В этой статье мы рассмотрим, как загрузить тестовую платформу распределенного потокового вещания Apache Kafka с помощью Apache JMeter ™ . Прежде всего, давайте изучим, что такое Кафка, и дадим несколько определений, которые нам понадобятся для дальнейшей работы.
Краткий обзор Apache Kafka
В большой распределенной системе обычно есть много сервисов, которые генерируют различные события: журналы, данные мониторинга, подозрительные действия пользователя и так далее. В Кафке их называют производителями . С другой стороны, есть сервисы, которым нужны сгенерированные данные. Они называются потребителями .
Кафка решает проблему взаимодействия этих сервисов. Он находится между производителями и потребителями, собирая данные от производителей, сохраняя их в распределенном хранилище тем и предоставляя каждому потребителю данные по подписке. Kafka запускается как кластер, состоящий из одного или нескольких серверов, каждый из которых называется брокером .
Другими словами, Кафка представляет собой гибрид распределенной базы данных и очереди сообщений. Он широко известен своими функциями и используется многими крупными компаниями для обработки терабайтов информации. Например, в LinkedIn Apache Kafka используется для потоковой передачи данных об активности пользователей, а Netflix использует их для сбора и буферизации данных для последующих систем, таких как Elasticsearch, Amazon EMR, Mantis и т. Д.
Давайте рассмотрим некоторые функции Kafka, которые важны для нагрузочного тестирования:
- Время хранения длинного сообщения — по умолчанию неделя.
- Высокая производительность благодаря последовательному вводу / выводу.
- Удобная кластеризация.
- Высокая доступность данных благодаря возможности реплицировать и распределять очереди по кластеру.
- Он не только может передавать данные, но и обрабатывать их с помощью потокового API.
Как правило, Kafka используется для работы с очень большим объемом данных. Поэтому во время нагрузочного тестирования следует обратить внимание на следующие аспекты:
- Постоянная запись данных на диск будет влиять на производительность сервера. Если этого недостаточно, он достигнет состояния отказа в обслуживании.
- Кроме того, распределение разделов и количество брокеров также влияет на использование сервисных мощностей. Например, у брокеров может просто не хватить ресурсов для обработки потока данных. В результате производители исчерпают локальные буферы для хранения сообщений, и часть сообщений может быть потеряна.
- Когда используется функция репликации, все становится еще сложнее. Это связано с тем, что для его обслуживания требуется еще больше ресурсов, а случай, когда брокеры отказываются принимать сообщения, становится еще более вероятным.
Данные, которые обрабатываются в таких огромных количествах, могут быть очень легко потеряны, хотя большинство процессов автоматизированы. Поэтому тестирование этих сервисов важно, и необходимо иметь возможность генерировать правильную нагрузку.
Чтобы продемонстрировать нагрузочное тестирование Apache Kafka, он будет установлен на Ubuntu. Мы также будем использовать плагин Pepper-Box в качестве производителя. Он имеет более удобный интерфейс для работы с генерацией сообщений, чем kafkameter . Мы должны будем реализовать потребителя самостоятельно, потому что ни один плагин не обеспечивает реализацию потребителя, и мы собираемся использовать для этого Jamp223 Sampler .
Настройка производителя: Pepper-Box
Чтобы установить плагин, вам нужно скомпилировать этот исходный код или скачать файл jar , затем поместить его в папку lib / ext и перезапустить JMeter .
Этот плагин имеет 3 элемента:
- Pepper-Box PlainText Config позволяет создавать текстовые сообщения в соответствии с указанным шаблоном.
- Pepper-Box Serialized Config позволяет создавать сообщения, которые являются сериализованными объектами Java.
- PepperBoxKafkaSampler предназначен для отправки сообщений, созданных предыдущими элементами.
Давайте посмотрим на каждого из них.
Pepper-Box PlainText Config
Чтобы добавить этот элемент, перейдите в группу « Потоки» -> «Добавить» -> «Элемент конфигурации» -> «Конфигурация Pepper-Box PlainText».
