Разработчики постоянно стремятся сделать свои приложения более продвинутыми, но действительно ли они используются всеми? Для большинства приложений ответ — нет. Чтобы охватить наибольшую аудиторию, давайте узнаем, как сделать наши приложения более доступными.
В продолжение Международного дня инвалидов , давайте посмотрим, как мы можем сделать наши приложения для iOS более доступными.
В этом уроке мы будем использовать AVAudioEngine для расшифровки речи и отображения ее пользователю в виде текста (как это делает Siri на вашем iPhone).
В этом руководстве предполагается, что вы хорошо владеете Swift и знакомы с использованием Xcode для разработки под iOS.
Настройка проекта
Чтобы продолжить, вы можете создать новый проект в XCode или загрузить пример проекта для этого приложения.
Если вы работаете с новым проектом, добавьте следующую строку в начало файла ViewController.swift, чтобы Speech API был импортирован.
|
1
|
import Speech
|
Еще один шаг, который необходимо выполнить перед началом работы, — привести ViewController() соответствие с SFSpeechRecognizerDelegate .
Как только это будет сделано, вы готовы начать учебник.
1. Запрос разрешения
Поскольку Apple серьезно относится к конфиденциальности, имеет смысл требовать, чтобы разработчики запрашивали разрешение у пользователей перед использованием микрофонов устройства, особенно если данные отправляются на серверы Apple для анализа.
В случае распознавания речи требуется разрешение, поскольку данные передаются и временно хранятся на серверах Apple, чтобы повысить точность распознавания. — Документация Apple
В вашем проекте XCode вам нужно открыть файл Info.plist и добавить две пары ключ-значение. Вот ключи, которые вы можете вставить в:
-
NSMicrophoneUsageDescription -
NSSpeechRecognitionUsageDescription
В качестве значений вы можете ввести любую строку, которая точно описывает желаемые разрешения и зачем они вам нужны. Вот как это должно выглядеть после добавления:

Теперь нам нужно запросить разрешение у пользователя, прежде чем мы сможем продолжить. Для этого мы можем просто вызвать метод, удобно называемый requestAuthorization() .
Но прежде чем мы это сделаем, внутри вашего viewDidLoad() добавьте следующую строку кода:
|
1
|
microphoneButton.isEnabled = false
|
По умолчанию это отключает кнопку, поэтому пользователь не может нажать кнопку до того, как приложение сможет проверить его.
Далее вам нужно добавить следующий вызов метода:
|
1
2
3
4
5
|
SFSpeechRecognizer.requestAuthorization { (status) in
OperationQueue.main.addOperation {
// Your code goes here
}
}
|
Внутри обработчика завершения этого метода мы получаем статус авторизации и затем устанавливаем его в постоянное status называемое status . После этого у нас есть асинхронный вызов, который добавляет код внутри блока в основной поток (поскольку состояние кнопки должно быть изменено в основном потоке).
Внутри блока addOperation вам нужно добавить следующий оператор switch чтобы проверить, каков на самом деле статус авторизации:
|
1
2
3
4
5
6
7
8
9
|
switch status {
case .authorized: dictationButton.isEnabled = true
promptLabel.text = «Tap the button to begin dictation…»
default: dictationButton.isEnabled = false
promptLabel.text = «Dictation not authorized…»
}
|
Мы включаем возвращаемое значение функции authorizationStatus() . Если действие разрешено ( status .authorized ), кнопка диктовки включена, и нажмите кнопку, чтобы начать диктовку …. В противном случае кнопка диктовки отключается, а диктовка не авторизуется … отображается.
2. Разработка пользовательского интерфейса
Далее нам нужно спроектировать пользовательский интерфейс, чтобы можно было выполнять две вещи: запускать или останавливать диктовку и отображать интерпретированный текст. Для этого перейдите в файл Main.storyboard .
