Я недавно опубликовал , как настроить кластер EMR с помощью CLI. В этом посте я покажу, как настроить кластер с помощью Java SDK для AWS . На мой взгляд, лучший способ показать, как это сделать с помощью Java AWS SDK, — показать полный пример, поэтому давайте начнем.
- Создать новый проект Maven
Для этой задачи я создал новый проект Maven по умолчанию. Основным классом в этом проекте является тот, который вы можете запустить для запуска кластера EMR и выполнения задания MapReduce, которое я создал в этом посте :
|
001
002
003
004
005
006
007
008
009
010
011
012
013
014
015
016
017
018
019
020
021
022
023
024
025
026
027
028
029
030
031
032
033
034
035
036
037
038
039
040
041
042
043
044
045
046
047
048
049
050
051
052
053
054
055
056
057
058
059
060
061
062
063
064
065
066
067
068
069
070
071
072
073
074
075
076
077
078
079
080
081
082
083
084
085
086
087
088
089
090
091
092
093
094
095
096
097
098
099
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
|
package net.pascalalma.aws.emr;import com.amazonaws.AmazonServiceException;import com.amazonaws.auth.AWSCredentials;import com.amazonaws.auth.PropertiesCredentials;import com.amazonaws.regions.Region;import com.amazonaws.regions.Regions;import com.amazonaws.services.ec2.model.InstanceType;import com.amazonaws.services.elasticmapreduce.AmazonElasticMapReduceClient;import com.amazonaws.services.elasticmapreduce.model.*;import com.amazonaws.services.elasticmapreduce.util.StepFactory;import com.amazonaws.services.s3.AmazonS3;import com.amazonaws.services.s3.AmazonS3Client;import java.util.Arrays;import java.util.Date;import java.util.List;import java.util.UUID;/** * Created with IntelliJ IDEA. * User: pascal * Date: 22-07-13 * Time: 20:45 */public class MyClient { private static final String HADOOP_VERSION = "1.0.3"; private static final int INSTANCE_COUNT = 1; private static final String INSTANCE_TYPE = InstanceType.M1Small.toString(); private static final UUID RANDOM_UUID = UUID.randomUUID(); private static final String FLOW_NAME = "dictionary-" + RANDOM_UUID.toString(); private static final String BUCKET_NAME = "map-reduce-intro"; private static final String S3N_HADOOP_JAR = "s3n://" + BUCKET_NAME + "/job/MapReduce-1.0-SNAPSHOT.jar"; private static final String S3N_LOG_URI = "s3n://" + BUCKET_NAME + "/log/"; private static final String[] JOB_ARGS = new String[]{"s3n://" + BUCKET_NAME + "/input/input.txt", "s3n://" + BUCKET_NAME + "/result/" + FLOW_NAME}; private static final List<String> ARGS_AS_LIST = Arrays.asList(JOB_ARGS); private static final List<JobFlowExecutionState> DONE_STATES = Arrays .asList(new JobFlowExecutionState[]{JobFlowExecutionState.COMPLETED, JobFlowExecutionState.FAILED, JobFlowExecutionState.TERMINATED}); static AmazonS3 s3; static AmazonElasticMapReduceClient emr; private static void init() throws Exception { AWSCredentials credentials = new PropertiesCredentials( MyClient.class.getClassLoader().getResourceAsStream("AwsCredentials.properties")); s3 = new AmazonS3Client(credentials); emr = new AmazonElasticMapReduceClient(credentials); emr.setRegion(Region.getRegion(Regions.EU_WEST_1)); } private static JobFlowInstancesConfig configInstance() throws Exception { // Configure instances to use JobFlowInstancesConfig instance = new JobFlowInstancesConfig(); instance.setHadoopVersion(HADOOP_VERSION); instance.setInstanceCount(INSTANCE_COUNT); instance.setMasterInstanceType(INSTANCE_TYPE); instance.setSlaveInstanceType(INSTANCE_TYPE); // instance.setKeepJobFlowAliveWhenNoSteps(true); // instance.setEc2KeyName("4synergy_palma"); return instance; } private static void runCluster() throws Exception { // Configure the job flow RunJobFlowRequest request = new RunJobFlowRequest(FLOW_NAME, configInstance()); request.setLogUri(S3N_LOG_URI); // Configure the Hadoop jar to use HadoopJarStepConfig jarConfig = new HadoopJarStepConfig(S3N_HADOOP_JAR); jarConfig.setArgs(ARGS_AS_LIST); try { StepConfig enableDebugging = new StepConfig() .withName("Enable debugging") .withActionOnFailure("TERMINATE_JOB_FLOW") .withHadoopJarStep(new StepFactory().newEnableDebuggingStep()); StepConfig runJar = new StepConfig(S3N_HADOOP_JAR.substring(S3N_HADOOP_JAR.indexOf('/') + 1), jarConfig); request.setSteps(Arrays.asList(new StepConfig[]{enableDebugging, runJar})); //Run