В этом уроке мы собираемся создать виджет для наших веб-страниц, который позволит посетителям искать содержимое нашего сайта. Мы будем использовать jQuery для передачи поискового запроса на сервер, а также для получения и отображения результатов. Мы будем использовать PHP для поиска термина на локальном сайте, а затем возвращать любые соответствующие URL-адреса обратно на страницу в виде объекта JSON. Часть 2 показывает, как искать в базе данных системы управления контентом (CMS).
Серверная часть PHP, используемая в этом руководстве, является лишь примером и не единственным способом, которым мы могли бы выполнить поиск. Бэкэнд, к которому подключен виджет, будет отличаться в зависимости от структуры сайта, на котором он используется. Код, используемый в этом примере, будет хорошо работать на сайтах от малого до среднего с большим количеством статического контента. Сайт, управляемый данными или большим количеством продукта, вероятно, лучше использовал бы серверную часть для поиска в базе данных, которую было бы одинаково легко кодировать.
PHP
Сначала мы рассмотрим PHP, а затем построим его. Там будет простой маленький скрипт, который начинается в указанном каталоге, а затем пересекает все подкаталоги, собирая URL-адреса всех страниц в дереве.
Затем нам нужно будет выполнить поиск по каждой странице, чтобы увидеть, содержит ли она термин, который посетитель искал, и запишите его URL, если он это сделает. Наконец, мы можем преобразовать информацию в формат JSON для легкой обработки в браузере. Давайте начнем; на новой странице в вашем текстовом редакторе добавьте следующий код:
|
1
2
3
4
5
6
7
|
<?php
//function to get all files in a tree
function searchFiles($startDir, $urls = array()) {
}
?>
|
Большая часть функциональности в PHP будет в функции, которую мы здесь определяем; функция searchFiles принимает два аргумента: первый — каталог, в котором начинается поиск, второй — массив. Далее нам нужно добавить логику паутинга и поиска, все из которых могут войти в эту функцию; внутри функции добавьте следующий код:
|
1
2
3
4
5
|
//get search term from POST
$term = $_GET[«term»];
//scan starting dir
$contents = scandir($startDir);
|
Сначала мы получаем поисковый термин, который будет передан в файл как часть запроса GET . Мы не используем базу данных, поэтому в этом примере я не сосредоточился на каких-либо мерах безопасности.
Затем мы используем нативную функцию PHP scandir, которая будет читать содержимое указанного каталога. Каталог для сканирования получается из первого параметра, переданного функции. Возвращаемое значение scandir хранится в переменной $ contents и будет массивом.
Сразу после кода, который мы только что посмотрели, добавьте следующий код:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
//loop through each item
for ($x = 0; $x < count($contents); $x++) {
//build path to each item
$path = $startDir .
if(is_dir($path)) { //if item is a dir
//skip these
if($contents[$x] !== «.» && $contents[$x] !== «..») {
//recursively call function to open sub dirs
$urls = searchFiles($path, $urls);
}
} elseif(is_file($path)) { //if item is a file
//only get HTML files
$chunks = explode(«.», $contents[$x]);
if ($chunks[count($chunks) -1] == «html») {
//open file
$handle = fopen($path, «r»);
$fsize = filesize($path);
$fileContents = fread($handle, $fsize);
//get text from page
$pageChunks = split(«<title>», $fileContents);
$title = split(«</title>», $pageChunks[1]);
//strip tags from each file
$cleanContents = strip_tags($fileContents);
if(stristr($cleanContents, $term) === FALSE) {
continue;
} else {
//trim start of string
$trimmedPath = substr($path, 2);
//add to matching URLs array
$urls[] = array(«url» => $trimmedPath, «title» => $title[0]);
}
}
}
}
|
Цикл for , который включает в себя довольно много функциональности, циклически перебирает каждый элемент в массиве, возвращаемом scandir . Помните, что на данном этапе это просто содержимое стартового каталога, с которым мы работаем.
Сначала мы строим путь для каждого элемента, объединяя начальный каталог с косой чертой и текущим именем файла. Это необходимо для того, чтобы мы могли получить доступ к файлам, которые находятся в любых подкаталогах внутри исходного каталога.
Затем мы проверяем, является ли текущий элемент каталогом, используя встроенную функцию PHP is_dir . Если это каталог, мы игнорируем каталоги current ( . ) И parent ( .. ), так что мы получаем только подкаталоги, а затем рекурсивно вызываем функцию searchFiles , передавая переменную $ path в качестве каталога для поиска и Массив $ urls, если он существует. Он будет существовать только в том случае, если функция уже была вызвана, и, если она существует, будет содержать URL-адреса любых страниц, которые уже были найдены и в которых содержится искомое условие.
Если текущий элемент является файлом, который мы подтверждаем функцией is_file , мы затем проверяем расширение файла, чтобы увидеть, является ли это тип файла, который мы хотим найти. Очевидно, что мы не хотим искать файлы сценариев, файлы CSS или любой другой ресурс, который не содержит контента. В этом примере мы просто ищем файлы HTML. Мы можем проверить расширение, взорвав строку, используя точку в качестве разделителя, а затем посмотрев на последний элемент в результирующем массиве.
Если текущий элемент имеет расширение HTML, мы открываем файл в режиме только для чтения и сохраняем все содержимое файла, теги и все, в переменной $ fileContents . Мы используем PHP-функцию filesize, чтобы обеспечить чтение всего файла в переменную. Содержимое файла будет сохранено как одна длинная строка.
Далее мы хотим получить заголовок страницы, чтобы мы могли использовать его, если файл содержит поисковый запрос. Мы можем сделать это легко, сначала взорвав нашу гигантскую нить на
|
1
|
<title>
|
строка. Затем мы взрываем оставшуюся строку на
|
1
|
</title>
|
строка, которая даст нам заголовок страницы, которую мы храним в массиве $ title .
После этого мы можем дополнительно подготовить строку содержимого файла для обработки, удалив из нее все теги HTML. Это означает, что будет выполняться поиск только содержимого страницы. Как только мы получим чистую строку, мы сможем увидеть, находится ли искомый термин в строке, используя функцию stristr без учета регистра.
Если страница содержит искомый термин, мы затем приводим в порядок путь к файлу, удаляя первые два символа ( ./ ), так как они нам не понадобятся для ссылки на файл. Наконец, мы добавляем URL-адрес файла и заголовок страницы в качестве нового элемента в ассоциативный массив $ urls .
Как только функция завершится, мы можем вернуть ассоциативный массив:
|
1
2
|
//return array of filenames
return $urls;
|
У нас еще есть пара задач, которые нужно выполнить с помощью PHP; непосредственно после функции searchFiles добавьте следующий код:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
//set starting dir as current dir
$startDir = «.»;
//call function initially
$urls = searchFiles($startDir);
//delay response
sleep(1);
//convert to JSON obejct and echo to page
$response = $_GET[«jsoncallback»] .
echo $response;
|
Сначала мы устанавливаем текущий каталог в качестве начального каталога; переменная $ startDir передается функции searchFiles при первом ее вызове, что мы и делаем дальше, сохраняя возвращаемое значение (наш ассоциативный массив) в переменной $ urls . Если не найдено совпадений с поисковым термином, массив все равно будет создан, но он будет пустым, что мы можем проверить в нашем JavaScript чуть позже.
