Подобные схемы действительно работают — они не только привлекают внимание, если содержание также ценно (и в этом случае, поверьте мне), формат статьи может быть чрезвычайно интересным.
Эта статья познакомит вас с 10 трюками SQL, которые многие из вас, возможно, даже не думали, были возможны. Эта статья является кратким изложением моего нового, чрезвычайно быстро развивающегося, смехотворно ребяческого юмора, который я выступаю на конференциях (недавно в JAX и Devoxx France ). Вы можете процитировать меня по этому поводу:
Полные слайды можно увидеть на слайд-шоу:
… и я уверен, что скоро будет запись на видео. Вот 10 хитростей SQL, которые вы не могли себе представить :
Вступление
Чтобы понять значение этих 10 трюков SQL, в первую очередь важно понять контекст языка SQL. Почему я говорю о SQL на конференциях Java? (а я обычно единственный!) Вот почему:

С самого начала у разработчиков языков программирования возникло желание создавать языки, на которых вы сообщаете машине, ЧТО вы хотите получить, а не КАК ее получить. Например, в SQL вы сообщаете компьютеру, что вы хотите «соединить» (JOIN) таблицу пользователей и таблицу адресов и найти пользователей, которые живут в Швейцарии. Вам все равно, КАК база данных будет извлекать эту информацию (например, должна ли таблица пользователей быть загружена первой или таблица адресов? Должны ли эти две таблицы объединяться во вложенном цикле или с помощью хэш-карты? Должны ли все данные сначала загружаться в память и затем фильтруется для швейцарских пользователей, или мы должны загружать только швейцарские адреса в первую очередь? И т.д.)
Как и в случае любой абстракции, вам все равно нужно знать основы того, что происходит за кулисами в базе данных, чтобы помочь базе данных принимать правильные решения при запросе. Например, имеет смысл:
- Установить формальные отношения внешнего ключа между таблицами (это говорит базе данных, что каждому адресу гарантированно соответствует соответствующий пользователь)
- Добавьте индекс в поле поиска: Страна (это говорит базе данных, что конкретные страны можно найти в
O(log N)вместоO(N))
Но как только ваша база данных и ваше приложение станут зрелыми, вы поместите все важные метаданные на место и сможете сосредоточиться только на своей бизнес-логике. Следующие 10 трюков демонстрируют удивительную функциональность, написанную всего лишь несколькими строками декларативного SQL, производя простой и сложный вывод.
1. Все это стол
Это самая тривиальная уловка, и даже не совсем уловка, но она имеет фундаментальное значение для глубокого понимания SQL: все является таблицей ! Когда вы видите SQL-выражение, подобное этому:
|
1
2
|
SELECT *FROM person |
… Вы быстро заметите сидящего за столом person в предложении FROM . Это круто, это стол. Но вы поняли, что все утверждение — это тоже таблица? Например, вы можете написать:
|
1
2
3
4
5
|
SELECT *FROM ( SELECT * FROM person) t |
И теперь вы создали так называемую «производную таблицу» — то есть вложенную SELECT в предложении FROM .
Это тривиально, но если подумать, довольно элегантно. Вы также можете создавать специальные таблицы в памяти с помощью конструктора VALUES() как таковые в некоторых базах данных (например, PostgreSQL, SQL Server):
|
1
2
3
4
|
SELECT *FROM ( VALUES(1),(2),(3)) t(a) |
Который просто дает:
|
1
2
3
4
5
|
a--- 1 2 3 |
Если это предложение не поддерживается, вы можете вернуться к производным таблицам, например, в Oracle:
|
1
2
3
4
5
6
|
SELECT *FROM ( SELECT 1 AS a FROM DUAL UNION ALL SELECT 2 AS a FROM DUAL UNION ALL SELECT 3 AS a FROM DUAL) t |
Теперь, когда вы видите, что VALUES() и производные таблицы на самом деле одно и то же, концептуально, давайте рассмотрим оператор INSERT , который поставляется в двух вариантах:
|
1
2
3
4
5
6
7
8
9
|
-- SQL Server, PostgreSQL, some others:INSERT INTO my_table(a)VALUES(1),(2),(3);-- Oracle, many others:INSERT INTO my_table(a)SELECT 1 AS a FROM DUAL UNION ALLSELECT 2 AS a FROM DUAL UNION ALLSELECT 3 AS a FROM DUAL |
В SQL все является таблицей. Когда вы вставляете строки в таблицу, вы на самом деле не вставляете отдельные строки. Вы действительно вставляете целые таблицы. Большинству людей просто приходится вставлять таблицы из одной строки большую часть времени, и поэтому они не понимают, что на самом деле делает INSERT .
Все это стол. В PostgreSQL четные функции являются таблицами:
|
1
2
|
SELECT *FROM substring('abcde', 2, 3) |
Вышеуказанные выходы:
|
1
2
3
|
substring---------bcd |
Если вы программируете на Java, вы можете использовать аналог Java 8 Stream API, чтобы сделать этот шаг вперед. Рассмотрим следующие эквивалентные понятия:
|
1
2
3
4
5
6
7
8
|
TABLE : Stream<Tuple<..>>SELECT : map() DISTINCT : distinct()JOIN : flatMap()WHERE / HAVING : filter()GROUP BY : collect()ORDER BY : sorted()UNION ALL : concat() |
В Java 8 «все является потоком» (по крайней мере, как только вы начнете работать с потоками). Независимо от того, как вы преобразуете поток, например, с помощью map() или filter() , результирующий тип всегда снова является Stream.
Мы написали целую статью, чтобы объяснить это более глубоко и сравнить API потока с SQL: общие предложения SQL и их эквиваленты в потоках Java 8
И если вы ищете «лучшие потоки» (то есть потоки с еще большей семантикой SQL), ознакомьтесь с jOOλ , библиотекой с открытым исходным кодом, которая переносит оконные функции SQL в Java .
2. Генерация данных с помощью рекурсивного SQL
Распространенные табличные выражения (также: CTE, также называемый факторингом подзапроса, например, в Oracle) — это единственный способ объявить переменные в SQL (кроме неясного предложения WINDOW , которое знают только PostgreSQL и Sybase SQL Anywhere).
Это мощная концепция. Чрезвычайно мощный. Рассмотрим следующее утверждение:
|
1
2
3
4
5
6
7
8
9
|
-- Table variablesWITH t1(v1, v2) AS (SELECT 1, 2), t2(w1, w2) AS ( SELECT v1 * 2, v2 * 2 FROM t1 )SELECT *FROM t1, t2 |
Это дает
|
1
2
3
|
v1 v2 v3 v4----------------- 1 2 2 4 |
Используя простое предложение WITH , вы можете указать список табличных переменных (помните: все является таблицей), которые могут даже зависеть друг от друга.
Это легко понять. Это делает CTE (Common Table Expressions) уже очень полезным, но что действительно здорово, так это то, что им разрешено быть рекурсивными! Рассмотрим следующий пример PostgreSQL:
|
1
2
3
4
5
6
7
8
9
|
WITH RECURSIVE t(v) AS ( SELECT 1 -- Seed Row UNION ALL SELECT v + 1 -- Recursion FROM t)SELECT vFROM tLIMIT 5 |
Это дает
|
1
2
3
4
5
6
7
|
v--- 1 2 3 4 5 |
Как это работает? Это сравнительно легко, когда вы видите через множество ключевых слов. Вы определяете общее табличное выражение, которое имеет ровно два подзапроса UNION ALL .
Первый подзапрос UNION ALL — это то, что я обычно называю «начальным рядом». Это «семена» (инициализирует) рекурсию. Он может создать один или несколько рядов, по которым мы потом вернёмся. Помните: все является таблицей, поэтому наша рекурсия произойдет для всей таблицы, а не для отдельной строки / значения.
Второй подзапрос UNION ALL — это место, где происходит рекурсия. Если вы посмотрите внимательно, вы заметите, что он выбирает из t . Т.е. второму подзапросу разрешено выбирать из того самого CTE, который мы собираемся объявить. Рекурсивный. Таким образом, он также имеет доступ к столбцу v , который объявлен CTE, который уже использует его.
