Android Things позволяет создавать удивительные устройства IoT с простым кодом, но одна из вещей, которые могут сделать устройство необычным, — это машинное обучение. Хотя в Интернете есть несколько служб, которые позволяют загружать данные и возвращать результаты, возможность использовать машинное обучение локально и в автономном режиме может быть невероятно полезной.
В этой статье я поделюсь некоторыми своими впечатлениями от использования классификатора изображений TensorFlow, начиная с примера Google ThingsorFlow для Android .
Зачем использовать машинное обучение?
Машинное обучение может помочь решить проблемы, которые обычные приложения не могут. Чтобы представить контекст, давайте рассмотрим простой пример, где машинное обучение может использоваться с устройством IoT для улучшения повседневной жизни.
Здесь, в Колорадо, нередко можно увидеть новостные статьи о дикой природе, выходящей из гор и бродящей по центру города:

Или медведи лазают по деревьям в местном университете:

У меня даже был друг, опубликовавший видео медведя за пределами их дома!

Несмотря на то, что об этих ситуациях обычно заботятся без проблем, имеются открытые данные Отдела парков и дикой природы штата Колорадо, в которых подробно описываются конфликты между черным медведем и человеком , а также различные виды / виды деятельности диких животных . Просматривая данные о конфликтах между черным медведем и человеком в Google Планета Земля, мы можем найти области, где встречи с медведями могут представлять опасность для общественной безопасности.
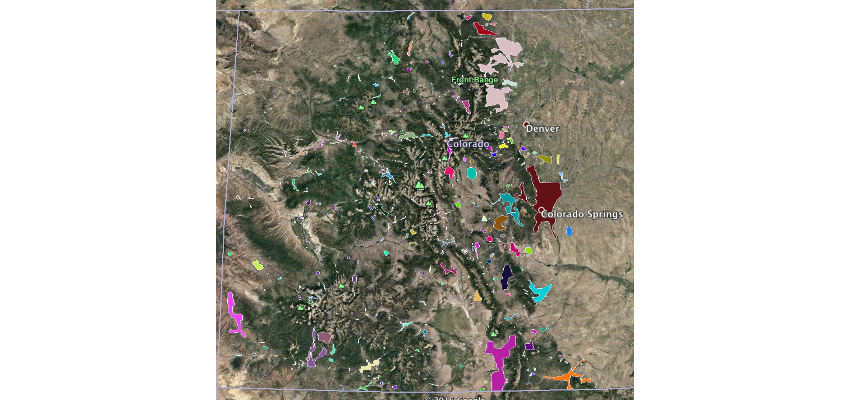
Кроме того, в то время как я читал данные о дикой природе в штате, моя подруга опубликовала изображение ее машины после аварии с участием лося во время ее поездки в Дуранго, штат Колорадо. Книга , чуть более 4000 несчастных случаев с участием дикой природы произошли за один год в Колорадо, с около 150 травм и один смертельный исход. По данным информационного бюллетеня « Защитники дикой природы», во всех Соединенных Штатах это число возрастает с 725 000 до 1 500 000 несчастных случаев с около 200 человеческими жертвами в год.

