В этом выступлении я представлю трех разных клиентов для эластичного поиска, а также Spring Data Elasticsearch. Но для начала давайте рассмотрим некоторые из основ эластичного поиска.
elasticsearch
Чтобы представить эластичный поиск, я использую определение, которое взято непосредственно с сайта эластичного.
Elasticsearch — это распределенный поисковый и аналитический механизм на основе JSON, разработанный для горизонтальной масштабируемости, максимальной надежности и простого управления.
Давайте сначала посмотрим, что означает механизм поиска и анализа на основе JSON .
Чтобы понять, что делаетasticsearch, полезно посмотреть пример страницы поиска. Это то, с чем все знакомы, поиск кода на Github.
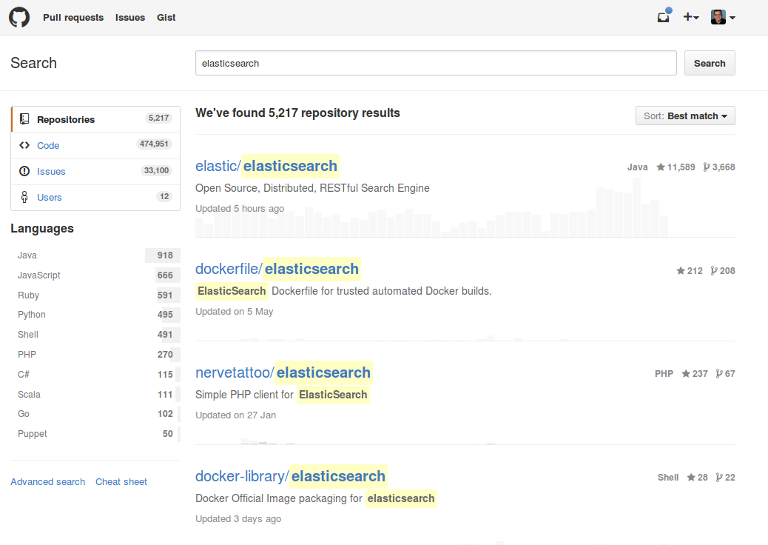
Ключевые слова могут быть введены в одном поисковом входе, ниже приведен список результатов. Одна из отличительных особенностей поисковой системы и других баз данных заключается в том, что существует понятие релевантности. Мы можем видеть, что для нашего поискового термина elasticsearch поиска проект для поисковой системы находится на первом месте. Очень вероятно, что люди ищут проект при поиске этого термина. Факторы, которые используются для определения того, является ли результат более релевантным, чем другой, могут варьироваться от приложения к приложению — я не знаю, что делает Github, но могу представить, что они используют такие факторы, как популярность, помимо классических функций релевантности текста. На веб-сайте есть намного больше функций, которые поддерживает классическая поисковая система, такая как elasitcsearch: выделение вхождения в результате, разбиение на страницы в списке и сортировка по различным критериям. Слева вы можете увидеть так называемые фасеты, которые можно использовать для дальнейшего уточнения списка результатов, используя критерии из найденных документов. Это похоже на функции, найденные на сайтах электронной коммерции, таких как Ebay и Amazon. Для того, чтобы сделать что-то подобное, в эластичном поиске есть функция агрегирования, которая также является основой его аналитических возможностей. Это и многое другое может быть сделано с использованием эластичного поиска. В этом случае это еще более очевидно — Github на самом деле использует эластичный поиск для поиска большого объема данных, которые они хранят.