Вот три элемента конструктора интерфейса, которые вам понадобятся для продолжения этого урока:
-
UILabel -
UITextView -
UIButton
Поскольку размещение в этом приложении не имеет решающего значения, я не буду подробно рассказывать, где и как все разместить, поэтому просто следуйте этому основному каркасу при размещении элементов пользовательского интерфейса:
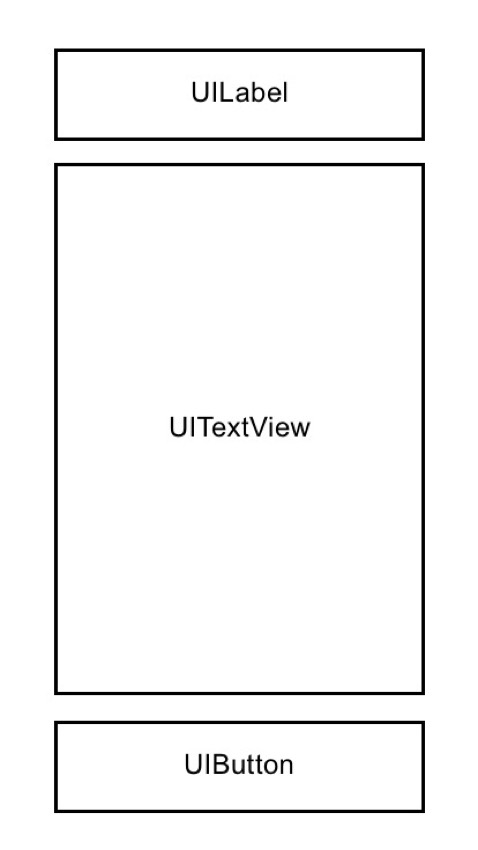
В качестве ориентира, вот как выглядит моя раскадровка на данный момент:
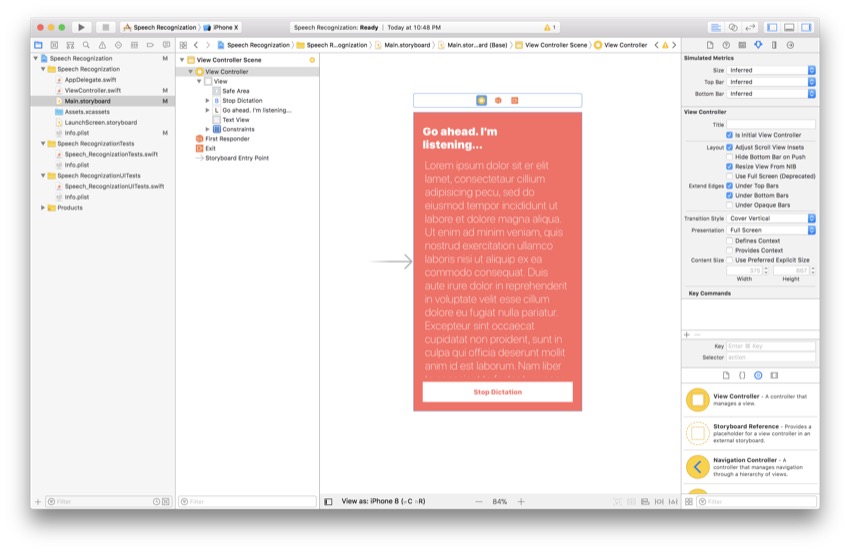
Опять же, все в порядке, если ваш макет выглядит иначе, но просто убедитесь, что у вас есть те же три основных элемента в каркасе. Теперь вставьте следующие строки кода в начало вашего ViewController() :
|
1
2
3
|
@IBOutlet var promptLabel: UILabel!
@IBOutlet var transcribedTextView: UITextView!
@IBOutlet var dictationButton: UIButton!
|
Внизу класса ViewController() просто добавьте следующую функцию, которая будет срабатывать при нажатии кнопки диктовки:
|
1
2
3
|
@IBAction func dictationButtonTapped() {
// Your code goes here
}
|
Последнее, что осталось сделать, — это открыть Помощник редактора и подключить соединения построителя интерфейса к файлу Main.storyboard . Точки, которые появляются рядом с ними, теперь должны выглядеть заполненными, и теперь вы сможете получить доступ ко всем этим элементам как к переменным и методам соответственно.