Мы также используем функцию сна PHP, чтобы задержать ответ на одну секунду; нам, вероятно, не нужно было бы делать это в реальной реализации, поскольку задержка между браузером и сервером в любом случае, вероятно, будет больше, чем эта, но для целей этого примера задержка ответа позволяет нам увидеть спиннер загрузки, который мы Я буду использовать и, кажется, заставить пример работать лучше.
Наконец, мы конвертируем массив $ urls в правильно отформатированный объект JSON, используя встроенную функцию PHP json_encode , и заключаем объект в фигурные скобки и получаем запрос Get , который мы затем возвращаем на страницу. Сохраните этот файл как search.php . Он должен войти в корневой каталог сайта, на котором он будет использоваться.
JSON
JSON — это легкий и эффективный механизм для передачи данных по сети. Как правило, с ним быстрее и проще работать, чем с XML, но он еще не достиг того же уровня принятия, что и XML. Метод, известный как JSONP, который изначально поддерживается jQuery, позволяет нам обрабатывать данные полностью в браузере и полностью без стандартной политики междоменного исключения. Это значительно упрощает доступ и повторное использование контента из удаленных доменов.
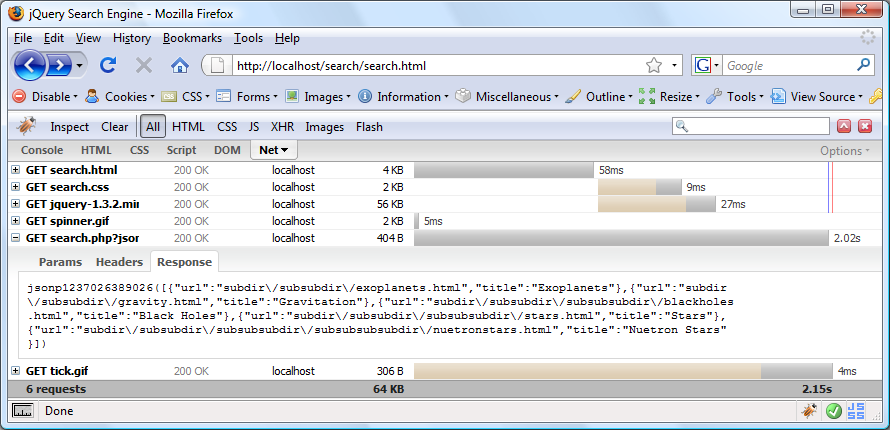
Наш файл PHP преобразует стандартный ассоциативный массив PHP в буквальный объект JSON, содержащий массив. Внутри каждого элемента в этом массиве будет другой объект, и данные, возвращаемые нашей функцией, будут отображаться как значения свойств в этом вложенном объекте. Мы еще не написали jQuery, который будет обрабатывать объект, но на следующем снимке экрана показано, как объект ответа будет отображаться в Firebug, чтобы вы могли визуализировать структуру JSON:
Некоторые jQuery и HTML
Теперь мы можем создать страницу, которая будет вызывать серверный скрипт, который мы только что создали при выполнении поиска; в новом файле в вашем текстовом редакторе добавьте следующий код:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
<!DOCTYPE HTML PUBLIC «-//W3C//DTD HTML 4.01//EN» «http://www.w3.org/TR/html4/strict.dtd»>
<html>
<head>
<link rel=»stylesheet» type=»text/css» href=»search.css»>
<meta http-equiv=»Content-Type» content=»text/html; charset=utf-8″>
<title>jQuery Search Engine</title>
</head>
<body>
<div id=»container»>
<h2 class=»text»>Search My Site:</h2>
<input type=»text» id=»query»><button id=»search» class=»text»>Search</button>
</div>
<script type=»text/javascript» src=»jquery-1.3.2.min.js»></script>
<script type=»text/javascript»>
</script>
</body>
</html>
|
Мы ссылаемся на таблицу стилей, которую мы вскоре напишем, и на jQuery. На странице просто есть пользовательский интерфейс поиска, который состоит из контейнера, метки, ввода и кнопки, и ничего больше. Остальные элементы, которые использует поисковый виджет, мы создадим по мере необходимости. Мы также оставили пустой элемент скрипта внизу страницы; внутри этих тегов добавьте следующий код:
|
1
2
3
|
$(function() {
});
|
Это сокращенный способ jQuery для указания функции, выполняемой при загрузке страницы. Вся логика передачи поискового запроса на сервер и обработки ответа будет лежать в этой анонимной функции. Теперь добавьте следующий код в функцию:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
//hide noResults message if present
($(«#noResults»).length > 0) ?
$(this).remove();
}) : null ;
//hide error if present
($(«#error»).length > 0) ?
$(this).remove();
}) : null ;
//hide results if present
($(«#results»).length > 0) ?
$(this).remove();
}) : null ;
//hide success icon if present
($(«#success»).length > 0) ?
$(this).remove();
}) : null ;
|
Сначала нужно проверить, отображаются ли результаты, сообщения об ошибках или любые предыдущие результаты в случае, если посетитель уже взаимодействовал с пользовательским интерфейсом. Мы также можем проверить значок успеха, который мог быть добавлен к виджету.
Если существует какой-либо из них (который мы добавим в ближайшее время), который мы проверяем, проверяя, возвращает ли jQuery что-нибудь, когда мы проверяем это с помощью селектора идентификаторов , мы просто скрываем их с помощью анимации fadeOut и затем удаляем их со страницы с помощью обратного вызова, который выполняется после завершения анимации.
Далее мы проверяем, что текстовый ввод для поискового запроса не пустой:
|
1
2
3
4
5
6
7
8
|
//check input not empty
if($(«#query»).val()) {
} else {
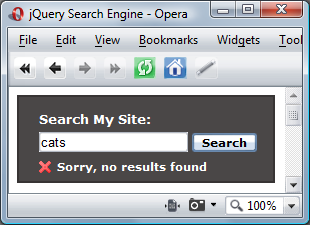
//show error message
$(«<p>»).addClass(«text»).attr(«id», «noResults»).text(«Sorry, no results found»).appendTo(«#container»).slideDown(«fast»);
}
|
Если ввод пуст, мы можем создать и отобразить простое сообщение об ошибке, которое предотвращает пустые представления и предупреждает посетителя об ошибке. Мы можем показать ошибку, используя анимацию slideDown . На следующем снимке экрана показано, как будет выглядеть ошибка:
Первая ветвь условного, однако, — то, где большая часть обработки имеет место; добавьте следующий код в первую часть оператора if :
|
01
02
03
04
05
06
07
08
09
10
|
//disable button and input
$(this).attr(«disabled», «disabled»);
$(«#query»).attr(«disabled», «disabled»);
//add spinner
$(«<img>»).attr({ src: «spinner.gif», id: «spinner» }).css({ position: «absolute», top: 27, right: 80 }).insertAfter(«#search»);
//get search term and build querystring
var term = $(«#query»).val(),
query = «term=» + term;
|
Сначала мы отключаем кнопку, чтобы запретить многократные отправки одного и того же поискового запроса. Мы также отключаем ввод как визуальную подсказку к поисковому запросу. Затем мы можем добавить небольшой загрузчик, чтобы он выглядел так, как будто страница что-то делает, ожидая ответа. Загрузка блесен — это круто, и их можно скачать в готовом для использования формате с различных сайтов. Мы добавляем его на страницу и просто размещаем так, чтобы он оказался внутри ввода. Затем мы получаем значение, введенное во вход, и строим строку запроса, которая будет передана на сервер. На следующем рисунке показано, как будет выглядеть блесна:

Далее мы можем сделать запрос, используя метод getJSON в jQuery:
|
1
2
3
4
|
//request JSON object of matching urls
$.getJSON(«search.php?jsoncallback=?», query, function(data) {
});
|
Мы предоставляем три аргумента для метода; Первый — это URL нашего PHP-файла с присоединенной строкой запроса JSONP. Имя, которое мы указываем после первого вопросительного знака, должно совпадать с именем, которое мы присвоили суперглобальному значению, переданному в запросе GET с сервера. Добавление =? после этого включается JSONP. jQuery автоматически передает объект ответа анонимной функции, которую мы передаем методу getJSON в качестве третьего аргумента. Второй аргумент — это данные, которые мы изначально хотим отправить на сервер, что, конечно, является поисковым термином.