Если вы хотите создать поисковое приложение, как это, вы должны сначала установить движок. К счастью, с Flexiblesearch действительно легко начать работу. Нет особых требований, кроме недавнего времени выполнения Java. Вы можете скачать архив эластичного поиска с веб-сайта эластичного пакета, распаковать его и запустить эластичный поиск с помощью сценария.
|
1
2
3
4
5
6
7
8
|
# download archivewget https://artifacts.elastic.co/downloads/ elasticsearch/elasticsearch-5.0.0.zipunzip elasticsearch-5.0.0.zip# on windows: elasticsearch.batelasticsearch-5.0.0/bin/elasticsearch |
Для производственного использования существуют также пакеты для разных дистрибутивов Linux. Вы можете увидеть, чтоasticsearch запускается при выполнении HTTP GET-запроса на стандартном порту. В примерах я использую curl, клиент командной строки для выполнения HTTP-запросов, который доступен для многих сред.
|
1
|
curl -XGET "http://localhost:9200" |
asticsearch ответит на этот запрос документом JSON, содержащим некоторую информацию об установке.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
{ "name" : "LI8ZN-t", "cluster_name" : "elasticsearch", "cluster_uuid" : "UvbMAoJ8TieUqugCGw7Xrw", "version" : { "number" : "5.0.0", "build_hash" : "253032b", "build_date" : "2016-10-26T04:37:51.531Z", "build_snapshot" : false, "lucene_version" : "6.2.0" }, "tagline" : "You Know, for Search"} |
Самым важным для нас является то, что мы видим, что сервер запущен. Но есть также информация о версиях наasticsearch и Lucene, базовой библиотеке, используемой для большинства функций поиска.
Если мы теперь хотим сохранить данные вasticsearch, мы отправим их также в виде документа JSON, на этот раз с помощью запроса POST. Поскольку мне действительно нравится еда в Сингапуре, я хочу создать приложение, которое позволит мне искать мою любимую еду. Давайте индексировать первое блюдо.
|
1
2
3
4
5
6
7
8
9
|
{ "food": "Hainanese Chicken Rice", "tags": ["chicken", "rice"], "favorite": { "location": "Tian Tian", "price": 5.00 }}' |
Мы используем тот же порт, который использовали ранее, на этот раз мы просто добавляем еще два фрагмента к URL: food и dish . Первый — это название индекса, логическая коллекция документов. Второй тип. Он определяет структуру документа, который мы сохраняем, так называемое отображение.
Само блюдо моделируется как документ. asticsearch поддерживает различные типы данных, такие как строка, которая используется для атрибута food , список, как в tags и даже встроенные документы, такие как favorite документ. Помимо этого есть более примитивные типы, такие как числовые, логические и специализированные типы, такие как географические координаты.
Теперь мы можем проиндексировать другой документ, выполнив другой запрос POST.
|
1
2
3
4
5
6
|
{ "food": "Ayam Penyet", "tags": ["chicken", "indonesian"], "spicy": true}' |
Структура этого документа немного отличается. Он не содержит favorite вложенного документа, но имеет другой атрибут spicy . Документы одного и того же типа могут быть очень разными, но имейте в виду, что вам нужно интерпретировать некоторые части вашего приложения. Обычно у вас будут похожие документы.
После индексации документов их можно автоматически найти. Один из вариантов — сделать запрос GET для /_search и добавить термин запроса в качестве параметра.
|
1
|
curl -XGET "http://localhost:9200/food/dish/_search?q=chicken" |
Поиск курицы в обоих документах также возвращает их обоих. Это выдержка из результата.
|
01
02
03
04
05
06
07
08
09
10
11
|
...{"total":2,"max_score":0.3666863,"hits":[{"_index":"food","_type":"dish","_id":"AVg9cMwARrBlrY9tYBqX","_score":0.3666863,"_source":{ "food": "Hainanese Chicken Rice", "tags": ["chicken", "rice"], "favorite": { "location": "Tian Tian", "price": 5.00 }}},... |
Существует некоторая глобальная информация, например количество найденных документов. Но самым важным свойством является массив совпадений, который содержит исходный источник наших проиндексированных блюд.
Очень легко начать, как это, но в большинстве случаев запросы будут более сложными. Вот почемуasticsearch предоставляет DSL запроса, структуру JSON, которая описывает запрос, а также любые другие функции поиска, которые запрашиваются.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
{ "query": { "bool": { "must": { "match": { "_all": "rice" } }, "filter": { "term": { "tags.keyword": "chicken" } } } }}' |
Мы ищем все документы, которые содержат термин « rice а также имеют tags chicken . Доступ к полю с помощью .keyword позволяет выполнять точный поиск и является новой функцией вasticsearch 5.0.