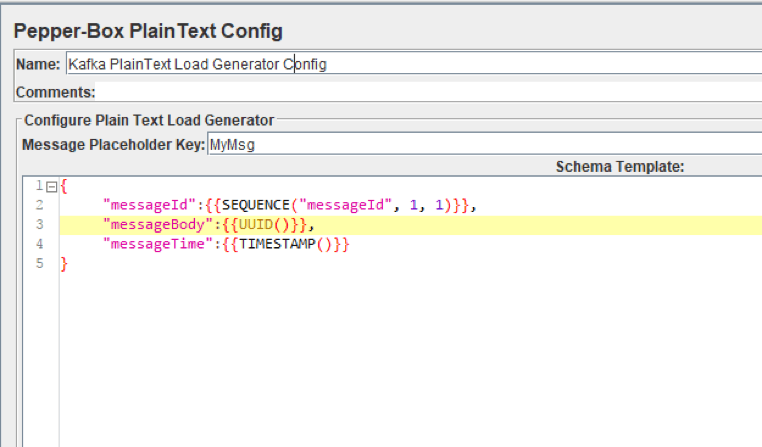
Как вы можете видеть на картинке выше, элемент имеет 2 поля:
- Ключ заполнителя сообщения — ключ, который необходимо указать в PepperBoxKafkaSampler, чтобы использовать шаблон из этого элемента.
- Шаблон схемы — шаблон сообщения, в котором вы можете использовать переменные и функции JMeter, а также функции плагина. Структура сообщения может быть любой, от простого текста до JSON или XML.
Например, на приведенном выше снимке экрана мы передаем строку JSON в виде сообщения, используя несколько функций плагина: указать номер сообщения, указать идентификатор и метку времени отправки.
Сериализированная конфигурация Pepper-Box
Чтобы добавить этот элемент, перейдите в группу потоков -> Добавить -> Элемент конфигурации -> Сериализованная конфигурация Pepper-Box
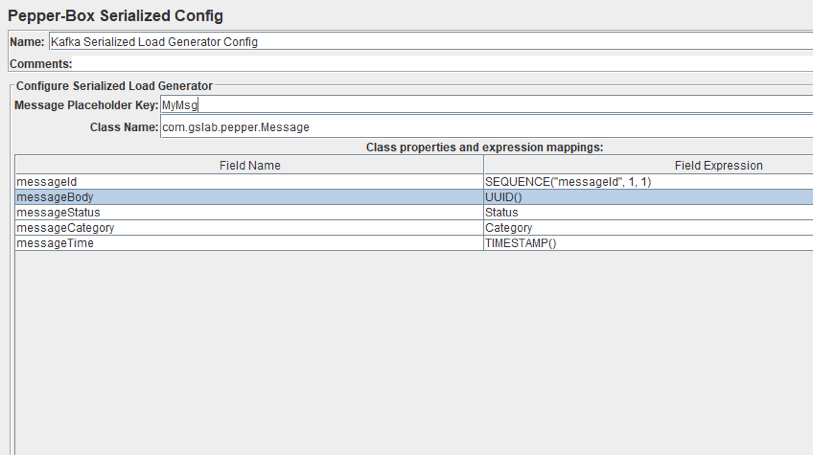
Как вы можете видеть на рисунке выше, элемент имеет поле для ключа и поле Class Name, которое предназначено для указания класса Java. Файл jar с классом должен быть помещен в папку lib / ext . После того, как он указан, поля с его свойствами появятся ниже, и вы можете назначить им нужные значения. Мы повторили сообщение от последнего элемента, но на этот раз это будет объект Java.
PepperBoxKafkaSampler
Чтобы добавить этот элемент, перейдите в группу Thread -> Add -> Sampler -> Java Request . Затем выберите com.gslab.pepper.sampler.PepperBoxKafkaSampler из раскрывающегося списка.
