Задумывались ли вы, как социальные сети делают предварительный просмотр URL так хорошо, когда вы делитесь ссылками? Как они узнают, какие изображения нужно захватить, кого цитировать в качестве автора или какие теги прикрепить к предварительному просмотру? Это все ползет со сложными регулярными выражениями поверх исходного кода? На самом деле, чаще всего это не так. Мета-информация, определенная в источнике, может быть ненадежной, и сайты с менее звездной репутацией часто используют их в качестве носителей ключевых слов, пытаясь заставить поисковые системы ранжировать их выше. Разве то, что мы, люди, видим перед нами, имеет значение в любом случае?
Если вы хотите создать фрагмент предварительного просмотра URL-адреса или агрегатор новостей, в Интернете доступно много автоматических сканеров, как проприетарных, так и с открытым исходным кодом, но вы редко находите такую нишу, как визуальное машинное обучение. Это именно то, чем является Diffbot — «робот визуального обучения», который отображает URL-адрес, который вы запрашиваете полностью, а затем визуально извлекает данные, помогая себе с некоторыми метаданными из источника страницы по мере необходимости.
Изучив некоторую теорию, в этом посте мы сделаем демонстрационный вызов API в одном из постов SitePoint.
PHP библиотека
Библиотека PHP для Diffbot несколько устарела, и поэтому мы не будем использовать ее в этой демонстрации. Мы будем выполнять необработанные вызовы API, и в некоторых будущих публикациях мы создадим собственную библиотеку для взаимодействия с API.
Если вы все же хотите взглянуть на библиотеку PHP, посмотрите здесь , и если вы заинтересованы в библиотеках для других языков, у Diffbot есть каталог .
Обновление, июль 2015 года : библиотека PHP была разработана с момента публикации этой статьи. Смотрите весь процесс разработки здесь или исходный код здесь .
Контент JavaScript
Во вступительном разделе мы сказали, что Diffbot полностью обрабатывает запрос, а затем анализирует его. Но как насчет контента JavaScript? В настоящее время веб-сайты часто отображают некоторый HTML выше сгиба, а затем завершают CSS, JS и динамическую загрузку контента после этого. Может ли Diffbot API увидеть это?
На самом деле, да. Diffbot буквально визуализирует страницу полностью, а затем проверяет ее визуально, как описано в моих вопросах и ответах StackOverflow здесь . Однако есть некоторые оговорки, поэтому обязательно внимательно прочитайте ответ.
Ценообразование и API Здоровье
Diffbot имеет несколько уровней использования. Существует бесплатный пробный уровень, который убивает ваш API-токен через 7 дней или 10000 звонков, в зависимости от того, что произойдет раньше. Коммерческие токены можно купить по разным ценам , и срок их действия никогда не истекает, но у них есть ограничения. Особый индивидуальный подход предоставляется для проектов с открытым исходным кодом и / или образовательных проектов, которые предоставляют старую модель бесплатного токена — 10 000 вызовов в месяц, максимум раз в секунду, но никогда не истекает. Вам нужно связаться с ними напрямую, если вы считаете, что имеете право.
Diffbot гарантирует высокое время безотказной работы, но иногда случаются сбои, особенно в наиболее ресурсоемком API связки: Crawlbot. Crawlbot используется для сканирования целых доменов, а не только отдельных страниц, и поэтому имеет более низкий уровень надежности, чем другие API. Не слишком много, но достаточно, чтобы быть заметным на экране « Состояние API» — на экране, который вы можете проверить, работает ли API, или он в настоящее время недоступен, если ваши вызовы сталкиваются с проблемами или возвращают ошибку 500.
демонстрация
Чтобы подготовить среду, загрузите экземпляр Homestead Improved .
Создать проект
Создайте начальный проект Laravel, введя SSHing в виртуальную машину с помощью vagrant vagrant ssh , перейдя в папку Code и выполнив composer create-project laravel/laravel Laravel --prefer-dist . Это позволит вам получить доступ к странице приветствия Laravel через http://homestead.app:8000 из браузера хоста.