Помимо самого поиска, вы можете использовать DSL-запрос, чтобы запросить дополнительную информацию уasticsearch, будь то выделение или автозаполнение, или агрегаты, которые можно использовать для создания функции огранки.
Давайте перейдем к другой части определения.
Elasticsearch […] распространяется […], предназначен для горизонтальной масштабируемости, максимальной надежности
До сих пор мы обращались только к одному экземпляру эластичного поиска.
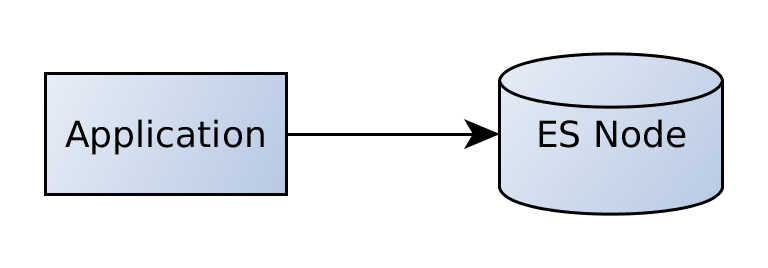
Наше приложение будет общаться непосредственно с этим узлом. Теперь, так какasticsearch разработан для горизонтальной масштабируемости, мы также можем добавить больше узлов.
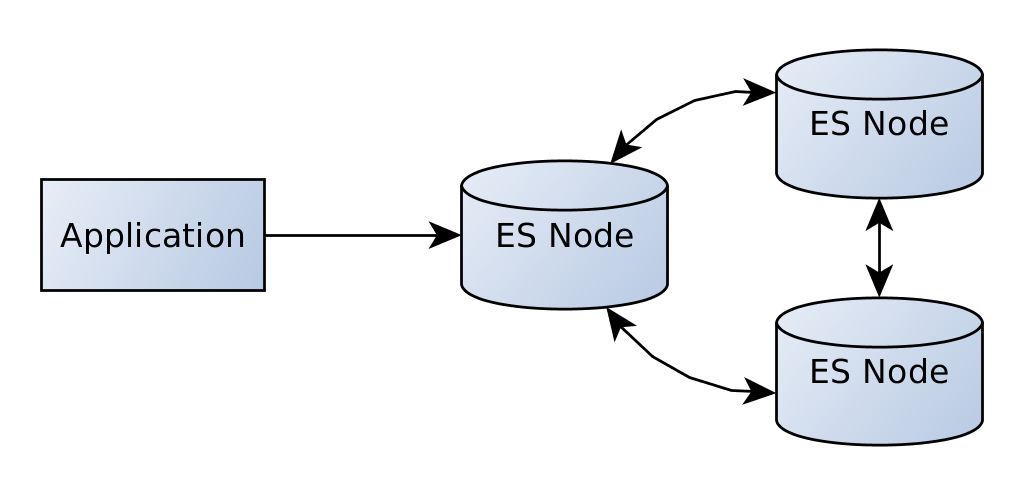
Узлы образуют кластер. Мы все еще можем общаться с первым узлом, и он будет распределять все запросы к нужным узлам кластера. Это совершенно прозрачно для нас.
Вначале создать кластер с помощью эластичного поиска действительно просто, но, конечно, может быть сложнее поддерживать производственный кластер.
Теперь, когда у нас есть общее представление о том, что делаетasticsearch, давайте посмотрим, как мы можем получить к нему доступ из приложения Java.
