Я использовал расширение под названием XHP. Он включает синтаксис HTML-in-PHP для генерации разметки интерфейса. Я достиг этого недавно и с удивлением обнаружил, что он больше не поддерживается официально для современных версий PHP.
Итак, я решил реализовать его версию для пользователя, используя базовый компилятор конечного автомата. Казалось, что это будет веселый проект для вас!
Код для этого урока можно найти на Github .

Создание компиляторов
Многие разработчики избегают писать свои собственные компиляторы или интерпретаторы, думая, что тема слишком сложна или трудна для правильного изучения. Я тоже так чувствовал. Компиляторы могут быть сложными для создания, а тема может быть невероятно сложной и сложной. Но это не значит, что вы не можете создать компилятор.
Создание компилятора похоже на создание бутерброда. Любой может достать ингредиенты и собрать их вместе. Вы можете сделать бутерброд. Вы также можете пойти в школу шеф-поваров и узнать, как приготовить лучший чертов бутерброд, который когда-либо видел мир. Вы можете изучать искусство приготовления бутербродов в течение многих лет, и люди могут говорить о ваших бутербродах в других странах. Вы не позволите широте и сложности приготовления бутерброда помешать вам сделать свой первый бутерброд, не так ли?
Компиляторы (и интерпретаторы) начинаются со скромных манипуляций со строками и временных переменных. Когда они достаточно популярны (или достаточно медленны), тогда могут вмешаться эксперты; заменить строковые манипуляции и временные переменные слезами единорога и цинизмом.
На фундаментальном уровне компиляторы берут строку кода и выполняют ее через несколько шагов:
-
Код разбит на токены — значащие символы и подстроки — которые компилятор будет использовать для получения значения. Заявление
if (isEmergency) alert("there is an emergency")может содержать токены, такие какif,isEmergency,alertи"there is an emergency"; и все это что-то значит для компилятора.Первый шаг — разделить весь исходный код на эти значащие биты, чтобы компилятор мог начать организовывать их в логическую иерархию, чтобы он знал, что делать с кодом.
-
Токены расположены в логической иерархии (иногда называемой абстрактным синтаксическим деревом), которая представляет то, что необходимо сделать в программе. Предыдущее утверждение можно понимать как «Работать, если условие (
isEmergency) оценивается как истинное. Если это так, запустите функцию (alert) с параметром ("there is an emergency") ».
Используя эту иерархию, код может быть немедленно выполнен (в случае интерпретатора или виртуальной машины) или переведен на другие языки (в случае таких языков, как CoffeeScript и TypeScript, которые являются языками компиляции в Javascript).
В нашем случае мы хотим сохранить большую часть синтаксиса PHP, но мы также хотим добавить наш собственный небольшой синтаксис сверху. Мы могли бы создать совершенно новый интерпретатор … или мы могли бы предварительно обработать новый синтаксис, скомпилировав его в синтаксически правильный код PHP.
Я уже писал о предварительной обработке PHP , и это мой любимый подход к добавлению нового синтаксиса. В этом случае нам нужно написать более сложный скрипт; поэтому мы будем отклоняться от того, как мы ранее добавили новый синтаксис.
Генерация токенов
Давайте создадим функцию для разделения кода на токены. Это начинается так:
function tokens($code) { $tokens = []; $length = strlen($code); $cursor = 0; while ($cursor < $length) { if ($code[$cursor] === "{") { print "ATTRIBUTE STARTED ({$cursor})" . PHP_EOL; } if ($code[$cursor] === "}") { print "ATTRIBUTE ENDED ({$cursor})" . PHP_EOL; } if ($code[$cursor] === "<") { print "ELEMENT STARTED ({$cursor})" . PHP_EOL; } if ($code[$cursor] === ">") { print "ELEMENT ENDED ({$cursor})" . PHP_EOL; } $cursor++; } } $code = ' <?php $classNames = "foo bar"; $message = "hello world"; $thing = ( <div className={() => { return "outer-div"; }} nested={<span className={"nested-span"}>with text</span>} > a bit of text before <span> {$message} with a bit of extra text </span> a bit of text after </div> ); '; tokens($code); // ELEMENT STARTED (5) // ELEMENT STARTED (95) // ATTRIBUTE STARTED (122) // ELEMENT ENDED (127) // ATTRIBUTE STARTED (129) // ATTRIBUTE ENDED (151) // ATTRIBUTE ENDED (152) // ATTRIBUTE STARTED (173) // ELEMENT STARTED (174) // ATTRIBUTE STARTED (190) // ATTRIBUTE ENDED (204) // ELEMENT ENDED (205) // ELEMENT STARTED (215) // ELEMENT ENDED (221) // ATTRIBUTE ENDED (222) // ELEMENT ENDED (232) // ELEMENT STARTED (279) // ELEMENT ENDED (284) // ATTRIBUTE STARTED (302) // ATTRIBUTE ENDED (311) // ELEMENT STARTED (350) // ELEMENT ENDED (356) // ELEMENT STARTED (398) // ELEMENT ENDED (403)
Это из
tokens-1.php
Мы хорошо начали. Проходя по коду, мы можем проверить, что представляет собой каждый символ (и определить те, которые важны для нас). Например, мы видим, что первый элемент открывается, когда мы встречаем символ < в индексе 5. Первый элемент закрывается в индексе 210.
К сожалению, это первое открытие неправильно соответствует <?php . Это не элемент в нашем новом синтаксисе, поэтому мы должны помешать коду выбрать его:
preg_match("#^</?[a-zA-Z]#", substr($code, $cursor, 3), $matchesStart); if (count($matchesStart)) { print "ELEMENT STARTED ({$cursor})" . PHP_EOL; } // ... // ELEMENT STARTED (95) // ATTRIBUTE STARTED (122) // ELEMENT ENDED (127) // ATTRIBUTE STARTED (129) // ATTRIBUTE ENDED (151) // ATTRIBUTE ENDED (152) // ATTRIBUTE STARTED (173) // ELEMENT STARTED (174) // ...
Это из
tokens-2.php
Вместо проверки только текущего символа наш новый код проверяет три символа: соответствуют ли они шаблону <div или </div , но не <?php или $num1 < $num2 .
Есть еще одна проблема: в нашем примере используется синтаксис функции стрелки, поэтому => сопоставляется как последовательность закрытия элемента. Давайте уточним, как мы сопоставляем последовательности закрытия элементов:
preg_match("#^=>#", substr($code, $cursor - 1, 2), $matchesEqualBefore); preg_match("#^>=#", substr($code, $cursor, 2), $matchesEqualAfter); if ($code[$cursor] === ">" && !$matchesEqualBefore && !$matchesEqualAfter) { print "ELEMENT ENDED ({$cursor})" . PHP_EOL; } // ... // ELEMENT STARTED (95) // ATTRIBUTE STARTED (122) // ATTRIBUTE STARTED (129) // ATTRIBUTE ENDED (151) // ATTRIBUTE ENDED (152) // ATTRIBUTE STARTED (173) // ELEMENT STARTED (174) // ...