Анонимная функция будет выполнена, когда ответ от сервера будет получен, давайте добавим код для него далее; в фигурных скобках добавьте следующий код:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
if (data.length > 0) {
//add success icon
$(«<div>»).attr(«id», «success»).insertAfter(«#container > h2»).fadeIn(«fast»);
//create container for results
$(«<div>»).attr(«id», «results»).css(«display», «none»).appendTo(«#container»);
//add message
$(«<p>»).addClass(«text»).text(«The following pages contain the search term:»).appendTo(«#results»);
//create list
$(«<ul>»).attr(«id», «resultList»).appendTo(«#results»);
//process response
for (var x = 0; x < data.length; x++) {
//create list item
var li = $(«<li>»);
//create result
$(«<a />»).addClass(«result text»).attr(«href», data[x].url).text(data[x].title).appendTo(li);
li.appendTo(«#resultList»);
}
//show results
$(«#results»).slideDown(«fast»);
|
Сначала мы проверяем, что длина объекта ответа больше нуля; если это так, мы создаем значок успеха, который будет добавлен сразу после элемента h2. Мы добавим некоторые другие значки позже в CSS, но этот нужно создать здесь. Значок появится, как на следующем скриншоте:
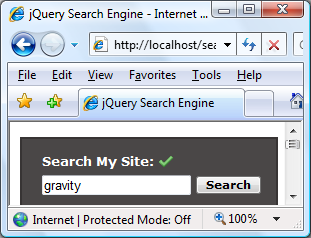
Мы также создаем элемент контейнера для результатов и добавляем его в основной контейнер виджета, хотя мы не показываем его сразу. Затем мы добавляем сообщение об успешном завершении в контейнер результатов. Окончательная предварительная обработка DOM, которую мы делаем, заключается в создании нового неупорядоченного элемента списка.
Далее мы используем простой цикл for для циклического прохождения каждого элемента в массиве нашего объекта. Каждый элемент будет представлять одну страницу, содержащую поисковый термин, поэтому все, что мы делаем на каждой итерации, — это создание нового элемента списка и создание ссылки на страницу, используя URL-адрес для ссылки и заголовок страницы в качестве текст ссылки (мы также можем использовать его для заголовка ссылки). Затем ссылка добавляется к элементу списка, а элемент списка к списку.
После прохождения каждого элемента в массиве мы показываем результаты, используя приятную анимацию slideDown. Теперь нам нужно учитывать, является ли объект ответа пустым массивом. Это будет означать, что ни одна страница не содержит поискового запроса:
|
1
2
3
4
5
|
} else {
//show error message
$(«<p>»).addClass(«text»).attr(«id», «noResults»).text(«Sorry, no results found»).appendTo(«#container»).slideDown(«fast»);
}
|
Все, что нам нужно сделать, это показать сообщение об ошибке, указывающее, что не найдено ни одной подходящей страницы. Мы добавляем его на страницу и снова показываем с анимацией. Последний бит jQuery будет выполнен независимо от того, возвращены результаты или нет:
|
1
2
3
4
5
6
|
//remove spinner
$(«#spinner»).remove();
//enable button and input
$(«#search»).attr(«disabled», «»);
$(«#query»).attr(«disabled», «»);
|
Мы просто удаляем загрузочный счетчик и снова активируем кнопку и ввод, чтобы можно было продолжить поиск. На этом этапе должен быть виден либо список результатов, либо сообщение об ошибке. Это подводит нас к концу кода jQuery; нам просто нужно добавить немного CSS сейчас, и наш виджет должен быть завершен. Сохраните файл как search.html .
Маленький стиль
Теперь нам просто нужно добавить немного CSS для завершения виджета; Многие стили предназначены исключительно для оформления, но некоторые из них влияют на поведение виджета. Список результатов поиска будет отображаться в раскрывающемся списке в нижней части контейнера поиска, как меню, и будет перекрывать любой другой контент, который может быть на странице, поэтому требуются некоторые стили.
На новой странице вашего текстового редактора добавьте следующие селекторы и правила:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
.text {
font-family:verdana;
}
#container {
width:234px;
border:2px solid #373434;
}
#container h2 { margin:4px 0;
#query {
margin-right:4px;
font-size:80%;
}
#search { color:#000000;
#error {
margin:8px 0 0;
padding-left:28px;
}
#success {
background:url(tick.gif) no-repeat;
margin:7px 0 0 5px;
}
#results {
position:absolute;
background-color:#4a4747;
}
#resultList { margin:0 0 10px;
#resultList li { list-style-type:none;
#resultList li a { text-decoration:none;
#resultList li a:hover { text-decoration:underline;
#noResults {
position:absolute;
}
|
Сохраните этот файл как search.css . Первый селектор является классом для всего текста в виджете и просто более удобен, чем установка одинаковых правил для каждого из текстовых элементов в отдельности. Помимо этого мы устанавливаем некоторые размеры и некоторые положения. Большинство элементов, которые мы создаем динамически, изначально скрыты, так что мы можем анимировать их, а не просто отображать их мгновенно.
В виджете достаточно места для отсутствия результатов и сообщений об ошибках, поэтому они расположены абсолютно внутри внешнего контейнера виджетов. Раскрывающееся меню результатов также расположено абсолютно, так что оно не перемещает содержимое другой страницы и выравнивается по левому и нижнему краям контейнера виджета. Мы также добавляем изображения иконок здесь.
Резюме
Теперь это весь код, который нам нужен для создания полнофункционального виджета. Для придания этому примеру большей отдачи загрузка кода содержит поддельный сайт с большим количеством контента, который мы можем найти. Все, что вам нужно сделать, это перетащить основную папку в каталог контента на веб-сервере, на котором установлен и настроен PHP.