Добавить маршрут и действие
В app/routes.php добавьте следующий маршрут:
Route::get('/diffbot', 'HomeController@diffbotDemo');
В app/controllers/HomeController добавьте следующее действие:
public function diffbotDemo() { die("hi"); }
Если http://homestead.app:8000/diffbot теперь выводит «hi» на экране, мы готовы начать играть с API.
Получить токен
Для взаимодействия с Diffbot API вам нужен токен. Подпишитесь на один на их странице с ценами . Ради этой демонстрации давайте назовем наш токен $TOKEN , и мы будем ссылаться на него в URL. Замените $TOKEN своим собственным значением, где это необходимо.
Установить жадность
Мы будем использовать Guzzle в качестве нашего HTTP-клиента. Это не обязательно, но я рекомендую вам ознакомиться с ним в нашей прошлой статье .
Добавьте "guzzlehttp/guzzle": "4.1.*@dev" в ваш composer.json чтобы блок require выглядел следующим образом:
"require": { "laravel/framework": "4.2.*", "guzzlehttp/guzzle": "4.1.*@dev" },
В корне проекта запустите composer update .
Выбрать данные статьи
В первом примере мы будем сканировать сообщение SitePoint с API по умолчанию для статьи из Diffbot. Для этого мы обращаемся к документам, которые отлично объясняют рабочий процесс. Измените тело действия diffbotDemo на следующий код:
public function diffbotDemo() { $token = "$TOKEN"; $version = 'v3'; $client = new GuzzleHttp\Client(['base_url' => 'http://api.diffbot.com/']); $response = $client->get($version.'/article', ['query' => [ 'token' => $token, 'url' => 'http://www.sitepoint.com/7-mistakes-commonly-made-php-developers/' ]]); die(var_dump($response->json())); }
Сначала мы устанавливаем наш токен. Затем мы определяем переменную, которая будет содержать версию API. Далее, нам нужно создать новый клиент Guzzle, и мы также даем ему базовый URL, чтобы нам не приходилось вводить его каждый раз, когда мы делаем другой запрос.
Затем мы создаем объект ответа, отправляя запрос GET по URL-адресу API, и добавляем массив параметров запроса в формате ключ => значение. В этом случае мы передаем только токен и URL, самый базовый из параметров.
