Фильтр в Lucene — это битовый набор, который ограничивает пространство поиска для любого запроса; Вы передаете его в метод поиска IndexSearcher. Он эффективен для ряда случаев использования, таких как защита документов, разделы индекса, детализация фасетов и т. Д.
Чтобы применить фильтр, Lucene должен вычислить пересечение документов, соответствующих запросу, по документам, разрешенным фильтром. Сегодня мы делаем это
в IndexSearcher следующим образом:
while (true) {
if (scorerDoc == filterDoc) {
// Check if scorer has exhausted, only before collecting.
if (scorerDoc == DocIdSetIterator.NO_MORE_DOCS) {
break;
}
collector.collect(scorerDoc);
filterDoc = filterIter.nextDoc();
scorerDoc = scorer.advance(filterDoc);
} else if (scorerDoc > filterDoc) {
filterDoc = filterIter.advance(scorerDoc);
} else {
scorerDoc = scorer.advance(filterDoc);
}
}
Мы называем это «подходом перепрыгивания»: запрос и фильтр по очереди пытаются перейти к следующему подходящему документу друг друга, часто пропуская целевой документ. Когда оба попадают на один и тот же документ, он собирается.
К сожалению, по разным причинам эта реализация неэффективна (подробнее об этом говорится в
LUCENE-1536 ):
- Предварительный метод для большинства запросов является дорогостоящим.
- Предварительный метод для большинства фильтров обычно дешев.
- Если количество документов, соответствующих запросу, намного больше, чем
число, соответствующее фильтру, или наоборот, лучше
проводить сопоставление в зависимости от того, что является более строгим. - Если фильтр поддерживает быстрый произвольный доступ и не является супер
разреженным, его лучше применять при перечислении публикаций, например, при
удалении документов. - Счетчики запросов не имеют API произвольного доступа, только .advance (),
который выполняет ненужную дополнительную работу .next () для следующего соответствующего
документа.
Чтобы исправить это, Lucene действительно нужен этап оптимизации, во многом как современная база данных, которая смотрит на тип и структуру запроса и фильтра, а также оценивает, сколько документов будет соответствовать, а затем выбирает подходящий путь выполнения. Скорее всего, это будет связано со спецификацией / генерацией исходного кода (
LUCENE-1594 ) для написания выделенного кода Java для выполнения выбранного пути. Когда-нибудь мы доберемся до этой точки!
До тех пор существует простой способ получить большое ускорение во многих случаях, обращаясь к 4-му вопросу выше. До гибкой индексации, когда вы получили перечисление проводок для документов, соответствующих заданному термину, Lucene автоматически отфильтровывает удаленные документы. Благодаря гибкой индексации API теперь позволяет передавать битовый набор, отмечающий пропускаемые документы. Обычно вы передаете удаленные документы IndexReader. Но с помощью простого подкласса FilterIndexReader можно использовать любой фильтр в качестве пропускаемых документов.
Чтобы проверить это, я создал простой класс CachedFilterIndexReader (я прикреплю его к
LUCENE-1536). Вы передаете ему существующий IndexReader плюс фильтр, и он создает IndexReader, который отфильтровывает как удаленные документы, так и документы, которые не соответствуют предоставленному фильтру. По сути, он компилирует удаленные документы IndexReader (если они есть) и отрицание входящего фильтра в один набор кэшированных битов, а затем передает этот набор битов в качестве skipDocs всякий раз, когда запрашиваются публикации. Затем вы можете создать IndexSearcher из этого читателя, и все поиски по нему будут отфильтрованы в соответствии с предоставленным вами фильтром.
Это всего лишь прототип, и он имеет определенные ограничения, например, он не реализует повторное открытие, он медленно создает свой кэшированный фильтр и т. Д.
Тем не менее, он работает очень хорошо! Я протестировал его на 10M-индексе Википедии со случайным фильтром, принимающим 50% документов
| запрос | QPS по умолчанию | QPS Flex | % сдача |
| объединенная ~ 0,7 | 19,95 | 19,25 | -3,5% |
| ип * д | 43,19 | 52,21 | 20,9% |
| Ед. изм* | 21,53 | 30,52 | 41,8% |
| «Соединенные Штаты» | 6,12 | 8,74 | 42,9% |
| + соединенные штаты | 9,68 | 14,23 | 47,0% |
| Соединенные Штаты | 7,71 | 14,56 | 88,9% |
| состояния | 15,73 | 36,05 | 129,2% |
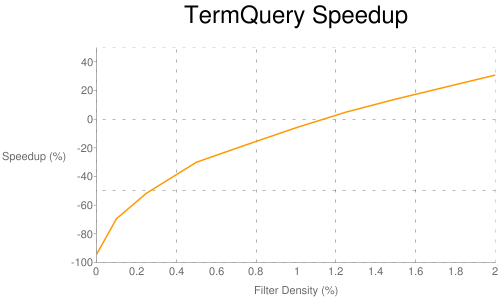
Я не уверен, почему нечеткий запрос стал немного медленнее, но ускорение других запросов просто потрясающее. Однако этот подход на самом деле медленнее, если фильтр очень разреженный. Чтобы проверить это, я запустил только TermQuery («состояния») для разных плотностей фильтра:
переход, по крайней мере для TermQuery, составляет где-то около 1,1%, то есть, если фильтр принимает более 1,1% индекса, лучше всего используйте класс CachedFilterIndexReader; в противном случае лучше использовать текущую реализацию Lucene.
Благодаря этому новому гибкому API до тех пор, пока мы не сможем исправить Lucene для правильной оптимизации для пересечения фильтров и запросов, этот класс предоставляет вам жизнеспособное, полностью внешнее, средство огромных ускорений для не разреженных фильтров!