В нашем примере мы заполняем рекурсию строкой (1) , а затем выполняем рекурсию, добавляя v + 1 . Затем рекурсия останавливается на месте использования путем установки LIMIT 5 ( остерегайтесь потенциально бесконечных рекурсий — как в случае Java 8 Streams ).
Примечание: полнота по Тьюрингу
Рекурсивный CTE делает выполнение SQL: 1999 завершенным, что означает, что любая программа может быть написана на SQL! (если вы достаточно сумасшедший)
Один впечатляющий пример, который часто появляется в блогах: набор Мандельброта, например, как показано на http://explainextended.com/2013/12/31/happy-new-year-5/
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
WITH RECURSIVE q(r, i, rx, ix, g) AS ( SELECT r::DOUBLE PRECISION * 0.02, i::DOUBLE PRECISION * 0.02, .0::DOUBLE PRECISION , .0::DOUBLE PRECISION, 0 FROM generate_series(-60, 20) r, generate_series(-50, 50) i UNION ALL SELECT r, i, CASE WHEN abs(rx * rx + ix * ix) <= 2 THEN rx * rx - ix * ix END + r, CASE WHEN abs(rx * rx + ix * ix) <= 2 THEN 2 * rx * ix END + i, g + 1 FROM q WHERE rx IS NOT NULL AND g < 99)SELECT array_to_string(array_agg(s ORDER BY r), '')FROM ( SELECT i, r, substring(' .:-=+*#%@', max(g) / 10 + 1, 1) s FROM q GROUP BY i, r) qGROUP BY iORDER BY i |
Запустите выше на PostgreSQL, и вы получите что-то вроде
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
.-.:-.......==..*.=.::-@@@@@:::.:.@..*-. =. ...=...=...::+%.@:@@@@@@@@@@@@@+*#=.=:+-. ..- .:.:=::*....@@@@@@@@@@@@@@@@@@@@@@@@=@@.....::...:. ...*@@@@=.@:@@@@@@@@@@@@@@@@@@@@@@@@@@=.=....:...::. .::@@@@@:-@@@@@@@@@@@@@@@@@@@@@@@@@@@@:@..-:@=*:::. .-@@@@@-@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@.=@@@@=..: ...@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@:@@@@@:.. ....:-*@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@:: .....@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@-.. .....@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@-:... .--:+.@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@... .==@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@-.. ..+@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@-#. ...=+@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@.. -.=-@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@..: .*%:@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@:@- . ..:... ..-@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@.............. ....-@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@%@=.--.-.....-=.:..........::@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@....=:-....=@+..=.........@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@:..:+@@::@==@-*:%:+.......:@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@.::@@@-@@@@@@@@@-:=.....:@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@:.:@@@@@@@@@@@@@@@=:.....%@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@.:@@@@@@@@@@@@@@@@@-...:@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@:-:@@@@@@@@@@@@@@@@@@@-..%@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@.%@@@@@@@@@@@@@@@@@@@-..-@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@.@@@@@@@@@@@@@@@@@@@@@::+@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@+@@@@@@@@@@@@@@@@@@@@@@:@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@..@@@@@@@@@@@@@@@@@@@@@@-@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@- @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@. |
Впечатляет, а?
3. Выполнение общих расчетов
В этом блоге полно примеров . Они являются одними из наиболее образовательных примеров для изучения продвинутого SQL, потому что есть по крайней мере дюжина способов реализации промежуточного итога.
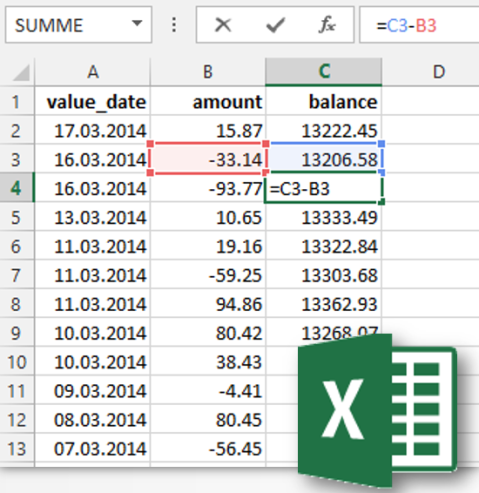
Промежуточный итог легко понять, концептуально.
В Microsoft Excel вы просто вычисляете сумму (или разницу) двух предыдущих (или последующих) значений, а затем используете полезный перекрестный курсор для перемещения этой формулы по всей электронной таблице. Вы «пропускаете» эту сумму через электронную таблицу. «Подводящий итог».
В SQL лучший способ сделать это — использовать оконные функции, еще одну тему, которую этот блог освещал много раз .
Оконные функции — это мощная концепция — поначалу их не так просто понять, но на самом деле они действительно очень просты:
Оконные функции — это агрегаты / ранжирование в подмножестве строк относительно текущей строки, преобразуемой с помощью SELECT
Вот и все.
По сути, это означает, что оконная функция может выполнять вычисления для строк, которые «выше» или «ниже» текущей строки. Однако, в отличие от обычных агрегатов и GROUP BY , они не преобразуют строки, что делает их очень полезными.
Синтаксис может быть кратко изложен следующим образом, отдельные части являются необязательными
|
1
2
3
4
5
|
function(...) OVER ( PARTITION BY ... ORDER BY ... ROWS BETWEEN ... AND ...) |
Итак, у нас есть какая-либо функция (примеры таких функций мы увидим позже), за которой следует предложение OVER() , которое определяет окно. Т.е. это предложение OVER() определяет:
-
PARTITION: Для окна будут рассматриваться только те строки, которые находятся в том же разделе, что и текущая строка. -
ORDER: Окно можно заказать независимо от того, что мы выбираем - Определение
ROWS(илиRANGE): окно может быть ограничено фиксированным количеством строк «впереди» и «позади»
Это все, что нужно для оконных функций.
Теперь, как это поможет нам рассчитать промежуточную сумму? Рассмотрим следующие данные:
|
1
2
3
4
5
6
7
|
| ID | VALUE_DATE | AMOUNT | BALANCE ||------|------------|--------|------------|| 9997 | 2014-03-18 | 99.17 | 19985.81 || 9981 | 2014-03-16 | 71.44 | 19886.64 || 9979 | 2014-03-16 | -94.60 | 19815.20 || 9977 | 2014-03-16 | -6.96 | 19909.80 || 9971 | 2014-03-15 | -65.95 | 19916.76 | |
Давайте предположим, что BALANCE — это то, что мы хотим вычислить из AMOUNT
Интуитивно мы сразу видим, что верно следующее:
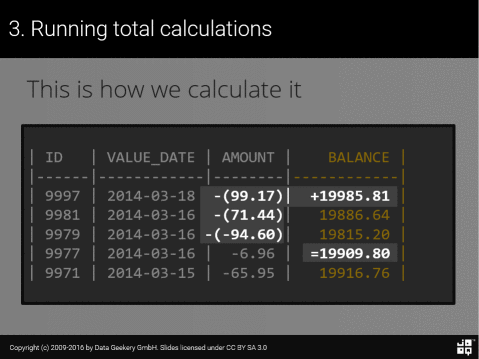
Таким образом, в простом английском языке любой баланс может быть выражен с помощью следующего псевдо SQL:
|
1
2
3
|
TOP_BALANCE - SUM(AMOUNT) OVER ( "all the rows on top of the current row") |
В реальном SQL это будет записано следующим образом:
|
1
2
3
4
5
6
7
|
SUM(t.amount) OVER ( PARTITION BY t.account_id ORDER BY t.value_date DESC, t.id DESC ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) |
Объяснение:
- Раздел рассчитает сумму для каждого банковского счета, а не для всего набора данных
- Порядок гарантирует, что транзакции заказаны (в пределах раздела) до суммирования
- Предложение Строки будут рассматривать только предыдущие строки (в пределах раздела, учитывая порядок) до суммирования
Все это будет происходить в памяти над набором данных, который уже был выбран вами в ваших предложениях FROM .. WHERE и т. Д., И, таким образом, будет чрезвычайно быстрым.
Интермеццо
Прежде чем мы перейдем ко всем другим удивительным трюкам, рассмотрим это: мы видели
- (Рекурсивные) общие табличные выражения (CTE)
- Оконные функции
Обе эти функции:
- Потрясающие
- Очень мощный
- декларативный
- Часть стандарта SQL
- Доступно в большинстве популярных РСУБД (кроме MySQL)
- Очень важные строительные блоки
Если из этой статьи можно сделать вывод, это тот факт, что вы должны абсолютно точно знать эти два строительных блока современного SQL. Почему? Потому как:

4. Нахождение самой большой серии без пробелов
У переполнения стека есть эта очень хорошая функция, чтобы побудить людей оставаться на их сайте как можно дольше. Жетоны:

Для масштаба, вы можете увидеть, сколько значков у меня есть. Тонны.
Как вы рассчитываете эти значки? Давайте посмотрим на «Энтузиаст» и «Фанатик». Эти значки вручаются всем, кто проводит определенное количество дней подряд на своей платформе. Независимо от даты свадьбы или дня рождения жены, вы ДОЛЖНЫ ВОЙТИ, или счетчик снова начинает работать с нуля.
Теперь, когда мы занимаемся декларативным программированием, нам не нужно поддерживать счетчики состояния и памяти. Мы хотим выразить это в форме онлайн-аналитического SQL. Т.е. рассмотрим эти данные:
|
01
02
03
04
05
06
07
08
09
10
11
|
| LOGIN_TIME ||---------------------|| 2014-03-18 05:37:13 || 2014-03-16 08:31:47 || 2014-03-16 06:11:17 || 2014-03-16 05:59:33 || 2014-03-15 11:17:28 || 2014-03-15 10:00:11 || 2014-03-15 07:45:27 || 2014-03-15 07:42:19 || 2014-03-14 09:38:12 | |
Это не очень помогает. Давайте удалим часы из отметки времени. Это легко:
|
1
2
3
4
|
SELECT DISTINCT cast(login_time AS DATE) AS login_dateFROM loginsWHERE user_id = :user_id |
Который дает:
|
1
2
3
4
5
6
|
| LOGIN_DATE ||------------|| 2014-03-18 || 2014-03-16 || 2014-03-15 || 2014-03-14 | |
Теперь, когда мы узнали о оконных функциях, давайте просто добавим простой номер строки к каждой из этих дат:
|
1
2
3
4
|
SELECT login_date, row_number() OVER (ORDER BY login_date)FROM login_dates |
Который производит:
|
1
2
3
4
5
6
|
| LOGIN_DATE | RN ||------------|----|| 2014-03-18 | 4 || 2014-03-16 | 3 || 2014-03-15 | 2 || 2014-03-14 | 1 | |
Все еще легко. Теперь, что произойдет, если вместо того, чтобы выбирать эти значения отдельно, мы вычитаем их?
|
1
2
3
4
|
SELECT login_date - row_number() OVER (ORDER BY login_date)FROM login_dates |
Мы получаем что-то вроде этого:
|
1
2
3
4
5
6
|
| LOGIN_DATE | RN | GRP ||------------|----|------------|| 2014-03-18 | 4 | 2014-03-14 || 2014-03-16 | 3 | 2014-03-13 || 2014-03-15 | 2 | 2014-03-13 || 2014-03-14 | 1 | 2014-03-13 | |
Ух ты. Интересный. Итак, 14 - 1 = 13 , 15 - 2 = 13 , 16 - 3 = 13 , но 18 - 4 = 14 . Никто не может сказать это лучше, чем Дож:

Вот простой пример такого поведения:
- ROW_NUMBER () никогда не имеет пробелов. Вот как это определяется
- Наши данные, однако,
Поэтому, когда мы вычтем серию последовательных целых чисел без пробелов из последовательности непоследовательных дат, мы получим ту же дату для каждой подсерии последовательных дат без пробелов, и мы снова получим новую дату, где у ряда дат были пробелы.
Да.
Это означает, что теперь мы можем просто GROUP BY этому произвольному значению даты:
|
1
2
3
4
5
6
7
|
SELECT min(login_date), max(login_date), max(login_date) - min(login_date) + 1 AS lengthFROM login_date_groupsGROUP BY grpORDER BY length DESC |
И мы сделали. Самая большая серия последовательных дат без пропусков была найдена:
|
1
2
3
4
|
| MIN | MAX | LENGTH ||------------|------------|--------|| 2014-03-14 | 2014-03-16 | 3 || 2014-03-18 | 2014-03-18 | 1 | |
С полным запросом:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
WITH login_dates AS ( SELECT DISTINCT cast(login_time AS DATE) login_date FROM logins WHERE user_id = :user_id ), login_date_groups AS ( SELECT login_date, login_date - row_number() OVER (ORDER BY login_date) AS grp FROM login_dates )SELECT min(login_date), max(login_date), max(login_date) - min(login_date) + 1 AS lengthFROM login_date_groupsGROUP BY grpORDER BY length DESC |

Не так сложно в конце концов, верно? Конечно, сама идея имеет значение, но сам запрос действительно очень прост и элегантен. Ни в коем случае нельзя было бы реализовать какой-либо алгоритм императивного стиля более простым способом, чем этот.
Уф.
5. Нахождение длины серии
Ранее мы видели серию последовательных значений. С этим легко справиться, поскольку мы можем злоупотреблять последовательностью целых чисел. Что, если определение «ряда» менее интуитивно понятно, и, кроме того, несколько рядов содержат одинаковые значения? Рассмотрим следующие данные, где LENGTH — длина каждой серии, которую мы хотим вычислить:
|
01
02
03
04
05
06
07
08
09
10
11
|
| ID | VALUE_DATE | AMOUNT | LENGTH ||------|------------|--------|------------|| 9997 | 2014-03-18 | 99.17 | 2 || 9981 | 2014-03-16 | 71.44 | 2 || 9979 | 2014-03-16 | -94.60 | 3 || 9977 | 2014-03-16 | -6.96 | 3 || 9971 | 2014-03-15 | -65.95 | 3 || 9964 | 2014-03-15 | 15.13 | 2 || 9962 | 2014-03-15 | 17.47 | 2 || 9960 | 2014-03-15 | -3.55 | 1 || 9959 | 2014-03-14 | 32.00 | 1 | |
Да, вы правильно догадались. «Ряд» определяется тем, что последовательные (упорядоченные по идентификатору) строки имеют одинаковый знак (AMOUNT). Проверьте еще раз данные в следующем формате:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
| ID | VALUE_DATE | AMOUNT | LENGTH ||------|------------|--------|------------|| 9997 | 2014-03-18 | +99.17 | 2 || 9981 | 2014-03-16 | +71.44 | 2 || 9979 | 2014-03-16 | -94.60 | 3 || 9977 | 2014-03-16 | - 6.96 | 3 || 9971 | 2014-03-15 | -65.95 | 3 || 9964 | 2014-03-15 | +15.13 | 2 || 9962 | 2014-03-15 | +17.47 | 2 || 9960 | 2014-03-15 | - 3.55 | 1 || 9959 | 2014-03-14 | +32.00 | 1 | |
Как мы делаем это? «Легкий» & # 55357; & # 56841; Во-первых, давайте избавимся от шума и добавим еще один номер строки:
|
1
2
3
4
5
6
|
SELECT id, amount, sign(amount) AS sign, row_number() OVER (ORDER BY id DESC) AS rnFROM trx |
Это даст нам:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
| ID | AMOUNT | SIGN | RN ||------|--------|------|----|| 9997 | 99.17 | 1 | 1 || 9981 | 71.44 | 1 | 2 || 9979 | -94.60 | -1 | 3 || 9977 | -6.96 | -1 | 4 || 9971 | -65.95 | -1 | 5 || 9964 | 15.13 | 1 | 6 || 9962 | 17.47 | 1 | 7 || 9960 | -3.55 | -1 | 8 || 9959 | 32.00 | 1 | 9 | |
Теперь следующая цель — создать следующую таблицу:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
| ID | AMOUNT | SIGN | RN | LO | HI ||------|--------|------|----|----|----|| 9997 | 99.17 | 1 | 1 | 1 | || 9981 | 71.44 | 1 | 2 | | 2 || 9979 | -94.60 | -1 | 3 | 3 | || 9977 | -6.96 | -1 | 4 | | || 9971 | -65.95 | -1 | 5 | | 5 || 9964 | 15.13 | 1 | 6 | 6 | || 9962 | 17.47 | 1 | 7 | | 7 || 9960 | -3.55 | -1 | 8 | 8 | 8 || 9959 | 32.00 | 1 | 9 | 9 | 9 | |
В этой таблице мы хотим скопировать значение номера строки в «LO» в «нижнем» конце серии и в «HI» в «верхнем» конце серии. Для этого мы будем использовать магические LEAD () и LAG (). LEAD () может получить доступ к n-й следующей строке из текущей строки, тогда как LAG () может получить доступ к n-й предыдущей строке из текущей строки. Например:
|
1
2
3
4
5
6
7
|
SELECT lag(v) OVER (ORDER BY v), v, lead(v) OVER (ORDER BY v)FROM ( VALUES (1), (2), (3), (4)) t(v) |
Приведенный выше запрос производит:

Это потрясающе! Помните, что с помощью оконных функций вы можете выполнять ранжирование или агрегирование подмножеств строк относительно текущей строки. В случае LEAD () и LAG () мы просто обращаемся к одной строке относительно текущей строки, учитывая ее смещение. Это полезно во многих случаях.
Продолжая наш пример «LO» и «HI», мы можем просто написать:
|
1
2
3
4
5
6
7
8
9
|
SELECT trx.*, CASE WHEN lag(sign) OVER (ORDER BY id DESC) != sign THEN rn END AS lo, CASE WHEN lead(sign) OVER (ORDER BY id DESC) != sign THEN rn END AS hi,FROM trx |
… В котором мы сравниваем «предыдущий» знак ( lag(sign) ) с «текущим» знаком ( sign ). Если они разные, мы помещаем номер строки в «LO», потому что это нижняя граница нашей серии.
Затем мы сравниваем «следующий» знак ( lead(sign) ) с «текущим» знаком ( sign ). Если они разные, мы помещаем номер строки в «HI», потому что это верхняя граница нашей серии.
Наконец, немного скучная обработка NULL, чтобы все было правильно, и мы сделали:
|
1
2
3
4
5
6
7
8
9
|
SELECT -- With NULL handling... trx.*, CASE WHEN coalesce(lag(sign) OVER (ORDER BY id DESC), 0) != sign THEN rn END AS lo, CASE WHEN coalesce(lead(sign) OVER (ORDER BY id DESC), 0) != sign THEN rn END AS hi,FROM trx |
Следующий шаг. Мы хотим, чтобы «LO» и «HI» появлялись во ВСЕХ строках, а не только в «нижней» и «верхней» границах ряда. Например, вот так:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
| ID | AMOUNT | SIGN | RN | LO | HI ||------|--------|------|----|----|----|| 9997 | 99.17 | 1 | 1 | 1 | 2 || 9981 | 71.44 | 1 | 2 | 1 | 2 || 9979 | -94.60 | -1 | 3 | 3 | 5 || 9977 | -6.96 | -1 | 4 | 3 | 5 || 9971 | -65.95 | -1 | 5 | 3 | 5 || 9964 | 15.13 | 1 | 6 | 6 | 7 || 9962 | 17.47 | 1 | 7 | 6 | 7 || 9960 | -3.55 | -1 | 8 | 8 | 8 || 9959 | 32.00 | 1 | 9 | 9 | 9 | |
Мы используем функцию, которая доступна по крайней мере в Redshift, Sybase SQL Anywhere, DB2, Oracle. Мы используем предложение «IGNORE NULLS», которое можно передать некоторым оконным функциям:
|
01
02
03
04
05
06
07
08
09
10
11
|
SELECT trx.*, last_value (lo) IGNORE NULLS OVER ( ORDER BY id DESC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS lo, first_value(hi) IGNORE NULLS OVER ( ORDER BY id DESC ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS hiFROM trx |
Много ключевых слов! Но суть всегда одна и та же. Из любой данной «текущей» строки мы смотрим на все «предыдущие значения» ( ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW ), но игнорируем все нули. Из этих предыдущих значений мы берем последнее значение, и это наше новое значение «LO». Другими словами, мы берем «ближайшее» значение «LO».
То же самое с «Привет». Из любой данной «текущей» строки мы смотрим на все «последующие значения» ( ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING ), но игнорируем все нули. Из последующих значений мы берем первое значение, и это наше новое значение «HI». Другими словами, мы берем «самое близкое» значение «HI».
Объяснил в Powerpoint:
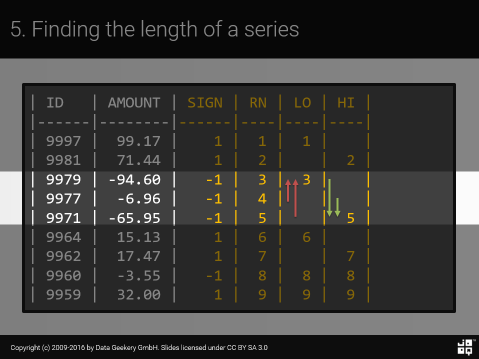
На 100% правильно, с немного скучным NULL теребением
|
01
02
03
04
05
06
07
08
09
10
11
|
SELECT -- With NULL handling... trx.*, coalesce(last_value (lo) IGNORE NULLS OVER ( ORDER BY id DESC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW), rn) AS lo, coalesce(first_value(hi) IGNORE NULLS OVER ( ORDER BY id DESC ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING), rn) AS hiFROM trx |
Наконец, мы просто делаем последний тривиальный шаг, имея в виду ошибки off-by-1:
|
1
2
3
4
|
SELECT trx.*, 1 + hi - lo AS lengthFROM trx |
И мы сделали. Вот наш результат:
|
01
02
03
04
05
06
07
08
09
10
11
|
| ID | AMOUNT | SIGN | RN | LO | HI | LENGTH||------|--------|------|----|----|----|-------|| 9997 | 99.17 | 1 | 1 | 1 | 2 | 2 || 9981 | 71.44 | 1 | 2 | 1 | 2 | 2 || 9979 | -94.60 | -1 | 3 | 3 | 5 | 3 || 9977 | -6.96 | -1 | 4 | 3 | 5 | 3 || 9971 | -65.95 | -1 | 5 | 3 | 5 | 3 || 9964 | 15.13 | 1 | 6 | 6 | 7 | 2 || 9962 | 17.47 | 1 | 7 | 6 | 7 | 2 || 9960 | -3.55 | -1 | 8 | 8 | 8 | 1 || 9959 | 32.00 | 1 | 9 | 9 | 9 | 1 | |
И полный запрос здесь:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
WITH trx1(id, amount, sign, rn) AS ( SELECT id, amount, sign(amount), row_number() OVER (ORDER BY id DESC) FROM trx ), trx2(id, amount, sign, rn, lo, hi) AS ( SELECT trx1.*, CASE WHEN coalesce(lag(sign) OVER (ORDER BY id DESC), 0) != sign THEN rn END, CASE WHEN coalesce(lead(sign) OVER (ORDER BY id DESC), 0) != sign THEN rn END FROM trx1 )SELECT trx2.*, 1 - last_value (lo) IGNORE NULLS OVER (ORDER BY id DESC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) + first_value(hi) IGNORE NULLS OVER (ORDER BY id DESC ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING)FROM trx2 |

Да. Эта вещь SQL начинает становиться интересной!
Готовы к большему?
6. Проблема суммы подмножеств с SQL
Это мой любимый!
Что такое проблема с суммой подмножеств? Найдите интересное объяснение здесь:
https://xkcd.com/287
И скучный здесь:
https://en.wikipedia.org/wiki/Subset_sum_problem
По существу, для каждого из этих итогов …
|
1
2
3
4
5
|
| ID | TOTAL ||----|-------|| 1 | 25150 || 2 | 19800 || 3 | 27511 | |
… Мы хотим найти «наилучшую» (т. Е. Ближайшую) возможную сумму, состоящую из любой комбинации этих элементов:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
| ID | ITEM ||------|-------|| 1 | 7120 || 2 | 8150 || 3 | 8255 || 4 | 9051 || 5 | 1220 || 6 | 12515 || 7 | 13555 || 8 | 5221 || 9 | 812 || 10 | 6562 | |
Поскольку вы все быстро осваиваете свою умственную математическую обработку, вы сразу же подсчитали, что это лучшие суммы:
|
1
2
3
4
5
|
| TOTAL | BEST | CALCULATION|-------|-------|--------------------------------| 25150 | 25133 | 7120 + 8150 + 9051 + 812| 19800 | 19768 | 1220 + 12515 + 5221 + 812| 27511 | 27488 | 8150 + 8255 + 9051 + 1220 + 812 |
Как это сделать с SQL? Легко. Просто создайте CTE, который содержит все 2 n * возможные * суммы, а затем найдите ближайший для каждого TOTAL :
|
1
2
3
4
5
6
7
8
9
|
-- All the possible 2N sumsWITH sums(sum, max_id, calc) AS (...)-- Find the best sum per “TOTAL”SELECT totals.total, something_something(total - sum) AS best, something_something(total - sum) AS calcFROM draw_the_rest_of_the_*bleep*_owl |
Когда вы читаете это, вы можете быть как мой друг здесь:

Но не волнуйтесь, решение — опять же — не так уж сложно (хотя оно не работает из-за природы алгоритма):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
WITH sums(sum, id, calc) AS ( SELECT item, id, to_char(item) FROM items UNION ALL SELECT item + sum, items.id, calc || ' + ' || item FROM sums JOIN items ON sums.id < items.id)SELECT totals.id, totals.total, min (sum) KEEP ( DENSE_RANK FIRST ORDER BY abs(total - sum) ) AS best, min (calc) KEEP ( DENSE_RANK FIRST ORDER BY abs(total - sum) ) AS calc,FROM totals CROSS JOIN sumsGROUP BY totals.id, totals.total |
В этой статье я не буду объяснять детали этого решения, потому что пример взят из предыдущей статьи, которую вы можете найти здесь:
Как найти ближайшую сумму подмножества с помощью SQL
Наслаждайтесь чтением деталей, но не забудьте вернуться сюда для оставшихся 4 трюков:
7. Покрытие промежуточного итога
До сих пор мы видели, как вычислить «обычную» промежуточную сумму с помощью SQL с помощью оконных функций . Это было просто. А как насчет того, чтобы ограничить текущую сумму так, чтобы она никогда не опускалась ниже нуля? По сути, мы хотим рассчитать это:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
| DATE | AMOUNT | TOTAL ||------------|--------|-------|| 2012-01-01 | 800 | 800 || 2012-02-01 | 1900 | 2700 || 2012-03-01 | 1750 | 4450 || 2012-04-01 | -20000 | 0 || 2012-05-01 | 900 | 900 || 2012-06-01 | 3900 | 4800 || 2012-07-01 | -2600 | 2200 || 2012-08-01 | -2600 | 0 || 2012-09-01 | 2100 | 2100 || 2012-10-01 | -2400 | 0 || 2012-11-01 | 1100 | 1100 || 2012-12-01 | 1300 | 2400 | |
Таким образом, когда -15550 тот большой отрицательный AMOUNT -20000 , вместо того, чтобы отображать реальный TOTAL -15550 , мы просто отображали 0 . Другими словами (или наборы данных):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
| DATE | AMOUNT | TOTAL ||------------|--------|-------|| 2012-01-01 | 800 | 800 | GREATEST(0, 800)| 2012-02-01 | 1900 | 2700 | GREATEST(0, 2700)| 2012-03-01 | 1750 | 4450 | GREATEST(0, 4450)| 2012-04-01 | -20000 | 0 | GREATEST(0, -15550)| 2012-05-01 | 900 | 900 | GREATEST(0, 900)| 2012-06-01 | 3900 | 4800 | GREATEST(0, 4800)| 2012-07-01 | -2600 | 2200 | GREATEST(0, 2200)| 2012-08-01 | -2600 | 0 | GREATEST(0, -400)| 2012-09-01 | 2100 | 2100 | GREATEST(0, 2100)| 2012-10-01 | -2400 | 0 | GREATEST(0, -300)| 2012-11-01 | 1100 | 1100 | GREATEST(0, 1100)| 2012-12-01 | 1300 | 2400 | GREATEST(0, 2400) |
Как мы это сделаем?

Точно. С неясным, специфичным для поставщика SQL. В этом случае мы используем Oracle SQL

Как это работает? Удивительно легко!
Просто добавьте MODEL после любой таблицы, и вы откроете банку удивительных SQL-червей!
|
1
2
3
4
|
SELECT ... FROM some_table-- Put this after any tableMODEL ... |
MODEL туда MODEL , мы можем реализовать логику электронных таблиц непосредственно в наших инструкциях SQL, как и в Microsoft Excel.
Следующие три предложения являются наиболее полезными и широко используемыми (т.е. 1-2 на человека в год на этой планете):
|
1
2
3
4
5
6
7
8
9
|
MODEL -- The spreadsheet dimensions DIMENSION BY ... -- The spreadsheet cell type MEASURES ... -- The spreadsheet formulas RULES ... |
Смысл каждого из этих трех дополнительных пунктов лучше всего объяснить слайдами снова.
Предложение DIMENSION BY определяет размеры вашей электронной таблицы. В отличие от MS Excel, в Oracle вы можете иметь любое количество измерений:
Предложение MEASURES определяет значения, доступные в каждой ячейке вашей электронной таблицы. В отличие от MS Excel, в каждой ячейке Oracle может быть целый кортеж, а не одно значение.

Предложение RULES определяет формулы, которые применяются к каждой ячейке в вашей электронной таблице. В отличие от MS Excel, эти правила / формулы централизованы в одном месте, а не помещаются внутри каждой ячейки:

Этот дизайн делает модель немного сложнее в использовании, чем MS Excel, но гораздо более мощной, если вы решитесь. Тогда весь запрос будет «тривиально»:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
SELECT *FROM ( SELECT date, amount, 0 AS total FROM amounts)MODEL DIMENSION BY (row_number() OVER (ORDER BY date) AS rn) MEASURES (date, amount, total) RULES ( total[any] = greatest(0, coalesce(total[cv(rn) - 1], 0) + amount[cv(rn)]) ) |
Все это настолько мощно, что поставляется с собственным техническим документом Oracle, поэтому вместо того, чтобы объяснять подробности здесь, в этой статье, прочитайте превосходный технический документ:
8. Распознавание паттернов временных рядов
Если вы занимаетесь обнаружением мошенничества или любой другой областью, в которой анализ больших объемов данных выполняется в режиме реального времени, то распознавание образов временных рядов, безусловно, не является для вас новым термином.
Если мы рассмотрим набор данных «длина ряда», нам может потребоваться сгенерировать триггеры для сложных событий в нашем временном ряду как таковой:
|
01
02
03
04
05
06
07
08
09
10
11
|
| ID | VALUE_DATE | AMOUNT | LEN | TRIGGER|------|------------|---------|-----|--------| 9997 | 2014-03-18 | + 99.17 | 1 || 9981 | 2014-03-16 | - 71.44 | 4 || 9979 | 2014-03-16 | - 94.60 | 4 | x| 9977 | 2014-03-16 | - 6.96 | 4 || 9971 | 2014-03-15 | - 65.95 | 4 || 9964 | 2014-03-15 | + 15.13 | 3 || 9962 | 2014-03-15 | + 17.47 | 3 || 9960 | 2014-03-15 | + 3.55 | 3 || 9959 | 2014-03-14 | - 32.00 | 1 | |
Правило вышеупомянутого триггера:
Активизировать 3- е повторение события, если событие происходит более 3 раз.
Как и в предыдущем предложении MODEL , мы можем сделать это с помощью специального предложения Oracle, которое было добавлено в Oracle 12c:
|
1
2
3
4
5
|
SELECT ... FROM some_table-- Put this after any table to pattern-match-- the table’s contentsMATCH_RECOGNIZE (...) |
Простейшее возможное применение MATCH_RECOGNIZE включает в себя следующие подпункты:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
SELECT *FROM seriesMATCH_RECOGNIZE ( -- Pattern matching is done in this order ORDER BY ... -- These are the columns produced by matches MEASURES ... -- A short specification of what rows are -- returned from each match ALL ROWS PER MATCH -- «Regular expressions» of events to match PATTERN (...) -- The definitions of «what is an event» DEFINE ...) |
Это звучит безумно Давайте посмотрим на некоторые примеры реализации предложений
|
01
02
03
04
05
06
07
08
09
10
11
|
SELECT *FROM seriesMATCH_RECOGNIZE ( ORDER BY id MEASURES classifier() AS trg ALL ROWS PER MATCH PATTERN (S (R X R+)?) DEFINE R AS sign(R.amount) = prev(sign(R.amount)), X AS sign(X.amount) = prev(sign(X.amount))) |
Что мы здесь делаем?
- Мы упорядочиваем таблицу по
ID, который является порядком, в котором мы хотим сопоставить события. Легко. - Затем мы указываем значения, которые мы хотим в результате. Нам нужен trg «MEASURE», который определяется как классификатор, то есть литерал, который мы будем использовать в
PATTERNпозже. Кроме того, мы хотим, чтобы все строки соответствовали друг другу. - Затем мы указываем шаблон, подобный регулярному выражению. Шаблон представляет собой событие «S» для запуска, за которым, возможно, следует «R» для повтора, «X» для нашего специального события X, за которым следует один или несколько «R» для повторения снова. Если весь шаблон соответствует, мы получаем SRXR или SRXRR или SRXRRR, то есть X будет в третьей позиции серии длины> = 4
- Наконец, мы определяем R и X как одно и то же: событие, когда
SIGN(AMOUNT)текущей строки совпадает сSIGN(AMOUNT)предыдущей строки. Нам не нужно определять «S». «S» — это просто любой другой ряд.
Этот запрос волшебным образом выдаст следующий результат:
|
01
02
03
04
05
06
07
08
09
10
11
|
| ID | VALUE_DATE | AMOUNT | TRG ||------|------------|---------|-----|| 9997 | 2014-03-18 | + 99.17 | S || 9981 | 2014-03-16 | - 71.44 | R || 9979 | 2014-03-16 | - 94.60 | X || 9977 | 2014-03-16 | - 6.96 | R || 9971 | 2014-03-15 | - 65.95 | S || 9964 | 2014-03-15 | + 15.13 | S || 9962 | 2014-03-15 | + 17.47 | S || 9960 | 2014-03-15 | + 3.55 | S || 9959 | 2014-03-14 | - 32.00 | S | |
Мы можем видеть один «X» в нашем потоке событий. Именно там, где мы этого ожидали. При 3-м повторении события (того же знака) в серии длиной> 3.
Boom!
Поскольку нас не интересуют события «S» и «R», давайте просто удалим их как таковые:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
SELECT id, value_date, amount, CASE trg WHEN 'X' THEN 'X' END trgFROM seriesMATCH_RECOGNIZE ( ORDER BY id MEASURES classifier() AS trg ALL ROWS PER MATCH PATTERN (S (R X R+)?) DEFINE R AS sign(R.amount) = prev(sign(R.amount)), X AS sign(X.amount) = prev(sign(X.amount))) |
производить:
|
01
02
03
04
05
06
07
08
09
10
11
|
| ID | VALUE_DATE | AMOUNT | TRG ||------|------------|---------|-----|| 9997 | 2014-03-18 | + 99.17 | || 9981 | 2014-03-16 | - 71.44 | || 9979 | 2014-03-16 | - 94.60 | X || 9977 | 2014-03-16 | - 6.96 | || 9971 | 2014-03-15 | - 65.95 | || 9964 | 2014-03-15 | + 15.13 | || 9962 | 2014-03-15 | + 17.47 | || 9960 | 2014-03-15 | + 3.55 | || 9959 | 2014-03-14 | - 32.00 | | |
Спасибо Оракул!

Опять же, не ожидайте, что я объясню это лучше, чем превосходный технический документ Oracle, который я настоятельно рекомендую прочитать, если вы все равно используете Oracle 12c:
9. Поворот и разворот
Если вы прочитали это далеко, следующее будет почти слишком смущающе простым:
Это наши данные, то есть актеры, названия фильмов и рейтинги фильмов:
|
1
2
3
4
5
6
7
8
9
|
| NAME | TITLE | RATING ||-----------|-----------------|--------|| A. GRANT | ANNIE IDENTITY | G || A. GRANT | DISCIPLE MOTHER | PG || A. GRANT | GLORY TRACY | PG-13 || A. HUDSON | LEGEND JEDI | PG || A. CRONYN | IRON MOON | PG || A. CRONYN | LADY STAGE | PG || B. WALKEN | SIEGE MADRE | R | |
Это то, что мы называем поворотом:
|
1
2
3
4
5
6
7
8
9
|
| NAME | NC-17 | PG | G | PG-13 | R ||-----------|-------|-----|-----|-------|-----|| A. GRANT | 3 | 6 | 5 | 3 | 1 || A. HUDSON | 12 | 4 | 7 | 9 | 2 || A. CRONYN | 6 | 9 | 2 | 6 | 4 || B. WALKEN | 8 | 8 | 4 | 7 | 3 || B. WILLIS | 5 | 5 | 14 | 3 | 6 || C. DENCH | 6 | 4 | 5 | 4 | 5 || C. NEESON | 3 | 8 | 4 | 7 | 3 | |
Обратите внимание на то, как мы сгруппированы по актерам, а затем «определили» количество фильмов по рейтингу, в котором играл каждый актер. Вместо того, чтобы показывать это «реляционным» способом (то есть каждая группа представляет собой ряд), мы повели все это, чтобы получить столбец на группу. Мы можем сделать это, потому что мы знаем все возможные группы заранее.
Отключение происходит наоборот, когда из вышесказанного мы хотим вернуться к представлению «строка на группу»:
|
1
2
3
4
5
6
7
8
9
|
| NAME | RATING | COUNT ||-----------|--------|-------|| A. GRANT | NC-17 | 3 || A. GRANT | PG | 6 || A. GRANT | G | 5 || A. GRANT | PG-13 | 3 || A. GRANT | R | 6 || A. HUDSON | NC-17 | 12 || A. HUDSON | PG | 4 | |
Это на самом деле очень просто. Вот как мы это сделаем в PostgreSQL:
|
01
02
03
04
05
06
07
08
09
10
11
|
SELECT first_name, last_name, count(*) FILTER (WHERE rating = 'NC-17') AS "NC-17", count(*) FILTER (WHERE rating = 'PG' ) AS "PG", count(*) FILTER (WHERE rating = 'G' ) AS "G", count(*) FILTER (WHERE rating = 'PG-13') AS "PG-13", count(*) FILTER (WHERE rating = 'R' ) AS "R"FROM actor AS aJOIN film_actor AS fa USING (actor_id)JOIN film AS f USING (film_id)GROUP BY actor_id |
Мы можем добавить простое предложение FILTER к статистической функции, чтобы подсчитать только некоторые данные.
Во всех других базах данных мы бы сделали это так:
|
01
02
03
04
05
06
07
08
09
10
11
|
SELECT first_name, last_name, count(CASE rating WHEN 'NC-17' THEN 1 END) AS "NC-17", count(CASE rating WHEN 'PG' THEN 1 END) AS "PG", count(CASE rating WHEN 'G' THEN 1 END) AS "G", count(CASE rating WHEN 'PG-13' THEN 1 END) AS "PG-13", count(CASE rating WHEN 'R' THEN 1 END) AS "R"FROM actor AS aJOIN film_actor AS fa USING (actor_id)JOIN film AS f USING (film_id)GROUP BY actor_id |
Здесь хорошо то, что агрегатные функции обычно учитывают только NULL значения, поэтому, если мы сделаем все значения NULL , которые не интересны для агрегации, мы получим тот же результат.
Теперь, если вы используете либо SQL Server, либо Oracle, вы можете вместо этого использовать встроенные предложения PIVOT или UNPIVOT . Опять же, как в случае с MODEL или MATCH_RECOGNIZE , просто добавьте это новое ключевое слово после таблицы и получите тот же результат:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
-- PIVOTINGSELECT something, somethingFROM some_tablePIVOT ( count(*) FOR rating IN ( 'NC-17' AS "NC-17", 'PG' AS "PG", 'G' AS "G", 'PG-13' AS "PG-13", 'R' AS "R" ))-- UNPIVOTINGSELECT something, somethingFROM some_tableUNPIVOT ( count FOR rating IN ( "NC-17" AS 'NC-17', "PG" AS 'PG', "G" AS 'G', "PG-13" AS 'PG-13', "R" AS 'R' )) |
Легко. Следующий.
10. Злоупотребление XML и JSON
Прежде всего