Итак, как мы можем использовать машинное обучение, чтобы помочь решить эту проблему? Благодаря распознаванию изображений мы можем создать устройство, запускаемое движением, которое может делать снимки с помощью Raspberry Pi, а затем анализировать их для обнаружения потенциально опасного дикого животного.
Используя образец Google, мы можем создать устройство Android Things, которое будет снимать фотографии с помощью Raspberry Pi и классифицировать содержимое этих изображений по более чем тысяче возможных ярлыков. Но эти ярлыки не совсем соответствуют тому, что нам нужно использовать.
Обучив TensorFlow использовать собственные изображения и метки, мы можем создать устройство, которое может идентифицировать лося, лося или черного медведя, а затем выполнить действие, если оно будет обнаружено. Это позволяет нам создавать устройства, которые потенциально могут спасти жизни, но при этом просты в создании.
Создание пользовательского классификатора изображений TensorFlow
После того, как вы установили и запустите пример Google TensorFlow для Android Things, пришло время начать его модифицировать. Первое, что вы хотите сделать, это убедиться, что TensorFlow на вашем компьютере и работает. Это может быть довольно сложным, и самый простой способ заставить его работать должным образом на протяжении всего процесса генерации обученных файлов — это установить и использовать Docker . Эта программа позволит вам запускать на вашем компьютере виртуальные машины, предварительно настроенные для TensorFlow.
После того, как вы установили Docker и запустили его на своем компьютере, вы должны открыть его настройки и установить использование памяти для ваших виртуальных машин. Я установил для себя использование 7 ГБ памяти, что может быть больше, чем нужно, но я потратил несколько дней, пытаясь заставить TensorFlow правильно создавать необходимые обученные графики без сбоев, прежде чем я понял, что виртуальной машине не хватает памяти.
В этом примере мы будем переучивать существующий пример машинного обучения для использования наших собственных данных, поскольку это намного быстрее, чем обучение нового набора данных с нуля. Для более подробного объяснения того, что мы делаем, вы можете взглянуть на официальную документацию TensorFlow .
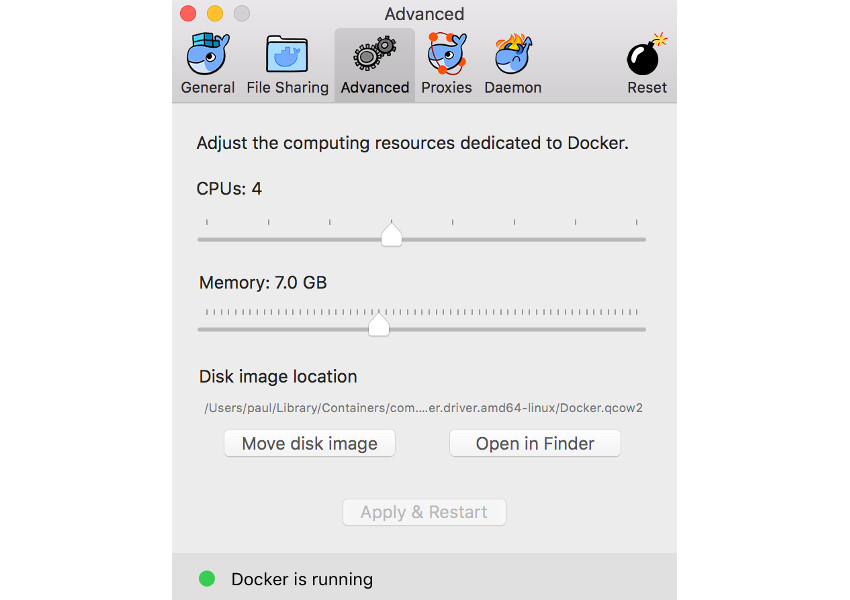
После того, как вы установили Docker и запустили его на своем компьютере, вам нужно будет запустить его из терминала и снять образ. В этом примере я работаю под macOS, поэтому команды могут немного отличаться для вашей платформы.
|
1
2
3
4
|
docker run -it -v $HOME/tf_files:/tf_files gcr.io/tensorflow/tensorflow:latest-devel
cd /tensorflow
git pull
git checkout v1.0.1
|
Когда все завершится, у вас в терминале должна появиться подсказка, подобная этой:
|
1
|
root@1643721c503b:/tensorflow#
|
На этом этапе вам понадобится набор изображений для обучения TensorFlow. Я использовал плагин Fatkun Batch Download Image Chrome для загрузки возвращенных изображений из массива поиска Google. Когда у вас установлен плагин, вы можете искать то, что хотите классифицировать, и начинать выбирать изображения, которые вы хотите сохранить.

Чтобы сделать именование немного проще, вы также можете перейти в раздел « Дополнительные параметры » и позволить плагину переименовывать изображения при их загрузке.