Это из
tokens-3.php
Как и в случае с JSX, для атрибутов было бы хорошо разрешить динамические значения (даже если эти значения являются вложенными элементами JSX). Есть несколько способов сделать это, но я предпочитаю обрабатывать все атрибуты как текст и рекурсивно их токенизировать. Чтобы сделать это, нам нужен некий конечный автомат, который отслеживает, насколько глубоко мы находимся в элементе и атрибуте. Если мы находимся внутри тега элемента, мы должны перехватить верхний уровень {…} в качестве значения строкового атрибута и игнорировать последующие фигурные скобки. Аналогично, если мы находимся внутри атрибута, мы должны игнорировать последовательности открытия и закрытия вложенных элементов:
function tokens($code) { $tokens = []; $length = strlen($code); $cursor = 0; $elementLevel = 0; $elementStarted = null; $elementEnded = null; $attributes = []; $attributeLevel = 0; $attributeStarted = null; $attributeEnded = null; while ($cursor < $length) { $extract = trim(substr($code, $cursor, 5)) . "..."; if ($code[$cursor] === "{" && $elementStarted !== null) { if ($attributeLevel === 0) { print "ATTRIBUTE STARTED ({$cursor}, {$extract})" . PHP_EOL; $attributeStarted = $cursor; } $attributeLevel++; } if ($code[$cursor] === "}" && $elementStarted !== null) { $attributeLevel--; if ($attributeLevel === 0) { print "ATTRIBUTE ENDED ({$cursor})" . PHP_EOL; $attributeEnded = $cursor; } } preg_match("#^</?[a-zA-Z]#", substr($code, $cursor, 3), $matchesStart); if (count($matchesStart) && $attributeLevel < 1) { print "ELEMENT STARTED ({$cursor}, {$extract})" . PHP_EOL; $elementLevel++; $elementStarted = $cursor; } preg_match("#^=>#", substr($code, $cursor - 1, 2), $matchesEqualBefore); preg_match("#^>=#", substr($code, $cursor, 2), $matchesEqualAfter); if ( $code[$cursor] === ">" && !$matchesEqualBefore && !$matchesEqualAfter && $attributeLevel < 1 ) { print "ELEMENT ENDED ({$cursor})" . PHP_EOL; $elementLevel--; $elementEnded = $cursor; } if ($elementStarted && $elementEnded) { // TODO $elementStarted = null; $elementEnded = null; } $cursor++; } } // ... // ELEMENT STARTED (95, <div...) // ATTRIBUTE STARTED (122, {() =...) // ATTRIBUTE ENDED (152) // ATTRIBUTE STARTED (173, {<spa...) // ATTRIBUTE ENDED (222) // ELEMENT ENDED (232) // ELEMENT STARTED (279, <span...) // ELEMENT ENDED (284) // ELEMENT STARTED (350, </spa...) // ELEMENT ENDED (356) // ELEMENT STARTED (398, </div...) // ELEMENT ENDED (403)
Это из
tokens-4.php
Мы добавили новые переменные $attributeLevel , $attributeStarted и $attributeEnded ; чтобы проследить, насколько глубоко мы находимся во вложении атрибутов, и где начинается и заканчивается верхний уровень. В частности, если мы находимся на верхнем уровне, когда значение атрибута начинается или заканчивается, мы фиксируем текущую позицию курсора. Позже мы будем использовать это, чтобы извлечь значение строкового атрибута и заменить его заполнителем.
Мы также начинаем захватывать $elementStarted и $elementEnded (с $elementLevel выполняющим роль, аналогичную $attributeLevel ), чтобы мы могли захватить полный открывающий или закрывающий тег элемента. В этом случае $elementEnded относится не к закрывающему тегу, а к закрывающей последовательности символов открывающего тега. Закрывающие теги обрабатываются как отдельные токены…
После извлечения небольшой подстроки после текущей позиции курсора, мы можем видеть, что элементы и атрибуты начинаются и заканчиваются именно там, где мы ожидаем. Вложенные управляющие структуры и элементы фиксируются как строки, оставляя только элементы верхнего уровня, вложенные элементы без атрибутов и значения атрибутов.
Давайте упакуем эти токены, связав атрибуты с тегами, в которых они определены:
function tokens($code) { $tokens = []; $length = strlen($code); $cursor = 0; $elementLevel = 0; $elementStarted = null; $elementEnded = null; $attributes = []; $attributeLevel = 0; $attributeStarted = null; $attributeEnded = null; $carry = 0; while ($cursor < $length) { if ($code[$cursor] === "{" && $elementStarted !== null) { if ($attributeLevel === 0) { $attributeStarted = $cursor; } $attributeLevel++; } if ($code[$cursor] === "}" && $elementStarted !== null) { $attributeLevel--; if ($attributeLevel === 0) { $attributeEnded = $cursor; } } if ($attributeStarted && $attributeEnded) { $position = (string) count($attributes); $positionLength = strlen($position); $attribute = substr( $code, $attributeStarted + 1, $attributeEnded - $attributeStarted - 1 ); $attributes[$position] = $attribute; $before = substr($code, 0, $attributeStarted + 1); $after = substr($code, $attributeEnded); $code = $before . $position . $after; $cursor = $attributeStarted + $positionLength + 2 /* curlies */; $length = strlen($code); $attributeStarted = null; $attributeEnded = null; continue; } preg_match("#^</?[a-zA-Z]#", substr($code, $cursor, 3), $matchesStart); if (count($matchesStart) && $attributeLevel < 1) { $elementLevel++; $elementStarted = $cursor; } preg_match("#^=>#", substr($code, $cursor - 1, 2), $matchesEqualBefore); preg_match("#^>=#", substr($code, $cursor, 2), $matchesEqualAfter); if ( $code[$cursor] === ">" && !$matchesEqualBefore && !$matchesEqualAfter && $attributeLevel < 1 ) { $elementLevel--; $elementEnded = $cursor; } if ($elementStarted !== null && $elementEnded !== null) { $distance = $elementEnded - $elementStarted; $carry += $cursor; $before = trim(substr($code, 0, $elementStarted)); $tag = trim(substr($code, $elementStarted, $distance + 1)); $after = trim(substr($code, $elementEnded + 1)); $token = ["tag" => $tag, "started" => $carry]; if (count($attributes)) { $token["attributes"] = $attributes; } $tokens[] = $before; $tokens[] = $token; $attributes = []; $code = $after; $length = strlen($code); $cursor = 0; $elementStarted = null; $elementEnded = null; continue; } $cursor++; } return $tokens; } $code = ' <?php $classNames = "foo bar"; $message = "hello world"; $thing = ( <div className={() => { return "outer-div"; }} nested={<span className={"nested-span"}>with text</span>} > a bit of text before <span> {$message} with a bit of extra text </span> a bit of text after </div> ); '; tokens($code); // Array // ( // [0] => <?php // // $classNames = "foo bar"; // $message = "hello world"; // // $thing = ( // [1] => Array // ( // [tag] => <div className={0} nested={1}> // [started] => 157 // [attributes] => Array // ( // [0] => () => { return "outer-div"; } // [1] => <span className={"nested-span"}>with text</span> // ) // // ) // // [2] => a bit of text before // [3] => Array // ( // [tag] => <span> // [started] => 195 // ) // // [4] => {$message} with a bit of extra text // [5] => Array // ( // [tag] => </span> // [started] => 249 // ) // // [6] => a bit of text after // [7] => Array // ( // [tag] => </div> // [started] => 282 // ) // // )
Это из
tokens-5.php
Здесь много чего происходит, но все это просто естественный прогресс по сравнению с предыдущей версией. Мы используем начальные и конечные позиции захваченного атрибута, чтобы извлечь все значение атрибута в виде одной большой строки. Затем мы заменяем каждый захваченный атрибут числовым заполнителем и сбрасываем строку кода и позиции курсора.