Транспортный клиент
Транспортный клиент был доступен с самого начала и является клиентом, выбранным наиболее часто. Начиная сasticsearch 5.0, он имеет собственный артефакт, который можно интегрировать в вашу сборку, например, используя Gradle.
|
1
2
3
4
5
|
dependencies { compile group: 'org.elasticsearch.client', name: 'transport', version: '5.0.0'} |
Все функциональные возможности Elasticsearch доступны через интерфейс Client , конкретный экземпляр — TransportClient , который может быть создан с помощью объекта Settings и может иметь один или несколько адресов узлов эластичного поиска.
|
1
2
3
4
5
6
|
TransportAddress address = new InetSocketTransportAddress( InetAddress.getByName("localhost"), 9300);Client client = new PreBuiltTransportClient(Settings.EMPTY) addTransportAddress(address); |
Затем client предоставляет методы для различных функций эластичного поиска. Во-первых, давайте искать снова. Напомним структуру запроса, который мы выпустили выше.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
{ "query": { "bool": { "must": { "match": { "_all": "rice" } }, "filter": { "term": { "tags.keyword": "chicken" } } } }}' |
Запрос bool который имеет запрос на match в своем разделе must и запрос term в своем разделе filter .
К счастью, когда у вас есть такой запрос, вы можете легко преобразовать его в эквивалент Java.
|
01
02
03
04
05
06
07
08
09
10
11
12
|
SearchResponse searchResponse = client .prepareSearch("food") .setQuery( boolQuery(). must(matchQuery("_all", "rice")). filter(termQuery("tags.keyword", "chicken"))) .execute().actionGet();assertEquals(1, searchResponse.getHits().getTotalHits());SearchHit hit = searchResponse.getHits().getAt(0);String food = hit.getSource().get("food").toString(); |
Мы запрашиваем SearchSourceBuilder , вызывая prepareSearch на client . Там мы можем задать запрос, используя статические вспомогательные методы. И снова, это запрос bool запросе которого есть запрос на match в разделе filter запрос запроса.
Вызов execute возвращает объект Future, actionGet является блокирующей частью вызова. SearchResponse представляет ту же структуру JSON, которую мы видим при выполнении поиска с использованием интерфейса HTTP. Источник блюда затем доступен в виде карты.
При индексации данных доступны разные опции. Одним из них является использование jsonBuilder для создания представления JSON.
|
1
2
3
4
5
6
7
8
9
|
XContentBuilder builder = jsonBuilder() .startObject() .field("food", "Roti Prata") .array("tags", new String [] {"curry"}) .startObject("favorite") .field("location", "Tiong Bahru") .field("price", 2.00) .endObject() .endObject(); |
Он предоставляет различные методы, которые можно использовать для создания структуры документа JSON. Это может затем использоваться в качестве источника для IndexRequest.
|
1
2
3
4
|
IndexResponse resp = client.prepareIndex("food","dish") .setSource(builder) .execute() .actionGet(); |
Помимо использования jsonBuilder есть несколько других доступных опций.
Распространенным вариантом является использование карты, удобных методов, которые принимают имя и значение поля для простых структур, или возможность передавать строку, часто в сочетании с библиотекой, такой как Джексон, для сериализации.
Выше мы видели, что Транспортный Клиент принимает адрес одного или нескольких узлов эластичного поиска. Вы могли заметить, что порт отличается от порта, используемого для http, 9300 вместо 9200. Это связано с тем, что клиент не обменивается данными через http — он подключается к существующему кластеру с помощью транспортного протокола, двоичного протокола, который также используется для связи между узлами в кластере.
