В экосистеме больших данных всегда есть новый выбор, когда дело доходит до аналитики и науки о данных. Апач инкубирует так много проектов, что люди всегда смущаются тем, как выбрать подходящий экосистемный проект. В конвейере данных науки, специальный запрос является важным аспектом, который дает пользователям возможность выполнять различные запросы, которые приведут к исследовательской статистике, которая поможет им понять свои данные. На самом деле, для многих компаний и практик Hive по-прежнему остается их рабочей лошадкой. Столь же древний, как Улей, разные группы могут взломать его по-разному, чтобы его было удобно использовать; Тем не менее, я слышал много жалоб, что запрос никогда не может закончить. Потеря времени ожидания при выполнении запроса и корректировка результатов запроса может замедлить темпы открытия науки о данных.
Лично мне нравится использовать Spark для выполнения специальных запросов по сравнению с программой Hive Map-Reduce, в основном из-за легкости выполнения других действий в Spark одновременно. Мне не нужно переключаться между разными инструментами. Недавно я также посмотрел на Alluxio, которая является распределенной файловой системой в памяти. В этой статье я продемонстрирую примеры, в которых используются SparkSQL, Parquet и Alluxio для ускорения специальной обработки запросов. При использовании Spark для ускорения запросов ключевым моментом является локальность данных.
Установите Alluxio с MapR
Сначала мы начнем с существующей системы MapR 5.1, работающей на экземпляре AWS с 3 узлами (m4.2xlarge). Мы загружаем Alluxio с Github и компилируем с артефактами Mapr5.1.
|
1
2
3
4
|
git clone git://github.com/alluxio/alluxio.gitcd alluxiogit checkout v1.2.0mvn clean package -Dhadoop.version=2.7.0-mapr-1602 -Pspark -DskipTests |
Oracle Java 8 используется для компиляции Alluxio, и это также та же версия Java, на которой работает система MapR. Однако для запуска веб-интерфейса Alluxio необходимо временно вернуться к Java 7. Мы также внесли несколько изменений в конфигурацию, добавив alluxio-env.sh:
|
1
2
3
4
5
|
ALLUXIO_MASTER_HOSTNAME=${ALLUXIO_MASTER_HOSTNAME:-"node1 host name"}ALLUXIO_WORKER_MEMORY_SIZE=${ALLUXIO_WORKER_MEMORY_SIZE:-"5120MB"}ALLUXIO_RAM_FOLDER=${ALLUXIO_RAM_FOLDER:-"/mnt/ramdisk"}ALLUXIO_UNDERFS_ADDRESS=${ALLUXIO_UNDERFS_ADDRESS:- "/mapr/clustername/tmp/underFSStorage"}ALLUXIO_JAVA_OPTS+=" - Dalluxio.master.journal.folder=/mapr/clustername/tmp/journal" |
Эти конфигурации будут помещены в хранилище файлов Alluxio в файловой системе MapR, а также в главный журнал, а также будут установлены 5 ГБ памяти для файлов рабочих наборов Alluxio. Мы даже можем настроить выделенный том в MapR-FS для использования в качестве файловой системы для Alluxio. Мы также можем добавить рабочий файл с именем хоста 3-х узлов, на которых планировалось запустить работники Alluxio.
|
1
2
3
|
node1node2node3 |
Таким образом, на вершине нашего 3-узлового кластера MapR у нас есть архитектура Alluxio с мастером, работающим на узле 1, и работниками, работающими на узле 1, узле 2 и узле 3. Вам просто нужно запустить несколько команд, чтобы запустить Alluxio; тогда вы сможете получить доступ к веб-интерфейсу на узле 1: 19999
|
1
2
3
4
|
clush -ac /opt/mapr/alluxio/confcd /opt/mapr/alluxio/ bin/alluxio formatbin/alluxio-start.sh all |
Подготовьте данные
Для сравнения мы также собираем кластер Cloudera с 4 узлами (m4.2xlarge) с CDH-5.8.0 и размещаем Alluxio на его 3 узлах данных с той же архитектурой. Мы запустили отдельную оболочку Spark на обоих кластерах с spark-master на узле 1 и 3 рабочими с 10 ГБ памяти на узлах [1-3]. Мы будем использовать данные прогноза рейтинга кликов из Kaggle в качестве примера данных, над которыми мы будем работать. Размер данных выборки составляет 5,9 ГБ, что содержит более 40 миллионов строк. Для запуска оболочки Spark мы используем:
|
1
|
spark-shell --master spark://node1:7077 --executor-memory 2G --packages com.databricks:spark-csv_2.1:0:1.4.0 |
В оболочке Spark мы загружаем csv из maprfs и hdfs по их пути:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
val trainSchema = StructType(Array( StructField("id", StringType, false), StructField("click", IntegerType, true), StructField("hour", IntegerType, true), StructField("C1", IntegerType, true), StructField("banner_pos", IntegerType, true), StructField("site_id", StringType, true), StructField("site_domain", StringType, true), StructField("site_category", StringType, true), StructField("app_id", StringType, true), StructField("app_domain", StringType, true), StructField("app_category", StringType, true), StructField("device_id", StringType, true), StructField("device_ip", StringType, true), StructField("device_model", StringType, true), StructField("device_type", IntegerType, true), StructField("device_conn_type", IntegerType, true), StructField("C14", IntegerType, true), StructField("C15", IntegerType, true), StructField("C16", IntegerType, true), StructField("C17", IntegerType, true), StructField("C18", IntegerType, true), StructField("C19", IntegerType, true), StructField("C20", IntegerType, true), StructField("C21", IntegerType, true)))val train = sqlContext.read.format("com.databricks.spark.csv") .option("header", "true") .schema(trainSchema) .load(trainPath) |
Затем мы записываем файл три раза для генерации необходимых нам данных: 1) запись в Alluxio в формате csv, 2) запись в Alluxio в формате Parquet, и 3) запись в HDFS / MapR-FS в формате Parquet, поскольку формат CSV уже существует на HDFS / MapR-FS.
|
1
2
3
4
5
6
|
train.write.parquet("maprfs:///tmp/train_parquet")train.write.parquet("alluxio://node1:19998/train_parquet")train.write .format("com.databricks.spark.csv") .option("header", "true") .save("alluxio://node:19998/train_crt") |
Когда мы посмотрим на размер файла, мы увидим, что файл Parquet является более эффективным по размеру. 5,9 ГБ данных CSV сжимаются до размера менее 1 ГБ.