Затем вам нужно будет переместить изображения, которые вы используете, в папку в tf_files в вашей домашней директории, которая является папкой, которую мы создали при инициализации нашего докера. В этом примере мой каталог изображений называется TensorFlowTrainingImages . Каждый классифицируемый элемент должен иметь свою собственную папку в этом каталоге, как показано ниже.
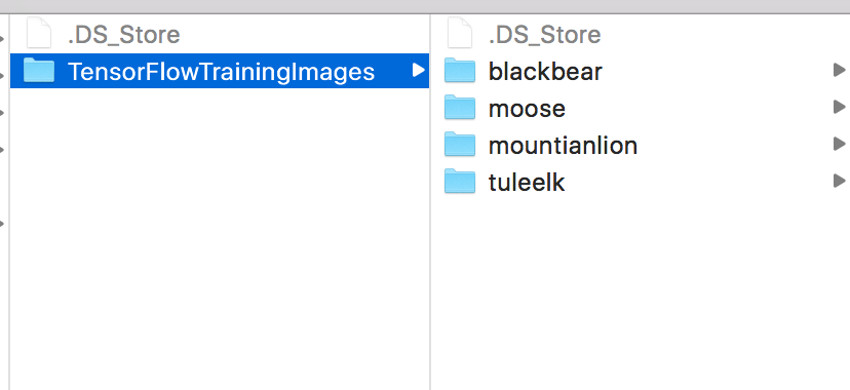
Как только ваши каталоги настроены, вы можете начать переподготовку с помощью следующей команды из терминала Docker:
|
1
2
3
4
5
6
7
|
python tensorflow/examples/image_retraining/retrain.py \
—bottleneck_dir=/tf_files/bottlenecks \
—how_many_training_steps 3000 \
—model_dir=/tf_files/inception \
—output_graph=/tf_files/graph.pb \
—output_labels=/tf_files/labels.txt \
—image_dir /tf_files/TensorFlowTrainingImages
|
Приведенная выше команда создаст узкие места , которые по сути являются данными, используемыми при окончательном прохождении данных классификации, и файлом графиков и меток, которые используются для классификации.
С этого момента операции, которые мы запускаем с TensorFlow, могут занять от нескольких минут до часа, в зависимости от скорости вашего компьютера. Это может быть хорошее время, чтобы сделать кофе или пойти на небольшую прогулку.
При выполнении команды переподготовки вы должны увидеть много выводов в вашем терминале, аналогично следующему:
|
1
2
3
|
2017-04-12 18:21:28.495685: Step 130: Train accuracy = 95.0%
2017-04-12 18:21:28.495779: Step 130: Cross entropy = 0.250339
2017-04-12 18:21:28.748928: Step 130: Validation accuracy = 92.0% (N=100)
|
Как только ваши узкие места будут созданы, у вас будет файл graph.pb и файл label.txt , представляющий ваши данные. Хотя эти форматы отлично работают при выполнении классификации на вашем компьютере, они, как правило, не работают при размещении в приложении Android. Вам нужно будет оптимизировать их.
Начните с выполнения следующей команды. Примите все значения по умолчанию.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
./configure
Please specify the location of python.
Please specify optimization flags to use during compilation [Default is -march=native]:
Do you wish to use jemalloc as the malloc implementation?
jemalloc enabled on Linux
Do you wish to build TensorFlow with Google Cloud Platform support?
No Google Cloud Platform support will be enabled for TensorFlow
Do you wish to build TensorFlow with Hadoop File System support?
No Hadoop File System support will be enabled for TensorFlow
Do you wish to build TensorFlow with the XLA just-in-time compiler (experimental)?
No XLA support will be enabled for TensorFlow
Found possible Python library paths:
/usr/local/lib/python2.7/dist-packages
/usr/lib/python2.7/dist-packages
Please input the desired Python library path to use.
Using python library path: /usr/local/lib/python2.7/dist-packages
Do you wish to build TensorFlow with OpenCL support?
No OpenCL support will be enabled for TensorFlow
Do you wish to build TensorFlow with CUDA support?
No CUDA support will be enabled for TensorFlow
Configuration finished
Extracting Bazel installation…
…………..
INFO: Starting clean (this may take a while).
…………
INFO: All external dependencies fetched successfully.
|
После завершения настройки выполните следующую команду, чтобы настроить инструмент оптимизации. Этот шаг занял около часа на моей машине, поэтому терпение является ключевым!
|
1
|
bazel build tensorflow/python/tools:optimize_for_inference
|
Как только ваш инструмент оптимизации создан, вы можете использовать его для оптимизации вашего графического файла.
|
1
2
3
4
5
|
bazel-bin/tensorflow/python/tools/optimize_for_inference \
—input=/tf_files/graph.pb \
—output=/tf_files/optimized_graph.pb \
—input_names=Mul \
—output_names=final_result
|
Теперь, когда ваш оптимизированный график создан, вы можете найти его с метками в папке tf_files в вашем домашнем каталоге.