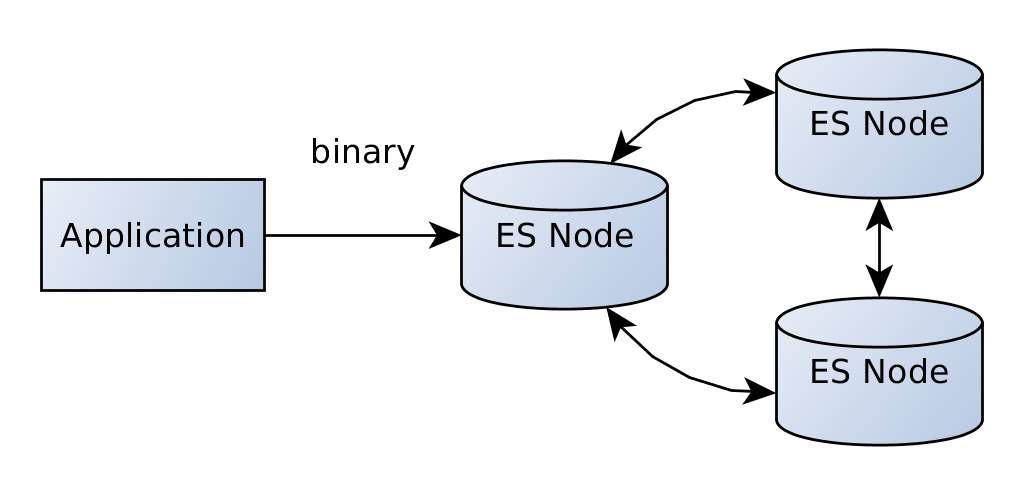
Вы могли также заметить, что пока мы говорим только с одним узлом кластера. Когда этот узел выйдет из строя, мы больше не сможем получить доступ к нашим данным. Если вам нужна высокая доступность, вы можете включить опцию сниффинга, которая позволяет вашему клиенту общаться с несколькими узлами в кластере.
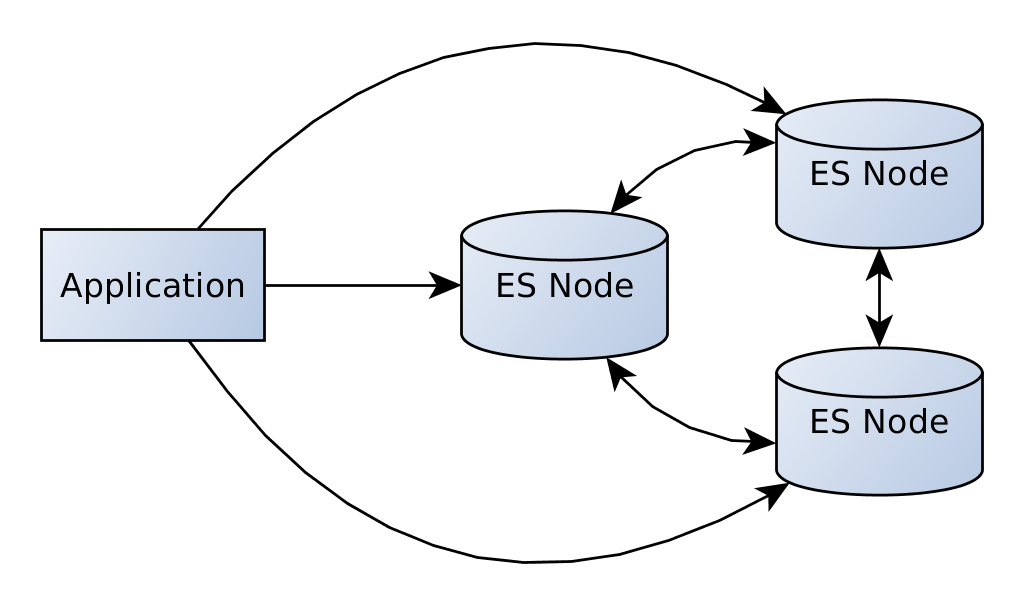
Теперь, когда один из узлов выходит из строя, мы можем получить доступ к данным, используя другие узлы. Эту функцию можно включить, установив для client.transport.sniff значение true при создании клиента.
|
01
02
03
04
05
06
07
08
09
10
|
TransportAddress address = new InetSocketTransportAddress( InetAddress.getByName("localhost"), 9300);Settings settings = Settings.builder() .put("client.transport.sniff", true) .build();Client client = new PreBuiltTransportClient(settings) addTransportAddress(address); |
Эта функция работает, запрашивая текущее состояние кластера у известного узла, используя один из API-интерфейсов управления Flexiblesearch. При настройке это делается во время запуска и через регулярные интервалы, по умолчанию каждые 5 секунд.