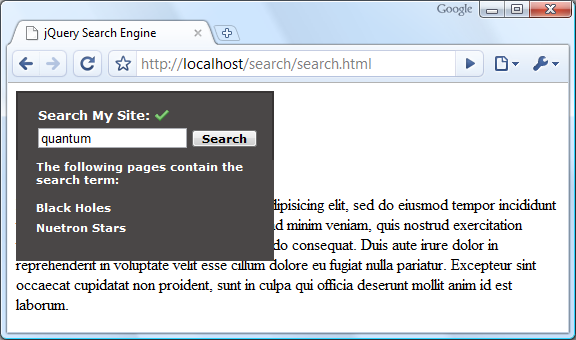
Мы должны обнаружить, что, если мы нажмем кнопку, не введя слово в текстовое поле, мы увидим сообщение об ошибке, а если мы найдем что-то, что не найдено, мы увидим сообщение без результатов. Когда мы ищем найденный термин, мы видим раскрывающийся список результатов и можем перейти на любую страницу в списке. На следующем снимке экрана показано, как будет выглядеть меню результатов (я также добавил фиктивный контент на страницу поиска, чтобы мы могли убедиться, что меню будет перекрывать другой контент, не мешая потоку страниц):
Скринкаст: часть 1
Часть 2
Некоторое время назад я написал учебное пособие, посвященное созданию статического поискового движка, который просматривал иерархию сайтов и просматривал каждую найденную веб-страницу по заданной текстовой строке. Этот тип поиска был нацелен на владельцев веб-сайтов, состоящих из статических HTML-страниц. В этом уроке мы собираемся сделать то же самое, но на этот раз вместо того, чтобы перемещаться по папкам и подпапкам в поисках страниц, вместо этого мы будем искать базу данных. Этот тип поиска предназначен для сайтов, которые создаются динамически из содержимого базы данных, таких как многие популярные платформы для ведения блогов.
В целом, мы будем делать то же самое; мы захватим поисковое слово из ввода, запросим файл PHP, передав слово поиска. Затем мы будем искать поисковый термин и возвращать список URL-адресов страниц, которые содержат поисковый термин в виде объекта JSON. Затем мы можем обработать ответ и создать список результатов для отображения (или предоставить сообщение, если термин не найден).
Хотите верьте, хотите нет, но поиск в базе данных контента на самом деле проще и требует меньше кода, чем рекурсивный и исчерпывающий поиск по каталогам и подкаталогам, поэтому для примерно того же объема кода мы можем сделать то же самое, что и раньше, но добавить некоторые новые функции такие как сортировка результатов и создание навигации по списку с помощью клавиатуры. Для справки мы будем использовать MySQL версии 5.0 и PHP версии 5.2.
Темы, которые мы будем охватывать, приведены ниже:
- Создание и заполнение базы данных с помощью MySQL CLI (интерфейс командной строки)
- Чтение базы данных с помощью PHP
- Поиск по тексту с помощью PHP
- Работа с массивами PHP — многомерная и ассоциативная
- Создание JSON и его передача в браузер таким образом, чтобы можно было использовать JSONP
- Обработка JSON с помощью jQuery
- Работа с событиями клавиатуры в jQuery
Начиная
Возможно, вы не читали предыдущий учебник или не получили исходные файлы из этого примера. Не волнуйся; тебе они не нужны. Мы рассмотрим каждую строку кода, которую нужно написать, как если бы это была отдельная статья. Прочтение предыдущего урока не является обязательным требованием для прочтения этого учебника, хотя, это даст вам лучшее основание.
Первое, что мы должны сделать, это создать рабочую среду; нам потребуется полный веб-сервер, установленный и настроенный, с PHP и MySQL, также доступными. В каталоге содержания веб-сервера создайте новую папку с именем dbSearch . Это папка проекта, в которой будут храниться все ресурсы, которые мы создаем. На данный момент, все, что нужно, чтобы перейти в эту папку, это последняя версия jQuery (1.3.2 на момент написания).
Создание базы данных
При развертывании этого виджета в блоге или на сайте, управляемом данными, база данных, содержащая контент, уже будет существовать. Однако для целей этого урока нам нужно его настроить. Мы можем сделать это быстро и легко, используя MySQL CLI. В CLI (открыв его и введя пароль) введите следующую команду:
|
1
|
CREATE DATABASE dbSearch;
|
Обратите внимание, что CLI не чувствителен к регистру, но многие люди, особенно новички в MySQL, считают, что использование команд с заглавной буквы помогает отличать команды от значений и других идентификаторов. Эта команда создаст новую базу данных с именем dbSearch . После создания мы должны выбрать базу данных для использования с помощью следующей команды:
|
1
|
USE dbSearch
|
Команда USE — одна из немногих, возможно, только команд, которые не должны заканчиваться точкой с запятой. Затем мы должны создать таблицу для хранения данных. Мы можем сделать это с помощью команды CREATE :
|
1
|
CREATE TABLE pages(url TINYTEXT, title TINYTEXT, content MEDIUMTEXT);
|
Эта команда создаст новую таблицу с именем pages и добавит в нее три столбца; столбец url, который мы будем использовать для хранения относительного имени файла для каждой страницы, столбец заголовка, в котором мы можем хранить заголовки страниц, и столбец содержимого, в котором мы будем хранить содержимое страницы. Мы используем варианты TEXT тип данных для данных, которые мы добавим в таблицу; В первом варианте TINYTEXT может содержать до 255 символов, что не так много в общей схеме, но достаточно просто для любого из URL или заголовков страниц, которые мы будем использовать в этом примере.
Для столбца содержимого задан тип данных MEDIUMTEXT , который допускает использование до 16777215 символов (около 15 МБ). В правильной реализации мы, вероятно, хотели бы использовать LONGTEXT , который допускает примерно до 4 ГБ текста. Помните, что в зависимости от платформы, на которой построен ваш блог, база данных и таблицы, вероятно, уже существуют и будут настроены. На этом этапе окно CLI должно выглядеть примерно так:

Загрузка данных в таблицу
Это еще один шаг, который не нужно выполнять при развертывании на действующем сайте, поскольку база данных уже будет содержать такую информацию. Однако для целей этого урока нам нужны поддельные данные для поиска.
Существует множество различных способов ввода данных в таблицу базы данных; мы могли бы вручную вводить данные по одной записи за раз, что нормально для небольших наборов данных, но, вероятно, немного монотонно для объема данных, которые мы будем вводить в этом примере. Вместо этого мы отправим текстовый файл в нашу базу данных, чтобы заполнить его некоторым содержимым. Текстовый файл включен в код загрузки для этого примера.
При загрузке данных в базу данных с использованием текстового файла его содержимое необходимо структурировать определенным образом. Каждая строка соответствует отдельной записи, и данные для каждого столбца должны быть разделены пробелами, как в следующем примере:
|
1
|
afilename.html The Title Some content, lorem ipsum etc, etc.
|
Создав текстовый файл (или извлекая его из загрузки кода), мы должны указать MySQL использовать его и использовать данные в нем для заполнения нашей таблицы. Следующая команда достигнет этого:
|
1
|
LOAD DATA LOCAL INFILE ‘c:/apache site/dbSearch/tableData.txt’ INTO TABLE pages LINES TERMINATED BY ‘\r\n’;
|
Мы просто сообщаем серверу, в каком файле содержатся данные, в какой таблице они должны быть загружены и как заканчивается каждая строка в файле. Строка, указанная в качестве ограничителя строки, зависит от платформы, используемой для создания текстового файла.