Запустите SparkSQL на горячих данных
Теперь пришло время читать данные и отслеживать различные показатели. Я покажу, как Parquet может повысить производительность запросов и когда полезно использовать Alluxio. Прежде чем читать какие-либо файлы, мы удалим кэш ОС, чтобы получить более точное измерение.
|
1
|
clush -a "sudo sh -c 'free && sync && echo 3 > /proc/sys/vm/drop_caches && free'" |
CSV FILES |
PARQUET FILES |
|
Cloudera |
textFile/csv reader |
Parquet reader |
MapR |
textFile/csv reader |
Parquet reader |
Мы можем зафиксировать время выполнения через пользовательский интерфейс Spark, но мы также можем написать небольшой фрагмент Scala для этого:
|
1
2
3
4
|
val start_time=System.nanoTime()train.count \\or some other operationsval end_time = System.nanoTime()println("Time elapsed: " + (end_time-start_time)/1000000 + " milliseconds") |
Сначала мы читаем данные CSV в RDD с помощью textFile () в Spark и делаем простой подсчет файла CSV. Вы можете заметить одну странную вещь: кэшированный RDD оказывается медленнее. Я хочу подчеркнуть это, поскольку RDD не сильно сжимается при кэшировании в Spark. Например, DataFrame / набор данных сжимается намного эффективнее в Spark. Следовательно, с нашей ограниченной выделенной памятью, мы на самом деле можем кэшировать только 15% данных, что составляет лишь часть целого. Поэтому, когда мы пытаемся выполнить запрос в кэшированном Spark RDD, мы хотим убедиться, что исполнителю выделено достаточно памяти.
Cloudera |
MapR |
|
TextFile |
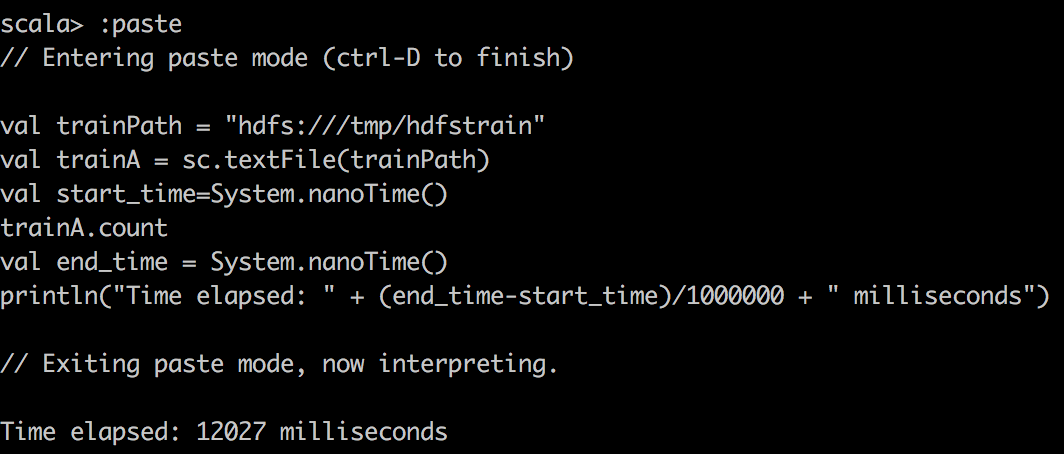 |
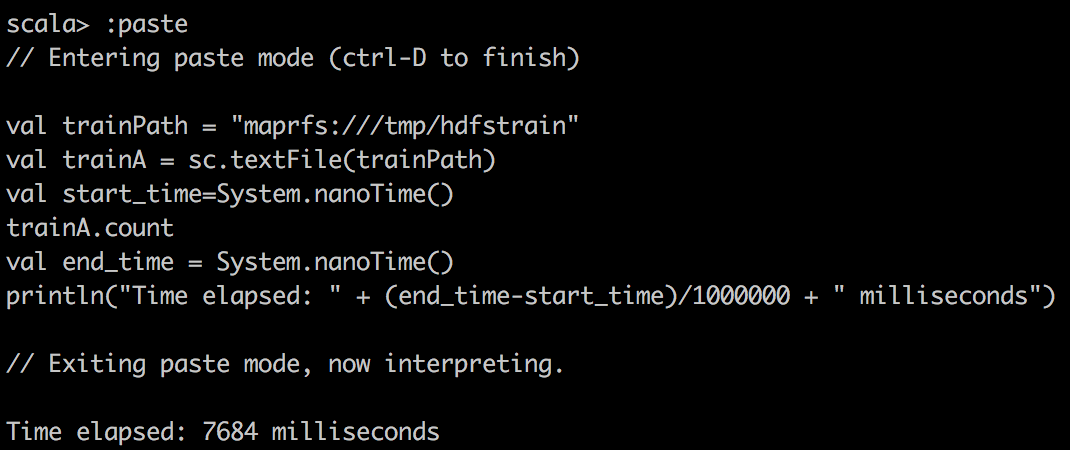 |
TextFile reading Alluxio |
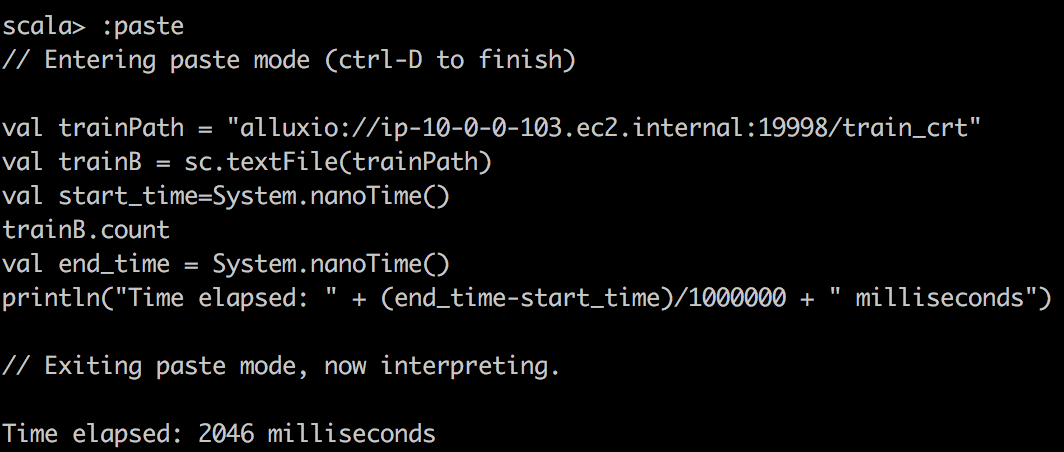 |
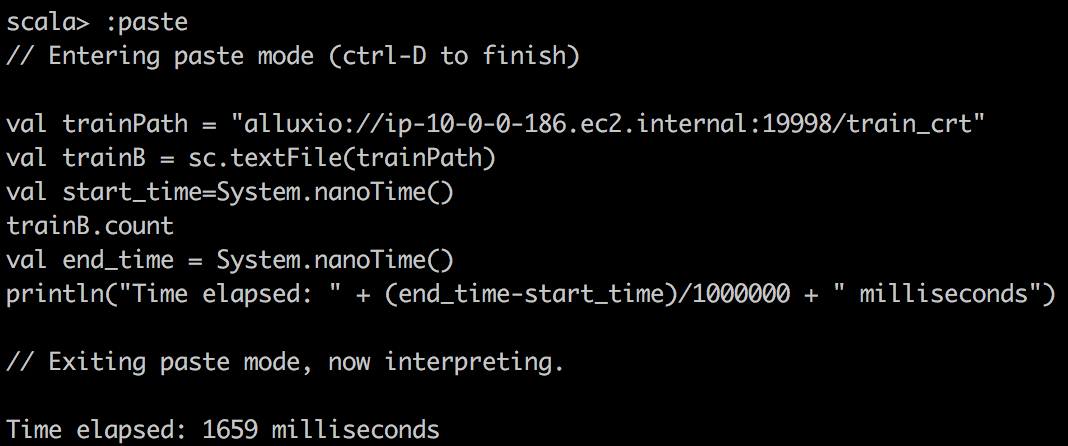 |
TextFile cached |
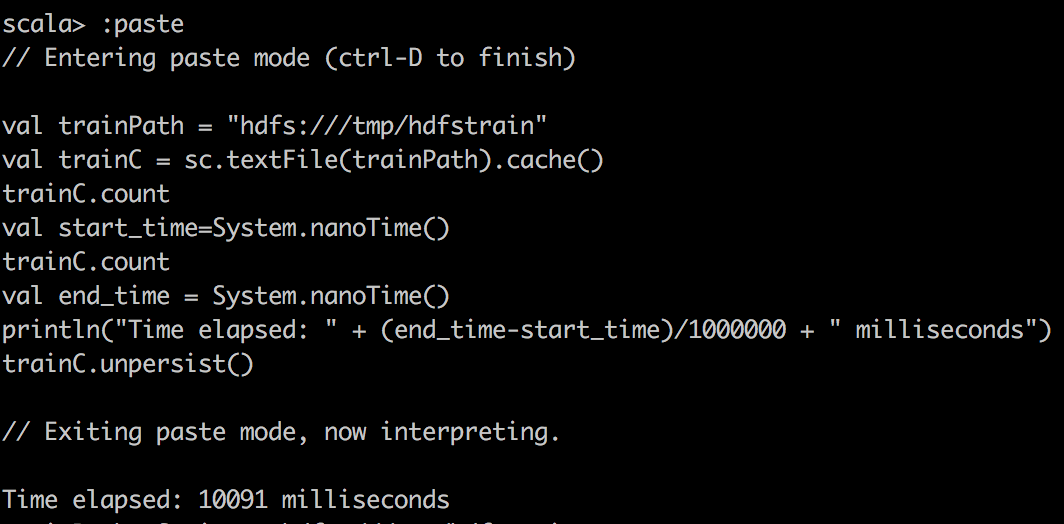 |
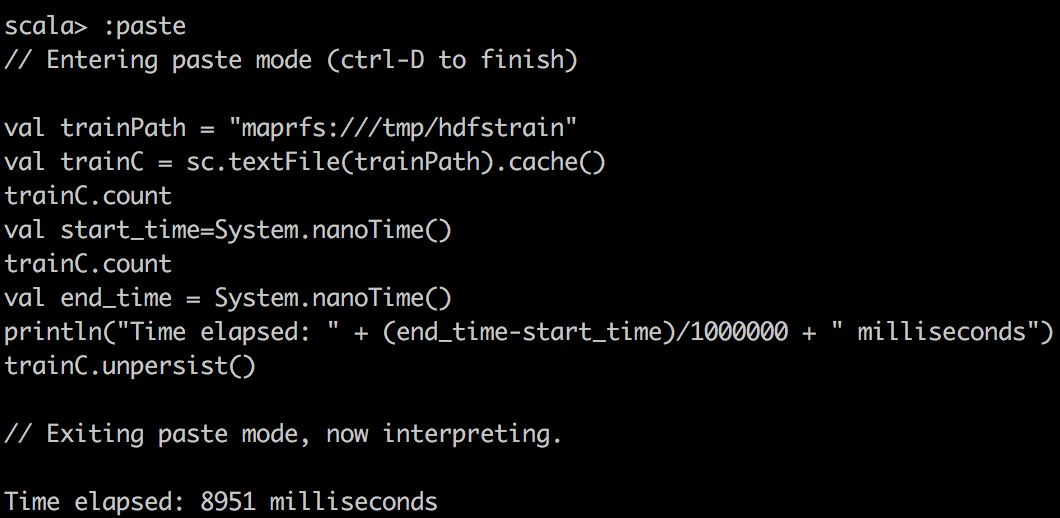 |
Во-вторых, мы используем пакет Databricks для чтения CSV в DataFrame в Spark и делаем простой подсчет в файле csv. Здесь мы отмечаем гораздо лучшее сжатие и огромный подъем при кэшировании Spark DataFrame в память.
