стог сена
Haystack — это библиотека Python, которая обеспечивает модульный поиск для Django. Он имеет API, который обеспечивает поддержку для различных серверных частей поиска, таких как Elasticsearch, Whoosh, Xapian и Solr.
Elasticsearch
Elasticsearch — популярная поисковая система Lucene, способная выполнять полнотекстовый поиск, и она разработана на Java.
В поиске Google используется тот же подход, что и при индексации их данных, и поэтому очень легко получить любую информацию, используя всего несколько ключевых слов, как показано ниже.
Установите Джанго Хейстек и Elasticsearch
Первый шаг — настроить Elasticsearch и запустить его локально на вашей машине. Elasticsearch требует Java, поэтому на вашем компьютере должна быть установлена Java.
Мы собираемся следовать инструкциям с сайта Elasticsearch .
Загрузите архив Elasticsearch 1.4.5 следующим образом:
|
1
|
curl -L -O https://download.elastic.co/elasticsearch/elasticsearch/elasticsearch-1.4.5.tar.gz
|
Извлеките его следующим образом:
|
1
|
tar -xvf elasticsearch-1.4.5.tar.gz
|
Затем он создаст пакет файлов и папок в вашем текущем каталоге. Затем мы идем в каталог bin следующим образом:
|
1
|
cd elasticsearch-1.4.5/bin
|
Запустите Elasticsearch следующим образом.
|
1
|
./elasticsearch
|
Чтобы убедиться, что он успешно установлен, перейдите на http://127.0.0.1:9200/ , и вы должны увидеть что-то вроде этого.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
{
«name» : «W3nGEDa»,
«cluster_name» : «elasticsearch»,
«cluster_uuid» : «ygpVDczbR4OI5sx5lzo0-w»,
«version» : {
«number» : «5.6.3»,
«build_hash» : «1a2f265»,
«build_date» : «2017-10-06T20:33:39.012Z»,
«build_snapshot» : false,
«lucene_version» : «6.6.1»
},
«tagline» : «You Know, for Search»
}
|
Убедитесь, что у вас также есть стог сена.
|
1
|
pip install django-haystack
|
Давайте создадим наш проект Django. Наш проект сможет проиндексировать всех клиентов в банке, упрощая поиск и получение данных, используя всего несколько поисковых терминов.
|
1
|
django-admin startproject Bank
|
Эта команда создает файлы, которые предоставляют конфигурации для проектов Django.
Давайте создадим приложение для клиентов.
|
1
2
3
|
cd Bank
python manage.py startapp customers
|
settings.py Конфигурации
Чтобы использовать Elasticsearch для индексации нашего контента, доступного для поиска, нам нужно определить внутренний параметр для стога сена в файле settings.py нашего проекта. Мы собираемся использовать Elasticsearch в качестве нашего бэкенда.
HAYSTACK_CONNECTIONS является обязательным параметром и должен выглядеть следующим образом:
|
1
2
3
4
5
6
7
|
HAYSTACK_CONNECTIONS = {
‘default’: {
‘ENGINE’: ‘haystack.backends.elasticsearch_backend.ElasticsearchSearchEngine’,
‘URL’: ‘http://127.0.0.1:9200/’,
‘INDEX_NAME’: ‘haystack’,
},
}
|
В settings.py мы также собираемся добавить стог сена и клиентов в список installed apps .