3. Добавление переменных
Теперь мы наконец готовы начать распознавание речи. Первым шагом является создание соответствующих переменных и констант, которые мы будем использовать на протяжении всего процесса. Под вашими строками интерфейса добавьте следующие строки кода:
|
1
2
3
4
5
|
let audioEngine = AVAudioEngine()
let speechRecognizer = SFSpeechRecognizer(locale: Locale(identifier: «en-US»))!
var request: SFSpeechAudioBufferRecognitionRequest?
var task: SFSpeechRecognitionTask?
|
Вот описание того, что делают переменные и константы:
-
audioEngineявляется экземпляром классаAVAudioEngine()Проще говоря, этот класс представляет собой серию аудио узлов. Аудио узлы используются для выполнения различных действий со звуком, таких как его генерация и обработка. -
speechRecognizerявляется экземпляром классаSFSpeechRecognizer()Этот класс не распознает ничего, кроме указанного языка, в данном случае американского английского. -
requestявляется необязательной переменной типаSFSpeechAudioBufferRecognitionRequest, и в настоящее время она инициализируется значениемnil. Позже в этом уроке мы на самом деле создадим один из них и установим его значение, когда нам нужно его использовать. Это будет использоваться для распознавания входных данных с микрофона устройства. -
task— еще одна необязательная переменная, на этот раз типаSFSpeechRecognition. Позже мы будем использовать эту переменную для отслеживания прогресса распознавания речи.
После того, как вы добавили переменные, у вас есть все необходимое, чтобы погрузиться прямо в процесс распознавания речи.
4. Объявление метода диктовки
Теперь мы сделаем основной метод для нашего алгоритма распознавания речи. Ниже viewDidLoad() объявите следующую функцию:
|
1
2
3
|
func startDictation() {
// Your code goes here
}
|
Поскольку мы не знаем текущий статус task , нам нужно отменить текущую задачу, а затем нам нужно установить ее обратно в nil (в случае, если это еще не сделано). Это можно сделать, добавив следующие две строки кода в ваш метод:
|
1
2
|
task?.cancel()
task = nil
|
Большой! Теперь мы знаем, что задача еще не запущена. Это важный шаг, когда вы используете переменные, объявленные вне области метода. Стоит отметить, что мы используем необязательную цепочку для вызова функции cancel() для task . Это краткий способ написать, что мы хотим вызывать метод cancel() если task не равна нулю.
5. Инициализация переменных
Теперь мы должны инициализировать переменные, которые мы создали ранее в этом уроке. Чтобы продолжить, добавьте эти строки кода в метод startDictation() из предыдущего шага:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
request = SFSpeechAudioBufferRecognitionRequest()
let audioSession = AVAudioSession.sharedInstance()
let inputNode = audioEngine.inputNode
guard let request = request else { return }
request.shouldReportPartialResults = true
try?
try?
try?
|
Давайте разберемся с этим. Помните переменную request мы создали ранее? Первая строка кода инициализирует эту переменную экземпляром класса SFSpeechAudioBufferRecognitionRequest .
Затем мы назначаем общий экземпляр audioSession константе под названием audioSession . Аудио сеанс ведет себя как посредник между приложением и самим устройством (и аудиокомпонентами).
После этого мы устанавливаем входной узел в одноэлементный inputNode именем inputNode . Чтобы начать запись, мы позже создадим tap этого узла.
Далее мы используем guard, чтобы развернуть переменную request которую мы инициализировали ранее. Это просто, чтобы избежать необходимости развернуть это позже в приложении. Тогда мы включим отображение неполных результатов. Это работает аналогично диктовке на iPhone — если вы когда-либо использовали диктовку, вы будете знать, что система печатает все, что думает, а затем, используя контекстные подсказки, корректирует вещи, если это необходимо.
Наконец, последние три строки кода пытаются установить различные атрибуты аудиосеанса. Эти операции могут выдавать ошибки, поэтому они должны быть помечены с помощью try? ключевое слово. Чтобы сэкономить время, мы просто будем игнорировать любые возникающие ошибки.
Теперь мы инициализировали большинство переменных, которые ранее были в нулевом состоянии. Последняя переменная для инициализации — это переменная task . Мы сделаем это на следующем шаге.
6. Инициализация переменной задачи
Для инициализации этой переменной потребуется обработчик завершения. Вставьте следующий код в startDictation() вашего startDictation() :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
task = speechRecognizer.recognitionTask(with: request, resultHandler: { (result, error) in
guard let result = result else { return }
self.transcribedTextView.text = result.bestTranscription.formattedString
if error != nil ||
self.audioEngine.stop()
self.request = nil
self.task = nil
inputNode.removeTap(onBus: 0)
}
})
|
Во-первых, мы создаем задачу recognitionTask с request в качестве параметра. Второй параметр — это замыкание, определяющее обработчик результата. Параметр result является экземпляром SFSpeechRecognitionResult . Внутри этого обработчика завершения нам нужно снова развернуть переменную результата.