Cloudera |
MapR |
|
CSV File |
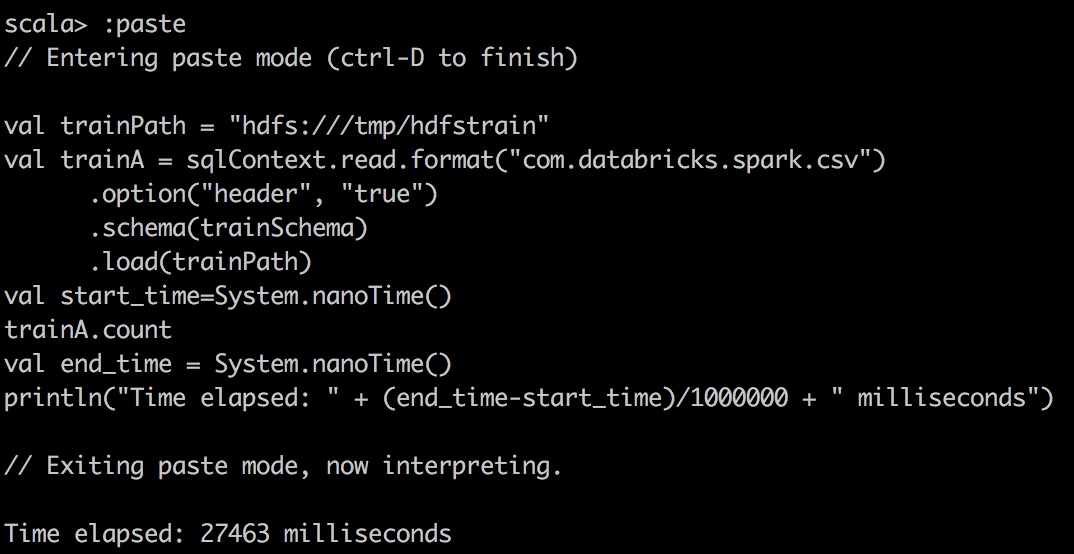 |
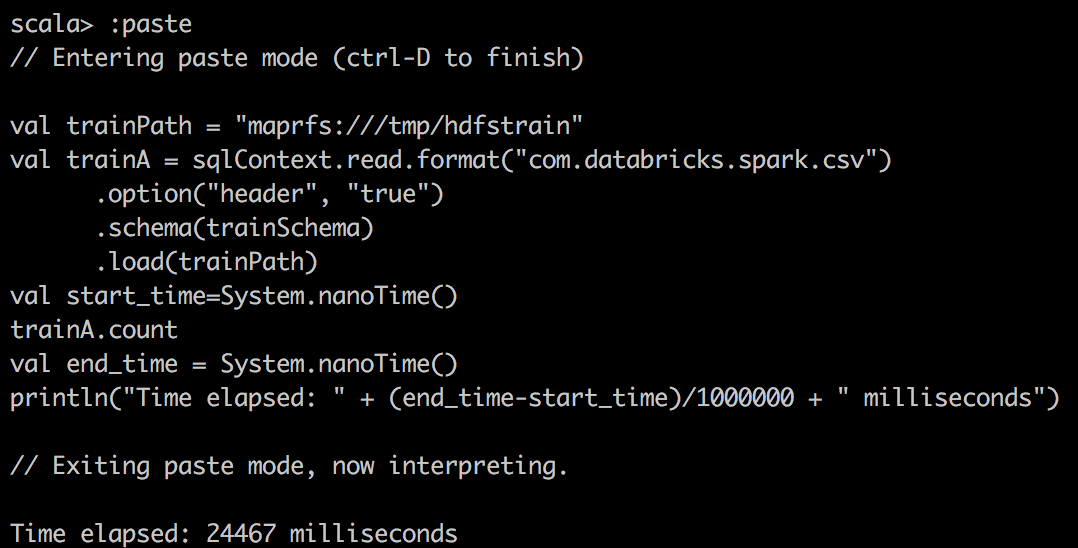 |
CSV File reading Alluxio |
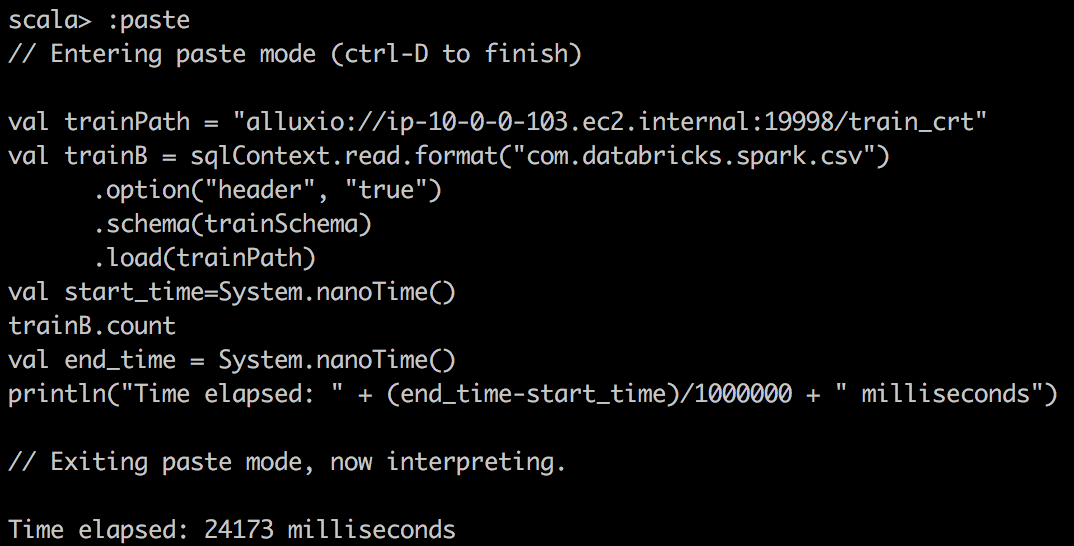 |
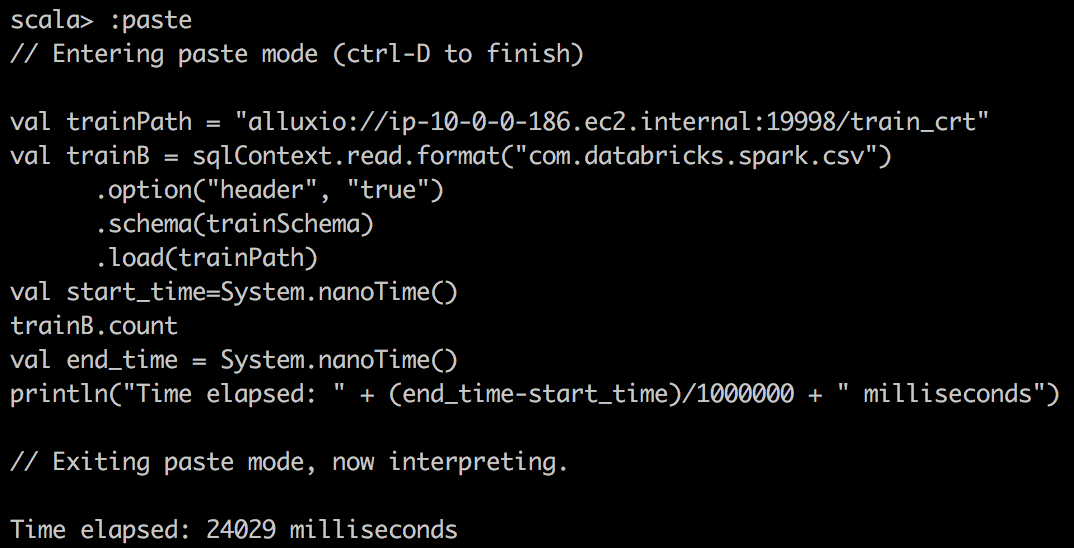 |
CSV File cached |
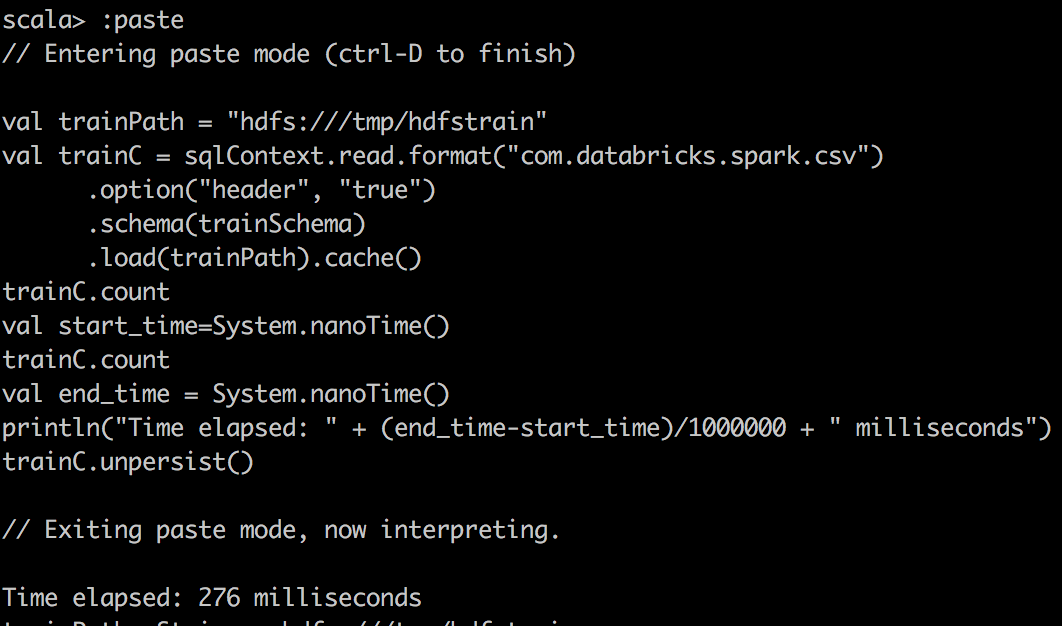 |