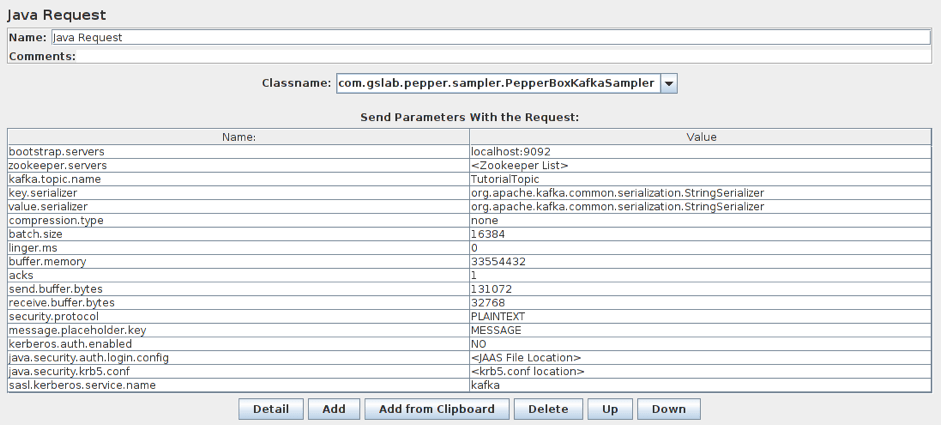
Этот элемент имеет следующие настройки:
- bootstrap.servers / zookeeper.servers — адреса брокеров / zookeepers (zookeeper — это интерфейс, который распределяет нагрузку от производителей между различными брокерами) в формате broker-ip-1: port, broker-ip-2: port , и т.д.
- kafka.topic.name — название темы для публикации сообщения.
- key.serializer — класс для сериализации ключей. Оставьте это без изменений, если в сообщении нет ключа.
- value.serializer — это класс для сериализации сообщений. Для простого текста поле остается неизменным. При использовании Pepper-Box Serialized Config необходимо указать «com.gslab.pepper.input.serialized.ObjectSerializer».
- compress.type — это тип сжатия сообщений (none / gzip / snappy / lz4).
- batch.size — это самый большой размер сообщения.
- linger.ms — время ожидания сообщения.
- buffer.memory — размер буфера производителя.
- acks — это качество обслуживания (-1/0/1 — доставка не гарантируется / сообщение обязательно будет доставлено / сообщение будет доставлено один раз).
- receive.buffer.bytes / send.buffer.bytes — размер буфера отправки / получения TCP. -1 — использовать значение ОС по умолчанию.
- security.protocol — это протокол шифрования (PLAINTEXT / SSL / SASL_PLAINTEXT / SASL_SSL).
- message.placeholder.key — это ключ сообщения, который был указан в предыдущих элементах.
- kerberos.auth.enabled, java.security.auth.login.config, java.security.krb5.conf, sasl.kerberos.service.name — это группа полей, отвечающая за аутентификацию.
Кроме того, при необходимости вы можете добавить дополнительные параметры, используя префикс _ перед именем, например, _ssl.key.password .
Конфигурирование потребителя
Теперь давайте перейдем к потребителю. Хотя производитель создает наибольшую нагрузку на сервер, служба также должна доставлять сообщения. Поэтому мы также должны добавить потребителей, чтобы более точно воспроизводить ситуации. Их также можно использовать для проверки доставки всех сообщений потребителя.
В качестве примера давайте возьмем следующий исходный код и кратко коснемся его шагов:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", group);
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(topic));
System.out.println("Subscribed to topic " + topic);
int i = 0;
while (true) {
ConsumerRecords<String, String> records = con-sumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
} 1. Конфигурация соединения выполнена.
2. Тема должна быть указана и подписка на нее.
3. Сообщения принимаются в цикле этой темы и выводятся на консоль.
Этот код с некоторыми модификациями будет добавлен в JSR223 Sampler в JMeter.
Построение нагрузочного тестирования сценария Apache Kafka в JMeter
Теперь, когда мы изучили все необходимые элементы для создания нагрузки, давайте попробуем опубликовать несколько сообщений в теме нашего сервиса Kafka. Давайте представим, что у нас есть ресурс, с которого собираются данные о его деятельности. Информация будет отправлена в виде XML-документа.
1. Добавьте конфигурацию Pepper-Box PlainText и создайте шаблон. Структура сообщения будет следующей: номер сообщения, идентификатор сообщения, идентификатор элемента, из которого собирается статистика, статистика, отметка даты отправки. Шаблон сообщения показан на скриншоте ниже.