|
01
02
03
04
05
06
07
08
09
10
11
|
INSTALLED_APPS = [
‘django.contrib.admin’,
‘django.contrib.auth’,
‘django.contrib.contenttypes’,
‘django.contrib.sessions’,
‘django.contrib.messages’,
‘django.contrib.staticfiles’,
‘rest_framework’,
‘haystack’,
‘customer’
]
|
Создавать модели
Давайте создадим модель для клиентов. У customers/models. py , добавьте следующий код.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
from __future__ import unicode_literals
from django.db import models
# Create your models here.
customer_type = (
(«Active», «Active»),
(«Inactive», «Inactive»)
)
class Customer(models.Model):
id = models.IntegerField(primary_key=True)
first_name = models.CharField(max_length=50, null=False, blank=True)
last_name = models.CharField(
max_length=50, null=False, blank=True)
other_names = models.CharField(max_length=50, default=» «)
email = models.EmailField(max_length=100, null=True, blank=True)
phone = models.CharField(max_length=30, null=False, blank=True)
balance = models.IntegerField(default=»0″)
customer_status = models.CharField(
max_length=100, choices=customer_type, default=»Active»)
address = models.CharField(
max_length=50, null=False, blank=False)
def save(self, *args, **kwargs):
return super(Customer, self).save(*args, **kwargs)
def __unicode__(self):
return «{}:{}».format(self.first_name, self.last_name)
|
Зарегистрируйте свою модель Customer в admin.py следующим образом:
|
1
2
3
4
5
6
|
from django.contrib import admin
from .models import Customer
# Register your models here.
admin.site.register(Customer)
|
Создать базу данных и Super User
Примените ваши миграции и создайте учетную запись администратора.
|
1
2
|
python manage.py migrate
python manage.py createsuperuser
|
Запустите свой сервер и перейдите по адресу http: // localhost: 8000 / admin / . Теперь вы сможете увидеть свою модель клиента там. Идем дальше и добавляем новых клиентов в админку.
Индексирование данных
Чтобы проиндексировать наши модели, мы начинаем с создания SearchIndex . Объекты SearchIndex определяют, какие данные должны быть помещены в поисковый индекс. Каждый тип модели должен иметь уникальный searchIndex .
Объекты SearchIndex — это способ, которым стог сена определяет, какие данные должны быть помещены в поисковый индекс, и обрабатывает поток данных. Чтобы создать SearchIndex , мы собираемся наследовать от indexes.SearchIndex и indexes.Indexable , определяем поля, которые мы хотим сохраните наши данные с помощью и определите метод get_model .
Давайте создадим CustomerIndex чтобы соответствовать моделированию наших Customer . Создайте файл search_indexes.py в каталоге приложения клиентов и добавьте следующий код.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
from .models import Customer
from haystack import indexes
class CustomerIndex(indexes.SearchIndex, indexes.Indexable):
text = indexes.EdgeNgramField(document=True, use_template=True)
first_name = indexes.CharField(model_attr=’first_name’)
last_name = indexes.CharField(model_attr=’last_name’)
other_names = indexes.CharField(model_attr=’other_names’)
email = indexes.CharField(model_attr=’email’, default=» «)
phone = indexes.CharField(model_attr=’phone’, default=» «)
balance = indexes.IntegerField(model_attr=’balance’, default=»0″)
customer_status = indexes.CharField(model_attr=’customer_status’)
address = indexes.CharField(model_attr=’address’, default=» «)
def get_model(self):
return Customer
def index_queryset(self, using=None):
return self.get_model().objects.all()
|
EdgeNgramField — это поле в стоге сена SearchIndex которое предотвращает неправильные совпадения, когда части двух разных слов смешиваются друг с другом.
Это позволяет нам использовать функцию autocomplete для проведения запросов. Мы будем использовать автозаполнение, когда начнем запрашивать наши данные.
document=True указывает на основное поле для поиска внутри. Кроме того, use_template=True в text поле позволяет нам использовать шаблон данных для построения документа, который будет проиндексирован.