Сниффинг — это важная функция, которая гарантирует, что ваше приложение будет работать даже во время отказа узла.
При использовании транспортного клиента у вас есть некоторые очевидные преимущества: так как клиент поставляется с сервером (и даже включает в себя зависимость от сервера), вы можете быть уверены, что весь текущий API доступен для использования в вашем клиентском коде. Связь более эффективна, чем JSON через HTTP, и существует поддержка балансировки нагрузки на стороне клиента.
С другой стороны, есть и некоторые недостатки: поскольку транспортный протокол является внутренним протоколом, вам необходимо использовать совместимую версиюasticsearch на сервере и на клиенте. Также, довольно неожиданно, это также означает, что необходимо использовать аналогичную версию JDK. Кроме того, вам нужно включить все зависимости от эластичного поиска в ваше приложение. Это может быть огромной проблемой, особенно с большими существующими приложениями. Например, может случиться так, что CMS уже поставляет некоторую версию Lucene. Часто невозможно разрешить конфликты зависимостей, подобные этому.
К счастью, для этого есть решение.
RestClient
asticsearch 5.0 представил новый клиент, который использует HTTP API эластичного поиска вместо внутреннего протокола. Это требует гораздо меньше зависимостей. Кроме того, вам не нужно заботиться о версии — текущий клиент также может быть использован сasticsearch 2.x.
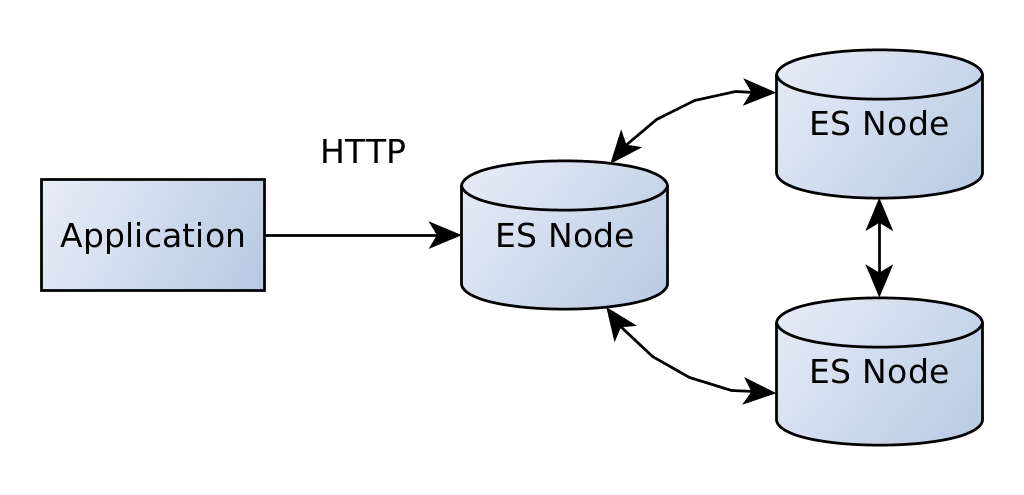
Но есть и недостаток — у него пока не так много возможностей.
Клиент также доступен как артефакт Maven.
|
1
2
3
4
5
|
dependencies { compile group: 'org.elasticsearch.client', name: 'rest', version: '5.0.0'} |
Клиент зависит только от apache httpclient и его зависимостей. Это список Gradle всех зависимостей.
|
1
2
3
4
5
6
|
+--- org.apache.httpcomponents:httpclient:4.5.2+--- org.apache.httpcomponents:httpcore:4.4.5+--- org.apache.httpcomponents:httpasyncclient:4.1.2+--- org.apache.httpcomponents:httpcore-nio:4.4.5+--- commons-codec:commons-codec:1.10\--- commons-logging:commons-logging:1.1.3 |
Это можно создать, передав один или несколько HttpHost .
