Узел является сетевым сервером, а также Haboob. Разница заключается в модели параллелизма: узел основан на потоках, а Haboob основан на событиях [9]. Очевидно, что из результатов бенчмарка механизм poll () / epoll () является серьезным узким местом, как только число активных одновременно работающих клиентов становится релевантным (в конкретном случае у 16384 клиентов сбои хитов с трудом достигаются, и тест не может продолжаться) , Для ясности «предпочтительные соединения» и «одобрение принятия» — это две разные политики планирования потоков для сетевого сервера.
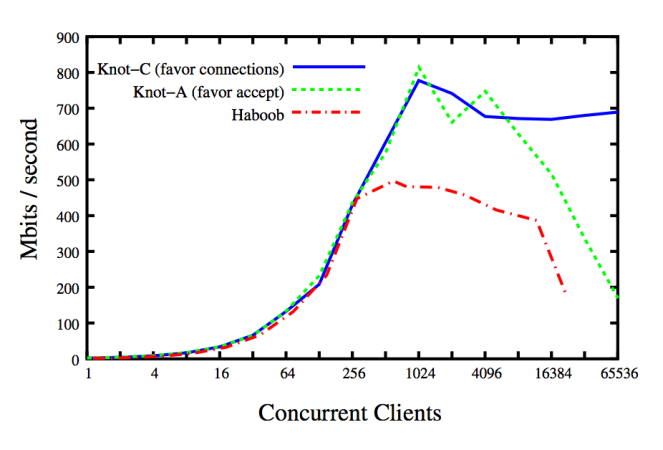
Эрик Брюер — ученый-компьютерщик из университета Беркли, который разработал знаменитую теорему CAP [15]. В серии статей он пытается демистифицировать и исправить неправильные представления о параллелизме на основе потоков и присущей ему масштабируемости. В частности, в двух основополагающих работах « Почему события — плохая идея » [9] и « Масштабируемые потоки для интернет-служб » [8] он сравнивает производительность масштабируемых серверов на основе событий и потоков, демонстрируя, что модель потоков масштабируется почти линейно с возможностями операционной системы (ОС): как только ОС получает противодавление от оборудования, происходит перегрузка, и это влияет на общую масштабируемость. Интересным является еще один момент: в 2003 году такая очистка происходила только тогда, когда сотни тысяч потоков имели дело с активными сетевыми подключениями. Интересно, нет?
Давайте рассмотрим несколько ресурсов из литературы, чтобы обсудить преимущества параллелизма на основе потоков, особенно в отношении современных аппаратных архитектур.
Таблетки истории
В этих случаях картинка стоит тысячи слов.
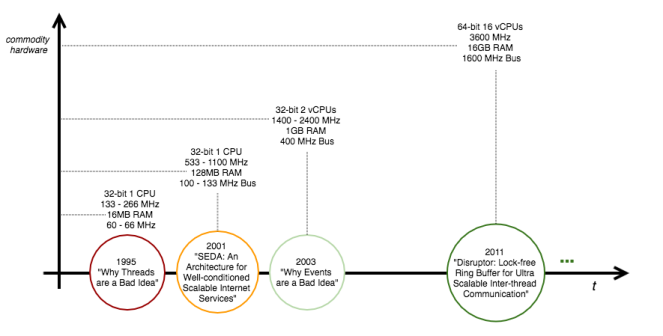
Аппаратное обеспечение ищется в [6] по шкале времени процессоров. Фактически, с улучшениями аппаратных средств, замеченными в эти последние годы, технологическая тенденция состояла в использовании аппаратного параллелизма с массивной многопоточностью. В настоящее время предпринимаются усилия в области неблокирующих и безблокирующих алгоритмов синхронизации и структур данных [7] для приложений, связанных с процессором. Примерами ультрамасштабируемых структур данных без блокировок являются LMAX Disruptor [16] ( 26 миллионов операций в секунду со средней задержкой 52 нс ) и Azul без блокировки Hashtable [17] (от 30 до 50 миллионов операций в секунду) ,
Несколько фактов
Несколько цифр от типичного обычного компьютера для сравнения его пределов по умолчанию с точки зрения памяти и потоков. В частности, интересно понять, на каком этапе процесса i. объем выделяемой виртуальной памяти и ii. размер стека на пользователя iii. максимальное количество процессов и, наконец, по системе iv. максимальное количество потоков.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
# linux kernel version[hailpam@jarvis ~]$ uname -r3.10.0-229.11.1.el7.x86_64# allocable virtual memory[hailpam@jarvis ~]$ ulimit -vunlimited# stack size[hailpam@jarvis ~]$ ulimit -s8192# maximum number of processes per user[hailpam@jarvis ~]$ ulimit -u4096# maximum number of threads[hailpam@jarvis ~]$ cat /proc/sys/kernel/threads-max 255977 |
В качестве примечания, версия 3.1 ядра Linux была выпущена в конце 2011 года. Из рисунков видно, что с точки зрения системы, процессов и пользователей в современной ОС Linux действительно нет никакого беспокойства по поводу количества потоков, выделяемых для масштабировать до тысяч активных соединений [8, 9], используя многоядерные возможности современных аппаратных архитектур.
