«Как это будет масштабироваться?»
Если вы работали над разработкой веб-приложений, вы слышали этот вопрос более одного раза. У вас есть отличная функция, которая отлично работает для нескольких тысяч клиентов, но как она работает для миллионов?
Проблемы масштабирования не просты, и не существует решений «один размер подходит всем», но мы можем взглянуть на некоторые из способов, которыми веб-бегемоты решили свои проблемы масштабирования, и получить несколько идей о том, как их решить. Мы можем даже узнать о удобном инструменте, который можно добавить в наш набор инструментов.
Большинство сложных проблем масштабирования в веб-приложениях может иметь элемент обработки, выполняемый в фоновом режиме. Например, если вы запускаете сайт знакомств, поиск новых совместимых совпадений для каждого из ваших клиентов может быть обработан в фоновом режиме. Нет необходимости пытаться сразу найти десять потенциальных партнеров для клиента, пока они ожидают загрузки страницы; вместо этого вы можете предоставить их им в следующий раз, когда они попадут на домашнюю страницу, уже выполнив всю необходимую обработку.
Преимущество возможности фонового процесса означает, что вы можете увеличить мощность машины, чтобы справиться с проблемой. Вы можете взять затруднительное положение, например найти родственную душу человека, и распределить его по кластеру машин, которые жуют кусочки, а затем возвращают нужные вам результаты.
Массовая обработка фона — это именно то, как большие пушки, такие как Facebook и Google, решили свои проблемы с масштабируемостью. Результаты Google получены из огромных готовых индексов, созданных с помощью фоновых заданий; он определенно не выполняет поиск по всей сети в тот момент, когда вы нажимаете кнопку поиска.
Один шаблон проектирования, которым пользуются и Google, и Facebook, — это возможность распределять вычисления между большими кластерами машин, которые имеют общий источник данных. Шаблон называется Map / Reduce, и Hadoop — это реализация с открытым исходным кодом. Эта статья представляет собой введение в Hadoop. Даже если в настоящее время у вас нет серьезных проблем с масштабированием, возможно, стоит ознакомиться с Map / Reduce как с концепцией, и игра с Hadoop — хороший способ сделать это.
Требования
Hadoop работает в оболочке типа Unix. Если вы используете Linux или Mac OS X, у вас все готово, но если вы работаете в Windows, самый простой способ подойти — запустить Linux на виртуальной машине. Для получения инструкций по настройке с использованием бесплатного программного обеспечения для виртуализации VirtualBox ознакомьтесь с данным руководством по SitePoint . Также возможно запустить Hadoop под Windows, используя эмулятор оболочки Cygwin .
Вам нужно будет установить SSH. В OS X SSH устанавливается по умолчанию, в то время как в Linux его установка так же проста, как получение его из диспетчера пакетов. Например, в Ubuntu:
$ sudo apt-get install ssh Далее вам нужно будет иметь возможность SSH подключаться к вашему локальному хосту без ключевой фразы. В OS X сначала нужно включить удаленный доступ. Перейдите в « Системные настройки» > « Общий доступ» и установите флажок « Удаленный вход в систему» . Чтобы проверить SSH, попробуйте выполнить эту команду:
$ ssh localhost
Если вас попросят ввести ключевую фразу, вам нужно будет выполнить эти команды, чтобы сгенерировать ключ для SSH без пароля:
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
Наконец, вам нужно установить Java. Часто это уже так; в противном случае отправляйтесь на Java.com и возьмите его.
Представляем карту / уменьшить
Что именно такое Map / Reduce? Основная идея Map / Reduce — распределенная обработка. У вас есть кластер машин, на котором размещена общая файловая система, в которой хранятся данные, и вы можете управлять распределенными заданиями.
Процессы, проходящие через кластер, называются заданиями. Эти задания имеют две фазы: фаза карты, на которой собираются данные, и фаза сокращения, где данные обрабатываются для создания окончательного набора результатов.
Давайте возьмем пример поиска родственной души на сайте знакомств. Все профили для миллионов пользователей хранятся в общей файловой системе, которая распределена по кластеру машин.
Мы отправляем работу в кластер с шаблоном профиля, который мы ищем. На этапе карты кластер находит все профили, которые соответствуют нашим требованиям. На этапе сокращения эти профили сортируются, чтобы найти лучшие совпадения, среди которых возвращаются только первые десять.
Hadoop — это структура Map / Reduce, которая разбита на две большие части. Первая — это файловая система Hadoop (HDFS). Это распределенная файловая система, написанная на Java, которая работает так же, как стандартная файловая система Unix. В довершение всего этого — система выполнения заданий Hadoop. Эта система координирует задания, расставляет приоритеты и отслеживает их, а также предоставляет структуру, которую вы можете использовать для разработки собственных типов работ. Он даже имеет удобную веб-страницу, где вы можете следить за ходом вашей работы.