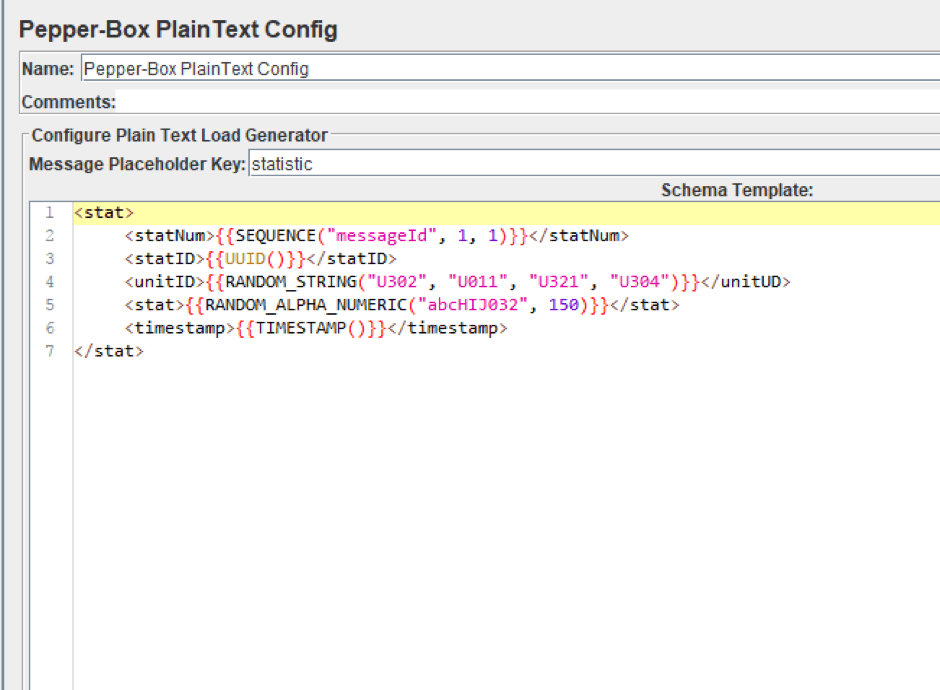
2. Add the PepperBoxKafkaSampler. In it, specify the addresses of bootstrap.servers and kafka.topic.name from our Kafka service. In our case, the address of broker is localhost:9092, the topic for demonstration is TutorialTopic. And we will also specify the placeholder.key from the template element from the previous step.
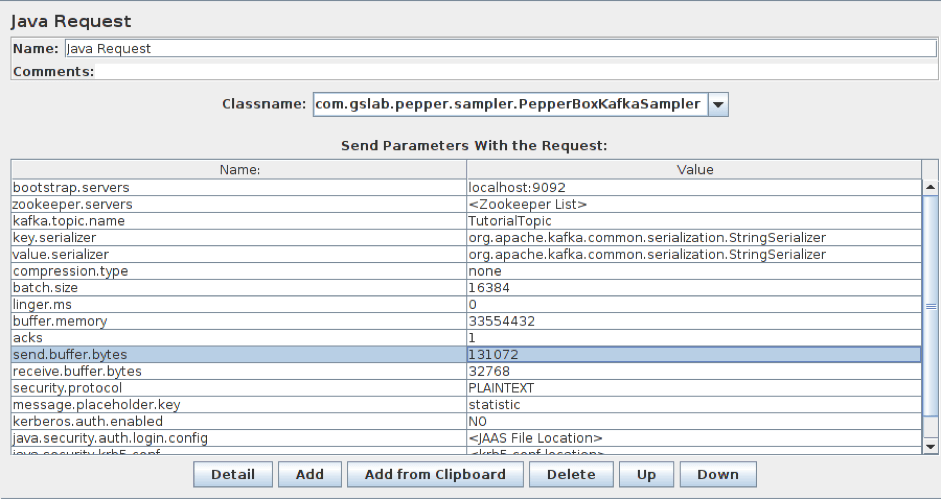
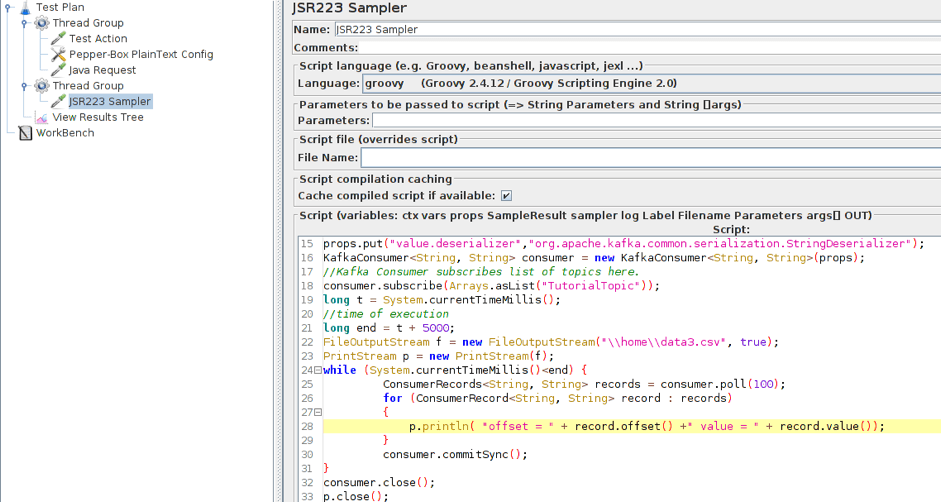
3. Add the JSR223 Sampler with the consumer code to a separate Thread Group. For it to work, you will also need a kafka-clients-x.x.x.x.jar file that contains classes for working with Kafka. You can find it in your Kafka directory — /kafka/lib.
Here, we modified part of the script and now it saves the data to a file rather than displaying it in the console. This has been done for a more convenient analysis of the results. We also added the part that is necessary for setting the execution time of the consumer. For the demonstration, it is set at 5 seconds.
Updated part:
long t = System.currentTimeMillis();
long end = t + 5000;
f = new FileOutputStream(".\\data.csv", true);
p = new PrintStream(f);
while (System.currentTimeMillis()<end)
{
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
{
p.println( "offset = " + record.offset() +" value = " + record.value());