Анатомия событий / Темы Дуализм
Когда речь заходит о разработке масштабируемых сетевых серверов для современных интернет-сервисов, всегда возникает один вопрос: достаточно ли масштабируем один поток на каждое соединение или должен быть принят неблокирующий ввод-вывод?
Модели на основе событий и потоков являются двойственными [1], это означает, что программа, разработанная с одной моделью, может быть напрямую сопоставлена с программой другой модели; обе модели логически эквивалентны, даже если они используют разные методы и конструкции; рабочие характеристики обеих моделей практически идентичны, так как методы планирования приняты для обеих из них.
Аргумент двойственности Лауэра и Нидхэма (конец 70-х) поднимает несколько интересных моментов, ставящих рядом события и потоки.
| События | Потоки |
| Обработчик события | монитор |
| Цикл событий | планирование |
| Типы событий, принятые обработчиком событий | Функции экспорта |
| Отправка ответа | Возвращаясь из процедуры |
| Отправка сообщения в ожидании ответа | Выполнение вызова процедуры блокировки |
| Ожидание сообщений переменных | Ожидание при условии |
Согласно аргументу двойственности, обе модели уступают одинаковым точкам блокировки при реализации эквивалентной логики. Сказано, что при сопоставимых условиях исполнения две модели должны иметь одинаковую производительность.
Параллелизм ввода-вывода и процессора
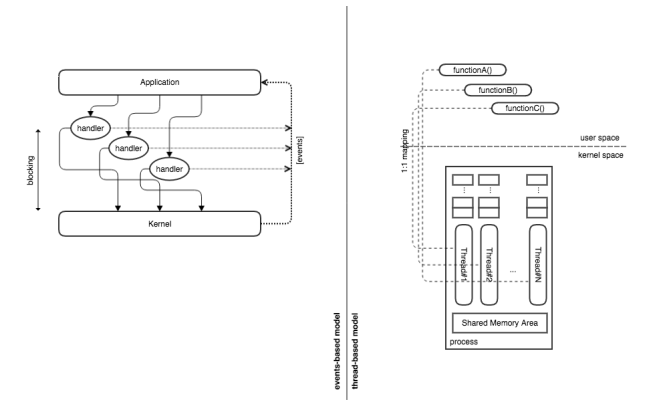
Когда дело доходит до операций ввода-вывода, могут быть приняты две основные модели: 1. блокирующая или 2. неблокирующая.
Модель блокировки основана на способности ОС выделять время ЦП другому процессу / потоку всякий раз, когда выполняется операция ввода-вывода: процесс / поток ввода-вывода приостанавливается, новый процесс / поток активируется, как только завершается ввод-вывод. выдается сигнал, чтобы разбудить приостановленный процесс / поток и заснуть фактическим активным. С другой стороны, неблокирующая модель основана на возможности приложения непрерывно опрашивать в цикле состояние операций ввода-вывода в рамках одного процесса / потока: статусы файловых дескрипторов непрерывно проверяются, и как только один из них получает новую буферизацию Для получения таких данных выдается дополнительный вызов. Интуитивно понятно, что стратегия опроса — это механизм, принятый ядром ОС для проверки состояния устройств; наличие такого механизма на уровне приложений выглядит интуитивно как своего рода тяжелое дублирование усилий.
ПРИМЕЧАНИЕ Построенные управляемые событиями архитектуры (SEDA) [12] способны сочетать два уровня параллелизма для превосходной производительности.
Об управлении задачами
Можно принять во внимание три основных метода: последовательный , кооперативный и упреждающий .