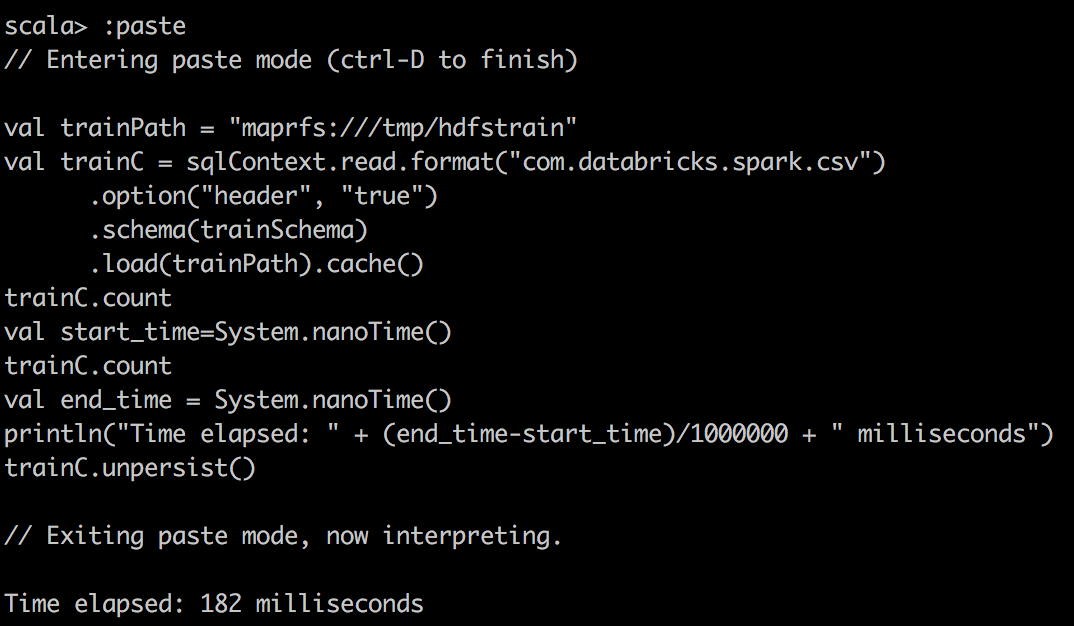 |
Наконец, мы читаем Parquet в DataFrame в Spark и делаем простой подсчет в файле Parquet. Мы можем заметить, что Parquet очень эффективен для столбчатых типов запросов благодаря своему великолепному дизайну. Кроме того, он очень хорошо работает с Apache Drill.