the job flow RunJobFlowResult result = emr.runJobFlow(request); //Check the status of the running job String lastState = ""; STATUS_LOOP: while (true) { DescribeJobFlowsRequest desc = new DescribeJobFlowsRequest( Arrays.asList(new String[]{result.getJobFlowId()})); DescribeJobFlowsResult descResult = emr.describeJobFlows(desc); for (JobFlowDetail detail : descResult.getJobFlows()) { String state = detail.getExecutionStatusDetail().getState(); if (isDone(state)) { System.out.println("Job " + state + ": " + detail.toString()); break STATUS_LOOP; } else if (!lastState.equals(state)) { lastState = state; System.out.println("Job " + state + " at " + new Date().toString()); } } Thread.sleep(10000); } } catch (AmazonServiceException ase) { System.out.println("Caught Exception: " + ase.getMessage()); System.out.println("Reponse Status Code: " + ase.getStatusCode()); System.out.println("Error Code: " + ase.getErrorCode()); System.out.println("Request ID: " + ase.getRequestId()); } } public static boolean isDone(String value) { JobFlowExecutionState state = JobFlowExecutionState.fromValue(value); return DONE_STATES.contains(state); } public static void main(String[] args) { try { init(); runCluster(); } catch (Exception e) { e.printStackTrace(); } }} |
В этом классе я сначала объявляю некоторые константы, я предполагаю, что они будут очевидны. В методе init () я использую файл свойств учетных данных, который я добавил в проект. Я добавил этот файл в папку «/ main / resources» моего проекта Maven. Он содержит мой ключ доступа и секретный ключ.
Также для региона EMR я установил регион EU-WEST.
Следующий метод — configInstance (). В этом методе я создаю и настраиваю JobFlowInstance, устанавливая версию Hadoop, количество экземпляров, размер экземпляров и т. Д. Также вы можете настроить параметр keepAlive, чтобы кластер оставался живым после завершения заданий. Это может быть полезно в некоторых случаях. Если вы хотите использовать эту опцию, может быть полезно также задать пару ключей, которую вы хотите использовать для доступа к кластеру, потому что я не смог получить доступ к кластеру без установки этого ключа.
Метод runCluster () — это то место, где кластер фактически запущен. Создает запрос на запуск кластера. В этом запросе добавляются шаги, которые должны быть выполнены. В нашем случае одним из шагов является запуск файла JAR, который мы создали на предыдущих шагах. Я также добавил шаг отладки, чтобы у нас был доступ к журналу отладки после завершения и завершения кластера. Мы можем просто получить доступ к файлам журнала в корзине S3, которую я установил с помощью константы ‘S3N_LOG_URI’.
Когда этот запрос создан, мы запускаем кластер на основе этого запроса. Затем мы проводим каждые 10 секунд, чтобы увидеть, завершилось ли задание, и показываем на консоли сообщение с указанием текущего состояния задания.
Чтобы выполнить первый запуск, мы должны подготовить ввод.
- Подготовьте вход
В качестве входных данных для задания (см. Это для получения дополнительной информации об этом примере задания) мы должны сделать содержимое словаря доступным для кластера EMR. Кроме того, мы должны сделать JAR-файл доступным и убедиться, что каталог вывода и журнала существует в наших сегментах S3. Есть несколько способов сделать это: вы можете сделать это также программно, используя SDK, используя S3cmd для этого из командной строки или используя Консоль управления AWS . Пока вы в конечном итоге с подобной настройкой, как это:
- s3: // Карта-свертка-интро
- s3: // Карта-свертка-интро / вход
- s3: //map-reduce-intro/input/input.txt
- s3: // Карта-свертка-интро / работа
- s3: //map-reduce-intro/job/MapReduce-1.0-SNAPSHOT.jar
- s3: // Карта-свертка-интро / журнал
- s3: // Карта-свертка-интро / результат
Или при использовании S3cmd это выглядит так:
|
1
2
3
4
5
|
s3cmd-1.5.0-alpha1$ s3cmd ls --recursive s3://map-reduce-intro/2013-07-20 13:06 469941 s3://map-reduce-intro/input/input.txt2013-07-20 14:12 5491 s3://map-reduce-intro/job/MapReduce-1.0-SNAPSHOT.jar2013-08-06 14:30 0 s3://map-reduce-intro/log/2013-08-06 14:27 0 s3://map-reduce-intro/result/ |
В приведенном выше примере я уже представил клиента S3 в коде. Вы также можете использовать это, чтобы подготовить ввод или получить вывод как часть работы клиента.