На высоком уровне кластерная система Hadoop выглядит как на рисунке 1 «Кластерная архитектура Hadoop» .
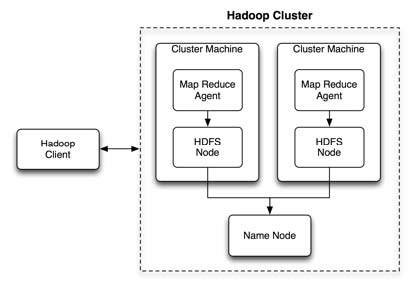
Клиенты подключаются к кластеру и отправляют задания. Эти задания затем отправляются агентам MapReduce, которые обрабатывают задания для данных в локальной части файловой системы HDFS. Все узлы HDFS обращаются к NameNode, чтобы зарегистрироваться в кластере.
Теперь, если вы посмотрите на все это и скажете: «Все хорошо, но это Java, и мы используем .NET», вам не о чем беспокоиться. Hadoop — это платформа, и вы можете привлекать клиентов к этой платформе на любом языке, который вам нужен. А поскольку Hadoop настолько хорош в качестве платформы распределенной обработки, он получает поддержку на всех языках.
В дополнение к ядру Hadoop я собираюсь представить систему Hive. Hive — это распределенная база данных SQL, которая располагается поверх Hadoop и HDFS. Есть три причины, почему стоит знать о Hive. Во-первых, потому что это значительно упрощает использование Hadoop и представляет его как технологию, которую вы можете использовать в своих проектах сегодня. Во-вторых, поскольку он использует SQL, технология, с которой большинство пользователей знакомо. В-третьих, потому что он используется Facebook для производства, а это значит, что он надежный, стабильный и в хорошем состоянии.
С Hadoop и Hive вы сможете размещать базы данных, которые содержат миллиарды записей, и выполнять запросы к ним (которые реализованы как задания Hadoop) в течение разумного времени. Это время будет регулироваться путем изменения размеров и рабочих характеристик машин в кластере.
Просто пару слов, чтобы вы успокоились по поводу всей проблемы кластера. Hadoop позволяет обслуживать и развертывать кластер машин, но для работы с ним нет необходимости иметь кластер машин. На самом деле подойдет любая старая одиночная машина. Вы можете запускать HDFS, Hadoop и Hive локально, и все работает отлично.
Давайте теперь углубимся в каждую из технологий.
Установка и настройка Hadoop
Перейдите на страницу релизов Hadoop и загрузите стабильную версию Hadoop . Релиз Hadoop включает в себя как среду выполнения заданий, так и встроенную систему HDFS. Распакуйте архив в каталог в вашей файловой системе и перейдите в него. В целях данного руководства мы будем запускать Hadoop в так называемом «псевдораспределенном режиме». То есть Hadoop будет моделировать распределенный кластер, запуская каждый узел в отдельном Java-процессе. Чтобы настроить Hadoop для этого режима, нам нужно отредактировать три файла конфигурации, каждый из которых находится в каталоге conf .
Просто замените элемент конфигурации в каждом файле следующей информацией:
Пример 1. conf/core-site.xml
<конфигурация> <свойство> <имя> fs.default.name </ name> <значение> hdfs: // localhost: 9000 </ value> </ property> </ configuration>
Пример 2. conf/hdfs-site.xml
<конфигурация> <свойство> <имя> dfs.replication </ name> <значение> 1 </ value> </ property> </ configuration>
Пример 3. mapred-site.xml
<configuration> <property> <name> mapred.job.tracker </ name> <value> localhost: 9001 </ value> </ property> </ configuration>
Другой требуемый параметр конфигурации находится в файле conf/hadoop-env.sh . Откройте этот файл и установите JAVA_HOME, чтобы он указывал на корень вашей установки Java. Например, в Mac OS X:
Пример 4. conf/hadoop-env.sh (отрывок)
export JAVA_HOME = / Система / Библиотека / Каркасы / JavaVM.framework / Home
Имея все это, вы сможете запустить следующую команду из каталога Hadoop:
$ bin/hadoop version Hadoop 0.20.2Subversion https://svn.apache.org/repos/asf/hadoop/common/branches/branch-0.20 -r 911707Compiled by chrisdo on Fri Feb 19 08:07:34 UTC 2010
Файловая система Hadoop (HDFS)
HDFS — ценный ресурс сам по себе. С HDFS вы можете взять набор обычных компьютеров и создать единую федеративную файловую систему. Если требуется больше дискового пространства, вы можете либо добавить больше машин, либо добавить больше дисков на каждую машину, либо и то и другое.
