
Вступление
Недавно я начал создавать сайт сообщества на платформе Yii, о котором я скоро напишу как часть моей серии «Программирование с Yii2» . Я хотел, чтобы было легко добавлять ссылки, связанные с контентом на сайте. В то время как людям легко вставлять URL-адреса в формы, требуется также много времени для предоставления информации о заголовке и источнике.
В сегодняшнем уроке я собираюсь показать вам, как использовать PHP для извлечения общих метаданных с веб-страниц, чтобы облегчить пользователям участие и создавать более интересные сервисы.
Помните, я участвую в комментариях ниже, так что скажите мне, что вы думаете! Вы также можете связаться со мной в Твиттере @lookahead_io .
Начиная
Во-первых, я создал форму для людей, чтобы добавить ссылки, вставив URL. Я также создал кнопку «Уточняющий запрос», чтобы использовать AJAX для запроса веб-страницы о метаданных.
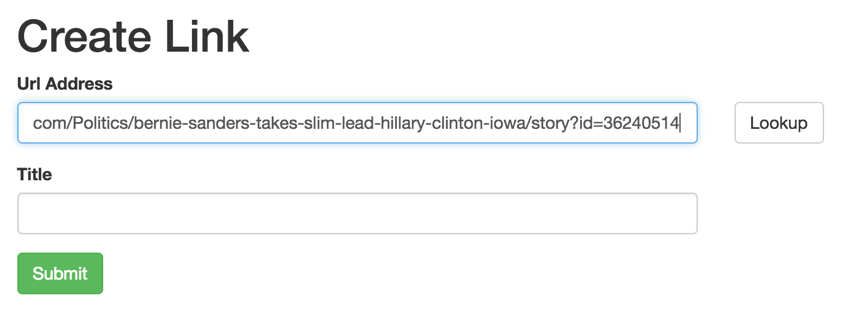
Нажатие Lookup вызывает функцию Link::grab() через ajax:
|
01
02
03
04
05
06
07
08
09
10
|
$(document).on(«click», ‘[id=lookup]’, function(event) {
$.ajax({
url: $(‘#url_prefix’).val()+’/link/grab’,
data: {url: $(‘#url’).val()},
success: function(data) {
$(‘#title’).val(data);
return true;
}
});
});
|
Соскоб страницы
Код Link::grab() вызывает fetch_og() . Это имитирует сканер для захвата страницы и получения метаданных с помощью DOMXPath :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
public static function fetch_og($url)
{
$options = array(‘http’ => array(‘user_agent’ => ‘facebookexternalhit/1.1’));
$context = stream_context_create($options);
$data = file_get_contents($url,false,$context);
$dom = new \DomDocument;
@$dom->loadHTML($data);
$xpath = new \DOMXPath($dom);
# query metatags with og prefix
$metas = $xpath->query(‘//*/meta[starts-with(@property, \’og:\’)]’);
$og = array();
foreach($metas as $meta){
# get property name without og: prefix
$property = str_replace(‘og:’, », $meta->getAttribute(‘property’));
$content = $meta->getAttribute(‘content’);
$og[$property] = $content;
}
return $og;
}
|
Для моего сценария я заменил теги og: выше, но код ниже ищет теги различных типов:
|
01
02
03
04
05
06
07
08
09
10
|
$tags = Link::fetch_og($url);
if (isset($tags[‘title’])) {
$title = $tags[‘title’];
} else if (isset($tags[‘metaProperties’][‘og:title’][‘value’])) {
$title=$tags[‘metaProperties’][‘og:title’][‘value’];
} else {
$title = ‘n/a’;
}
return $title;
}
|
Вы также можете получить другие теги, такие как ключевые слова, описание и т. Д. Затем jQuery добавляет результат в форму для отправки пользователем:

Идти дальше
У меня также есть таблица источников, которые я разработаю позже. Но в основном каждый раз, когда добавляется новый URL, мы анализируем его для базового домена веб-сайта и помещаем в Source таблицу:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
$model->source_id = Source::add($model->url);
…
public static function add($url=»,$name=») {
$source_url = parse_url($url);
$url = $source_url[‘host’];
$url = trim($url,’ \\’);
$s = Source::find()
->where([‘url’=>$url])
->one();
if (is_null($s)) {
$s=new Source;
$s->url = $url;
$s->name = $name;
$s->status = Source::STATUS_ACTIVE;
$s->save();
} else {
if ($s->name==») {
$s->name = $name;
$s->update();
}
}
return $s->id;
}
|
Сейчас я вручную обновляю имена источников, чтобы они выглядели чистыми для пользователя, например, ABC News , BoingBoing и Vice :

Надеюсь, в следующем выпуске я расскажу, как использовать свободно доступные API для поиска названия сайта. Странно для меня, для этого нет общего метатега; если бы интернет был идеальным.
Сайты Paywall
Некоторые сайты, такие как The New York Times, не позволяют просматривать метаданные из-за их платных сетей. Но у них есть API . Это не легко изучить из-за запутанной документации, но их разработчики быстро помогут на GitHub. Я также надеюсь написать об использовании поиска метаданных для названий New York Times в будущем эпизоде.
В заключение
Я надеюсь, что вы нашли это руководство полезным и применили его где-нибудь в своих проектах. Если вы хотите увидеть это в действии, вы можете попробовать некоторые из веб-страниц на моем сайте, « Активно вместе» .
Пожалуйста, поделитесь своими мыслями и отзывами в комментариях. Вы также всегда можете связаться со мной через Twitter @lookahead_io напрямую. И обязательно ознакомьтесь с моей страницей для инструкторов и другими моими сериями « Создание стартапа на PHP и программирование на Yii2» .