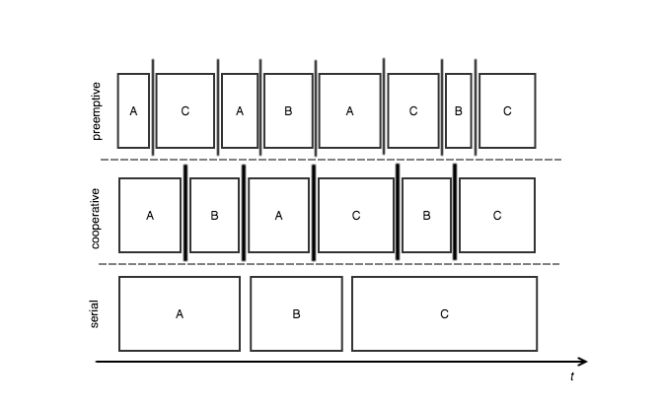
Серийный Самая простая техника: первым пришел, первым обслужен. Задачи выполняются в последовательности от начала до конца. Понятно, что нет чередования задач.
Кооператив . Задачи чередуются в соответствии с их собственными временными интервалами, это кооперативная модель выполнения задач, поскольку задачи распределяются по времени ЦП в соответствии с конкретными временными рамками выполнения: каждая задача может уступить время ЦП другой задаче с таким же приоритетом. Как уже было сказано, задачи чередуются, но шаблон отличается по сравнению с типичным упреждающим планированием.
Вытесняющий . Задачи не выполняются последовательно; они чередуются сигнальным механизмом, определяющим, когда задача способна выполнить новую единицу работы. Его можно легко связать с логикой планирования на основе приоритетов, поскольку механизм сигнализации может прерывать выполнение задач. В такой модели планировщик полностью контролирует стратегию перемежения, и по этой причине достигнутая пропускная способность может быть неоптимальной.
Ядро Linux принимает политику «Полностью честного планирования» (CFS) начиная с версии 2.6.3 [4]. Планировщик CFS максимизирует распределение времени ЦП, используя очередь выполнения, поддерживаемую Red-back Tree: опрос задач — операция O (1) , постановка задачи в очередь — операция O (log N), где N — фактическое количество задач. Такой планировщик использует приоритетное вытеснение: с установленным механизмом сигнализации Ядро может остановить выполнение задач, как только задачи с высоким приоритетом поступят в рабочую очередь, и справедливость будет достигнута.
Задача против управления стеком
Стек вызовов является фундаментальной концепцией в программировании, компиляторы принимают эту структуру данных, чтобы сохранить контекст обработки, входящий и выходящий из / в вызовы подпрограммы. С другой стороны, задачи являются неотъемлемой единицей работы для любой ОС, фактически даже процессы обрабатываются как много задач, которые должны быть запланированы на модулях ЦПУ планировщиком задач ядра.
Ясно, что стеки для процессов или потоков управляются ядром, которое заботится о переключении контекста путем подстановки и извлечения таких стеков, а также нескольких значений регистров ЦП, и параллелизм на основе потоков извлекает из этого выгоду. При программировании, управляемом событиями, параллелизм четко нацелен на использование одного потока опроса и выигрыша от параллелизма устройств ввода-вывода: все происходит в приложении, поэтому стек обработки для каждого класса событий должен явно управляться аппликативным кодом.
Проект, управляемый событиями, реализует форму совместного планирования задач: конкретная обработка обработчика является единицей работы, а оборот между обработчиками реализует поток планирования. С другой стороны, основанный на потоках проект реализует форму упреждающего планирования задач, в частности, такое планирование полностью связано с планированием ядра ОС.