Затем мы устанавливаем текст нашего текстового представления, чтобы быть лучшей транскрипцией, которую может предоставить алгоритм. Это не обязательно идеально, но алгоритм считает, что он лучше всего соответствует тому, что он слышал.
Наконец, в этом операторе if мы сначала проверяем, есть ли ошибка или результат получен окончательно. Если что-то из этого верно, звуковой движок и другие связанные процессы будут остановлены, и мы удалим tap . Не волнуйтесь, вы узнаете о кранах на следующем шаге!
7. Запуск аудио движка
Наконец-то момент, которого вы так долго ждали! Мы можем наконец запустить двигатель, который мы так долго создавали. Мы сделаем это, установив «кран». Добавьте следующий код под инициализацией вашей task :
|
1
2
3
4
|
let recordingFormat = inputNode.outputFormat(forBus: 0)
inputNode.installTap(onBus: 0, bufferSize: 1024, format: recordingFormat) { (buffer, when) in
self.request?.append(buffer)
}
|
В этом коде мы устанавливаем выходной формат входного узла на константу с именем recordingFormat . Это используется на следующем шаге для установки звукового tap на входном узле для записи и мониторинга аудио. Внутри обработчика завершения мы добавляем buffer в формате PCM в конец запроса на распознавание. Чтобы запустить двигатель, просто добавьте следующие две строки кода:
|
1
2
|
audioEngine.prepare()
try?
|
Это просто готовит и затем пытается запустить Audio Engine. Теперь нам нужно вызвать этот метод из нашей кнопки, поэтому давайте сделаем это на следующем шаге.
8. Отключение и включение кнопки
Мы не хотим, чтобы пользователь мог активировать распознавание речи, если он не доступен для использования — в противном случае приложение может аварийно завершить работу. Мы можем сделать это с помощью метода делегата, поэтому добавьте следующие несколько строк кода ниже startDictation() метода startDictation() :
|
1
2
3
4
5
6
7
|
func speechRecognizer(_ speechRecognizer: SFSpeechRecognizer, availabilityDidChange available: Bool) {
if available {
dictationButton.isEnabled = true
} else {
dictationButton.isEnabled = false
}
}
|
Это будет вызвано, когда распознаватель речи станет доступным после того, как станет недоступным или недоступным после того, как станет доступным. Внутри него мы просто будем использовать оператор if, чтобы включить или отключить кнопку в зависимости от состояния доступности.
Когда кнопка отключена, пользователь ничего не увидит, но кнопка не будет реагировать на нажатия. Это своего рода защитная сетка, предотвращающая слишком быстрое нажатие кнопки пользователем.
9. Реагирование на нажатия кнопок
Последнее, что остается сделать, это ответить, когда пользователь нажимает кнопку. Здесь мы также можем изменить то, что говорит кнопка, и сообщить пользователю, что ему нужно сделать. Чтобы освежить вашу память, вот действие @IBAction мы сделали ранее:
|
1
2
3
|
@IBAction func dictationButtonTapped() {
// Your code goes here
}
|
Внутри этой функции добавьте следующий оператор if:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
if audioEngine.isRunning {
dictationButton.setTitle(«Start Recording», for: .normal)
promptLabel.text = «Tap the button to dictate…»
request?.endAudio()
audioEngine.stop()
} else {
dictationButton.setTitle(«Stop Recording», for: .normal)
promptLabel.text = «Go ahead. I’m listening…»
startDictation()
}
|
Если аудио движок уже запущен, мы хотим остановить распознавание речи и отобразить соответствующее приглашение для пользователя. Если он не запущен, нам нужно запустить параметры распознавания и отображения, чтобы пользователь мог остановить диктовку.
Вывод
Это оно! Вы создали приложение, которое может распознавать ваш голос и транскрибировать его. Это может быть использовано для различных приложений, чтобы помочь пользователям, которые не могут взаимодействовать с вашими приложениями другими способами. Если вам понравился этот урок, обязательно ознакомьтесь с другими в этой серии!
И пока вы здесь, посмотрите другие наши посты о разработке приложений для Swift и iOS!
-
 XcodeЧто нового в Xcode 9?
XcodeЧто нового в Xcode 9? -
БезопасностьБезопасное кодирование в Swift 4
-
iOS SDKПередача данных между контроллерами в Swift