Cloudera |
MapR |
|
Parquet |
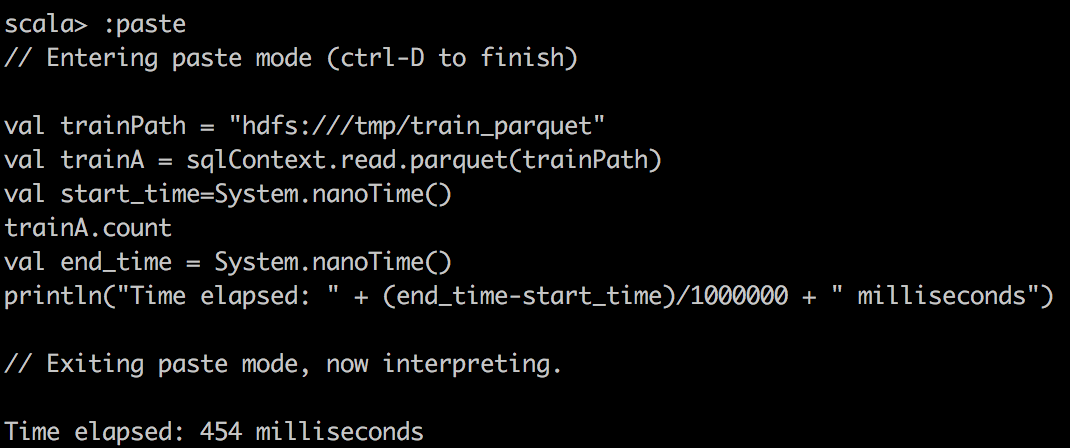 |
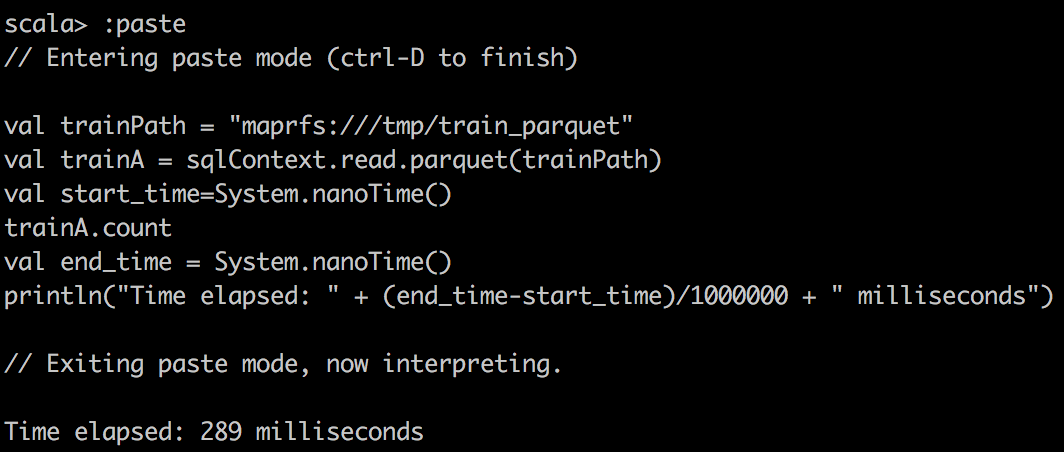 |
Parquet reading Alluxio |
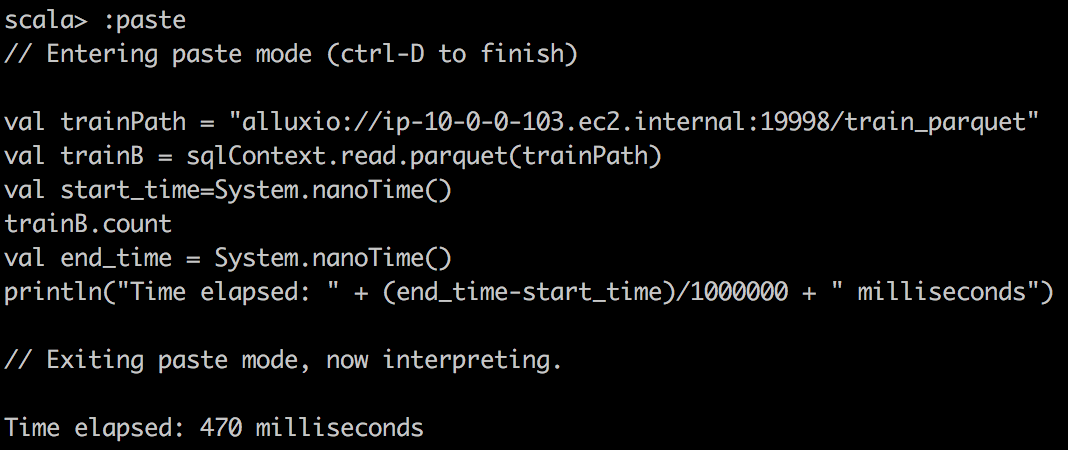 |
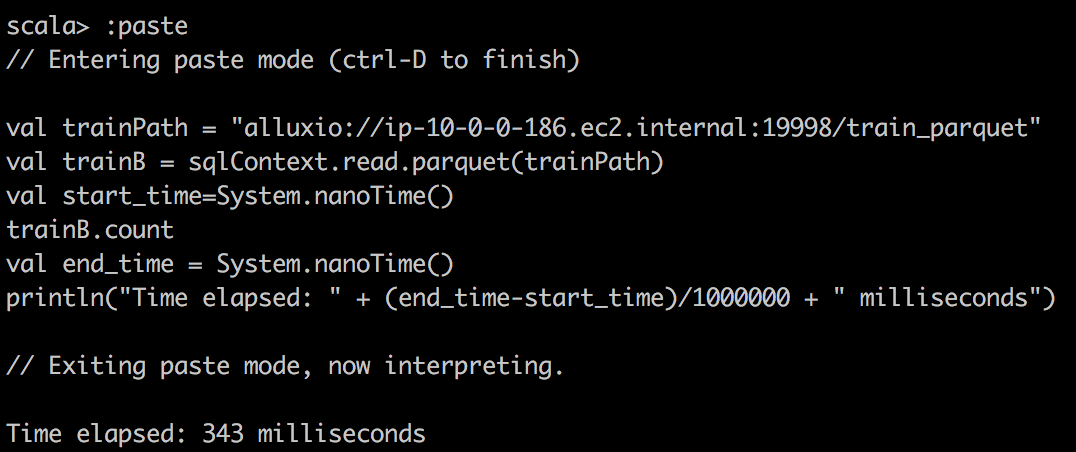 |
Parquet cached |
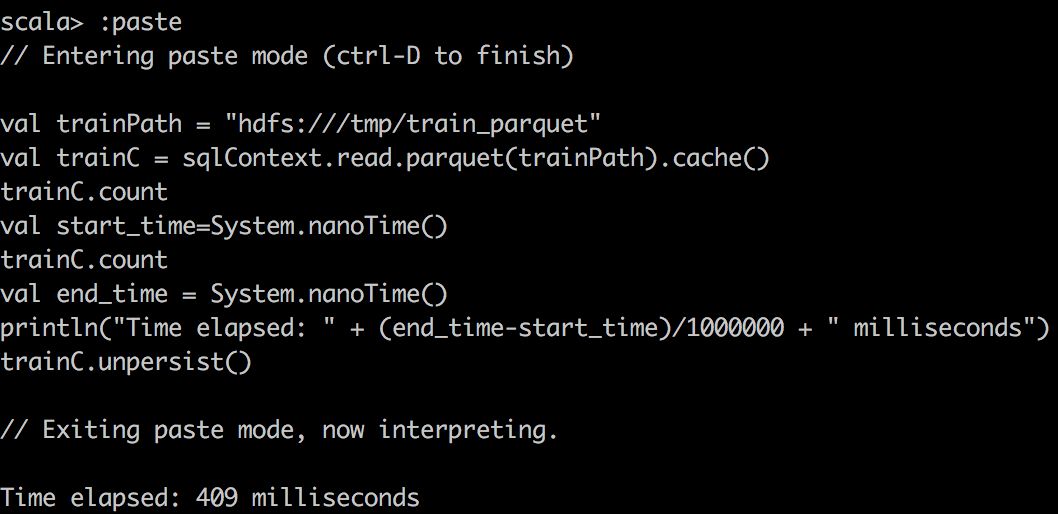 |
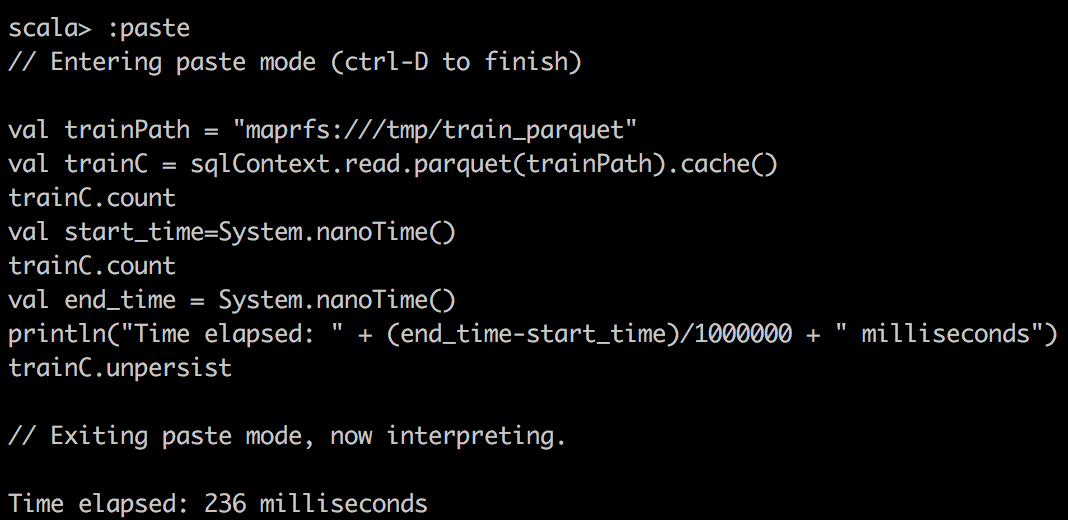 |
Мы можем заметить, что использование кэшированных DataFrame и RDD может значительно ускорить запрос. Если мы посмотрим, как выполняется задача, мы заметим, что для кэшированных задач все уровни локальности задач показывали «PROCESS_LOCAL», а для не кэшированных задач — «NODE_LOCAL». Вот почему я бы сказал, что локальность данных имеет ключевое значение для скорости запросов, и поэтому Alluxio будет успешным, если у вас будет много удаленных центров обработки данных. Но вы можете достичь аналогичной идеи с