Чтобы убедиться, что данные загружены в таблицу правильно, мы можем проверить это с помощью команды SELECT :
|
1
|
SELECT * FROM pages;
|
Это должно просто выбрать все данные в таблице и вывести их в CLI, как показано на следующем снимке экрана:
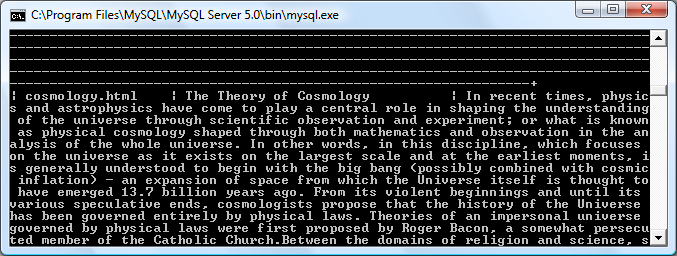
Каждый столбец и запись разделяются символом канала | ,
Серверный PHP
Теперь, когда у нас есть наш источник данных, мы можем работать с файлом, который будет взаимодействовать с ним — с PHP-файлом на стороне сервера. Следующее кодирование этого файла означает, что когда мы приступим к выполнению jQuery, который соберет все воедино, нам будут доступны данные. В новом файле в вашем текстовом редакторе добавьте следующий код:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
<?php
//db connection detils
$host = «localhost»;
$user = «root»;
$password = «your_password_here!»;
$database = «dbSearch»;
//get search term from GET
$term = » » .
//make connection
$server = mysql_connect($host, $user, $password);
$connection = mysql_select_db($database, $server);
//query the database
$query = mysql_query(«SELECT * FROM pages»);
//loop through and return results
for ($x = 0, $numrows = mysql_num_rows($query); $x < $numrows; $x++) {
$row = mysql_fetch_assoc($query);
if(substr_count(strtolower($row[«content»]), strtolower($term)) === 0) {
continue;
} else {
$urls[] = array(«url» => $row[«url»], «title» => $row[«title»], «occurs» => substr_count(strtolower($row[«content»]), strtolower($term)));
}
}
// Comparison function
function cmp($a, $b) {
return ($a[«occurs»] > $b[«occurs»]) ?
}
// Sort the array
uasort($urls, «cmp»);
//set GET response and convert data to JSON
$response = $_GET[«jsoncallback»] .
//delay response
sleep(1);
//echo JSON to page
echo $response;
?>
|
Сохраните этот файл как search.php в папке dbSearch . Это гораздо меньше кода на стороне сервера, чем было необходимо в первой части — использование базы данных действительно помогает упростить наш код. Давайте пройдемся по файлу и посмотрим, что мы делаем.
Первые четыре переменные используются для хранения информации о соединении, которую нам нужно будет предоставить для взаимодействия с базой данных. Не забудьте изменить переменную пароля на ту, которую вы используете для входа в MySQL CLI. Затем мы получаем поисковый термин, который будет передан в скрипт на странице. Мы заключаем поисковый термин в пробелы, так что сопоставляется только само слово, а не слова в других словах. Например, если мы этого не сделаем, поиск дыры также будет соответствовать целому .
Затем мы подключаемся к серверу MySQL и выбираем базу данных, используя только что определенные переменные. Мы также запрашиваем базу данных, выбирая все строки данных в таблице. Мы используем ту же команду для выбора данных, что и при использовании CLI ранее.
Затем мы перебираем каждую строку данных, возвращаемых запросом, используя цикл PHP for. Цикл принимает четыре аргумента; переменная счетчика $ x , общее количество строк в таблице, условие для выполнения другой итерации цикла (в то время как переменная счетчика меньше общего числа строк) и приращение счетчика, которое увеличит значение переменной счетчика на 1 на каждой итерации цикла.
Поиск данных
Первое, что мы делаем в цикле, — сохраняем текущую строку данных в переменной $ row, используя PHP-функцию mysql_fetch_assoc, которая возвращает ассоциативный массив, в котором каждый столбец в строке таблицы отображается как элемент массива. Имя столбца — это метка, используемая для доступа к каждому элементу в массиве.
Затем мы ищем элемент содержимого в массиве, используя оператор if и PHP-функцию substr_count, чтобы узнать, встречается ли поисковый термин 0 раз. Если это происходит 0 раз, мы просто переходим к следующей итерации цикла. Если строка встречается более 0 раз, мы создаем новый многомерный массив с именем $ urls и добавляем в него элементы url и title массива, а также появляется новый вызываемый элемент, который представляет собой целое число, возвращаемое функцией substr_count . Каждый элемент в этом массиве сам по себе является ассоциативным массивом. Мы используем функцию strtolower, чтобы сделать поиск нечувствительным к регистру.
Результатом этого кода является многомерный массив, в котором каждый элемент является ассоциативным массивом, содержащим URL-адреса, заголовки страниц и количество раз, которое был найден поисковый термин для страниц, содержание которых содержит поисковый термин. Следующее, что мы можем сделать дальше, чтобы действительно добавить значение к поиску, это отсортировать массив так, чтобы первый элемент в массиве содержал наибольшее количество вхождений поискового термина, давая каждому результату «ранг». Мы можем сделать это очень легко, используя функцию uasort PHP.
Функция uasort ожидает 2 аргумента; массив для сортировки и пользовательская функция, где сравниваются элементы в массиве. Функция cmp — это пользовательская функция сравнения, которая принимает 2 элемента из массива, переданного в uasort . Затем функция вернет false или true, если значение первого встречающегося элемента больше, чем значение второго. Функция uasort автоматически преобразует внешний массив в ассоциативный массив, и каждому элементу будет присвоен первоначальный индекс предварительной сортировки в качестве метки.
Затем мы заключаем этот массив в скобки и преобразуем его в объект JSON. Каждое свойство этого объекта является вложенным объектом JavaScript, который мы сможем быстро и эффективно обработать в браузере. Непосредственно перед возвращением объекта JSON мы используем функцию сна PHP, чтобы задержать ответ на 1 секунду; эта часть скрипта не должна использоваться, если и когда этот виджет развернут. Я только что обнаружил при запуске этого примера локально, что он работает лучше с этой задержкой. После задержки мы возвращаем объект JSON. Мы еще не создали страницу, которая будет взаимодействовать с этим файлом, но на следующем снимке экрана показана структура, которую примет объект JSON:

Структура данных JSON
JSON — это подмножество JavaScript, которое позволяет нам определять простые или сложные объекты и массивы. Значения этих структур данных могут быть любыми из множества различных типов данных, включая строки, числа, логические или нулевые значения, и даже могут быть другими объектами, как в этом примере. Нативная функция PHP json_encode работает, сохраняя стандартные массивы так, чтобы они оставались массивами, но преобразовывая ассоциативные массивы в объекты. Когда это происходит, метка элемента ассоциативного массива используется в качестве имени свойства.
Структура объекта JSON, который мы используем в этом примере, отличается от структуры, которую мы использовали в первой части этого урока. Причина этого, как я объяснил ранее, заключается в дополнительных данных, предоставляемых функцией uasort . Ранее наш объект JSON был массивом, который мы могли быстро и легко перебирать. Тот факт, что структура нашего объекта JSON изменилась, не усложняет доступ к нашим данным, как мы вскоре увидим.
Для справки, мы можем легко вернуть наш объект JSON в массив, обернув массив внутри PHP-функции array_values внутри функции json_encode , например так:
|
1
2
|
//set GET response and convert data to JSON $response = $_GET["jsoncallback"] . "(" . json_encode(array_values($urls)) . ")"; |
Однако код, который мы будем использовать для обработки нашего объекта JSON в этом примере, чрезвычайно гибок, поскольку его можно использовать для доступа к данным в нашем новом формате JSON, но точно такой же код можно использовать для доступа к формату массива, который JSON принял участие в первой части.