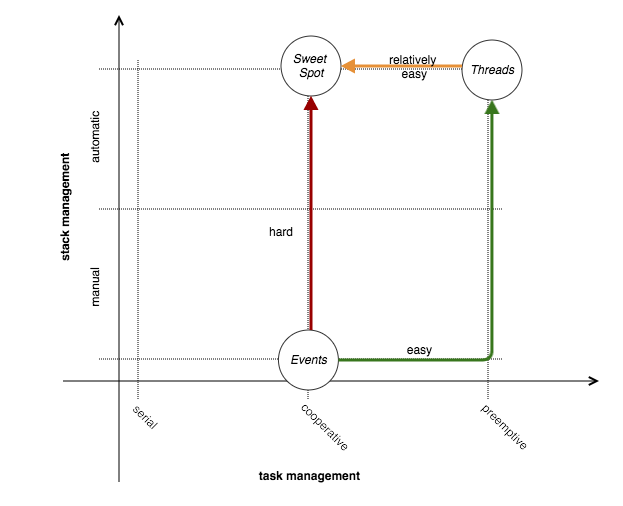
В [5] две модели анализируются с целью найти точку соприкосновения между двумя подходами: использование правильного сочетания параллелизма, основанного на потоках, в то же время имея дело с неблокирующим вводом-выводом, концепцией, обновленной Мэттом Уэлшем с его SEDA [12]. ]. В той же работе [5] подчеркиваются внутренние пределы сложности и масштабируемости чистого программирования, основанного на событиях, для работы с неблокирующим вводом-выводом, поэтому на приведенном выше рисунке трудный путь от «событий» к «сладкому пятну» ; гораздо лучше нацелиться на «сладкое пятно», движущееся из «ниток».
События внутренней сложности
Можно понять, что с событиями возникают три фундаментальные проблемы: инверсия управления, многоядерные процессоры и жизненные циклы слушателя [9].
Инверсия контроля
Феномен разрыва стека [5]: реконструкция стека в куче. Обратные вызовы идеальны для императивных языков программирования, которые не поддерживают / не обеспечивают замыкания, и поэтому асинхронные обратные вызовы представляют шаблон проектирования для ввода-вывода на основе событий: обратные вызовы регистрируются и вызываются всякий раз, когда интересующее событие всплывает. Обратные вызовы страдают от проблемы копирования стека, которая заключается в необходимости сохранения стека обработки вне стека: как только вызывается функция обратного вызова для продолжения операции ввода-вывода, контекст должен быть повторно активирован, чтобы последовательно возобновить любое предыдущие операции. Как ясно, контекст должен быть сохранен вне стека, потому что сама функция обратного вызова, как она есть, распределяется в стеке с ее фактическими параметрами: вызов без сохранения состояния, в стеке идет фактическое необходимое количество данных, которое обычно соответствует к фактическим значениям входных параметров. Контекст должен быть сохранен в куче и передан в качестве входного аргумента для обратного вызова. Эта модель критически сложна и неестественна: развертывание стека должно быть в состоянии вернуть любой контекст для текущих вычислений, что не относится к обратным вызовам из-за их природы, не связанной с процедурами обработки пространства и времени. Все дело в последовательном характере операций, которые разделяются на последовательные асинхронные подоперации с помощью подхода, основанного на событиях.
П р и м е ч а н и е — Замыкания уменьшают проблему разрыва стека, но, как интуитивно, не полностью в сложных сценариях.
Многоядерная обработка
Обработчики в цикле обработки событий должны выполняться последовательно, чтобы избежать искажения глобального состояния. Введение блокировки с событиями было бы невероятно сложно.
Жизненные циклы слушателя
Хендлеры живут пока не зарегистрированы. Если отмена регистрации не происходит, когда событие больше не может произойти, обработчик живет вечно без какого-либо смысла существовать: это утечка, как это происходит с управлением памятью.
Потоки внутренней простоты
Как видно, модель потока имеет внутреннюю простоту с технической точки зрения. Давайте рассмотрим несколько основных моментов.
Последовательное программирование
Потоки являются последовательными единицами исполнения по определению. Инструкции выполняются одна за другой при пассивации и повторной активации: любой алгоритм записывается как мысленный.
Автоматическое переключение контекста
Сигнализация на уровне ОС обрабатывает легкие и недорогие контекстные переключатели.
Поддержка компилятора и ОС
Последовательная модель памяти может быть оптимизирована компилятором. С другой стороны, ОС выполняет всю работу, связанную с этими облегченными процессами и распределением их ресурсов.