Когда каждый элемент закрывается, мы связываем все атрибуты с момента открытия элемента и создаем отдельный маркер массива из тега (с его заполнителями), атрибутов и начальной позиции. Результат может быть немного сложнее для чтения, но он точен с точки зрения захвата цели кода.
Итак, что мы будем делать с этими атрибутами вложенных элементов?
function tokens($code) { // ... while ($cursor < $length) { // ... if ($elementStarted !== null && $elementEnded !== null) { // ... foreach ($attributes as $key => $value) { $attributes[$key] = tokens($value); } if (count($attributes)) { $token["attributes"] = $attributes; } // ... } $cursor++; } $tokens[] = trim($code); return $tokens; } // ... // Array // ( // [0] => <?php // // $classNames = "foo bar"; // $message = "hello world"; // // $thing = ( // [1] => Array // ( // [tag] => <div className={0} nested={1}> // [started] => 157 // [attributes] => Array // ( // [0] => Array // ( // [0] => () => { return "outer-div"; } // ) // // [1] => Array // ( // [1] => Array // ( // [tag] => <span className={0}> // [started] => 19 // [attributes] => Array // ( // [0] => Array // ( // [0] => "nested-span" // ) // // ) // // ) // // [2] => with text // [3] => Array // ( // [tag] => </span> // [started] => 34 // ) // ) // // ) // // ) // // ...
Это из
tokens-5.php(модифицировано)
Прежде чем связать атрибуты, мы перебираем их и маркируем их значения с помощью рекурсивного вызова функции. Нам также нужно добавить любой оставшийся текст (не внутри атрибута или тега элемента) в массив токенов, иначе он будет проигнорирован.
Результатом является список токенов, которые могут иметь вложенные списки токенов. Это уже почти АСТ.
Организация токенов
Давайте превратим этот список токенов в нечто более похожее на AST. Первый шаг — исключить закрывающие теги, которые соответствуют открывающим тегам. Нам нужно определить, какие токены являются тегами:
function nodes($tokens) { $cursor = 0; $length = count($tokens); while ($cursor < $length) { $token = $tokens[$cursor]; if (is_array($token)) { print $token["tag"] . PHP_EOL; } $cursor++; } } $tokens = [ 0 => '<?php $classNames = "foo bar"; $message = "hello world"; $thing = (', 1 => [ 'tag' => '<div className={0} nested={1}>', 'started' => 157, 'attributes' => [ 0 => [ 0 => '() => { return "outer-div"; }', ], 1 => [ 1 => [ 'tag' => '<span className={0}>', 'started' => 19, 'attributes' => [ 0 => [ 0 => '"nested-span"', ], ], ], 2 => 'with text</span>', ], ], ], 2 => 'a bit of text before', 3 => [ 'tag' => '<span>', 'started' => 195, ], 4 => '{$message} with a bit of extra text', 5 => [ 'tag' => '</span>', 'started' => 249, ], 6 => 'a bit of text after', 7 => [ 'tag' => '</div>', 'started' => 282, ], 8 => ');', ]; nodes($tokens); // <div className={0} nested={1}> // <span> // </span> // </div>
Это из
nodes-1.php
Я извлек список токенов из последнего скрипта токена, так что мне больше не нужно запускать и отлаживать эту функцию. Внутри цикла, похожего на тот, который мы использовали во время токенизации, мы печатаем только теги элемента без атрибутов. Давайте выясним, являются ли они открывающими или закрывающими тегами, а также совпадают ли закрывающие теги с открывающими:
function nodes($tokens) { $cursor = 0; $length = count($tokens); while ($cursor < $length) { $token = $tokens[$cursor]; if (is_array($token) && $token["tag"][1] !== "/") { preg_match("#^<([a-zA-Z]+)#", $token["tag"], $matches); print "OPENING {$matches[1]}" . PHP_EOL; } if (is_array($token) && $token["tag"][1] === "/") { preg_match("#^</([a-zA-Z]+)#", $token["tag"], $matches); print "CLOSING {$matches[1]}" . PHP_EOL; } $cursor++; } return $tokens; } // ... // OPENING div // OPENING span // CLOSING span // CLOSING div
Это из
nodes-1.php(модифицировано)
Теперь, когда мы знаем, какие теги открывают, а какие закрывают; мы можем использовать ссылочные переменные для построения дерева:
function nodes($tokens) { $nodes = []; $current = null; $cursor = 0; $length = count($tokens); while ($cursor < $length) { $token =& $tokens[$cursor]; if (is_array($token) && $token["tag"][1] !== "/") { preg_match("#^<([a-zA-Z]+)#", $token["tag"], $matches); if ($current !== null) { $token["parent"] =& $current; $current["children"][] =& $token; } else { $token["parent"] = null; $nodes[] =& $token; } $current =& $token; $current["name"] = $matches[1]; $current["children"] = []; if (isset($current["attributes"])) { foreach ($current["attributes"] as $key => $value) { $current["attributes"][$key] = nodes($value); } $current["attributes"] = array_map(function($item) { foreach ($item as $value) { if (isset($value["tag"])) { return $value; } } foreach ($item as $value) { if (!empty($value["token"])) { return $value; } } return null; }, $current["attributes"]); } } else if (is_array($token) && $token["tag"][1] === "/") { preg_match("#^</([a-zA-Z]+)#", $token["tag"], $matches); if ($current === null) { throw new Exception("no open tag"); } if ($matches[1] !== $current["name"]) { throw new Exception("no matching open tag"); } if ($current !== null) { $current =& $current["parent"]; } } else if ($current !