Стилизация виджета поиска
Далее мы можем определить таблицу стилей для нашего виджета; В новом файле добавьте следующие селекторы и правила:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
.text { font-family:verdana;
margin-top:0; }
#container {
position:relative;
border:2px solid #373434; padding:10px 0 30px 20px; }
float:left;
#query { padding:0;
font-size:80%; width:145px; }
position:relative;
#error { margin:8px 0 0; display:none; background:url(warn.gif) no-repeat 6px 0; position:absolute;
}
#success { background:url(tick.gif) no-repeat; width:14px; height:11px; float:left;
}
#noResults { position:absolute;
background:url(cross.gif) no-repeat 0 1px; padding-left:18px; }
#results { position:absolute;
left:-2px;
display:none; }
}
padding:0;
white-space:nowrap;
}
}
}
|
Сохраните этот файл как search.css в папке dbSearch . Давайте посмотрим на стили, которые мы определяем; Сначала мы создаем класс для текстовых элементов, чтобы различные элементы оформления были единообразно стилизованы. Следующие четыре селектора идентификаторов предназначены для элементов по умолчанию, которые появляются в виджете поиска при начальной загрузке страницы. Практически все стили, установленные этими правилами, являются произвольными и были выбраны мной для целей данного примера. Вот как это будет выглядеть при загрузке страницы:

В #ERROR и #success селекторов для различных типов обратной связи , которые пользователь может получать, например, сообщение, которое отображается при отсутствии термина поиска не вводится, сообщение, которое отображается , когда поисковый термин не найден, или значок, который отображается, когда результаты найдены. Опять же, большинство стилей, используемых для этих элементов, могут быть изменены в соответствии с вашими предпочтениями. Наиболее важным правилом в каждом из них является отображение: нет; что, конечно, скрывает их, пока они не будут готовы к показу. На следующем снимке экрана показано сообщение об ошибке:
Все остальные правила используются для стилизации списка результатов, который создается, когда искомое условие найдено в хранилище данных. Мы не знаем заранее, как долго будет длиться каждый результат, поэтому мы используем правило минимальной ширины, чтобы позволить ширине списка результатов увеличиваться. Бело-пространство: Nowrap правило также предотвращает ширину каждого из результатов от быть ограничено.
Опять же, многие правила здесь используются для установки этого конкретного скина, и ничего более, так что вы можете легко изменить внешний вид виджета, не мешая его работе. Меню расположено абсолютно так, что оно не мешает другим элементам на странице. Когда результаты представлены, первый результат фокусируется и к нему применяется выбранный класс. Мы устанавливаем контур фокуса ссылки в том же цвете, что и выбранный класс, вместо удаления контура фокуса по причинам доступности. На следующем снимке экрана показано, как будет выглядеть список результатов:

Создание оболочки страницы
Сначала мы рассмотрим основную страницу; В новом файле в вашем текстовом редакторе создайте следующую страницу:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
|
<!DOCTYPE HTML PUBLIC «-//W3C//DTD HTML 4.01//EN» «http://www.w3.org/TR/html4/strict.dtd»>
<html>
<head>
<link rel="stylesheet" type="text/css" href="search.css"> <meta http-equiv=»Content-Type» content=»text/html; charset=utf-8″>
<title>jQuery Search Engine</title> </head>
<body>
<div id=»container»>
<h2 class="text">Search My Site:</h2> <input type="text" id="query" tabindex=1><button id="search" class="text">Search</button> </div>
<p>Lorem ipsum dolor...</p> <script type=»text/javascript» src=»jquery-1.3.2.min.js»></script>
<script type=»text/javascript»>
$(function() {
});
</script>
</body>
</html>
|
Страница настолько проста, насколько это возможно, имея только виджет поиска и некоторый текст макета. Здесь приведен текст, показывающий, как список результатов перекрывает любое существующее содержимое страницы (хотя нет никаких условий для наложения флэш-содержимого или полей выбора). Сам виджет также очень минимален, содержит простой заголовок, поисковый ввод и кнопку. Остальные элементы, которые нам понадобятся, мы можем создать по мере необходимости.
Мы ссылаемся на нашу таблицу стилей в заголовке страницы, а также на локальную версию jQuery в конце тела. После этого мы оставляем элемент script, содержащий стандартную функцию jQuery document.ready, в которой будет находиться основная часть нашего кода. Мы можем добавить это дальше; их много, поэтому после следующего примера кода мы посмотрим, что каждый бит делает по отдельности:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
|
//click handler for button $("#search").click(function() { //hide noResults message if present ($("#noResults")) ? $("#noResults").fadeOut("fast", function() { $(this).remove();
}) : null ; //hide error if present ($("#error")) ? $("#error").fadeOut("fast", function() { $(this).remove();
}) : null ; //hide results if present ($("#results")) ? $("#results").fadeOut("fast", function() { $(this).remove();
}) : null ; //hide success icon if present ($("#success")) ? $("#success").fadeOut("fast", function() { $(this).remove();
}) : null ; //check input not empty if($("#query").val()) { //disable button and input $(this).attr("disabled", "disabled"); $("#query").attr("disabled", "disabled"); //add spinner $("<img>").attr({ src: "spinner.gif", id: "spinner" }).css({ position: «absolute»,
top: 38, right: 90 }).insertAfter("#search"); //get search term and build querystring var term = $("#query").val(), query = "term=" + term; //request JSON object of matching urls $.getJSON("search.php?jsoncallback=?", query, function(data) { if (!data) { //show error message $("<p>").addClass("text").attr("id", "noResults").text("Sorry, no results found").appendTo("#container").slideDown("fast"); } else {
//add success icon $("<div>").attr("id", "success").insertAfter("#container > h2").fadeIn("fast"); //create container for results $("<div>").attr("id", "results").appendTo("#container"); //add message $("<p>").addClass("text").text("The following pages contain the search term:").appendTo("#results"); //create list $("<ol>").attr("id", "resultList").appendTo("#results"); //process response
for (prop in data) { //create list item
var li = $("<li>"); //create result $("<a />").addClass("result text").attr({ href: data[prop].url, title: data[prop].title + " (" + data[prop].occurs + " occurences)" }).text(data[prop].title).appendTo(li); li.appendTo("#resultList"); }
//add some extra class names $("#resultList").children(":first").addClass("first").parent().children(":last").addClass("last"); //show results $("#results").slideDown("fast", function() { //add class to first item and focus link $(this).find("ol").children(":first").addClass("selected").find("a").focus(); });
}
//remove spinner $("#spinner").remove(); //enable button and input $("#search").attr("disabled", ""); $("#query").attr("disabled", ""); });
} else {
//display error ($("#error").length > 0) ? null : $("<p>").attr("id", "error").addClass("text").text("Please enter a search term!").appendTo("#container").slideDown("fast"); }
});
|
Весь этот код инкапсулирован в обработчике кликов для кнопки поиска; внутри анонимной функции, которую мы передаем методу click helper, есть несколько отдельных разделов. Давайте посмотрим на каждого из них по очереди.
домоводство
Наша первая задача — привести в порядок, так как это может быть не первый раз, когда нажимается кнопка, и могут быть элементы, оставшиеся от предыдущих взаимодействий. Есть четыре вещи, которые мы должны искать и удалять, если они присутствуют:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
//hide noResults message if present ($("#noResults")) ? $("#noResults").fadeOut("fast", function() { $(this).remove();
}) : null ; //hide error if present ($("#error")) ? $("#error").fadeOut("fast", function() { $(this).remove();
}) : null ; //hide results if present ($("#results")) ? $("#results").fadeOut("fast", function() { $(this).remove();
}) : null ; //hide success icon if present ($("#success")) ? $("#success").fadeOut("fast", function() { $(this).remove();
}) : null ; |
Мы можем проверить, существует ли каждый из этих элементов, используя троичную конструкцию JavaScript; если они существуют, мы исчезаем, если они не существуют, мы ничего не делаем.
