В предыдущем сообщении в блоге я упомянул, что хочу извлечь всплывающие подсказки из The ThoughtWorks Radar в файл CSV, и я подумал, что это будет хороший мини-проект для практики на Go.
В частности, я хотел попробовать использовать каналы, и это казалось хорошим шансом сделать это.
Я наблюдал доклад Роба Пайка о разработке параллельных приложений, в котором он использует следующее определение параллелизма :
Параллелизм — это способ структурировать программу, разбивая ее на части, которые могут выполняться независимо.
Затем он демонстрирует это на следующей диаграмме:
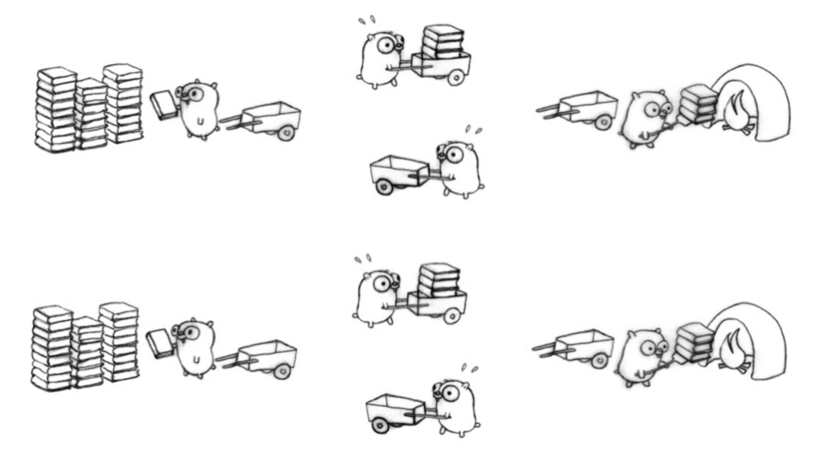
Я разбил очищающее приложение на четыре части:
- Найдите ссылки для скачивания ->
- Загрузите сообщения ->
- Соскрести данные с каждой страницы ->
- Запишите данные в файл CSV
Я не думаю, что мы сильно выиграем, распараллеливая шаги 1) или 4), но шаги 2) и 3) кажутся легко распараллеливаемыми Поэтому мы будем использовать одну процедуру для шагов 1) и 4) и несколько процедур для шагов 2) и 3).
Мы создадим два канала:
- filesToScrape
- filesScraped
И они будут взаимодействовать с нашими компонентами следующим образом:
- 2) запишет путь к загруженным файлам в файлы ToScape
- 3) будет читать из файлов ToScrape и записывать очищенный контент в файлы Scraped
- 4) будет читать из файла Scraped и помещать эту информацию в файл CSV.
Я решил сначала написать полностью серийную версию приложения, чтобы сравнить ее с параллельной версией. У меня был следующий общий код:
скрип / scrape.go
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
|
package scrape import ( "github.com/PuerkitoBio/goquery" "os" "bufio" "fmt" "log" "strings" "net/http" "io") func checkError(err error) { if err != nil { fmt.Println(err) log.Fatal(err) }} type Blip struct { Link string Title string} func (blip Blip) Download() File { parts := strings.Split(blip.Link, "/") fileName := "rawData/items/" + parts[len(parts) - 1] if _, err := os.Stat(fileName); os.IsNotExist(err) { checkError(err) body := resp.Body file, err := os.Create(fileName) checkError(err) io.Copy(bufio.NewWriter(file), body) file.Close() body.Close() } return File{Title: blip.Title, Path: fileName }} type File struct { Title string Path string} func (fileToScrape File ) Scrape() ScrapedFile { file, err := os.Open(fileToScrape.Path) checkError(err) doc, err := goquery.NewDocumentFromReader(bufio.NewReader(file)) checkError(err) file.Close() var entries []map[string]string doc.Find("div.blip-timeline-item").Each(func(i int, s *goquery.Selection) { entry := make(map[string]string, 0) entry["time"] = s.Find("div.blip-timeline-item__time").First().Text() entry["outcome"] = strings.Trim(s.Find("div.blip-timeline-item__ring span").First().Text(), " ") entry["description"] = s.Find("div.blip-timeline-item__lead").First().Text() entries = append(entries, entry) }) return ScrapedFile{File:fileToScrape, Entries:entries}} type ScrapedFile struct { File File Entries []map[string]string} func FindBlips(pathToRadar string) []Blip { blips := make([]Blip, 0) file, err := os.Open(pathToRadar) checkError(err) doc, err := goquery.NewDocumentFromReader(bufio.NewReader(file)) checkError(err) doc.Find(".blip").Each(func(i int, s *goquery.Selection) { item := s.Find("a") title := item.Text() link, _ := item.Attr("href") blips = append(blips, Blip{Title: title, Link: link }) }) return blips} |
Обратите внимание, что мы используем библиотеку goquery для очистки загружаемых нами HTML-файлов.
Blip используется для представления элемента, который появляется на радаре, например .NET Core . Файл представляет собой представление этого сообщения в моей локальной файловой системе, а ScrapedFile содержит локальное представление сообщения и содержит массив, содержащий каждое отображение, которое было сделано в радарах с течением времени.