Вы можете получить доступ к вашей HDFS несколькими способами. Существует API, который ваши программы могут использовать для подключения к файловой системе и извлечения, добавления, удаления или обновления файлов и каталогов. Также можно использовать интерфейс командной строки, а также веб-интерфейс для просмотра каталогов и доступа к файлам. Есть даже реализация Fuse ( MountableHDFS ), где вы можете монтировать файлы прямо на рабочем столе.
В установке HDFS есть два основных элемента. Одним из них является сервер NameNode. Это процесс с одним сервером, который расположен на одном компьютере. Каждый из компьютеров HDFS подключается к серверу NameNode, чтобы координировать свою идентификацию и управлять своей частью файловой системы.
Другим элементом является узел HDFS, работающий на каждой машине. Он обрабатывает хранение данных на этом конкретном компьютере и подключение к NameNode.
Для начала давайте отформатируем NameNode:
$ bin/hadoop namenode -format
Теперь мы запустим все демоны Hadoop (включая узел имен HDFS и узел данных, а также отслеживатели заданий и заданий Hadoop):
$ bin/start-all.sh
Теперь, когда все готово , вы сможете выполнять команды файловой системы, используя исполняемый файл hadoop . Например:
$ bin/hadoop fs -ls hdfs:/ Found 1 items drwxr-xr-x - jherr supergroup 0 2010-06-25 15:10 /tmp
Параметр -fs (имеется в виду файловая система) имеет много команд, включая обычные ls , mv , rm , tail , head и так далее. Существуют также команды для перемещения файлов в файловую систему HDFS из локальной файловой системы, moveToLocal и наоборот, moveFromLocal .
Мы можем добавить файл в файловую систему следующим образом:
$ bin / hadoop fs -put test.xml hdfs: / $ bin / hadoop fs -ls hdfs: / Found 2 items-rw-r - r-- 1 jherr supergroup 17 2010-06-25 15:13 / test. xmldrwxr-xr-x - супергруппа jherr 0 2010-06-25 15:10 / tmp
Вы также можете просмотреть эту файловую систему в своем браузере. Перейдите по http://localhost:50070 , который является панелью вашего NameNode. Нажмите на ссылку Обзор файловой системы, и вы увидите свою файловую систему, как показано на рисунке 2, «HDFS в браузере» .
Рисунок 2. HDFS в браузере
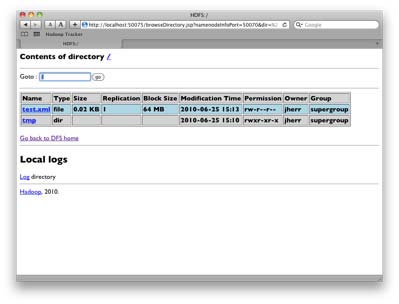
Как видите, распределенная файловая система, основанная на Java, которая работает в Unix, Windows и Mac, а также работает на обычном оборудовании, является ценным ресурсом сама по себе. Сказав это, стоит отметить, что HDFS не предлагает панацею. Это довольно неэффективно по времени для произвольного доступа и при хранении большого количества маленьких файлов. HDFS оптимизирована для ее главной цели, которая заключается в предоставлении общего хранилища данных для заданий Hadoop. Если вы ищете расширяемую файловую систему для изображений, HTML-файлов и т. П., Вы можете взглянуть на NFS или использовать размещенную систему, такую как Amazon S3.
Настройка и запуск Hadoop
Теперь, когда базовая HDFS настроена и запущена, пришло время сделать то же самое для частей Hadoop JobTracker и MapReduce.
Если JobTracker работает, вы должны быть в состоянии перейти к порту 50030 на машине, на которой запущен трекер. Панель инструментов показана на рисунке 3, «Hadoop JobTracker» .
Рисунок 3. Hadoop JobTracker
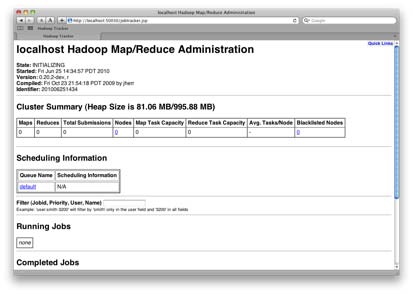
С запущенным JobTracker и настроенной HDFS вы готовы установить Hive и по-настоящему поработать с распределенным SQL.
Настройка Улей
Hive находится на вершине Hadoop, поэтому, как только ваш кластер настроен, для Hive все в порядке. Процесс начинается с загрузки и установки Hive . Вам нужно извлечь Hive из репозитория Subversion и скомпилировать его с помощью ant , как описано в этом документе.