Добавление вашего пользовательского классификатора в пример вещей Android
Поздравляем! Генерация графика и меток TensorFlow — сложная задача, и для ее правильной генерации может потребоваться некоторое время. Теперь, когда они у вас есть, пришло время отредактировать пример проекта Android Things, чтобы использовать ваши собственные данные. Сначала перейдите в файл build.gradle приложения и удалите следующий раздел, а также объявление его плагина:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
apply plugin: ‘de.undercouch.download’
// Download model zip file into ../../assets directory
// unzip it to demo project’s own ./assets directory
import de.undercouch.gradle.tasks.download.Download
task downloadFile(type: Download) {
src ‘https://storage.googleapis.com/download.tensorflow.org/models/inception5h.zip’
dest projectDir.toString() + ‘/../../assets/inception.zip’
}
task unzip(type: Copy) {
from zipTree(projectDir.toString() + ‘/../../assets/inception.zip’)
into file(projectDir.toString() + ‘/assets’)
}
unzip.dependsOn downloadFile
project.afterEvaluate {
if (!(new File(projectDir.toString() + ‘/assets’)).exists()) {
preBuild.dependsOn unzip
}
}
|
Приведенный выше код загружает образец графика и метки Google и добавляет их в каталог ресурсов . Так как мы сгенерировали свои собственные, нам не нужно беспокоиться об этом и мы можем удалить эти строки.
Затем откройте файл TensorFlowImageClassifier.java . Вы должны увидеть несколько объявленных переменных в верхней части файла с длинным комментарием о том, что нужно изменить, если вы используете свои собственные графики, сгенерированные из лаборатории кода (что достаточно близко к тому, что мы делали выше). ).
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
// These are the settings for the original v1 Inception model.
// use a model that’s been produced from the TensorFlow for Poets codelab,
// you’ll need to set IMAGE_SIZE = 299, IMAGE_MEAN = 128, IMAGE_STD = 128,
// INPUT_NAME = «Mul:0», and OUTPUT_NAME = «final_result:0».
// You’ll also need to update the MODEL_FILE and LABEL_FILE paths to point to
// the ones you produced.
public static final int INPUT_SIZE = 224;
// Note: the actual number of classes for Inception is 1001, but the output layer size is 1008.
private static final int NUM_CLASSES = 1008;
private static final int IMAGE_MEAN = 117;
private static final float IMAGE_STD = 1;
private static final String INPUT_NAME = «input:0»;
private static final String OUTPUT_NAME = «output:0»;
private static final String MODEL_FILE = «file:///android_asset/tensorflow_inception_graph.pb»;
private static final String LABEL_FILE =
«file:///android_asset/imagenet_comp_graph_label_strings.txt»;
|
Измените последнюю часть MODEL_FILE и LABEL_FILE чтобы соответствовать названию вашего оптимизированного графика и метки.
|
1
2
3
|
private static final String MODEL_FILE = «file:///android_asset/optimized_graph.pb»;
private static final String LABEL_FILE =
«file:///android_asset/labels.txt»;
|
Возвращаясь к длинному комментарию в оригинальном источнике, давайте продолжим и отредактируем файл в соответствии с рекомендациями Google.
|
1
2
3
4
5
6
|
public static final int NUM_CLASSES = 4;
public static final int INPUT_SIZE = 299;
public static final int IMAGE_MEAN = 128;
public static final float IMAGE_STD = 128;
public static final String INPUT_NAME = «Mul»;
public static final String OUTPUT_NAME = «final_result»;
|
Вы заметите, что мы устанавливаем NUM_CLASSES в 4 . Это количество предметов, доступных для нашего алгоритма машинного обучения для классификации. Вы можете изменить это, чтобы соответствовать количеству классификационных категорий, с которыми вы тренировались.
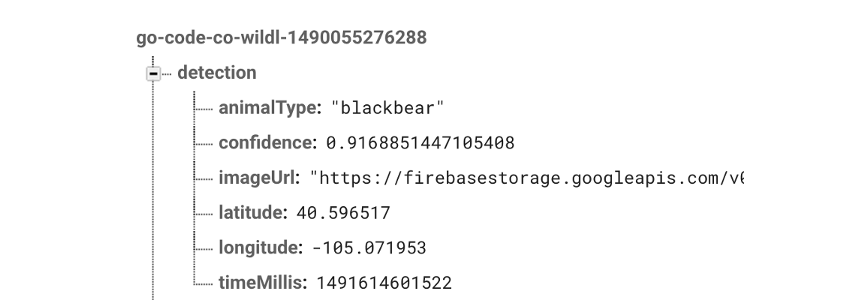
Чтобы закончить, переместите файл оптимизированного графика и метки в каталог app / src / main / assets . Как только это будет сделано, вы можете установить образец приложения на Raspberry Pi с модулем камеры и сделать снимок. Ниже фотография, которую я сделал с устройством:

И результаты, которые были отправлены в Firebase (с небольшими изменениями в примере приложения).
Вывод
В этом уроке вы получили краткое введение в использование TensorFlow для машинного обучения и его интеграцию в приложение Android Things. Как вы уже видели, машинное обучение — это мощный инструмент, который можно использовать для решения различных проблем, с которыми может столкнуться обычное приложение. Комбинируя машинное обучение с Интернетом вещей, вы можете создавать удивительные и полезные устройства, которые взаимодействуют с окружающим миром.
Используя то, что вы узнали из этой статьи и других статей из серии Android Things , вы можете создавать действительно потрясающие новые приложения и устройства!
-
 AndroidВведение в Android вещи
AndroidВведение в Android вещи -
Android SDKКак звонить и использовать SMS в приложениях для Android
-
Android SDKПриложения RxJava 2 для Android: RxBinding и RxLifecycle
-
Ионная 2Введение в Ionic 2



