[Эта статья была написана Майклом Кобурном]
В ходе недавней встречи я работал с заказчиком, который широко использует значения UUID () для своего первичного ключа и сохраняет его как char (36), и их число строк в этом примере таблицы выросло до более 1 миллиарда строк.
Таблица только для INSERT (без UPDATE или DELETE), и большая часть их поиска — поиск по PK. Поиск по PK выполнялся приемлемо, но они касались использования пространства таблицей, когда мы приближались к 1 ТБ (работа с innodb_file_per_table = 1 и Percona Server 5.5).
Эта модель схемы увеличивает нагрузку на резервные копии, поскольку они используют Percona XtraBackup, и поэтому был задан вопрос: влияет ли их выбор фактически случайного первичного ключа на основе UUID () на их дисковое хранилище и в какой степени? И в качестве аккуратного трюка я покажу в конце этого поста, как вы можете рассчитывать уровень фрагментации в своей таблице на регулярной основе, если вы так склонны. Так что читайте дальше!
Для фона наиболее распространенный подход для первичного ключа в InnoDB — это тот, который использует целочисленное значение AUTO_INCREMENT. Одним из преимуществ PK AUTO_INCREMENT является то, что он позволяет InnoDB добавлять новые записи в конец таблицы и предотвращает необходимость разделения индекса BTREE в любой точке. Больше на этом разделении ссылки в данный момент. Также обратите внимание, что этот пост в блоге не предназначен для продвижения одного типа модели над другим, моя цель — проиллюстрировать влияние вашего выбора PK на данные на диске.
Первичный ключ служит нескольким целям в InnoDB:
- Обеспечивает уникальность между рядами
- InnoDB сохраняет данные строк на диске, кластеризованные по первичному ключу
- В зависимости от используемого типа и используемого шаблона INSERT / UPDATE, предоставляется либо нефрагментированный, либо сильно фрагментированный первичный ключ
Я хотел профилировать три различных типа первичного ключа:
- целое число AUTO_INCREMENT — этот ключ будет занимать 4 байта
- бинарный (16) с использованием Упорядоченного UUID () — согласно UUID Картика () — оптимизированное сообщение в блоге
- char (36) с использованием UUID () — что использовал мой клиент
Затем я использовал мощный инструмент функции innodb_space space-lsn-age-illustrate (из innodb_ruby Джереми Коула) проект) для построения страниц LSN (порядковый номер журнала InnoDB, всегда увеличивающееся значение) из каждой таблицы, в которой используются различные первичные ключи через цвет ASCII (так жарко, верно? Спасибо, Джереми !!). Для справки, легенда указывает, что чем темнее цвет, тем «старая» обновленная версия страницы (LSN), в то время как при переходе через цветовую гамму к розовому цвету вы смотрите на последние записанные значения LSN. Я пытаюсь проиллюстрировать это тем, что когда вы используете AUTO_INCREMENT или UUID (), который был изменен для вставки в порядке возрастания, вы практически не разбиваете страницы и, таким образом, занимает минимальное количество страниц базы данных. С левой стороны вы смотрите на идентификаторы страниц для этой таблицы, и чем меньше количество потребляемых страниц, тем более эффективно упаковываются данные таблицы на этих страницах.
Это пример только INSERT, основанный на первичном ключе AUTO_INCREMENT. Обратите внимание, что более темные цвета тяжелы на самых ранних страницах и светлее, когда мы начинаем писать страницы с большим числом. Далее эта таблица заканчивает писать где-то около 700 страниц.

Первичный ключ целое число AUTO_INCREMENT
Когда мы смотрим на шаблон INSERT optimized-UUID (), мы видим, что он также имеет очень равномерно распределенный шаблон с самыми старыми страницами в начале (самыми низкими идентификаторами страниц) и новейшими письменными страницами в конце таблицы. Однако используется больше страниц, потому что первичный ключ шире, поэтому в итоге мы используем где-то около 1100 страниц.

Упорядоченный первичный ключ на основе UUID ()
Finally we arrive at the UUID() INSERT pattern, and as we expected, the fragmentation is extreme and has caused many page splits — this is the behaviour in InnoDB when a record needs to be written into an existing page (since it falls between two existing values) and InnoDB realises that if this additional value is written that the capacity of the page will be overcommitted, so it then “splits” the page into two pages and writes them both out. The rash of pink in the image below shows us that UUID() causes significant fragmentation because it is causing pages to be split all throughout the table. This is deemed “expensive” since the ibd file now is more than 2x greater than the UUID()-optimised method, and about 3x greater than a Primary Key with AUTO_INCREMENT.