После установки и настройки переменных среды Hive вы можете запустить клиент командной строки Hive следующим образом:
$ ./bin/hiveHive history file=/tmp/jherr/hive_job_log_jherr_201006251643_880032913.txthive> show tables;OK Time taken: 5.508 secondshive>OK Time taken: 5.508 secondshive>
Команда show tables показывает, что в настоящее время в распределенной базе данных нет таблиц. Отсюда вы можете следовать инструкциям на странице « Начало работы», чтобы добавить большую базу данных фильмов в установку Hive .
Эта база данных является хорошей отправной точкой для экспериментов с запросами и для просмотра того, как Hive создает задания Hadoop на лету для удовлетворения запроса. Возьмем, к примеру, очень простой запрос к базе данных фильмов, как показано ниже:
hive> SELECT movieid, AVG( rating ) FROM u_data GROUP BY movieid;Total MapReduce jobs = 1 ... Starting Job = job_201006251641_0002, Tracking URL = http://localhost: 50030/jobdetails.jsp?jobid=job_201006251641_0002 Kill Command = /Users/jherr/hadoop/bin/../bin/hadoop job - Dmapred.job.tracker=localhost:8021 -kill job_201006251641_0002 2010-06-25 04:51:40,648 map = 0%, reduce =0% ... 2010-06-25 04:52:04,895 map = 100%, reduce =100% Ended Job = job_201006251641_0002 OK 1 3.8783185840707963 2 3.2061068702290076 ... 1682 3.0 Time taken: 29.449 secondshive>Total MapReduce jobs = 1 ... Starting Job = job_201006251641_0002, Tracking URL = http://localhost: 50030/jobdetails.jsp?jobid=job_201006251641_0002 Kill Command = /Users/jherr/hadoop/bin/../bin/hadoop job - Dmapred.job.tracker=localhost:8021 -kill job_201006251641_0002 2010-06-25 04:51:40,648 map = 0%, reduce =0% ... 2010-06-25 04:52:04,895 map = 100%, reduce =100% Ended Job = job_201006251641_0002 OK 1 3.8783185840707963 2 3.2061068702290076 ... 1682 3.0 Time taken: 29.449 secondshive>
Я удалил некоторые детали, но вы можете увидеть общий ход. Клиент Hive создает задание для удовлетворения запроса, который можно отслеживать из веб-приложения JobTracker. Затем клиент Hive отслеживает задание и выдает результирующий набор.
Вы можете увидеть пример страницы задания, когда она будет завершена на рисунке 4 «Завершенная работа» .
Рисунок 4. Завершенная работа
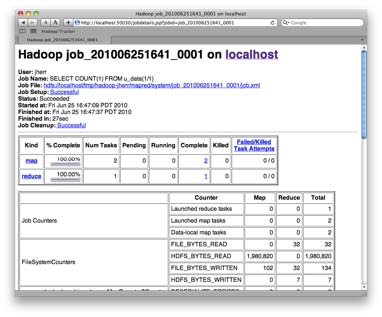
Внизу страницы есть даже классный графический раздел, который показывает прогресс узлов кластера Hadoop по мере того, как они отображают все данные, а затем сокращают их до ожидаемых результатов запроса. Это показано на рисунке 5, «График состояния задания» .
Рисунок 5. График статуса работы
На практике вы можете использовать клиент командной строки для подключения к Hive или к одному из драйверов, например HiveODBC. Кроме того, вы можете предоставить свой собственный код в Hive для добавления пользовательских функций запросов и фильтрации, которые затем распределяются по кластеру. Очень полезное руководство Hive Getting Started показывает пример этого на Python.
Куда идти дальше
Важно отметить, что есть несколько способов использовать Hadoop; Hive — это всего лишь один инструмент, который использует ресурсы Hadoop. Есть много проектов, которые используют Hadoop инновационными способами, такими как:
-
Pig — мощный язык потоков данных, основанный на платформе Hadoop
-
HBase — похож на Hive, но с большей склонностью к постоянству объекта
-
Hypertable — высокопроизводительная распределенная система хранения объектов
-
ZooKeeper — простая в использовании распределенная система управления процессами на основе Hadoop
Конечно, вы также можете разработать свой собственный проект для использования распределенной мощности Hadoop и HDFS.
Hadoop — это решение ваших проблем с масштабированием сегодня, а также платформа для разработки ваших собственных масштабируемых решений в будущем. Это хорошо написанное и документированное решение с открытым исходным кодом и очень популярное. Существует даже несколько книг по Hadoop, которые могут дать вам более глубокое представление об этой технологии.
В конечном счете, Hadoop — это новая технология, с которой вам следует ознакомиться, поскольку она, скорее всего, пригодится для ваших будущих проектов.