Давайте посмотрим на однопоточную версию скребка:
CMD / одиночный / main.go
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
package main import ( "fmt" "encoding/csv" "os" "github.com/mneedham/neo4j-thoughtworks-radar/scrape") func main() { var filesCompleted chan scrape.ScrapedFile = make(chan scrape.ScrapedFile) defer close(filesCompleted) blips := scrape.FindBlips("rawData/twRadar.html") var filesToScrape []scrape.File for _, blip := range blips { filesToScrape = append(filesToScrape, blip.Download()) } var filesScraped []scrape.ScrapedFile for _, file := range filesToScrape { filesScraped = append(filesScraped, file.Scrape()) } blipsCsvFile, _ := os.Create("import/blipsSingle.csv") writer := csv.NewWriter(blipsCsvFile) defer blipsCsvFile.Close() writer.Write([]string{"technology", "date", "suggestion" }) for _, scrapedFile := range filesScraped { fmt.Println(scrapedFile.File.Title) for _, blip := range scrapedFile.Entries { writer.Write([]string{scrapedFile.File.Title, blip["time"], blip["outcome"] }) } } writer.Flush()} |
rawData / twRadar.html является локальной копией страницы AZ, которая содержит все сообщения. Эта версия достаточно проста: мы создаем массив, содержащий все всплески, скребем их в другой массив, а затем этот массив в файл CSV. И если мы запустим это:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
$ time go run cmd/single/main.go real 3m10.354suser 0m1.140ssys 0m0.586s $ head -n10 import/blipsSingle.csv technology,date,suggestion.NET Core,Nov 2016,Assess.NET Core,Nov 2015,Assess.NET Core,May 2015,AssessA single CI instance for all teams,Nov 2016,HoldA single CI instance for all teams,Apr 2016,HoldAcceptance test of journeys,Mar 2012,TrialAcceptance test of journeys,Jul 2011,TrialAcceptance test of journeys,Jan 2011,TrialAccumulate-only data,Nov 2015,Assess |
Это займет несколько минут, и большую часть времени займет функция blip.Download () — работа, которую легко распараллелить. Давайте посмотрим на параллельную версию, где программы используют каналы для связи друг с другом:
CMD / параллельный / main.go
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
package main import ( "os" "encoding/csv" "github.com/mneedham/neo4j-thoughtworks-radar/scrape") func main() { var filesToScrape chan scrape.File = make(chan scrape.File) var filesScraped chan scrape.ScrapedFile = make(chan scrape.ScrapedFile) defer close(filesToScrape) defer close(filesScraped) blips := scrape.FindBlips("rawData/twRadar.html") for _, blip := range blips { go func(blip scrape.Blip) { filesToScrape <- blip.Download() }(blip) } for i := 0; i < len(blips); i++ { select { case file := <-filesToScrape: go func(file scrape.File) { filesScraped <- file.Scrape() }(file) } } blipsCsvFile, _ := os.Create("import/blips.csv") writer := csv.NewWriter(blipsCsvFile) defer blipsCsvFile.Close() writer.Write([]string{"technology", "date", "suggestion" }) for i := 0; i < len(blips); i++ { select { case scrapedFile := <-filesScraped: for _, blip := range scrapedFile.Entries { writer.Write([]string{scrapedFile.File.Title, blip["time"], blip["outcome"] }) } } } writer.Flush()} |
Давайте удалим только что загруженные файлы и попробуем эту версию.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
$ rm rawData/items/* $ time go run cmd/parallel/main.go real 0m6.689suser 0m2.544ssys 0m0.904s $ head -n10 import/blips.csv technology,date,suggestionZucchini,Oct 2012,AssessReactive Extensions for .Net,May 2013,AssessManual infrastructure management,Mar 2012,HoldManual infrastructure management,Jul 2011,HoldJavaScript micro frameworks,Oct 2012,TrialJavaScript micro frameworks,Mar 2012,TrialNPM for all the things,Apr 2016,TrialNPM for all the things,Nov 2015,TrialPowerShell,Mar 2012,Trial |
Итак, мы сократились с 190 до 7 секунд, очень круто! Одна интересная вещь заключается в том, что порядок значений в файле CSV будет отличаться, так как процедуры не обязательно вернутся в том же порядке, в котором они были запущены. Мы получаем одинаковое количество значений:
|
1
2
3
4
5
|
$ wc -l import/blips.csv 1361 import/blips.csv $ wc -l import/blipsSingle.csv 1361 import/blipsSingle.csv |
$ wc -l import / blips.csv 1361 import / blips.csv $ wc -l import / blipsSingle.csv 1361 import / blipsSingle.csv
И мы можем проверить, что содержимое идентично:
|
1
2
3
4
5
|
$ cat import/blipsSingle.csv | sort > /tmp/blipsSingle.csv $ cat import/blips.csv | sort > /tmp/blips.csv $ diff /tmp/blips.csv /tmp/blipsSingle.csv |
$ cat import / blipsSingle.csv | sort> /tmp/blipsSingle.csv $ cat import / blips.csv | sort> /tmp/blips.csv $ diff /tmp/blips.csv /tmp/blipsSingle.csv
Код в этом посте весь на github . Я уверен, что сделал несколько ошибок / есть способы, которыми это можно сделать лучше, так что дайте мне знать в комментариях или я @markhneedham в твиттере.
| Ссылка: | Go: Первая попытка увидеть каналы нашего партнера JCG Марка Нидхэма в блоге Марка Нидхэма . |