Важно учитывать потребности данных вашего приложения с самого начала разработки. Но если ваше приложение будет использовать NoSQL, и вы пришли из RDBMS / SQL фона, то вы можете подумать, что смотреть на данные с точки зрения NoSQL может быть сложно. Эта статья поможет вам, показывая, как некоторые из основных концепций моделирования данных применяются в области NoSQL.
Я буду использовать MongoDB для нашего обсуждения, поскольку она является одной из ведущих баз данных NoSQL с открытым исходным кодом благодаря своей простоте, производительности, масштабируемости и активной пользовательской базе. Конечно, в статье предполагается, что вы знакомы с основными понятиями MongoDB (такими как коллекции и документы). Если нет, я предлагаю вам прочитать некоторые из предыдущих статей здесь, в SitePoint, чтобы начать работу с MongoDB.
Понимание отношений
Отношения показывают, как ваши документы MongoDB связаны друг с другом. Чтобы понять различные способы организации наших документов, давайте рассмотрим возможные отношения.
Отношение 1 к 1 (1: 1)
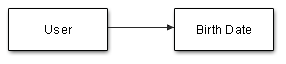
Отношение 1: 1 существует, когда один объект объекта связан с одним и только одним объектом другого объекта. Например, у одного пользователя может быть одна и только одна дата рождения. Поэтому, если у нас есть документ, в котором хранится информация о пользователях, и другой документ, в котором хранятся даты рождения, между ними будет соотношение 1: 1.
Отношение 1-ко-многим (1: N)
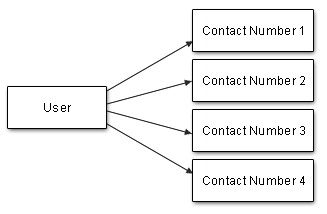
Такое отношение существует, когда один объект объекта может быть связан со многими объектами другого объекта. Например, между пользователем и его контактными номерами может быть отношение 1: N, так как один пользователь может иметь более одного номера.
Отношение многие ко многим (M: N)
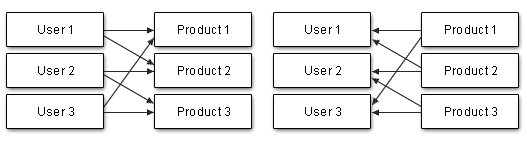
Такая связь существует, когда один объект объекта связан со многими объектами другого объекта и наоборот. Если мы сопоставим это с ситуацией пользователей и предметов, купленных ими, один пользователь может приобрести более одного предмета, а один предмет может быть приобретен более чем одним пользователем.
Моделирование отношений 1: 1 (1: 1)
Рассмотрим следующий пример, где нам нужно хранить адресную информацию для каждого пользователя (сейчас давайте предположим, что для каждого пользователя существует один адрес). В этом случае мы можем разработать встроенный документ, имеющий следующую структуру:
{ "_id": ObjectId("5146bb52d8524270060001f4"), "user_name": "Mark Benzamin" "dob": "12 Jan 1991", "address": { "flat_name": "305, Sunrise Park", "street": "Cold Pool Street", "city": "Los Angeles" } } У нас есть address сущность, встроенная в сущность пользователя, которая представляет всю информацию в одном документе. Это означает, что мы можем найти и получить все с помощью одного запроса.
<?php // query to find user 'Mark Benzamin' and his address $cursor = $collection->find( array("user_name" => "Mark Benzamin"), array("user_name" => 1,"address" => 1) );
Внедрение документов примерно аналогично отмене нормализации и полезно, когда между двумя объектами существует взаимосвязь «содержит». То есть один документ может храниться в другом, таким образом размещая связанные фрагменты информации в одном документе. Поскольку вся информация доступна в одном документе, такой подход имеет более высокую производительность чтения, поскольку операция запроса в документе дешевле для сервера, и мы находим и получаем соответствующие данные в том же запросе.
Напротив, нормализованный подход потребовал бы двух документов (в идеале в отдельных коллекциях), один для хранения основной пользовательской информации, а другой для хранения адресной информации. Второй документ будет содержать поле user_id указывающее пользователя, которому принадлежит адрес.
{ "_id": ObjectId("5146bb52d8524270060001f4"), "user_name": "Mark Benzamin", "dob": "12 Jan 1991" }
{ "_id": ObjectId("5146bb52d852427006000de4"), "user_id": ObjectId("5146bb52d8524270060001f4"), "flat_name": "305, Sunrise Park", "street": "Cold Pool Street", "city": "Los Angeles" }
Теперь нам нужно выполнить два запроса для получения одинаковых данных:
<?php // query to find user information $user = $collection->findOne( array("user_name" => "Mark Benzamin"), array("_id" => 1, "user_name" => 1) ); // query to find address corresponding to user $address = $collection->findOne( array("user_id" => $user["_id"]), array("flat_name" => 1, "street" => 1, "city" => 1) );
Первый запрос извлекает _id пользователя, который затем используется во втором запросе для получения его адресной информации.
В этом случае подход встраивания имеет больше смысла, чем подход ссылок, поскольку мы часто получаем имя пользователя и address вместе. Какой подход вам следует использовать, в конечном итоге зависит от того, как вы логически соединяете свои объекты и какие данные вам нужно извлечь из базы данных.
Моделирование встроенных отношений 1-ко-многим (1: N)
Теперь давайте рассмотрим случай, когда один пользователь может иметь несколько адресов. Если все адреса должны быть извлечены вместе с основной пользовательской информацией, было бы идеально встроить адресные объекты в пользовательский объект.