Наконец, поскольку Diffbot API возвращает данные JSON, мы используем метод Guzzle json() для автоматического декодирования их в массив. Затем мы распечатываем эти данные:
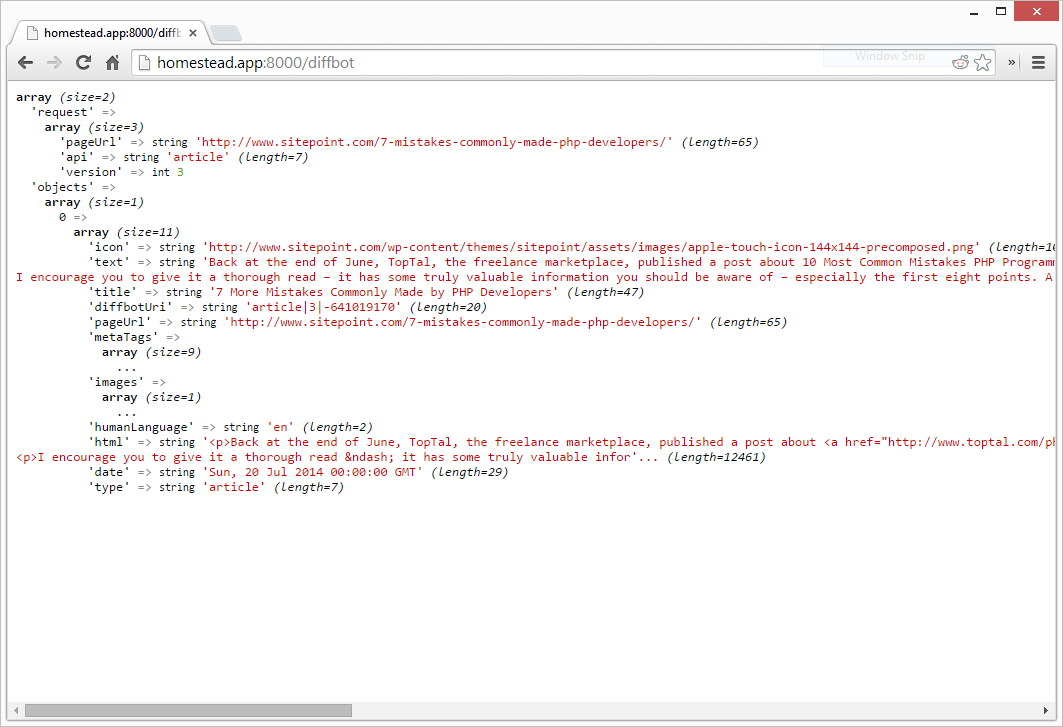
Как видите, мы получили некоторую информацию довольно быстро. Есть значок, который был использован, предварительный просмотр текста, заголовок, даже язык, дата и HTML были возвращены. Однако вы заметите, что автора нет. Давайте изменим это и запросим еще несколько значений.
Если мы добавим параметр «fields» в список параметров запроса и присвоим ему значение «tags», Diffbot попытается извлечь теги / категории из предоставленного URL. Добавьте эту строку в массив query :
'fields' => 'tags'
и затем измените часть die на это:
$data = $response->json(); die(var_dump($data['objects'][0]['tags']));
Обновление экрана теперь дает нам это:
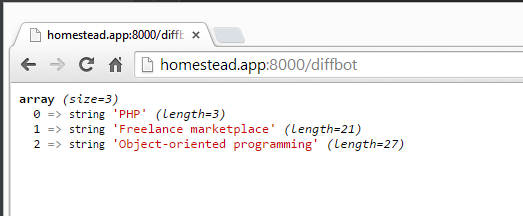
Но исходный код статьи отмечает несколько других тегов:
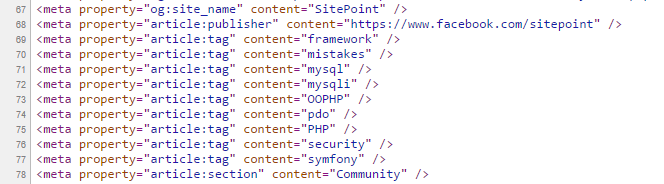
Почему результат так сильно отличается? Именно по той причине, о которой мы упоминали в конце самого первого абзаца этого поста: то, что мы, люди, видим, имеет приоритет. Diffbot является визуальным обучающим роботом, и поэтому его ИИ выводит теги из фактического визуализированного контента — что он может видеть — вместо того, чтобы смотреть на исходный код, который слишком легко виден для целей SEO.
Есть ли способ получить теги из исходного кода, если они действительно нужны? Кроме того, можем ли мы заставить Diffbot узнать автора статей SitePoint? Да. С пользовательским API.
Метатеги и автор с пользовательским API
Пользовательский API — это функция, которая позволяет вам не только настраивать существующий Diffbot API по своему вкусу, добавляя новые поля и правила для извлечения контента, но также позволяет создавать совершенно новые API (доступ к которым также осуществляется через выделенный URL) для настраиваемого контента. обработка.