|
1
2
3
4
|
RestClient restClient = RestClient.builder( new HttpHost("localhost", 9200, "http"), new HttpHost("localhost", 9201, "http")) .build(); |
Поскольку на данный момент не так много функциональности, большая часть JSON доступна только в виде строки. Это пример выполнения запроса match_all и преобразования ответа в строку с помощью вспомогательного метода.
|
1
2
3
4
5
6
7
|
HttpEntity entity = new NStringEntity( "{ \"query\": { \"match_all\": {}}}", ContentType.APPLICATION_JSON); // alternative: performRequestAsync Response response = restClient.performRequest("POST", "/_search", emptyMap(), entity); String json = toString(response.getEntity()); // ... |
Данные индексации также находятся на низком уровне. Вы просто отправляете строку, содержащую документ JSON, в конечную точку. Клиент поддерживает сниффинг с использованием отдельной библиотеки. Помимо того, что имеется меньше зависимостей, а версия эластичного поиска уже не так важна, есть еще одно преимущество для операций: теперь кластер можно отделить от приложений, используя HTTP как единственный протокол для взаимодействия с кластером.
Большая часть функциональности напрямую зависит от http-клиента Apache. Существует поддержка установки тайм-аутов, использования базовой аутентификации, пользовательских заголовков и обработки ошибок.
На данный момент нет поддержки запросов. Если вы можете добавить в свой список зависимостьasticsearch (что, конечно, лишает вас некоторых преимуществ), вы можете использовать SearchSourceBuilder и связанную с ним функциональность для создания строк для запроса.
Помимо нового RestClient есть еще один доступный HTTP-клиент, который имеет больше возможностей: клиент Jest, созданный сообществом.
Шутка
Jest доступен уже давно и является жизнеспособной альтернативой стандартным клиентам. Он также доступен через центральный Maven.
|
1
2
3
4
5
|
dependencies { compile group: 'io.searchbox', name: 'jest', version: '2.0.0'} |
JestClient — это центральный интерфейс, который позволяет отправлять запросы наasticsearch. Он может быть создан с использованием фабрики.
|
1
2
3
4
5
6
7
|
JestClientFactory factory = new JestClientFactory();factory.setHttpClientConfig(new HttpClientConfig .multiThreaded(true) .build());JestClient client = factory.getObject(); |
Как и в случае с RestClient, Jest не поддерживает генерацию запросов. Вы можете создать их с помощью шаблонов String или повторно использовать построители эластичного поиска (с недостатком необходимости снова управлять всеми зависимостями).
Строитель может быть использован для создания поискового запроса.
|
1
2
3
4
5
6
7
8
|
String query = jsonStringThatMagicallyAppears;Search search = new Search.Builder(query) .addIndex("library") .build();SearchResult result = client.execute(search);assertEquals(Integer.valueOf(1), result.getTotal()); |
Результат может быть обработан путем обхода структуры объекта Gson, которая может стать довольно сложной.
|
1
2
3
4
5
6
|
JsonObject jsonObject = result.getJsonObject();JsonObject hitsObj = jsonObject.getAsJsonObject("hits");JsonArray hits = hitsObj.getAsJsonArray("hits");JsonObject hit = hits.get(0).getAsJsonObject();// ... more boring code |
Но это не то, как вы обычно работаете с Jest. Преимущество Jest в том, что он напрямую поддерживает индексирование и поиск Java-бинов. Например, мы можем иметь представление наших документов блюдо.
|
01
02
03
04
05
06
07
08
09
10
11
|
public class Dish { private String food; private List<String> tags; private Favorite favorite; @JestId private String id; // ... getters and setters} |
Этот класс затем может быть автоматически заполнен из результатов поиска.
|
1
2
3
|
Dish dish = result.getFirstHit(Dish.class).source;assertEquals("Roti Prata", dish.getFood()); |
Конечно, поддержка бинов также может быть использована для индексации данных.