Обработка перед поиском
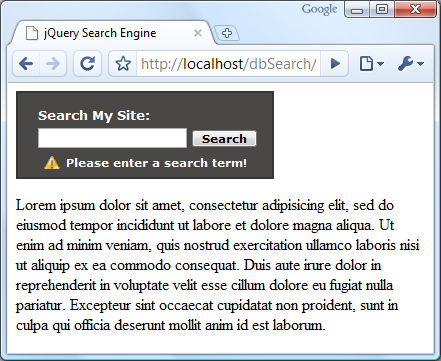
Далее есть несколько вещей, которые нам нужно сделать, прежде чем мы начнем настоящий поиск; сначала мы проверяем, имеет ли поле ввода в виджете значение, и если его нет, мы показываем сообщение об ошибке:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
//check input not empty if($("#query").val()) { //disable button and input $(this).attr("disabled", "disabled"); $("#query").attr("disabled", "disabled"); //add spinner $("<img>").attr({ src: "spinner.gif", id: "spinner" }).css({ position: «absolute»,
top: 38, right: 90 }).insertAfter("#search"); //get search term and build querystring var term = $("#query").val(), query = "term=" + term; } else {
//display error ($("#error").length > 0) ? null : $("<p>").attr("id", "error").addClass("text").text("Please enter a search term!").appendTo("#container").slideDown("fast"); }
|
На самом деле внутри первой части условного кода гораздо больше кода, но это все, что мы делаем перед тем, как сделать запрос; сначала мы отключаем и кнопку, и элемент ввода, чтобы предотвратить многократные отправки во время выполнения запроса. Мы также добавили спиннер AJAX, чтобы посетитель знал, что что-то происходит за кулисами.
Последнее, что мы делаем перед тем, как сделать запрос, — это подготовка данных, которые должны быть отправлены на сервер, — это поисковый термин, введенный в поле ввода.
Запрос и обработка ответа
Теперь мы готовы запросить и обработать ответ; сделать запрос легко с помощью метода jJuery getJSON :
|
1
2
3
4
|
//request JSON object of matching urls $.getJSON("search.php?jsoncallback=?", query, function(data) { });
|
Метод принимает три аргумента; URL-адрес ресурса на стороне сервера, который получит запрос и вернет данные. Второй аргумент — это данные, отправляемые на сервер, а последний — анонимная функция обратного вызова, которая будет выполнена в случае успешного запроса. Код, который входит в эту анонимную функцию, используется для обработки ответа и отображения результатов:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
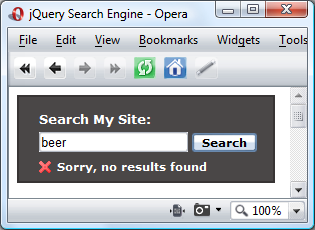
if (!data) { //show error message $("<p>").addClass("text").attr("id", "noResults").text("Sorry, no results found").appendTo("#container").slideDown("fast"); } else {
}
//remove spinner $("#spinner").remove(); //enable button and input $("#search").attr("disabled", ""); $("#query").attr("disabled", ""); |
В этом разделе мы сначала проверяем наличие данных в ответе; если поисковый термин не найден в базе данных, будет возвращен ноль, и если это так, мы можем создать и показать сообщение. Сообщение будет выглядеть так:
После того, как мы обработали объект и отобразили либо сообщение «нет результатов», либо результаты, мы можем затем удалить счетчик AJAX и активировать кнопку и ввод, чтобы разрешить выполнение дополнительных поисков.
Отображение результатов
Если поисковый термин найден, у нас будет объект JSON для обработки и результаты для создания и отображения:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
//add success icon $("<div>").attr("id", "success").insertAfter("#container > h2").fadeIn("fast"); //create container for results $("<div>").attr("id", "results").appendTo("#container"); //add message $("<p>").addClass("text").text("The following pages contain the search term:").appendTo("#results"); //create list $("<ol>").attr("id", "resultList").appendTo("#results"); //process response
for (prop in data) { //create list item
var li = $("<li>"); //create result $("<a />").addClass("result text").attr({ href: data[prop].url, title: data[prop].title + " (" + data[prop].occurs + " occurences)" }).text(data[prop].title).appendTo(li); li.appendTo("#resultList"); }
//add some extra class names $("#resultList").children(":first").addClass("first").parent().children(":last").addClass("last"); //show results $("#results").slideDown("fast", function() { //add class to first item and focus link $(this).find("ol").children(":first").addClass("selected").find("a").focus(); });
|
Сначала нам нужно создать несколько новых элементов; мы создаем значок успеха, который вставляется в виджет и располагается таким образом, что он появляется рядом с заголовком виджета (он просто выглядит неуместно в любом другом месте), и элементом контейнера для результатов. Мы также создаем сообщение о том, что следующий список содержит результаты поиска.
Порядок элементов в списке важен в этом контексте, поэтому мы создаем упорядоченный элемент списка, который мы заполним через мгновение. Результаты поиска располагаются в порядке убывания внутри объекта JSON, причем наивысший рейтинг (т. Е. Страница, содержащая наибольшее количество вхождений поискового термина) находится вверху.
Затем мы используем для в цикле для перебора каждого свойства внутри объекта JSON; на каждой итерации мы создаем новый элемент списка, затем новый элемент привязки. Мы даем ссылке некоторые имена классов, чтобы они подбирали соответствующие стили. Мы устанавливаем некоторые атрибуты элемента link, используя различные значения свойств внутренних объектов в объекте JSON.
Это достигается с помощью комбинации скобок и точечных обозначений. Объект состоит из ряда свойств, а значением каждого свойства является другой объект. Внутри каждого внутреннего объекта есть еще ряд свойств, значения которых содержат наши данные. Для доступа к каждому свойству во внешнем объекте мы используем переменную prop , которая определена в цикле, используя синтаксис в квадратных скобках: data [prop], а для доступа к нашим данным мы просто добавляем имя свойства, значение которого нам нужно получить: .url например.
Мы также добавляем текстовое содержимое элемента привязки, используя данные из нашего объекта, прежде чем окончательно добавить его к элементу списка. После этого элемент списка добавляется в список. Когда цикл завершился, и все элементы списка были созданы и добавлены, нам нужно присвоить первому и последнему элементам списка конкретные имена классов, чтобы мы могли легко ссылаться на них позже в сценарии.
В заключительной части этого раздела кода мы перемещаем список результатов в поле зрения, а затем выбираем первый элемент в списке, присваиваем ему имя класса и фокусируем его. На этом мы и завершили первую часть этого урока, но теперь мы собираемся добавить навигацию клавиатуры к результатам.