== null) { array_push($current["children"], [ "parent" => &$current, "token" => &$token, ]); } else { array_push($nodes, [ "token" => $token, ]); } $cursor++; } return $nodes; } // ... // Array // ( // [0] => Array // ( // [token] => <?php // // $classNames = "foo bar"; // $message = "hello world"; // // $thing = ( // ) // // [1] => Array // ( // [tag] => <div className={0} nested={1}> // [started] => 157 // [attributes] => Array // ( // [0] => Array // ( // [token] => () => { return "outer-div"; } // ) // // [1] => Array // ( // [tag] => <span className={0}> // [started] => 19 // [attributes] => Array // ( // [0] => Array // ( // [token] => "nested-span" // ) // // ) // // [parent] => // [name] => span // [children] => Array // ( // [0] => Array // ( // [parent] => *RECURSION* // [token] => with text // ) // // ) // // ) // // ) // // [parent] => // [name] => div // [children] => Array // ( // [0] => Array // ( // [parent] => *RECURSION* // [token] => a bit of text before // ) // // [1] => Array // ( // [tag] => <span> // [started] => 195 // [parent] => *RECURSION* // [name] => span // [children] => Array // ( // [0] => Array // ( // [parent] => *RECURSION* // [token] => {$message} with ... // ) // // ) // // ) // // [2] => Array // ( // [parent] => *RECURSION* // [token] => a bit of text after // ) // // ) // // ) // // [2] => Array // ( // [token] => ); // ) // // )
Это из
nodes-2.php
Потратьте некоторое время на изучение того, что здесь происходит. Мы создаем массив $nodes , в котором хранятся новые, организованные структуры узлов. У нас также есть переменная $current , которой мы присваиваем каждый открывающий тег тег по ссылке Таким образом, мы можем перейти в каждый элемент (открывающий тег, закрывающий тег и токены между ними); а также отступить, когда мы встретим закрывающий тег.
Ссылки являются наиболее сложной частью этого, но они необходимы для того, чтобы код был относительно простым. Я имею в виду, это не так просто; но это намного проще, чем не-справочная версия.
У нас нет самой чистой функции с точки зрения рекурсивной работы. Таким образом, когда мы пропускаем атрибуты через функцию nodes , мы иногда получаем пустые атрибуты «токена» вместе с атрибутами вложенного тега. Из-за этого нам необходимо отфильтровать атрибуты, чтобы сначала попытаться вернуть вложенный тег, а затем вернуть непустое значение атрибута токена. Это может быть убрано немного …
Код переписывания
Теперь, когда код аккуратно упорядочен в иерархии или AST, мы можем переписать его в действительный код PHP. Давайте начнем с написания только строковых токенов (которые не вложены в элементы) и форматирования полученного кода:
function parse($nodes) { $code = ""; foreach ($nodes as $node) { if (isset($node["token"])) { $code .= $node["token"] . PHP_EOL; } } return $code; } $nodes = [ 0 => [ 'token' => '<?php $classNames = "foo bar"; $message = "hello world"; $thing = (', ], 1 => [ 'tag' => '<div className={0} nested={1}>', 'started' => 157, 'attributes' => [ 0 => [ 'token' => '() => { return "outer-div"; }', ], 1 => [ 'tag' => '<span className={0}>', 'started' => 19, 'attributes' => [ 0 => [ 'token' => '"nested-span"', ], ], 'name' => 'span', 'children' => [ 0 => [ 'token' => 'with text', ], ], ], ], 'name' => 'div', 'children' => [ 0 => [ 'token' => 'a bit of text before', ], 1 => [ 'tag' => '<span>', 'started' => 195, 'name' => 'span', 'children' => [ 0 => [ 'token' => '{$message} with a bit of extra text', ], ], ], 2 => [ 'token' => 'a bit of text after', ], ], ], 2 => [ 'token' => ');', ], ]; parse($nodes); // <?php // // $classNames = "foo bar"; // $message = "hello world"; // // $thing = ( // );
Это из
parser-1.php
Я скопировал узлы, извлеченные из предыдущего скрипта, поэтому нам не нужно снова отлаживать или повторно использовать эту функцию. Давайте разберемся и с элементами:
require __DIR__ . "/vendor/autoload.php"; function parse($nodes) { $code = ""; foreach ($nodes as $node) { if (isset($node["token"])) { $code .= $node["token"] . PHP_EOL; } if (isset($node["tag"])) { $props = []; $attributes = []; $elements = []; if (isset($node["attributes"])) { foreach ($node["attributes"] as $key => $value) { if (isset($value["token"])) { $attributes["attr_{$key}"] = $value["token"]; } if (isset($value["tag"])) { $elements[$key] = true; $attributes["attr_{$key}"] = parse([$value]); } } } preg_match_all("#([a-zA-Z]+)={([^}]+)}#", $node["tag"], $dynamic); preg_match_all("#([a-zA-Z]+)=[']([^']+)[']#", $node["tag"], $static); if (count($dynamic[0])) { foreach($dynamic[1] as $key => $value) { $props["{$value}"] = $attributes["attr_{$key}"]; } } if (count($static[1])) { foreach($static[1] as $key => $value) { $props["{$value}"] = $static[2][$key]; } } $code .= "pre_" . $node["name"] . "([" . PHP_EOL; foreach ($props as $key => $value) { $code .= "'{$key}' => {$value}," . PHP_EOL; } $code .= "])" . PHP_EOL; } } $code = Pre\Plugin\expand($code); $code = Pre\Plugin\formatCode($code); return $code; } // ... // <?php // // $classNames = "foo bar"; // $message = "hello world"; // // $thing = ( // pre_div([ // 'className' => function () { // return "outer-div"; // }, // 'nested' => pre_span([ // 'className' => "nested-span", // ]), // ]) // );
Это из
parser-2.php
Когда мы находим узел тега, мы перебираем атрибуты и создаем новый массив атрибутов, который является либо просто текстом из узлов маркера, либо анализирует теги из узлов тега. Этот бит рекурсии имеет дело с возможностью атрибутов, которые являются вложенными элементами. Наше регулярное выражение обрабатывает только атрибуты, заключенные в одинарные кавычки (для простоты). Не стесняйтесь делать более полное выражение, обрабатывать более сложный синтаксис и значения атрибутов.