технологией MapR; просто создайте выделенное зеркало тома для некоторого тома с горячими данными и поместите его в локальные кластеры.
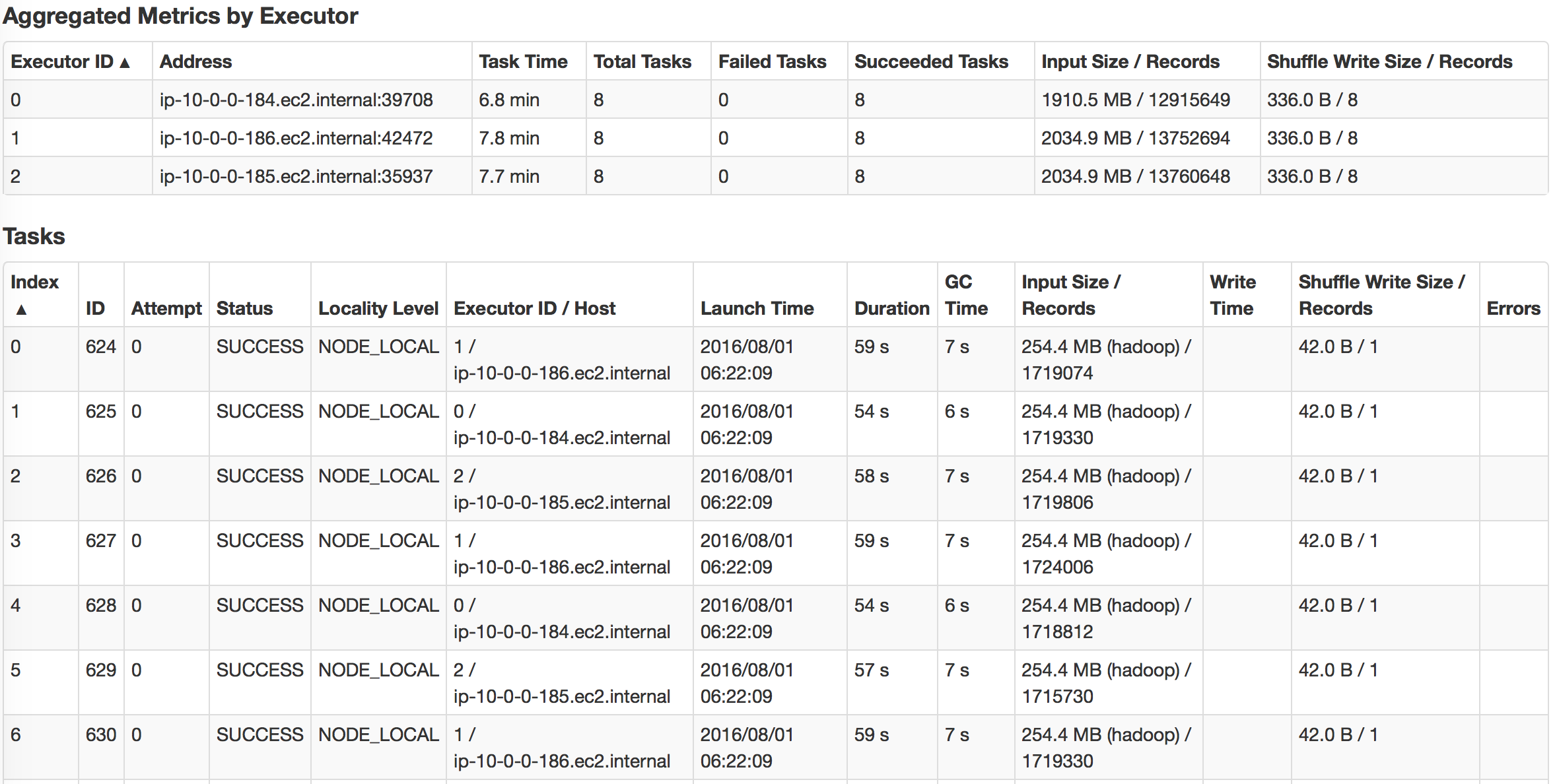
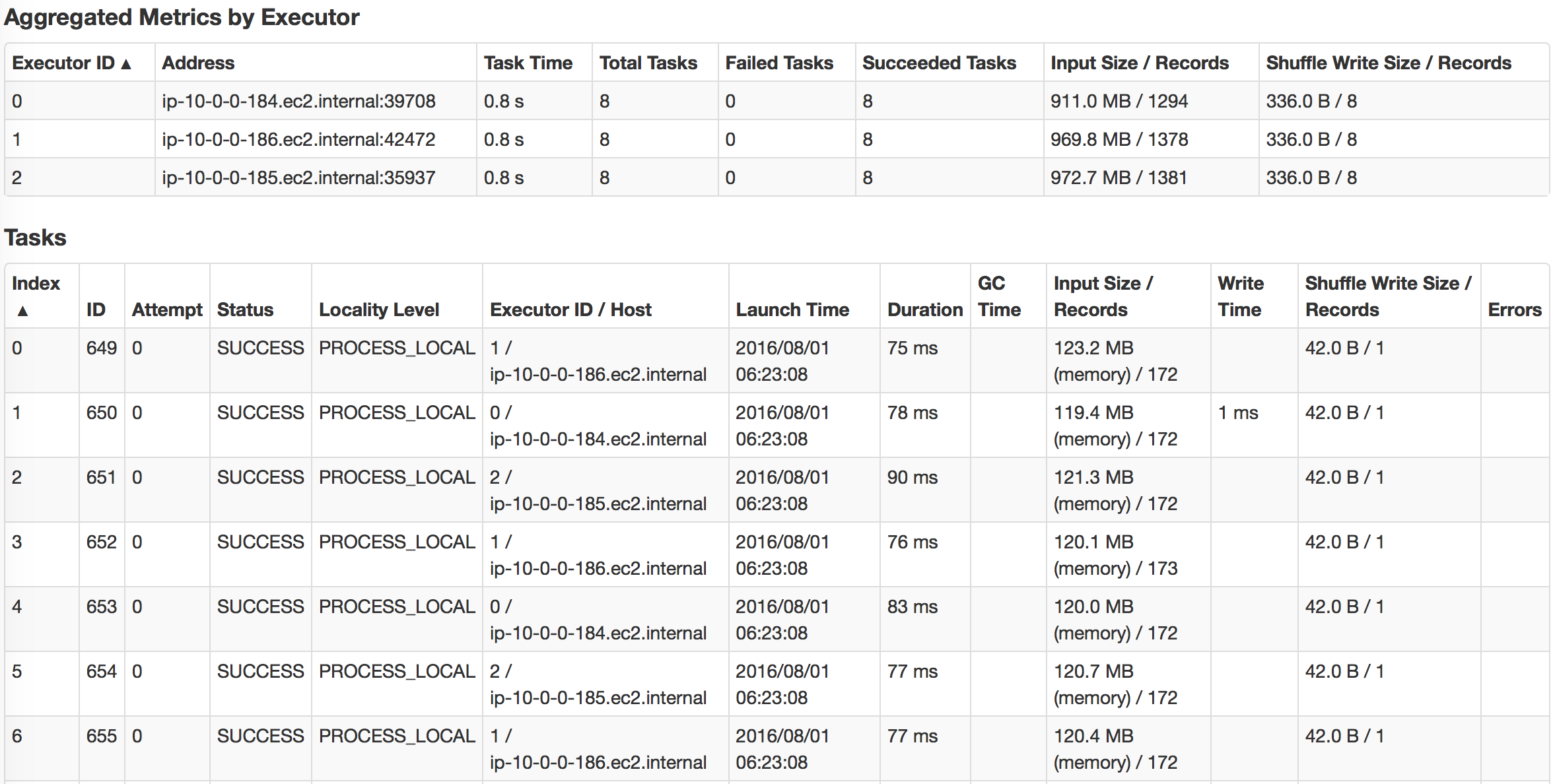
Резюме
Подводя итог, если мы хотим ускорить скорость запросов в Hadoop, нам действительно следует использовать кэшированный SparkSQL и попытаться использовать формат Parquet для правильного варианта использования. Alluxio отлично подходит, если у вас есть удаленные центры обработки данных или разнородный уровень хранения; он может предоставить данные, необходимые для выполнения Spark. Преимущества — устойчивость к сбоям в работе и совместное использование нескольких сеансов Spark. Чтобы действительно контролировать производительность системы, мы должны отслеживать статистику пропускной способности файловой системы. Это только приблизительное представление показателей производительности. Мы также отмечаем, что чем больше данных под ними, тем больше преимуществ мы можем получить, используя Alluxio или кэшируя их в памяти.
Кроме того, если вы заинтересованы в использовании Drill для запросов к Alluxio, просто поместите скомпилированный jar-файл alluxio-core-client-1.2.0-jar-with-dependencies.jar в jars / classb. Вам также необходимо добавить следующие строки в файл conf / core-site.xml.
|
1
2
3
4
|
<property> <name>fs.alluxio.impl</name> <value>alluxio.hadoop.FileSystem<value></property> |
Получайте удовольствие от запроса данных! Если у вас есть какие-либо вопросы, пожалуйста, задавайте их в разделе комментариев ниже. ![]()
| Ссылка: | Как ускорить специальную аналитику с помощью SparkSQL, Parquet и Alluxio от нашего партнера по JCG Донга Менга в блоге Mapr . |