Нативные потоки POSIX Linux
В библиотеке LinuxThreads исторически возникали ошибки проектирования и проблемы соответствия стандарту POSIX. Библиотека в основном создавала потоки путем клонирования родительского процесса в новый работающий процесс; отсюда конкретные проблемы с немасштабируемой сигнализацией, тяжелыми контекстными переключателями, а также управлением PID. Целевая группа, состоящая из инженеров IBM и Red Hat, работала над решением указанных проблем и выпуском высокопроизводительной POSIX-совместимой версии библиотеки потоков. Начиная с версии 2.6 (конец 2003 г.) ядра Linux, библиотека NPTL была интегрирована, что дало в ядро превосходную масштабируемость в управлении потоками: были оптимизированы системные вызовы, такие как clone (), были введены системные вызовы, такие как tkill (), чтобы специально сигнализировать потоки. ID потока был введен как механизм для работы с легким идентификатором процесса, и были представлены примитивы блокировки на основе условий, такие как futex () . Помимо прочего, ядро Linux для тех же версий получило существенные улучшения для планирования процессов: был представлен новый планировщик с постоянным временем для упрощения интеграции NPTL, использующий превосходный уровень масштабируемости, обеспечиваемый упомянутыми системными вызовами.
Все обсуждаемые улучшения привели к оптимизированному и легкому переключению контекста между теперь правильно названными потоками, которые совместно используют память, а также всеми другими обработчиками. NPTL подтолкнул ядро Linux к почти нулевому управлению потоками , благодаря этому превосходные характеристики для приложений, таких как сетевые серверы, интенсивно использующие потоки.
Темы и блокировка ввода-вывода
Можно сказать, старые принципы дизайна, которые снова имеют смысл. С введением NPTL результаты Brewer имеют смысл даже в общем случае, поэтому для ОС Linux. Пол Тайма в [11] демонстрирует явный разрыв в производительности неблокирующих операций ввода-вывода по сравнению с блокирующими операциями ввода-вывода и многопоточностью: блокирование операций ввода-вывода в среднем оценивается на 25% быстрее, предлагая пропускную способность на 25% выше, как показано на рисунке ниже (кредиты для P Тима тоже).
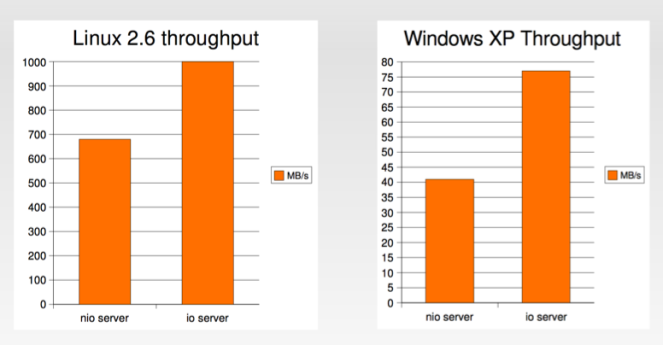
Логическое обоснование такой производительности заключается в накладных расходах на обработку событий: перестройка стека, работа с ним и обеспечение разнообразия — это факторы, которые на уровне приложений практически не влияют на производительность. Это вполне очевидно, если подумать об основном количестве системных вызовов, необходимых для простого извлечения данных из файловых дескрипторов (FD) (периодический опрос в списке FD и систематический поиск при появлении новых данных); и, как правило, приложения не являются «сопоставимой средой выполнения», если, с другой стороны, ядра ОС используются для того же.
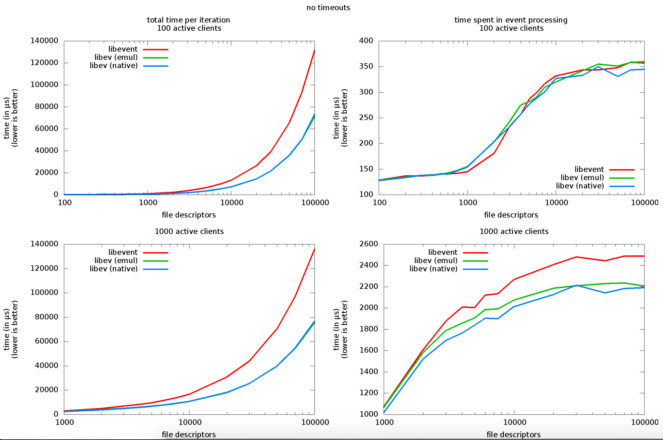
В интересном тесте libev (одной из лучших библиотек NIO для разработки на C / C ++) [13] подчеркиваются соответствующие накладные расходы, введенные библиотекой для работы с i. розетки, ii. наблюдатели событий и iii. активные клиенты: из 1000 FD и 100 активных клиентов накладные расходы на обработку событий очень важны (сотни микросекунд), а между 1000 и 10000 такие накладные расходы почти удваиваются, что едва ли соответствует характеристикам масштабируемости.