Давайте создадим шаблон в каталоге шаблонов наших клиентов. Внутри search/indexes/customers/customers_text.txt добавьте следующее:
|
1
2
3
|
{{object.first_name}}
{{object.last_name}}
{{object.other_names}}
|
Переиндексировать данные
Теперь, когда наши данные находятся в базе данных, пришло время поместить их в наш поисковый индекс. Для этого просто запустите ./manage.py rebuild_index . Вы получите итоги того, сколько моделей было обработано и помещено в индекс.
|
1
|
Indexing 20 customers
|
Кроме того, вы можете использовать RealtimeSignalProcessor , который автоматически обрабатывает обновления / удаления для вас. Чтобы использовать его, добавьте следующее в файл settings.py .
|
1
|
HAYSTACK_SIGNAL_PROCESSOR = ‘haystack.signals.RealtimeSignalProcessor’
|
Запрос данных
Мы собираемся использовать шаблон поиска и Haystack API для запроса данных.
Шаблон поиска
Добавьте URL-адреса стога сена в ваш URLconf.
|
1
|
url(r’^search/’, include(‘haystack.urls’)),
|
Давайте создадим наш шаблон поиска. В templates/search.html Добавьте следующий код.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
|
{% block head %}
<link rel="stylesheet" href="http://maxcdn.bootstrapcdn.com/bootstrap/3.3.6/css/bootstrap.min.css">
<script src="https://ajax.googleapis.com/ajax/libs/jquery/1.12.0/jquery.min.js"></script>
<script src="http://maxcdn.bootstrapcdn.com/bootstrap/3.3.6/js/bootstrap.min.js"></script>
{% endblock %}
{% block navbar %}
<nav class="navbar navbar-default">
<div class="container">
<div class="navbar-header">
<button type="button" class="navbar-toggle" data-toggle="collapse" data-target="#myNavbar">
<span class="icon-bar">
<span class="icon-bar">
<span class="icon-bar">
</button>
<a class="navbar-brand" href="#">HOME</a>
</div>
<div class="collapse navbar-collapse" id="myNavbar">
<ul class="nav navbar-nav navbar-right">
<li><input type="submit" class="btn btn-primary" value="Add Customer"> </li>
</ul>
</div>
</div>
</nav>
{% endblock %}
{% block content %}
<div class="container-fluid bg-3 text-center">
<form method="get" action="."
{{ form.non_field_errors }}
<div class="form-group">
{{ form.as_p }}
</div>
<div class="form-group">
<input type="submit" class="btn btn-primary" value="Search">
</div>
{% if query %}
<h3>Results</h3>
<div class="container-fluid bg-4 text-left">
<div class="row">
{% for result in page.object_list %}
<div class="col-sm-4">
<div class="thumbnail">
<div class="form-group">
<p>First name : {{result.first_name}} </p>
</div>
<div class="form-group">
<p>Last name : {{result.last_name}} </p>
</div>
<div class="form-group">
<p>Balance : {{result.balance}} </p>
</div>
<div class="form-group">
<p>Email : {{result.email}} </p>
</div>
<div class="form-group">
<p>Status : {{result.customer_status}} </p>
</div>
</div>
</div>
{% empty %}
<p style="text-center">No results found.</p>
{% endfor%}
</div>
</div>
{% endif %}
</form>
</div>
{% endblock %}
|
page.object_list представляет собой список объектов SearchResult который позволяет нам получить отдельные объекты модели, например, result.first_name .
Ваша полная структура проекта должна выглядеть примерно так:
Теперь запустите сервер, перейдите к 127.0.0.1:8000/search/ и выполните поиск, как показано ниже.
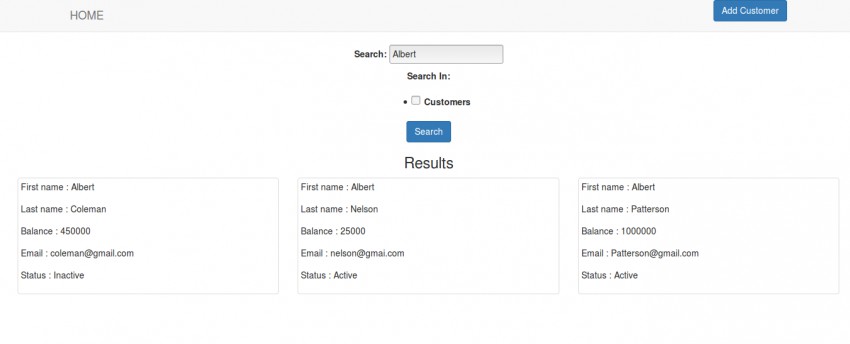
Поиск Albert даст результаты всех клиентов с именем Albert . Если ни один клиент не имеет имени Альберт, то запрос даст пустые результаты. Не стесняйтесь поиграть со своими собственными данными.