{ "_id": ObjectId("5146bb52d8524270060001f4"), "user_name": "Mark Benzamin" "address": [ { "flat_name": "305, Sunrise Park", "street": "Cold Pool Street", "city": "Los Angeles" }, { "flat_name": "703, Sunset Park", "street": "Hot Fudge Street", "city": "Chicago" } ] }
Мы все еще можем получить всю необходимую информацию с помощью одного запроса. При использовании ссылочного / нормализованного подхода мы разработали три документа (один пользователь, два адреса) и два запроса для выполнения одной и той же задачи.
Помимо эффективности и удобства, мы должны использовать встроенный подход в тех случаях, когда нам нужна атомарность в операциях. Поскольку любые обновления происходят в одном и том же документе, атомарность всегда застрахована.
Моделирование отношений «один ко многим» (1: N)
Имейте в виду, что размер вложенных документов может увеличиваться в течение срока службы приложения, что может отрицательно повлиять на производительность записи. Существует также ограничение в 16 МБ на максимальный размер каждого документа. Нормализованный подход предпочтителен, если внедренные документы будут слишком большими, если подход встраивания приведет к большому количеству дублированных данных или если вам необходимо смоделировать сложные или иерархические отношения между документами.
Рассмотрим пример поддержки сообщений, сделанных пользователем. Давайте предположим, что мы хотим, чтобы имя пользователя и его фотография профиля отображались в каждом сообщении (аналогично сообщению в Facebook, где мы можем видеть имя и изображение профиля в каждом сообщении). Денормализованный подход будет хранить пользовательскую информацию в каждом почтовом документе:
{ "_id": ObjectId("5146bb52d8524270060001f7"), "post_text": "This is my demo post 1", "post_likes_count": 12, "user": { "user_name": "Mark Benzamin", "profile_pic": "markbenzamin.jpg" } } { "_id": ObjectId("5146bb52d8524270060001f8"), "post_text": "This is my demo post 2", "post_likes_count": 32, "user": { "user_name": "Mark Benzamin", "profile_pic": "markbenzamin.jpg" } }
Мы видим, что этот подход хранит избыточную информацию в каждом почтовом документе. Заглядывая немного вперед, если имя пользователя или изображение профиля когда-либо изменялось, нам пришлось бы обновлять соответствующее поле во всех соответствующих сообщениях.
Таким образом, идеальным подходом было бы нормализовать информацию и связать ее через ссылки.
{ "_id": ObjectId("5146bb52d852427006000121"), "user_name": "Mark Benzamin", "profile_pic": "markbenzamin.jpg" }
{ "_id": ObjectId("5146bb52d8524270060001f7"), "post_text": "This is my demo post 1", "post_likes_count": 12, "user_id": ObjectId("5146bb52d852427006000121") } { "_id": ObjectId("5146bb52d8524270060001f8"), "post_text": "This is my demo post 2", "post_likes_count": 32, "user_id": ObjectId("5146bb52d852427006000121") }
Поле user_id в почтовом документе содержит ссылку на пользовательский документ. Таким образом, мы можем получить сообщения, сделанные пользователем, используя два запроса следующим образом:
<?php $user = $collection->findOne( array("user_name" => "Mark Benzamin"), array("_id" => 1, "user_name" => 1, "profile_pic" => 1) ); $posts = $collection->find( array("user_id" => $user["_id"]) );
Моделирование отношений «многие ко многим» (M: N)
Давайте возьмем наш предыдущий пример хранения пользователей и приобретенных ими предметов (в идеале в отдельных коллекциях) и разработки ссылочных документов, чтобы проиллюстрировать отношения M: N. Предположим, что коллекция, в которой хранятся документы для информации о пользователях, выглядит следующим образом, так что каждый документ содержит ссылочные идентификаторы для списка предметов, приобретенных пользователем.
{ "_id": "user1", "items_purchased": { "0": "item1", "1": "item2" } } { "_id": "user2", "items_purchased": { "0": "item2", "1": "item3" } }
Аналогично, предположим, что другая коллекция хранит документы для доступных предметов. Эти документы, в свою очередь, будут хранить идентификаторы ссылок для списка пользователей, которые его приобрели.
{ "_id": "item1", "purchased_by": { "0": "user1" } } { "_id": "item2", "purchased_by": { "0": "user1", "1": "user2" } } { "_id": "item3", "purchased_by": { "0": "user2" } }
Чтобы получить все предметы, купленные пользователем, мы напишем следующий запрос:
<?php // query to find items purchased by a user $items = $collection->find( array("_id" => "user1"), array("items_purchased" => 1) );
Приведенный выше запрос вернет идентификаторы всех предметов, приобретенных пользователем1. Позже мы можем использовать их для получения информации о соответствующем элементе.
В качестве альтернативы, если мы хотим получить пользователей, которые приобрели определенный товар, мы напишем следующее:
<?php // query to find users who have purchased an item $users = $collection->find( array("_id" => "item1"), array("purchased_by" => 1) );
Приведенный выше запрос возвращает идентификаторы всех пользователей, которые приобрели item1. Позже мы можем использовать эти идентификаторы для получения соответствующей информации о пользователе.
Этот пример продемонстрировал отношения M: N, которые в некоторых случаях очень полезны. Однако следует помнить, что во многих случаях такие отношения могут обрабатываться с использованием отношений 1: N вместе с некоторыми умными запросами. Это уменьшает объем данных, которые должны поддерживаться в обоих документах.
Вывод
Вот именно для этой статьи. Мы узнали о некоторых базовых концепциях моделирования, которые, несомненно, помогут вам начать собственное моделирование данных: отношения «1 к 1», «1 ко многим» и «многие ко многим», а также немного о нормализации данных и -нормализации. Вы должны быть в состоянии легко применить эти концепции к потребностям моделирования вашего собственного приложения. Если у вас есть какие-либо вопросы или комментарии, связанные со статьей, не стесняйтесь поделиться в разделе комментариев ниже.