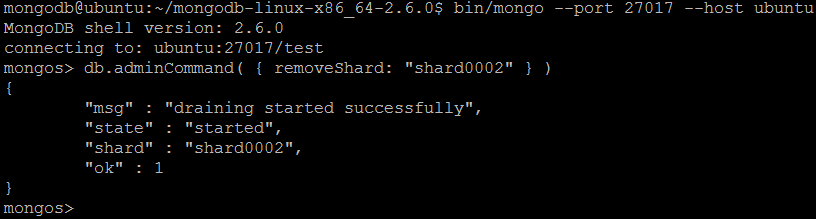
removeShard
| команда | mergeChunks | ||
| параметры |
|
||
| Описание | Команда объединяет два смежных фрагмента в одном и том же фрагменте. По крайней мере, один из чанка не должен иметь никаких документов. Команда должна быть введена для экземпляра mongos и запущена в контексте базы данных администратора . | ||
| Ссылка | http://docs.mongodb.org/manual/reference/command/mergeChunks/ |
mergeChunks
| команда | Трещина | ||
| параметры |
|
||
| обертка | sh.splitAt (пространство имен, запрос)
sh.splitFind (пространство имен, запрос) |
||
| Описание | Команда вручную разбивает фрагмент в сегментированном кластере на два фрагмента. Команда должна быть запущена в контексте базы данных администратора . | ||
| пример | В оболочке MongoDB давайте выполним команду:
db.adminCommand ({split: «bookstore.books», find: {«title»: «MongoDB в действии»}}) В качестве альтернативы, давайте запустим ту же команду, используя командную оболочку: sh.splitFind («bookstore.books», {«title»: «MongoDB в действии»}) |
||
| Ссылка | http://docs.mongodb.org/manual/reference/command/split/
http://docs.mongodb.org/manual/reference/method/sh.splitAt/ http://docs.mongodb.org/manual/reference/method/sh.splitFind/ |

Трещина
| команда | sh.moveChunk (пространство имен, запрос, имя шарда) | ||||||
| Описание | Команда перемещает чанк, содержащий документ, указанный в запросе, в другой сегмент с именем shard name . | ||||||
| пример | В оболочке MongoDB давайте выполним команды:
|
||||||
| Ссылка | http://docs.mongodb.org/manual/reference/method/sh.moveChunk/ |
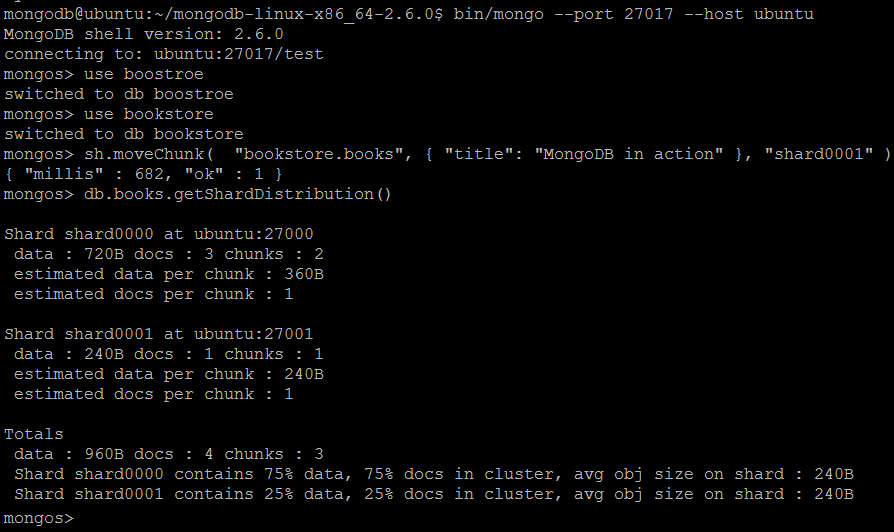
sh.moveChunk (пространство имен, запрос, имя шарда)
| команда | sh.addShardTag (осколок, метка) |
| Описание | Команда связывает осколок с тегом или идентификатором. MongoDB использует эти идентификаторы для направления фрагментов, попадающих в диапазон тегов, к конкретным фрагментам. |
| пример | Смотрите, пожалуйста, раздел Shard Tags . |
| Ссылка | http://docs.mongodb.org/manual/reference/method/sh.addShardTag/ |
sh.addShardTag (осколок, метка)
| команда | sh.addTagRange (пространство имен, минимум, максимум, тег) |
| Описание | Команда присоединяет диапазон значений ключа шарда к тегу шарда, созданному ранее с помощью команды sh.addShardTag () . |
| пример | Смотрите, пожалуйста, раздел Shard Tags . |
| Ссылка | http://docs.mongodb.org/manual/reference/method/sh.addTagRange/ |
sh.addTagRange (пространство имен, минимум, максимум, тег)
| команда | sh.removeShardTag (осколок, метка) |
| Описание | Команда удаляет связь между тегом и осколком. Команда должна быть выдана против экземпляра Mongos |
| пример | Смотрите, пожалуйста, раздел Shard Tags . |
| Ссылка | http://docs.mongodb.org/manual/reference/method/sh.removeShardTag/ |
sh.removeShardTag (осколок, метка)
8. Что дальше
В этой части мы рассмотрели основы возможностей сегментирования (разбиения) MongoDB . Для более полной и подробной информации, пожалуйста, обратитесь к официальной документации . В следующем разделе мы рассмотрим репликацию MongoDB .