JSON — это просто XML с меньшими возможностями и меньшим синтаксисом
Теперь все знают, что XML потрясающий. Следствие таково:
JSON менее классный
Не используйте JSON.
Теперь, когда мы решили эту проблему, мы можем спокойно проигнорировать постоянную рекламу JSON-in-the-the-database-обман (о чем большинство из вас пожалеет через пять лет) и перейти к последнему примеру. Как сделать XML в базе данных.
Вот что мы хотим сделать:
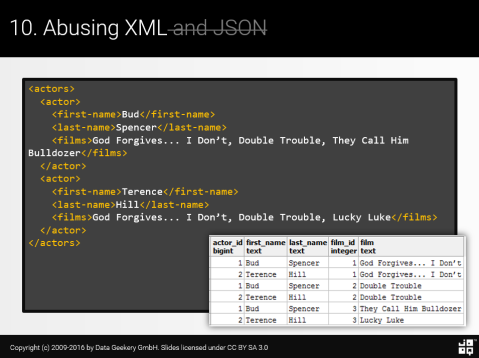
Учитывая исходный документ XML, мы хотим проанализировать этот документ, развернуть список фильмов, разделенных запятыми, на каждого актера и создать денормализованное представление актеров / фильмов в одном отношении.
Готовы. Поставил. Идти.Это идея. У нас есть три CTE:
|
01
02
03
04
05
06
07
08
09
10
11
|
WITH RECURSIVE x(v) AS (SELECT '...'::xml), actors( actor_id, first_name, last_name, films ) AS (...), films( actor_id, first_name, last_name, film_id, film ) AS (...)SELECT * FROM films |
В первом мы просто анализируем XML. Вот с PostgreSQL:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
WITH RECURSIVE x(v) AS (SELECT '<actors> <actor> <first-name>Bud</first-name> <last-name>Spencer</last-name> <films>God Forgives... I Don’t, Double Trouble, They Call Him Bulldozer</films> </actor> <actor> <first-name>Terence</first-name> <last-name>Hill</last-name> <films>God Forgives... I Don’t, Double Trouble, Lucky Luke</films> </actor></actors>'::xml), actors(actor_id, first_name, last_name, films) AS (...), films(actor_id, first_name, last_name, film_id, film) AS (...)SELECT * FROM films |
Легко.
Затем мы делаем магию XPath, чтобы извлечь отдельные значения из структуры XML и поместить их в столбцы:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
WITH RECURSIVE x(v) AS (SELECT '...'::xml), actors(actor_id, first_name, last_name, films) AS ( SELECT row_number() OVER (), (xpath('//first-name/text()', t.v))[1]::TEXT, (xpath('//last-name/text()' , t.v))[1]::TEXT, (xpath('//films/text()' , t.v))[1]::TEXT FROM unnest(xpath('//actor', (SELECT v FROM x))) t(v) ), films(actor_id, first_name, last_name, film_id, film) AS (...)SELECT * FROM films |
Все еще легко.
Наконец, немного магии рекурсивного сопоставления с шаблоном регулярных выражений, и все готово!
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
WITH RECURSIVE x(v) AS (SELECT '...'::xml), actors(actor_id, first_name, last_name, films) AS (...), films(actor_id, first_name, last_name, film_id, film) AS ( SELECT actor_id, first_name, last_name, 1, regexp_replace(films, ',.+', '') FROM actors UNION ALL SELECT actor_id, a.first_name, a.last_name, f.film_id + 1, regexp_replace(a.films, '.*' || f.film || ', ?(.*?)(,.+)?', '\1') FROM films AS f JOIN actors AS a USING (actor_id) WHERE a.films NOT LIKE '%' || f.film )SELECT * FROM films |
Давайте подведем итоги:

Вывод
Все, что показала эта статья, было декларативным. И относительно легко. Конечно, для забавного эффекта, которого я пытаюсь достичь в этом выступлении, был взят некоторый преувеличенный SQL, и я прямо назвал все «легким». Это совсем не просто, вы должны практиковать SQL. Как и многие другие языки, но немного сложнее, потому что:
- Синтаксис время от времени немного неудобен
- Декларативное мышление не легко. По крайней мере, это очень разные
Но как только вы это освоите, декларативное программирование с использованием SQL полностью того стоит, поскольку вы можете выразить сложные отношения между вашими данными в очень очень небольшом коде, просто описав результат, который вы хотите получить из базы данных.
Разве это не круто?
And if that was a bit over the top, do note that I’m happy to visit your JUG / conference to give this talk ( just contact us ), or if you want to get really down into the details of these things, we also offer this talk as a public or in-house workshop . Do get in touch! We’re looking forward.
See again the full set of slides here:
| Ссылка: | 10 SQL Tricks That You Didn’t Think Were Possible from our JCG partner Lukas Eder at the JAVA, SQL, AND JOOQ blog. |