- Запустить кластер
Когда все на месте, мы можем запустить работу. Я просто запускаю основной метод MyClient в IntelliJ и получаю следующий вывод в моей консоли:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
|
Job STARTING at Tue Aug 06 16:31:55 CEST 2013Job RUNNING at Tue Aug 06 16:36:18 CEST 2013Job SHUTTING_DOWN at Tue Aug 06 16:38:40 CEST 2013Job COMPLETED: { JobFlowId: j-JDB14HVTRC1L ,Name: dictionary-8288df47-8aef-4ad3-badf-ee352a4a7c43 ,LogUri: s3n://map-reduce-intro/log/,AmiVersion: 2.4.0 ,ExecutionStatusDetail: {State: COMPLETED,CreationDateTime: Tue Aug 06 16:31:58 CEST 2013 ,StartDateTime: Tue Aug 06 16:36:14 CEST 2013 ,ReadyDateTime: Tue Aug 06 16:36:14 CEST 2013 ,EndDateTime: Tue Aug 06 16:39:02 CEST 2013 ,LastStateChangeReason: Steps completed} ,Instances: {MasterInstanceType: m1.small ,MasterPublicDnsName: ec2-54-216-104-11.eu-west-1.compute.amazonaws.com ,MasterInstanceId: i-93268ddf ,InstanceCount: 1 ,InstanceGroups: [{InstanceGroupId: ig-2LURHNAK5NVKZ ,Name: master ,Market: ON_DEMAND ,InstanceRole: MASTER ,InstanceType: m1.small ,InstanceRequestCount: 1 ,InstanceRunningCount: 0 ,State: ENDED ,LastStateChangeReason: Job flow terminated ,CreationDateTime: Tue Aug 06 16:31:58 CEST 2013 ,StartDateTime: Tue Aug 06 16:34:28 CEST 2013 ,ReadyDateTime: Tue Aug 06 16:36:10 CEST 2013 ,EndDateTime: Tue Aug 06 16:39:02 CEST 2013}] ,NormalizedInstanceHours: 1 ,Ec2KeyName: 4synergy_palma ,Placement: {AvailabilityZone: eu-west-1a} ,KeepJobFlowAliveWhenNoSteps: false ,TerminationProtected: false ,HadoopVersion: 1.0.3} ,Steps: [ {StepConfig: {Name: Enable debugging ,ActionOnFailure: TERMINATE_JOB_FLOW ,HadoopJarStep: {Properties: [] ,Jar: s3://us-east-1.elasticmapreduce/libs/script-runner/script-runner.jar ,Args: [s3://us-east-1.elasticmapreduce/libs/state-pusher/0.1/fetch]} } ,ExecutionStatusDetail: {State: COMPLETED,CreationDateTime: Tue Aug 06 16:31:58 CEST 2013 ,StartDateTime: Tue Aug 06 16:36:12 CEST 2013 ,EndDateTime: Tue Aug 06 16:36:40 CEST 2013 ,} } , {StepConfig: {Name: /map-reduce-intro/job/MapReduce-1.0-SNAPSHOT.jar ,ActionOnFailure: TERMINATE_JOB_FLOW ,HadoopJarStep: {Properties: [] ,Jar: s3n://map-reduce-intro/job/MapReduce-1.0-SNAPSHOT.jar ,Args: [s3n://map-reduce-intro/input/input.txt , s3n://map-reduce-intro/result/dictionary-8288df47-8aef-4ad3-badf-ee352a4a7c43]} } ,ExecutionStatusDetail: {State: COMPLETED ,CreationDateTime: Tue Aug 06 16:31:58 CEST 2013 ,StartDateTime: Tue Aug 06 16:36:40 CEST 2013 ,EndDateTime: Tue Aug 06 16:38:10 CEST 2013 ,} }] ,BootstrapActions: [] ,SupportedProducts: [] ,VisibleToAllUsers: false,}Process finished with exit code 0 |
И, конечно, у нас есть результат в папке ‘result’, которую мы настроили в нашей корзине S3:
![]()
Я переношу результат на свою локальную машину и посмотрю на него:
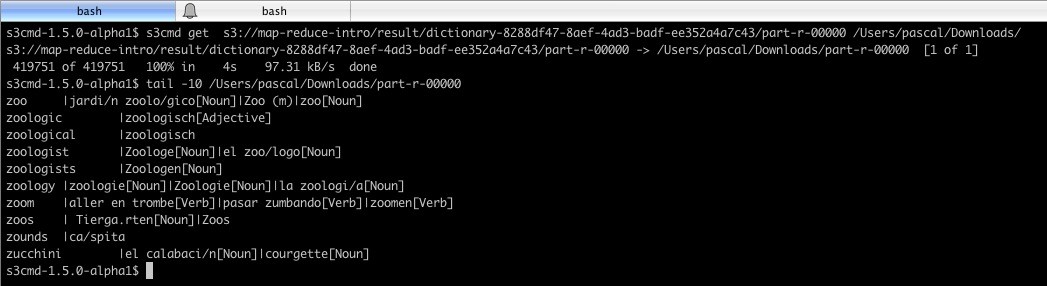
На этом мы завершаем этот простой, но я думаю, довольно полный пример создания задания Hadoop и запуска его в кластере после тестирования модуля, как мы делали бы со всем нашим программным обеспечением.
С этой настройкой в качестве основы довольно легко придумать более сложные бизнес-кейсы и протестировать их и настроить для работы на AWS EMR .