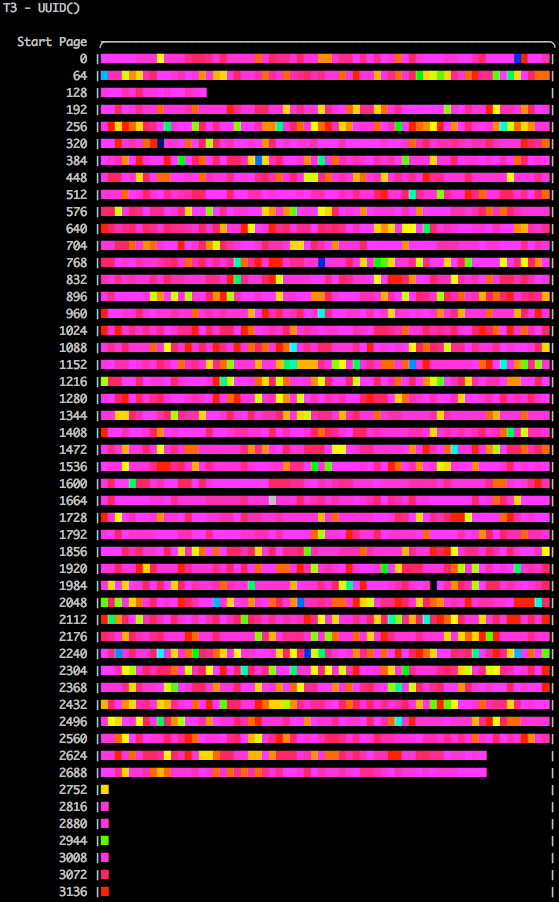
UUID() Primary Key
Based on this investigation we determined that the true size of the 1 billion row table was about half the size as reported by Linux when examining the .ibd file. We happened to have an opportunity to dump and load the table (mysqldump | mysql) and found that on restore the table consumed 450GB of disk — so our estimate was pretty good!
I also wanted to highlight that you can determine for yourself the statistics for data / pages split. As you can see below, the first two PK distributions are very tight, with pages packed up to 90%, however the UUID model leaves you with just slightly higher than 50%. You can run this against your prepared backups if you use Percona XtraBackup since at least version 2.1 by using the –stats option.
[root@mysql]# xtrabackup --stats --datadir=/data/backups/mysql --target-dir=/data/backups/mysql | grep -A5 test | grep -A5 PRIMARY
table: test/t1, index: PRIMARY, space id: 13, root page: 3, zip size: 0
estimated statistics in dictionary:
key vals: 8, leaf pages: 99, size pages: 161
real statistics:
level 1 pages: pages=1, data=1287 bytes, data/pages=7%
leaf pages: recs=60881, pages=99, data=1461144 bytes, data/pages=90%
--
table: test/t2_uuid_ordered, index: PRIMARY, space id: 14, root page: 3, zip size: 0
estimated statistics in dictionary:
key vals: 8, leaf pages: 147, size pages: 161
real statistics:
level 1 pages: pages=1, data=3675 bytes, data/pages=22%
leaf pages: recs=60882, pages=147, data=2191752 bytes, data/pages=91%
--
table: test/t3_uuid, index: PRIMARY, space id: 15, root page: 3, zip size: 0
estimated statistics in dictionary:
key vals: 8, leaf pages: 399, size pages: 483
real statistics:
level 2 pages: pages=1, data=92 bytes, data/pages=0%
level 1 pages: pages=2, data=18354 bytes, data/pages=56%
Below are the table definitions along with the scripts I used to generate the data for this post.
mysql> show create table t1G *************************** 1. row *************************** Table: t1 Create Table: CREATE TABLE `t1` ( `c1` int(10) unsigned NOT NULL AUTO_INCREMENT, `c2` char(1) NOT NULL DEFAULT 'a', PRIMARY KEY (`c1`), KEY `c2` (`c2`) ) ENGINE=InnoDB AUTO_INCREMENT=363876 DEFAULT CHARSET=utf8 1 row in set (0.00 sec) mysql> show create table t2_uuid_orderedG *************************** 1. row *************************** Table: t2_uuid_ordered Create Table: CREATE TABLE `t2_uuid_ordered` ( `pk` binary(16) NOT NULL, `c2` char(1) NOT NULL DEFAULT 'a', PRIMARY KEY (`pk`), KEY `c2` (`c2`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 1 row in set (0.00 sec) mysql> show create table t3_uuidG *************************** 1. row *************************** Table: t3_uuid Create Table: CREATE TABLE `t3_uuid` ( `pk` char(36) NOT NULL, `c2` char(1) NOT NULL DEFAULT 'a', PRIMARY KEY (`pk`), KEY `c2` (`c2`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 1 row in set (0.00 sec)
[root@mysql]# cat make_rows.sh
#!/bin/bash
while [ 1 ] ; do
mysql -D test -e "insert into t1 (c2) values ('d')" ;
mysql -D test -e "insert into t2_uuid_ordered (pk, c2) values (ordered_uuid(uuid()), 'a')" ;
mysql -D test -e "insert into t3_uuid (pk, c2) values (uuid(), 'a')" ;
done
[root@mysql]# cat space_lsn_age_illustrate.sh #!/bin/bash cd /var/lib/mysql echo "T1 - AUTO_INCREMENT" innodb_space -f test/t1.ibd space-lsn-age-illustrate echo "T2 - UUID() ORDERED" innodb_space -f test/t2_uuid_ordered.ibd space-lsn-age-illustrate echo "T3 - UUID()" innodb_space -f test/t3_uuid.ibd space-lsn-age-illustrate
I hope that this post helps you to better understand the impact of random vs ordered Primary Key selection! Please share with me your thoughts on this post in the comments, thanks for reading!
Note to those attentive readers seeking more information: I plan to write a follow-up post that deals with these same models but from a performance perspective. In this post I tried to be as specific as possible with regards to the disk consumption and fragmentation concerns – I feel it addressed the first part and allude to this mysterious “fragmentation” beast but only teases at what that could mean for query response time… Just sit tight, I’m hopeful to get a tag-along to this one post-PLMCE!
By the way, come see me speak at the Percona Live MySQL Conference and Expo in Santa Clara, CA the week of April 13th – I’ll be delivering 5 talks and moderating one Keynote Panel. I hope to see you there! If you are at PLMCE, attend one my talks or stop me in the hallway and say “Hi Michael, I read your post, now where’s my beer?” – and I’ll buy you a cold one of your choice 