Включение навигации по клавиатуре
Мы прикрепляем наш прослушиватель событий к привязке в элементе списка, у которого выбрано имя класса, которое мы применили к первому элементу в списке; таким образом, виджет будет прослушивать события только тогда, когда это уместно. Мы присоединяем слушателя, используя живой метод jQuery, чтобы нам не приходилось привязываться к событию всякий раз, когда мы показываем результаты:
|
1
2
3
4
|
//listen for keyboard events $(".selected").find("a").live("keydown", function(e) { });
|
При обнаружении события нажатия клавиши анонимная функция автоматически передается объекту события. Прежде чем мы перейдем к следующему пункту в списке, нам нужно сделать несколько вещей:
|
1
2
3
4
5
6
7
8
|
//prevent default browser behaviour for tab key (e.keyCode == 9) ? e.preventDefault() : null ; //close results if escape key clicked (e.keyCode == 27) ? $("#results").fadeOut("fast", function() { $(this).remove();
$("#query").val(""); }) : null ; |
Сначала нам нужно проверить, была ли нажатая клавиша клавишей табуляции, так как она имеет свое поведение по умолчанию, которое необходимо отключить. Мы делаем это, используя троичную часть JavaScript, чтобы увидеть, равно ли значение свойства keyCode объекта события 9. Если это так, мы предотвращаем поведение браузера по умолчанию с помощью метода protectDefault .
Мы также можем проверить, была ли нажата управляющая клавиша, и если это так, мы можем закрыть список результатов и сбросить значение поля ввода.
Затем нам нужно сделать разные вещи в зависимости от того, является ли текущий выбранный элемент списка первым или последним элементом в списке, который мы можем проверить, используя имена классов, которые мы добавили ранее:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
if($(this).parent().hasClass("first")) { //program up and down arrow keys and tab to move highlight (e.keyCode == 40 || e.keyCode == 9) ? $(this).parent().removeClass("selected").next().addClass("selected").children(":first").focus() : (e.keyCode == 38) ? $(this).parent().removeClass("selected").parent().children(":last").addClass("selected").children(":first").focus() : null ; } else if($(this).parent().hasClass("last")) { //program up and down arrow keys and tab to move highlight (e.keyCode == 40 || e.keyCode == 9) ? $(this).parent().removeClass("selected").parent().children(":first").addClass("selected").children(":first").focus() : (e.keyCode == 38) ? $(this).parent().removeClass("selected").prev().addClass("selected").children(":first").focus() : null ; } else {
//program up and down arrow keys and tab to move highlight (e.keyCode == 40 || e.keyCode == 9) ? $(this).parent().removeClass("selected").next().addClass("selected").children(":first").focus() : (e.keyCode == 38) ? $(this).parent().removeClass("selected").prev().addClass("selected").children(":first").focus() : null ; }
|
В каждой ветви условного выражения мы также должны реагировать по-разному в зависимости от того, какая клавиша была нажата; мы нацеливаемся на клавиши со стрелками вверх и вниз, которые перемещают выделение вверх или вниз по списку соответственно, а также на клавишу табуляции, которая перемещает выделение вниз по списку. Мы используем вложенное троичное условие для его компактного синтаксиса, который эквивалентен оператору if else .
Каждая ветвь внешнего условия содержит очень похожие выражения; давайте пройдемся по первому, чтобы посмотреть, что происходит. Первая часть троичного кода проверяет наличие клавиши со стрелкой вниз или клавиши табуляции, если обнаруживается любая из них, мы перемещаемся вверх от якоря, который находится в контексте $ (this) , к элементу родительского списка и удаляем выбранный имя класса Затем мы переходим к следующему элементу списка братьев и сестер и присваиваем ему выбранное имя класса. Затем перейдем к его первому дочернему элементу, который будет якорным элементом, и сфокусируем его.
Если ни одна из этих клавиш не обнаружена, мы проверяем наличие клавиши со стрелкой вверх, представленной 38. Мы хотим, чтобы выбор циклически проходил по списку, как если бы это было меню, поэтому, если клавиша вверх нажата, когда выбран первый элемент, мы должны перейти к последнему элементу в списке и применить выбранный класс и фокус. Если ни один из этих ключей не обнаружен, мы ничего не делаем.
Тройка в следующей ветви внешнего условного выражения очень похожа, но на этот раз мы смотрим на последний элемент списка, но на этот раз, если нажата клавиша «Вниз» или «Tab», мы перемещаем выделение к первому элементу в списке. Конечное условие снова очень похоже, но на этот раз мы просто перемещаем выделение вверх или вниз в зависимости от того, какая клавиша была нажата.
Кейтеринг для мышиных взаимодействий
Просто потому, что мы встроили навигацию с помощью клавиатуры в наш виджет, это не обязательно означает, что каждый посетитель собирается использовать его, поэтому для согласованности мы должны перемещать выделение вокруг, если указатель мыши наводится на какой-либо из элементов списка. Код для этого действительно очень прост:
|
1
2
3
4
5
6
7
|
//listen for mouseover $("#resultList").find("li").live("mouseover", function() { $(this).parent().children().removeClass("selected"); $(this).addClass("selected").children(":first").focus(); });
|
Это более простая версия того, что мы сделали с обработчиками событий клавиатуры; когда указатель находится над элементом списка, мы удаляем выбранный класс из всех элементов списка, а затем добавляем его обратно к любому элементу списка, фокусируя элемент привязки по ходу.
Наконец, мы можем добавить функцию, которая закроет меню результатов, если щелкнуть любой элемент за пределами меню. Мы делаем это путем присоединения обработчик щелчка к метке тела и проверки того, что элемент , который нажал не родитель выше в DOM , который является упорядоченный список с идентификатором из resultList :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
//add click handler to body $("body").click(function(e) { //close results if anything outside results is clicked if($(e.target).closest("ol").attr("id") != "resultList") { //remove menu ($("#resultList")) ? $("#results").fadeOut("fast", function() { $(this).remove();
$("#query").val(""); }) : null ; }
});
|
Присоединение слушателя события к телу в этой ситуации полезно, потому что клик по абсолютно любому элементу на странице будет пузыриться до тела, где мы можем захватить и исследовать его.
Резюме
Теперь у нас должен быть полностью работающий виджет, который позволит нам искать весь контент с сайта, который содержится в базе данных. Список результатов будет ориентирован как на клавиатуру, так и на мышь, и должен выглядеть так, как показано на следующем снимке экрана:
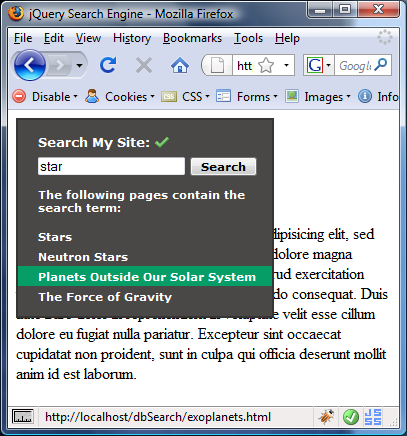
Давайте вспомним, что мы рассмотрели в этом уроке:
- Многие веб-сайты и блоги работают на базе данных, в которой хранится весь контент страницы. Мы рассмотрели пример источника данных MySQL и увидели, как мы можем легко заполнить тестовую базу данных, используя простой текстовый файл.
- Мы рассмотрели, как мы можем использовать PHP для извлечения информации из базы данных и поиска в ней, чтобы найти вхождения поискового термина. Мы рассмотрели создание структуры данных, сортировку данных и преобразование их в легко потребляемый объект JSON.
- Затем мы рассмотрели, как обрабатывать этот объект в браузере и обновлять DOM виджета, чтобы отразить, был ли поиск успешным или нет. Мы рассмотрели некоторые соображения, необходимые для включения навигации результатов по клавиатуре, превратив его в меню.