}
consumer.commitSync();
}
consumer.close();
p.close();
f.close();Now the structure of the script looks as follows. Both threads work simultaneously. The Producers begin to publish messages to the specified topics. The Consumers connect to the topics and wait for messages from Kafka. When a message is received by the Consumer, it writes the message to a file.
4. Run the script and view the results.
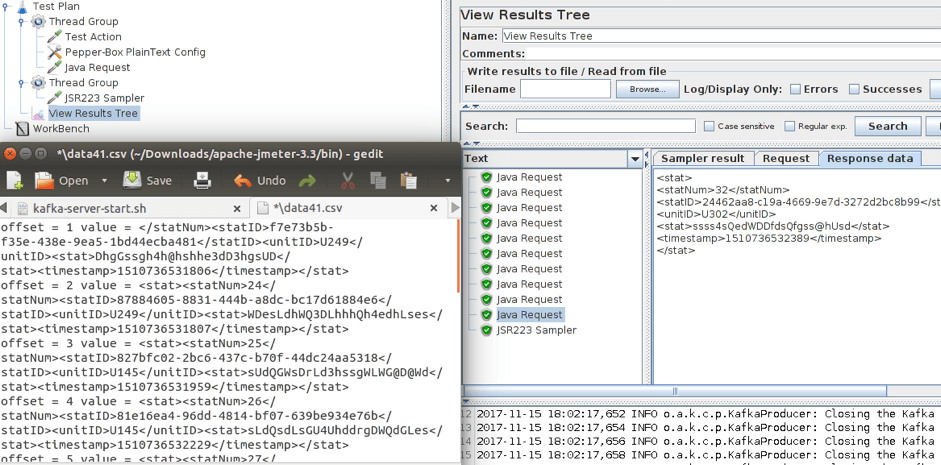
As you can see in the screenshot above, ten messages were sent. You can see the received messages in the opened file. After that, you just have to adjust the number of consumers and producers to increase the load.
It is worth reminding that the Apache Kafka is designed for a large number of connections, so you can simply reach the capacity limit of your network load generator. In which case, JMeter maintains the feature of distributed testing.
I would also like to note that there is no point in using random data for messages during the testing, since they can differ in size significantly from the current ones, and this difference may affect the test results. Please, take test data seriously.
That’s it! You now know how to load test Apache Kafka with JMeter. To learn more advanced JMeter, check out our advanced course from our free JMeter academy.