Haystack API
Haystack имеет класс SearchQuerySet который разработан для упрощения и согласованности выполнения поиска и повторения результатов. Большая часть API SearchQuerySet знакома с ORM QuerySet Django.
В customers/views.py добавьте следующий код:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
from django.shortcuts import render
from rest_framework.decorators import (
api_view, renderer_classes,
)
from .models import Customer
from haystack.query import SearchQuerySet
from rest_framework.response import Response
# Create your views here.
@api_view(['POST'])
def search_customer(request):
name = request.data['name']
customer = SearchQuerySet().models(Customer).autocomplete(
first_name__startswith=name)
searched_data = []
for i in customer:
all_results = {"first_name": i.first_name,
"last_name": i.last_name,
"balance": i.balance,
"status": i.customer_status,
}
searched_data.append(all_results)
return Response(searched_data)
|
autocomplete - это быстрый способ поиска автозаполнения. Он должен быть запущен для полей EdgeNgramField или NgramField .
В приведенном выше Queryset мы используем метод contains чтобы фильтровать наш поиск, чтобы получать только результаты, содержащие наши определенные символы. Например, Al будет получать только данные о клиентах, которые содержат Al . Обратите внимание, что результаты будут получены только из полей, определенных в customer_text.txt file .
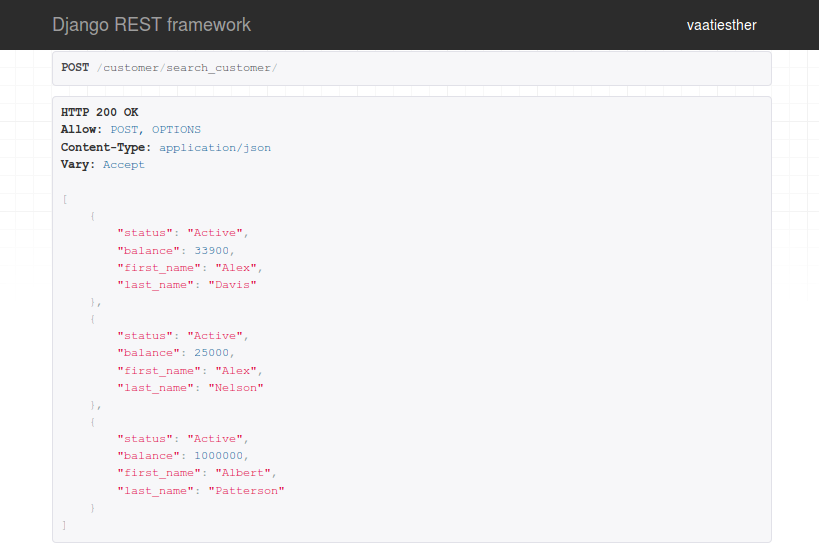
Помимо поиска полей contains другие поля, доступные для выполнения запросов, в том числе:
- содержание
- содержит
- точный
- GT
- GTE
- л
- Ге
- в
- начинается с
- EndsWith
- ассортимент
- нечеткий
Вывод
Огромное количество данных производится в любой момент в социальных сетях, здравоохранении, магазинах и других секторах. Большая часть этих данных неструктурирована и разбросана. Elasticsearch может использоваться для обработки и анализа этих данных в форме, которая может быть понята и потреблена.
Elasticsearch также широко используется для поиска контента, анализа данных и запросов. Для получения дополнительной информации посетите сайты Haystack и Elasticsearch .