Оглядываясь назад на первоначальный результат, предложенный в [9], изображающий сервер на основе потоков, выполняющий сервер на основе событий, и перебрав кучу интересных концепций и технологий, в то же время обнаружив критические проблемы с программированием на основе событий, теперь все должно Имеет смысл и ясно, что можно с полным основанием сказать, что: для ультрамасштабируемых сетевых серверов необходимо достичь Sweet Spot, приняв такую сложную архитектуру SEDA, но для относительной превосходной производительности достаточно модели на основе потоков.
Вывод
В этом путешествии возникло несколько интересных вещей: события являются плохой идеей для современных аппаратных архитектур, если целью является масштабируемость на основе ОС, и ii. потоки стоят почти ноль с точки зрения ОС. Статьи и ссылки, на которые есть ссылки, помогли закрепить несколько концепций, часто являющихся источниками неправильных представлений.
Как на вынос, так и как итог повествования, взорванного до сих пор, можно сказать, что: параллелизм на основе событий сложен для меня. программа, ii. тест и iii. отслеживать общий поток управления, более того, это неестественный способ работы со стеком (см. Rack Stack Ripping [5]). На данный момент можно утверждать, что параллелизм на основе потоков трудно для меня. программа, ii. тест и iii. отслеживать общий поток управления, и это справедливое утверждение; Ясно, что по сравнению с параллелизмом на основе событий подход на основе потоков гораздо проще, и причина этого заключается в политиках, управляемых ОС, которые не нужно реплицировать на уровне приложений (гораздо меньше накладных расходов).
Более того, интуитивно понятный параллелизм на основе потоков естественным образом согласуется с современными многоядерными аппаратными архитектурами: просто обычный сервер с 48 виртуальными ЦП является огромной тратой, если по замыслу используется несколько потоков уровня ОС. Вы бы согласились?
использованная литература
[1] О двойственности структур операционной системы , http://cgi.di.uoa.gr/~mema/courses/mde518/papers/lauer78.pdf
[2] Threads Vs Event , Virginia Tech, http://courses.cs.vt.edu/cs5204/fall09-kafura/Presentations/Threads-VS-Events.pdf [3] Темы против событий , http://berb.github.io/diploma-thesis/original/043_threadsevents.html [4] Полностью честный планировщик , Википедия, https://en.wikipedia.org/wiki/Completely_Fair_Scheduler [5] Совместное управление задачами без ручного управления стеками, Usenix, http://www.stanford.edu/class/cs240/readings/usenix2002-fibers.pdf [6] Список микропроцессоров Intel , Википедия, https://en.wikipedia.org/wiki/List_of_Intel_microprocessors [7] Неблокирующие алгоритмы , Википедия, https://en.wikipedia.org/wiki/Non-blocking_algorithm [8] Capriccio: масштабируемые потоки для интернет-сервисов , Университет Беркли, http://capriccio.cs.berkeley.edu/pubs/capriccio-sosp-2003.pdf [9] Почему события плохая идея , Университет Беркли, http://capriccio.cs.berkeley.edu/pubs/threads-hotos-2003.pdf [10] Родные потоки POSIX Linux , черновой вариант, https://www.akkadia.org/drepper/nptl-design.pdf [11] Тысячи потоков и блокировка ввода-вывода, https://www.mailinator.com/tymaPaulMultithreaded.pdf [12] Построенная управляемая событиями архитектура для хорошо подготовленных интернет-сервисов , Стэнфордский университет, http://www.cs.cornell.edu/courses/cs614/2003sp/papers/Wel01.pdf [13] Тест Либева , http://libev.schmorp.de/bench.html [14] Почему темы — плохая идея , Стэнфордский университет, https://web.stanford.edu/~ouster/cgi-bin/papers/threads.pdf [15] Теорема CAP , Википедия, https://en.wikipedia.org/wiki/CAP_theorem [16] LMAX Disruptor , https://lmax-exchange.github.io/disruptor/ [17] Азул, без блокировки, Hashtable , http://www.azulsystems.com/events/javaone_2007/2007_LockFreeHash.pdf [18] Результаты работы LMAX Disruptor , https://github.com/LMAX-Exchange/disruptor/wiki/Performance-Results| Ссылка: | Масштабирование до тысяч тем от нашего партнера JCG Паоло Марески в блоге TheTechSolo . |