Я установил pre/short-closures , чтобы функция стрелки была расширена до обычной функции:
composer require pre/short-closures
Там также есть функция форматирования PSR-2, поэтому наш код отформатирован в соответствии со стандартом.
Наконец, нам нужно разобраться с детьми:
require __DIR__ . "/vendor/autoload.php"; function parse($nodes) { $code = ""; foreach ($nodes as $node) { if (isset($node["token"])) { $code .= $node["token"] . PHP_EOL; } if (isset($node["tag"])) { // ... $children = []; foreach ($node["children"] as $child) { if (isset($child["tag"])) { $children[] = parse([$child]); } else { $children[] = "\"" . addslashes($child["token"]) . "\""; } } $props["children"] = $children; $code .= "pre_" . $node["name"] . "([" . PHP_EOL; foreach ($props as $key => $value) { if ($key === "children") { $code .= "\"children\" => [" . PHP_EOL; foreach ($children as $child) { $code .= "{$child}," . PHP_EOL; } $code .= "]," . PHP_EOL; } else { $code .= "\"{$key}\" => {$value}," . PHP_EOL; } } $code .= "])" . PHP_EOL; } } $code = Pre\Plugin\expand($code); $code = Pre\Plugin\formatCode($code); return $code; } // ... // <?php // // $classNames = "foo bar"; // $message = "hello world"; // // $thing = ( // pre_div([ // "className" => function () { // return "outer-div"; // }, // "nested" => pre_span([ // "className" => "nested-span", // "children" => [ // "with text", // ], // ]), // "children" => [ // "a bit of text before", // pre_span([ // "children" => [ // "{$message} with a bit of extra text", // ], // ]), // "a bit of text after", // ], // ]) // );
Это из
parser-3.php
Мы анализируем каждый дочерний тег и напрямую заключаем в кавычки каждый дочерний токен (добавляя косую черту для учета вложенных кавычек). Затем, когда мы создаем массив параметров; мы перебираем дочерние элементы и добавляем каждый в строку кода, которую в конечном итоге возвращает наша функция parse .
Каждый тег преобразуется в эквивалентную pre_div или pre_span . Это механизм-заполнитель для более крупной системы примитивных элементов. Мы можем продемонстрировать это, заглушив эти функции:
require __DIR__ . "/vendor/autoload.php"; function pre_div($props) { $code = "<div"; if (isset($props["className"])) { if (is_callable($props["className"])) { $class = $props["className"](); } else { $class = $props["className"]; } $code .= " class='{$class}'"; } $code .= ">"; foreach ($props["children"] as $child) { $code .= $child; } $code .= "</div>"; return trim($code); } function pre_span($props) { $code = pre_div($props); $code = preg_replace("#^<div#", "<span", $code); $code = preg_replace("#div>$#", "span>", $code); return $code; } function parse($nodes) { // ... } $nodes = [ 0 => [ 'token' => '<?php $classNames = "foo bar"; $message = "hello world"; $thing = (', ], 1 => [ 'tag' => '<div className={0} nested={1}>', 'started' => 157, 'attributes' => [ 0 => [ 'token' => '() => { return $classNames; }', ], 1 => [ 'tag' => '<span className={0}>', 'started' => 19, 'attributes' => [ 0 => [ 'token' => '"nested-span"', ], ], 'name' => 'span', 'children' => [ 0 => [ 'token' => 'with text', ], ], ], ], 'name' => 'div', 'children' => [ 0 => [ 'token' => 'a bit of text before', ], 1 => [ 'tag' => '<span>', 'started' => 195, 'name' => 'span', 'children' => [ 0 => [ 'token' => '{$message} with a bit of extra text', ], ], ], 2 => [ 'token' => 'a bit of text after', ], ], ], 2 => [ 'token' => ');', ], 3 => [ 'token' => 'print $thing;', ], ]; eval(substr(parse($nodes), 5)); // <div class='foo bar'> // a bit of text before // <span> // hello world with a bit of extra text // </span> // a bit of text after // </div>
Это из
parser-4.php
Я изменил входные узлы, так что $thing будет напечатан. Если мы реализуем наивную версию pre_div и pre_span то этот код выполняется успешно. В это трудно поверить, учитывая, как мало кода мы написали …
Интеграция с Pre
Вопрос в том, что нам с этим делать?
Это интересный эксперимент, но он не очень полезен. Что было бы лучше, так это иметь возможность добавить это в существующий проект и поэкспериментировать с проектированием на основе компонентов в реальном мире. С этой целью я расширил Pre, чтобы разрешить использование пользовательских компиляторов (наряду с пользовательскими определениями макросов, которые он уже позволяет).
Затем я упаковал tokens , nodes и функции parse в библиотеку многократного использования. Это заняло довольно много времени, и между первым созданием функций и созданием примера приложения с их использованием я немного их улучшил. Некоторые улучшения были небольшими (например, создание набора примитивов компонентов HTML), а некоторые были большими (например, рефакторинг выражений и разрешение пользовательских классов компонентов).
Я не собираюсь обсуждать все эти изменения, но я хотел бы показать вам, как выглядит этот пример приложения. Он начинается с серверного скрипта:
use Silex\Application; use Silex\Provider\SessionServiceProvider; use Symfony\Component\HttpFoundation\Request; use App\Component\AddTask; use App\Component\Page; use App\Component\TaskList; $app = new Application(); $app->register(new SessionServiceProvider()); $app->get("/", (Request $request) => { $session = $request->getSession(); $tasks = $session->get("tasks", []); return ( <Page> <TaskList>{$tasks}</TaskList> <AddTask></AddTask> </Page> ); }); $app->post("/add", (Request $request) => { $session = $request->getSession(); $id = $session->get("id", 0); $tasks = $session->get("tasks", []); $tasks[] = [ "id" => $id++, "text" => $request->get("text"), ]; $session->set("id", $id); $session->set("tasks", $tasks); return $app->redirect("/"); }); $app->get("/remove/{id}", (Request $request, $id) => { $session = $request->getSession(); $tasks = $session->get("tasks", []); $tasks = array_filter($tasks, ($task) => { return $task["id"] !== (int) $id; }); $session->set("tasks", $tasks); return $app->redirect("/"); }); $app->run();
Это из
server.pre
Приложение построено поверх Silex , который представляет собой аккуратный микро-фреймворк. Чтобы загрузить этот серверный скрипт, у меня есть индексный файл:
require __DIR__ . "/../vendor/autoload.php"; Pre\Plugin\process(__DIR__ . "/../server.pre");
Это из
public/index.php
… И я служу этому с:
php -S localhost:8080 -t public public/index.php
Я еще не пробовал запускать это через веб-сервер, такой как Apache или Nginx. Я полагаю, что это будет работать примерно так же.
