В этом посте я хочу описать, как использовать JSoup в Android. JSoup — это библиотека Java, которая помогает нам извлекать HTML-файлы и манипулировать ими. Есть некоторые ситуации, когда мы хотим проанализировать и извлечь некоторую информацию из HTML-страницы, а не отображать ее. В этом случае мы можем использовать JSoup, который имеет набор мощных API, очень простых в использовании и интегрируемых в наши проекты Android. В этом посте мы обсудим, как настроить и Android-проект, который использует JSoup и как извлечь некоторую информацию.
JSoup введение
Как уже говорилось, JSoup — это библиотека Java, предоставляющая набор API для извлечения и управления файлами HTML. Существует несколько способов чтения и анализа HTML-страницы; в нашем случае мы хотим получить его с удаленного сервера, а затем мы должны предоставить URL. Если мы хотим проанализировать страницу как DOM, мы имеем:
|
1
|
Document doc = Jsoup.connect(URL).get(); |
где doc — это экземпляр класса Document, который содержит полученный документ. Теперь у нас есть наш документ, и мы можем свободно извлекать информацию. Мы можем получить заголовок или другую информацию, используя теги HTML.
Например, если мы хотим получить весь тег с именем meta , мы имеем:
|
1
|
Elements metaElems = doc.select("meta"); |
где select это метод, который нужно использовать, когда мы хотим получить теги с помощью CSS-запроса. Например, если мы хотим получить значение атрибута из имеющегося у нас тега:
|
1
|
String name = metaElem.attr("name"); |
где name это имя атрибута. Кроме того, мы можем выбрать все элементы на странице HTML, которые имеют определенное значение класса CSS. Например, на этом сайте есть некоторые элементы, которые имеют класс CSS, равный теме , поэтому мы имеем:
|
1
|
Elements topicList = doc.select("h2.topic"); |
где мы выбираем только тег h2, имеющий класс с именем topic.
Если вы хотите получить больше информации, перейдите по этой ссылке .
Настройте проект и интегрируйте JSoup
Первое, что нам нужно сделать, это создать стандартный проект Android, который содержит простое действие. Я предполагаю, что вы используете Android Studio для этого. Как только ваш проект будет готов, мы должны добавить зависимость JSoup. Итак, откройте файл build.gradle и в разделе зависимостей добавьте:
|
1
|
compile 'org.jsoup:jsoup:1.7.3' |
итак имеем:
|
1
2
3
4
5
|
dependencies { compile fileTree(dir: 'libs', include: ['*.jar']) compile 'com.android.support:appcompat-v7:19.+' compile 'org.jsoup:jsoup:1.7.3'} |
Теперь мы готовы использовать JSoup API.
Создание приложения
Как только мы узнаем некоторую основную информацию о JSoup API, мы можем начать кодировать наше приложение. В конце мы получим:
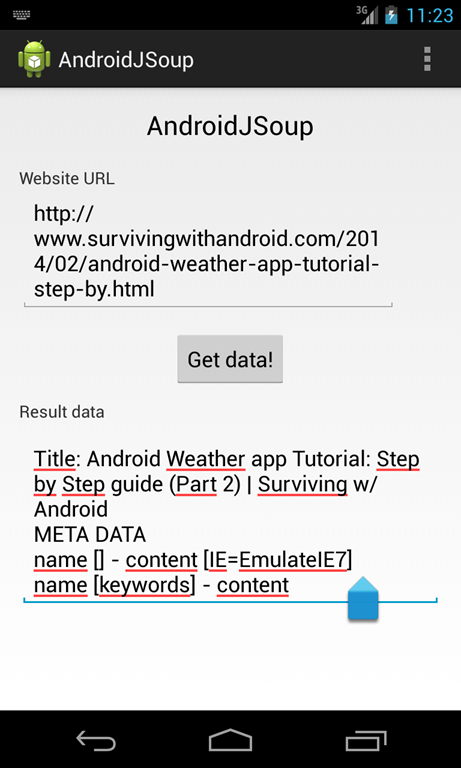
Первое, что нужно иметь в виду, это то, что мы вызываем удаленный веб-сайт, поэтому мы не можем использовать наш API JSoup в главном потоке, иначе у нас могут возникнуть проблемы с ANR, поэтому в этом примере мы будем использовать AsyncTask .
Как видите, макет очень прост: у нас есть EditText для вставки URL, кнопка для запуска HTML-анализа и другой EditText для отображения результатов. В основном виде деятельности мы имеем:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
@Overrideprotected void onCreate(Bundle savedInstanceState) { ... final EditText edtUrl = (EditText) findViewById(R.id.edtURL); Button btnGo = (Button) findViewById(R.id.btnGo); respText = (EditText) findViewById(R.id.edtResp); btnGo.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View view) { String siteUrl = edtUrl.getText().toString(); ( new ParseURL() ).execute(new String[]{siteUrl}); } });} |
где ParseURL — класс, отвечающий за анализ файла HTML с помощью JSoup. Теперь в этом классе мы имеем:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
private class ParseURL extends AsyncTask<String, Void, String> { @Override protected String doInBackground(String... strings) { StringBuffer buffer = new StringBuffer(); try { Log.d("JSwa", "Connecting to ["+strings[0]+"]"); Document doc = Jsoup.connect(strings[0]).get(); Log.d("JSwa", "Connected to ["+strings[0]+"]"); // Get document (HTML page) title String title = doc.title(); Log.d("JSwA", "Title ["+title+"]"); buffer.append("Title: " + title + "\r\n"); // Get meta info Elements metaElems = doc.select("meta"); buffer.append("META DATA\r\n"); for (Element metaElem : metaElems) { String name = metaElem.attr("name"); String content = metaElem.attr("content"); buffer.append("name ["+name+"] - content ["+content+"] \r\n"); } Elements topicList = doc.select("h2.topic"); buffer.append("Topic list\r\n"); for (Element topic : topicList) { String data = topic.text(); buffer.append("Data ["+data+"] \r\n"); } } catch(Throwable t) { t.printStackTrace(); } return buffer.toString(); } ... @Override protected void onPostExecute(String s) { super.onPostExecute(s); respText.setText(s); } |
Анализируя этот класс в строке 8, мы подключаемся к удаленному URL и получаем DOM-представление HTML-страницы. Затем в строке 11 мы получаем заголовок страницы. Используя информацию о JSoup, представленную выше, мы начинаем выбирать метатеги, используя метод select (строка 16). Мы знаем, что есть несколько метатегов, поэтому мы перебираем их и получаем имя и атрибут содержимого (строка 19-20). В последней части мы выбираем все теги HTML, имеющие класс, равный теме, и перебираем его, извлекая текстовое содержимое.
JSoup and Volley
В приведенном выше примере мы использовали AsyncTask для выполнения работы в фоновом режиме, но если вы предпочитаете, вы можете использовать и залп. В этом случае мы проанализируем документ не используя URL, а строку, содержащую полученный документ:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
StringRequest req = new StringRequest(Request.Method.GET, url, new Response.Listener<String>() { @Override public void onResponse(String data) { Document doc = Jsoup.parse(data); .... } }, new Response.ErrorListener() { @Override public void onErrorResponse(VolleyError volleyError) { // Handle error } } ); |
| Ссылка: | Разбор HTML в Android с Jsoup от нашего партнера JCG Франческо Аццолы в блоге Surviving w / Android . |