Перейдите на панель инструментов разработчика и войдите в систему с помощью токена. Затем перейдите в «Custom API». Активируйте вкладку «Создать правило» внизу и введите URL-адрес статьи, которую мы сканируем, в поле URL-адреса, затем нажмите «Тест». Ваш экран должен выглядеть примерно так:
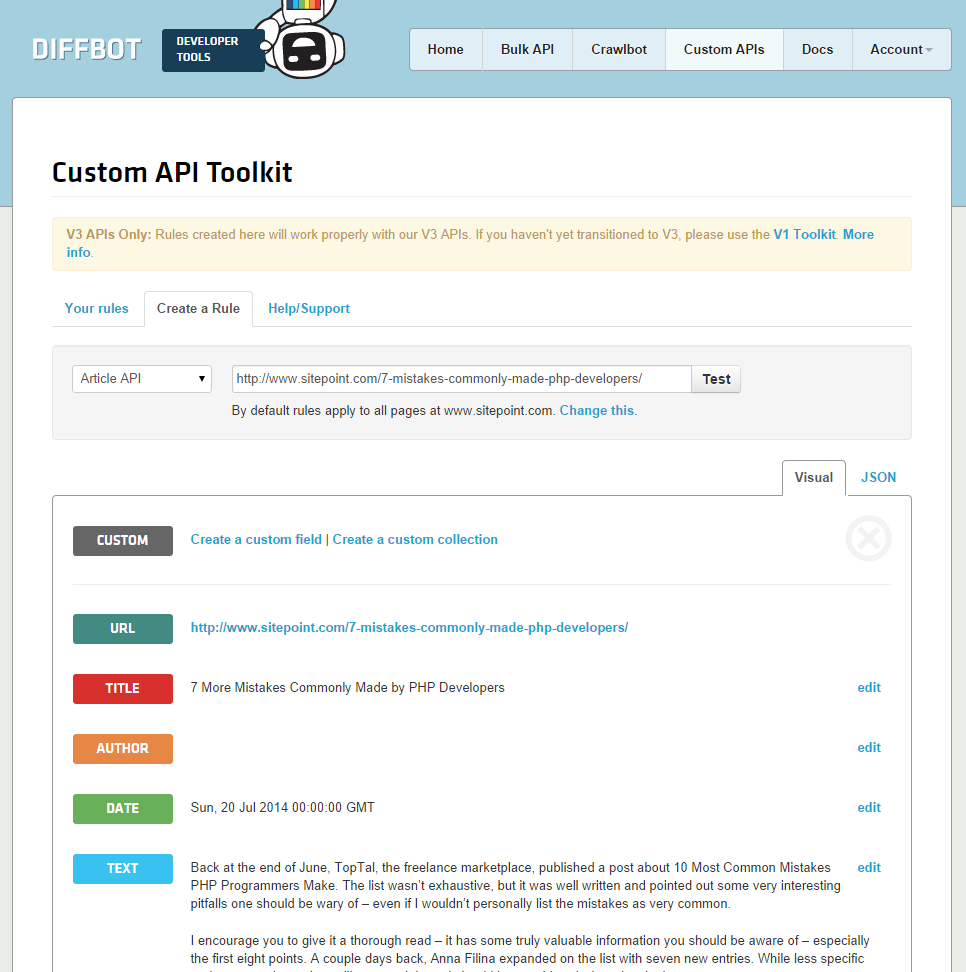
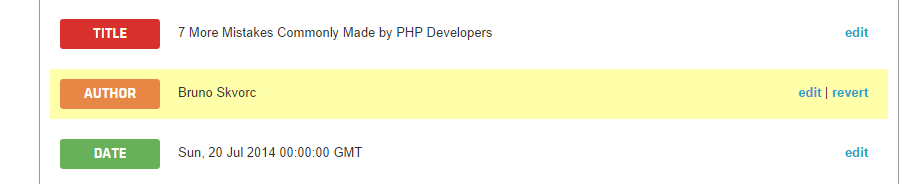
Вы сразу заметите, что поле Автор пустое. Вы можете настроить правило поиска авторов, щелкнув «Изменить» рядом с ним и найдя элемент Author в открывшемся окне предварительного просмотра, а затем щелкните его, чтобы получить желаемый результат. Однако из-за того, что некоторые, ну, конечно, не идеальные CSS на стороне SitePoint, очень трудно предоставить API-интерфейсу Diffbot согласованный путь к имени автора, особенно при нажатии на элементы. Вместо этого добавьте следующее правило вручную: .contributor--large .contributor_name a и нажмите Сохранить.