Серверные сценарии начинаются с того, что я настраиваю сервер Silex. Я определяю несколько маршрутов, первый из которых выбирает массив задач из текущего сеанса. Если этот массив не был определен, я по умолчанию устанавливаю пустой массив.
Я передаю их напрямую, как TaskList компонента TaskList . Я обернул это, и компонент AddTask , внутри компонента Page . Компонент Page выглядит так:
namespace App\Component; use InvalidArgumentException; class Page { public function render($props) { assert($this->hasValid($props)); { $children } = $props; return ( "<!doctype html>". <html lang="en"> <body> {$children} </body> </html> ); } private function hasValid($props) { if (empty($props["children"])) { throw new InvalidArgumentException("page needs content (children)"); } return true; } }
Это из
app/Component/Page.pre
Этот компонент не является строго обязательным, но я хочу объявить тип документа и освободить место для будущих заголовочных объектов (таких как таблицы стилей и мета-теги). Я деструктурирую ассоциативный массив $props (используя некоторый синтаксис pre/collections ) и передаю его в элемент <body> .
Тогда есть компонент TaskList :
namespace App\Component; class TaskList { public function render($props) { { $children } = $props; return ( <ul className={"task-list"}> {$this->children($children)} </ul> ); } private function children($children) { if (count($children)) { return {$children}->map(($task) => { return ( <Task id={$task["id"]}>{$task["text"]}</Task> ); }); } return ( <span>No tasks</span> ); } }
Это из
app/Component/TaskList.pre
Элементы могут иметь динамические атрибуты. Фактически, эта библиотека не поддерживает их с буквальными (заключенными в кавычки) значениями атрибута. Их сложно поддерживать, в дополнение к этим динамическим значениям атрибутов. Я определяю атрибут className ; который поддерживает несколько разных форматов:
- Выражение буквального значения, например
"task-list" - Массив (или объект
pre/collectionключа), например["first", "second"] - Ассоциативный массив (или объект
pre/collectionключом), например,["first" => true, "second" => false]
Это похоже на атрибут className в ReactJS. Форма с ключами или объектами использует достоверность значений, чтобы определить, добавляются ли ключи к атрибуту
classэлемента.
Все элементы по умолчанию поддерживают устаревшие и неэкспериментальные атрибуты, определенные в документации по Mozilla Developer Network. Все элементы поддерживают ассоциативный массив для своего атрибута style , который использует форму kebab-case ключей стиля CSS.
Наконец, все элементы поддерживают атрибуты aria- и aria- , и все значения атрибутов могут быть функциями, которые возвращают свои истинные значения (как форма отложенной загрузки).
Давайте посмотрим на компонент Task :
namespace App\Component; use InvalidArgumentException; class Task { public function render($props) { assert($this->hasValid($props)); { $children, $id } = $props; return ( <li className={"task"}> {$children} <a href={"/remove/{$id}"}>remove</a> </li> ); } private function hasValid($props) { if (!isset($props["id"])) { throw new InvalidArgumentException("task needs id (attribute)"); } if (empty($props["children"])) { throw new InvalidArgumentException("task needs text (children)"); } return true; } }
Это из
app/Component/Task.pre
Каждая задача ожидает id определенный для каждой задачи (которую определяет server.pre ), и некоторые дочерние server.pre . Дочерние элементы используются для текстового представления задачи и определяются в месте создания задач в компоненте TaskList .
Наконец, давайте посмотрим на компонент AddTask :
namespace App\Component; class AddTask { public function render($props) { return ( <form method={"post"} action={"/add"} className={"add-task"}> <input name={"text"} type={"text"} /> <button type={"submit"}>add</button> </form> ); } }
Это из
app/Component/AddTask.pre
Этот компонент демонстрирует самозакрывающийся компонент input и немного другое. Конечно, функции добавления и удаления должны быть определены (в скрипте сервера):
$app->post("/add", (Request $request) => { $session = $request->getSession(); $id = $session->get("id", 1); $tasks = $session->get("tasks", []); $tasks[] = [ "id" => $id++, "text" => $request->get("text"), ]; $session->set("id", $id); $session->set("tasks", $tasks); return $app->redirect("/"); }); $app->get("/remove/{id}", (Request $request, $id) => { $session = $request->getSession(); $tasks = $session->get("tasks", []); $tasks = array_filter($tasks, ($task) => { return $task["id"] !== (int) $id; }); $session->set("tasks", $tasks); return $app->redirect("/"); });
Это из
server.pre
Мы ничего не храним в базе данных, но мы могли бы. Эти компоненты и сценарии — все, что есть в примере приложения. Это не огромный пример, но он демонстрирует различные важные вещи, такие как вложение компонентов и итеративный рендеринг компонентов.
Это также хороший пример того, как некоторые из макросов Pre хорошо работают вместе; особенно короткие замыкания, коллекции, а в некоторых случаях асинхронные / ожидающие.
Вот гиф из этого в действии.
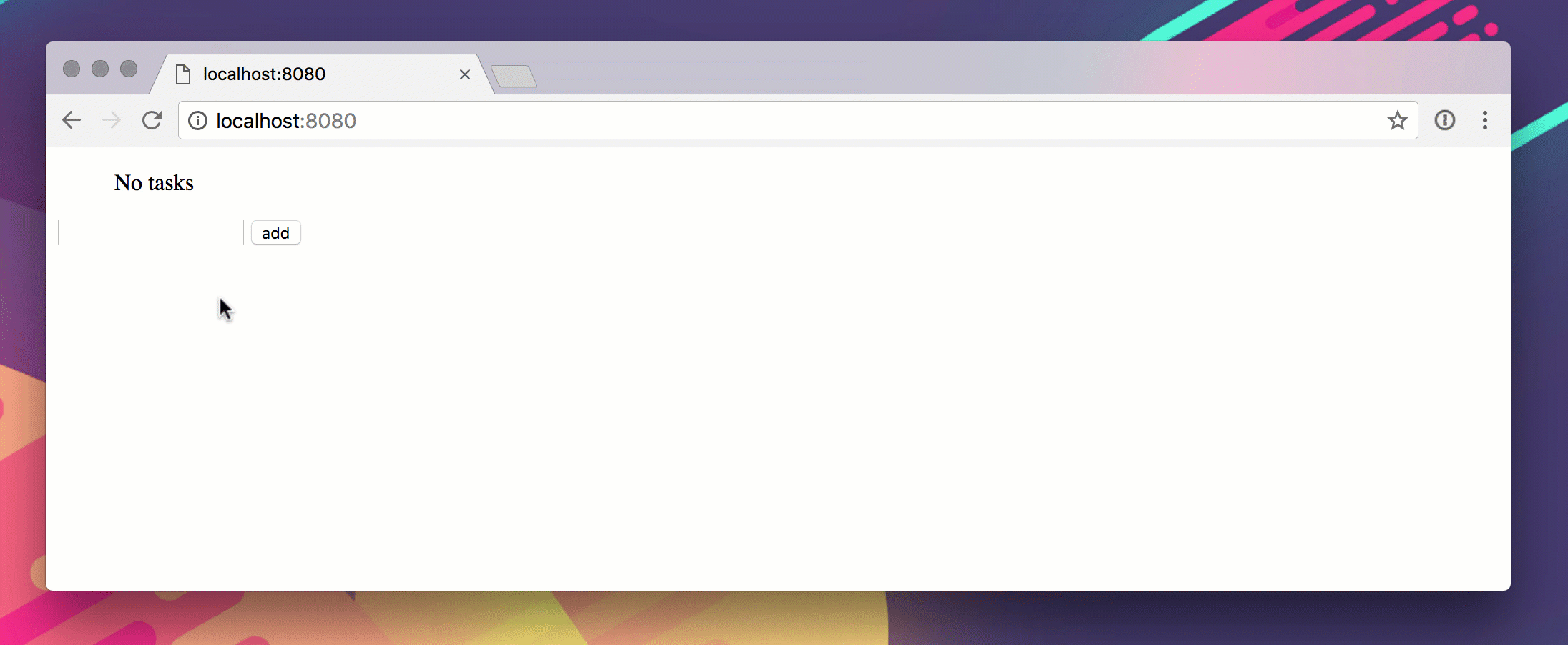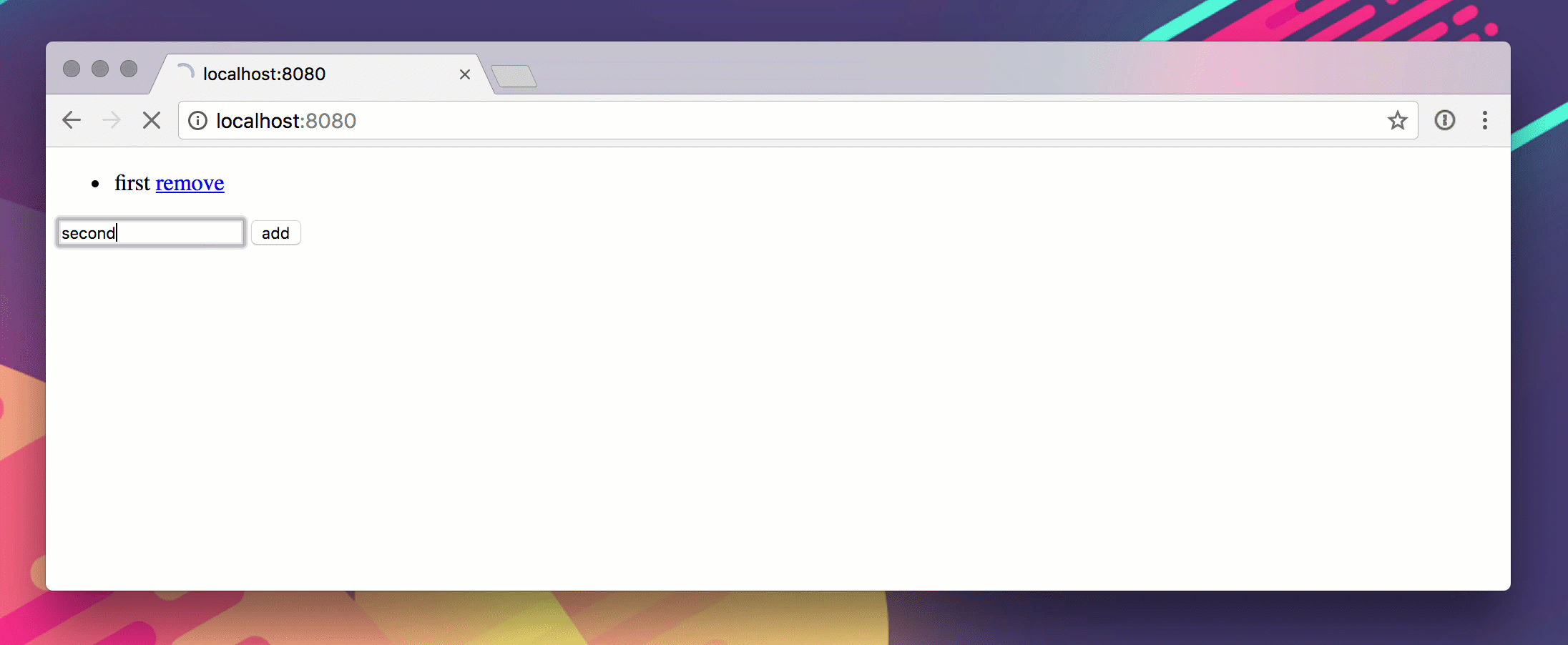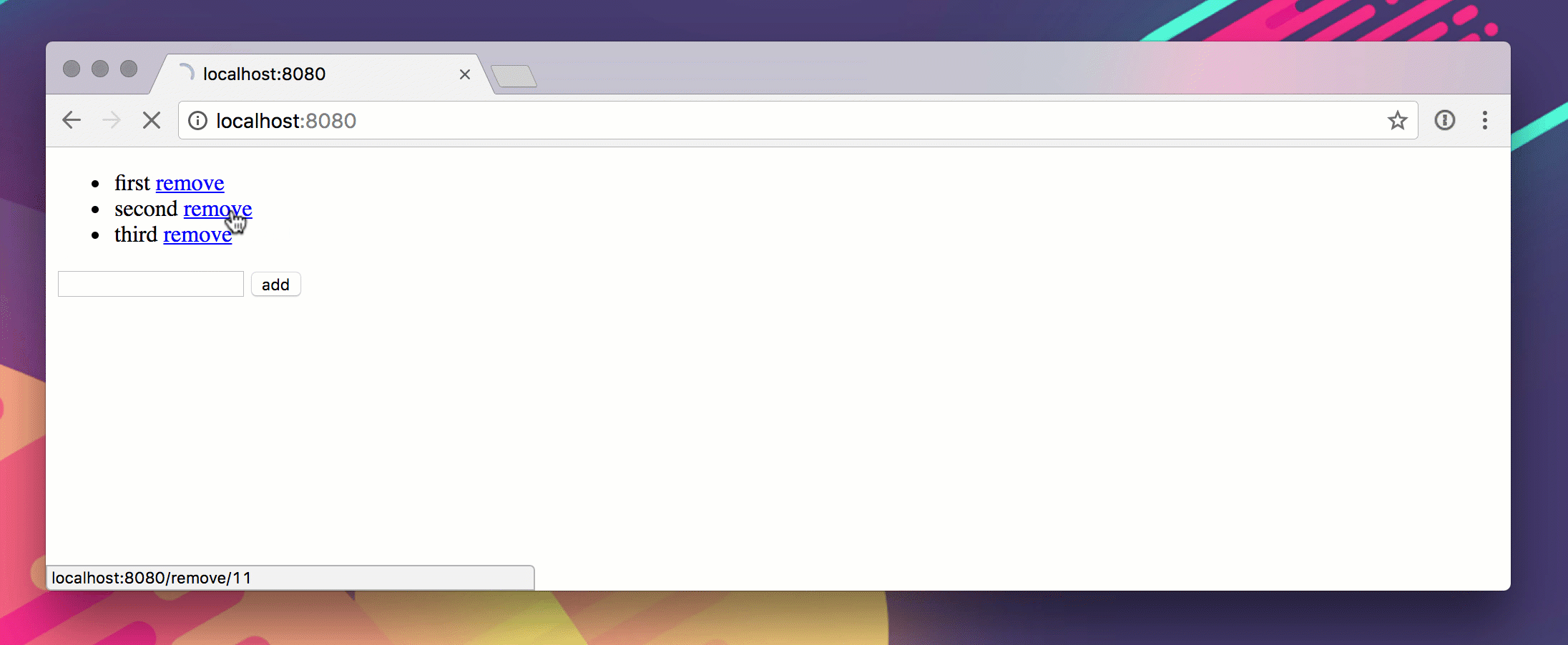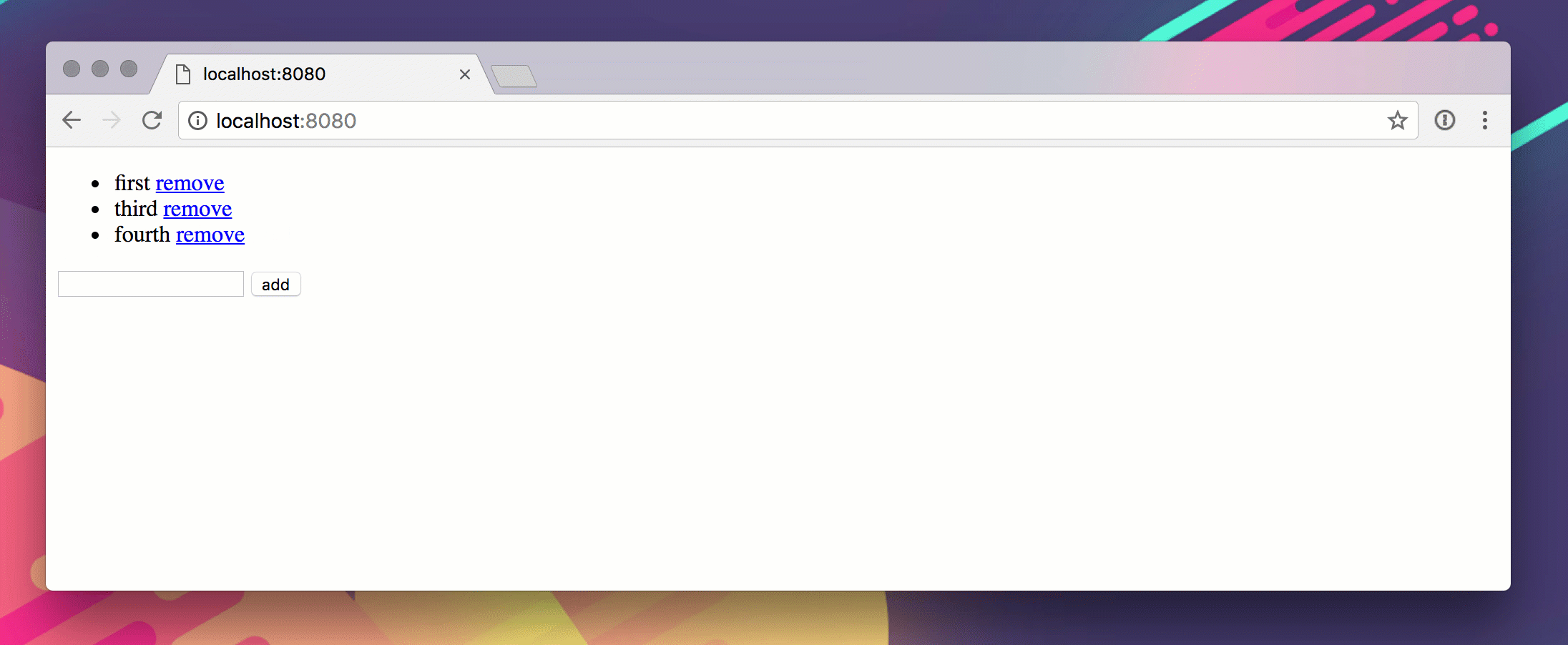
Phack
Пока я работал над этим проектом, я заново открыл проект под названием Phack от Sara Golemon . Это проект, похожий на Pre, который стремится перенести расширенный язык PHP (в нашем случае, Hack) в обычный PHP.
В файле readme перечислены функции Hack, которые Phack стремится поддерживать, и их статус. Одной из таких функций является XHP. Если вы всегда хотели написать Hack-код, но все еще использовали стандартные инструменты PHP; Я рекомендую проверить это. Я большой поклонник Сары и ее работы, поэтому я определенно буду следить за Факом.
Резюме
Это был вихревой тур по созданию простого компилятора. Мы узнали, как создать базовый компилятор конечного автомата и как заставить его поддерживать HTML-подобный синтаксис в обычном синтаксисе PHP. Мы также рассмотрели, как это может работать в примере приложения.
Я хотел бы призвать вас попробовать это. Возможно, вы захотите добавить свой собственный синтаксис в PHP — что вы можете сделать с Pre . Возможно, вы хотели бы радикально изменить PHP. Я надеюсь, что этот урок продемонстрировал один из способов сделать это, достаточно хорошо, чтобы вы справились с этой задачей. Помните: создание компиляторов не требует огромного количества знаний или обучения. Простые манипуляции со строками, проб и ошибок.
Дайте нам знать, что вы придумали!