Вы заметите, что окно предварительного просмотра теперь корректно заполняет поле Автор:
Фактически это новое правило автоматически применяется ко всем ссылкам SitePoint для вашего токена. Если вы попытаетесь просмотреть другую статью SitePoint, например эту , вы заметите, что Питер Найссен успешно извлечен:
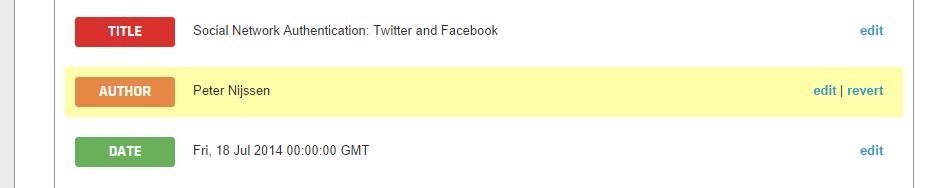
Хорошо, давайте изменим API дальше. Нам нужна article:tag значения article:tag , которые видны в исходном коде. Это требует двухэтапного процесса.
Шаг 1: Определите коллекцию
Коллекция — это именно то, на что это похоже — коллекция значений, собранных с помощью определенного набора правил. Мы назовем нашу коллекцию «MetaTags» и дадим ей следующий селектор: meta[property=article:tag] . Это означает «найти все метаэлементы в HTML, которые имеют атрибут property со значением article:tag ».
Шаг 2: Определите поля сбора
Поля коллекции — это отдельные записи в коллекции — в нашем случае это различные теги. Нажмите «Добавить настраиваемое поле в эту коллекцию» и добавьте следующие значения:
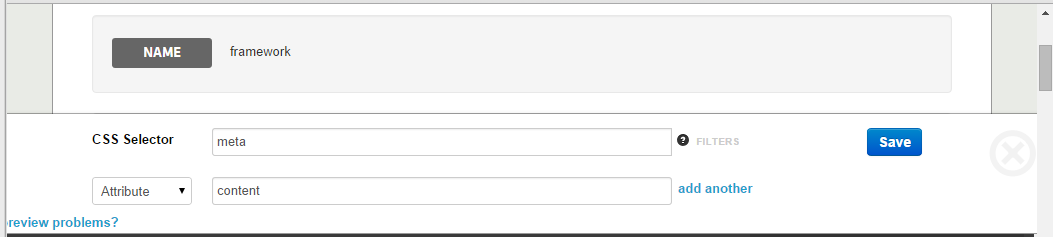
Нажмите Сохранить. Вы сразу получите доступ к списку тегов в окне результатов:
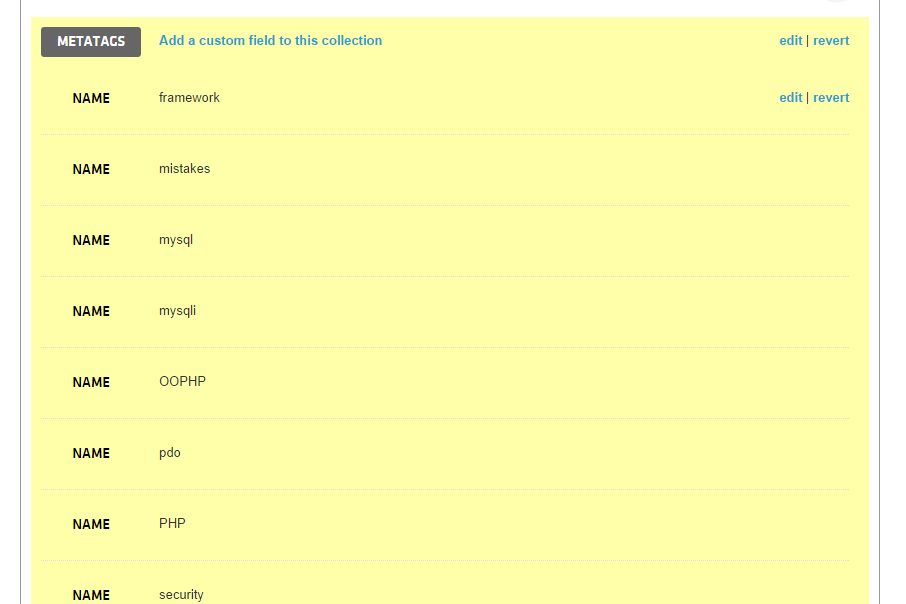
Измените окончательный результат действия diffbotDemo() на это:
die(var_dump($data['objects'][0]['metaTags']));
Если вы обновите URL-адрес, с которым мы тестировали ( http://homestead.app:8000/diffbot ), вы заметите, что значения автора и метатегов есть. Вот вывод, который производит приведенная выше строка кода:
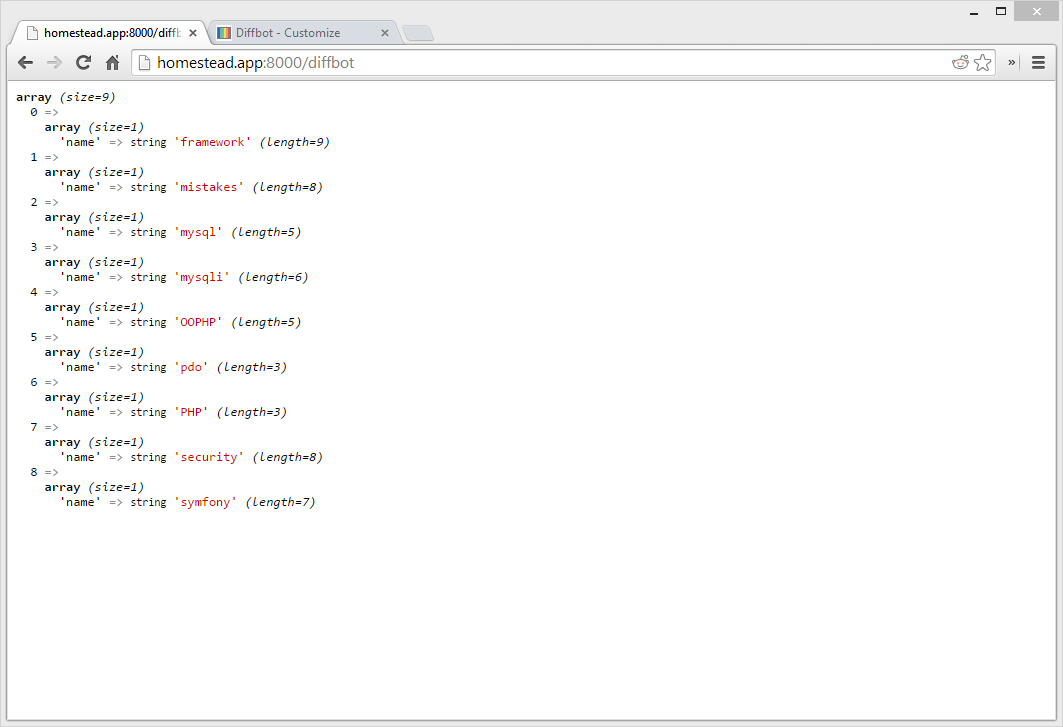
У нас есть наши теги!
Вывод
Diffbot — это мощный инструмент для извлечения данных в Интернете — нужно ли вам объединять многие сайты в единый поисковый индекс без объединения их бэкэндов, хотите создать агрегатор новостей, есть идея для веб-компонента предварительного просмотра URL или хотите регулярно Diffbot может помочь в сборе содержимого публичных ценовых списков конкурентов. С просто мертвыми простыми вызовами API и хорошо структурированными ответами вы сразу же приступите к работе. В следующей статье мы создадим новый API для использования Diffbot с PHP и повторим вызовы выше с ним. Мы также разместим библиотеку на Packagist, поэтому вы можете легко установить ее с помощью Composer. Будьте на связи!