Jest может быть хорошей альтернативой при доступе кasticsearch через http. Он обладает множеством полезных функций, таких как поддержка bean-компонентов при индексации и поиске, а также функция анализа, называемая обнаружением узлов. К сожалению, вы должны сами создавать поисковые запросы, но это относится и к RestClient.
Теперь, когда мы посмотрели на трех клиентов, пришло время увидеть абстракцию на более высоком уровне.
Spring Data Elasticsearch
Семейство проектов Spring Data обеспечивает доступ к различным хранилищам данных с использованием общей модели программирования. Он не пытается обеспечить абстракцию для всех магазинов, специальности каждого магазина по-прежнему доступны. Самая впечатляющая особенность — это динамические репозитории, которые позволяют вам определять запросы, используя интерфейс. Популярными модулями являются Spring Data JPA для доступа к реляционным базам данных и Spring Data MongoDB.
Как и все модули Spring, артефакты доступны в центральном Maven.
|
1
2
3
4
5
|
dependencies { compile group: 'org.springframework.data', name: 'spring-data-elasticsearch', version: '2.0.4.RELEASE'} |
Индексируемые документы представлены в виде Java-бинов с использованием пользовательских аннотаций.
|
01
02
03
04
05
06
07
08
09
10
11
12
|
@Document(indexName = "spring_dish")public class Dish { @Id private String id; private String food; private List<String> tags; private Favorite favorite; // more code} |
Различные аннотации могут использоваться для определения того, как документ будет храниться вasticsearch. В этом случае мы просто определяем имя индекса, которое будет использоваться при сохранении документа, и свойство, которое используется для хранения идентификатора, созданного эластичным поиском.
Для доступа к документам можно определить интерфейс, типизированный к классу блюда. Для расширения доступны различные интерфейсы, ElasticsearchCrudRepository предоставляет общий индекс и операции поиска.
|
1
2
3
4
|
public interface DishRepository extends ElasticsearchCrudRepository<Dish, String> {} |
Модуль предоставляет пространство имен для конфигурации XML.
|
1
2
3
4
5
6
7
8
9
|
<elasticsearch:transport-client id="client" /><bean name="elasticsearchTemplate" class="o.s.d.elasticsearch.core.ElasticsearchTemplate"> <constructor-arg name="client" ref="client"/></bean><elasticsearch:repositories base-package="de.fhopf.elasticsearch.springdata" /> |
Элемент transport-client создает экземпляр транспортного клиента, ElasticsearchTemplate обеспечивает общие операции сasticsearch. Наконец, элемент repositories инструктирует Spring Data сканировать интерфейсы, расширяющие один из интерфейсов Spring Data. Это автоматически создаст экземпляры для тех.
Затем вы можете подключить репозиторий к своему приложению и использовать его для хранения и поиска экземпляров Dish .
|
01
02
03
04
05
06
07
08
09
10
11
12
|
Dish mie = new Dish();mie.setId("hokkien-prawn-mie");mie.setFood("Hokkien Prawn Mie");mie.setTags(Arrays.asList("noodles", "prawn"));repository.save(Arrays.asList(hokkienPrawnMie));// one line ommitedIterable<Dish> dishes = repository.findAll();Dish dish = repository.findOne("hokkien-prawn-mie"); |
Получение документов по идентификатору не очень интересно для поисковой системы. Чтобы действительно запрашивать документы, вы можете добавить в свой интерфейс больше методов, соответствующих определенному соглашению об именах.
|
01
02
03
04
05
06
07
08
09
10
11
12
|
public interface DishRepository extends ElasticsearchCrudRepository<Dish, String> { List<Dish> findByFood(String food); List<Dish> findByTagsAndFavoriteLocation(String tag, String location); List<Dish> findByFavoritePriceLessThan(Double price); @Query("{\"query\": {\"match_all\": {}}}") List<Dish> customFindAll();} |
Большинство методов начинаются с findBy за которым следует одно или несколько свойств. Например, findByFood запросит поле food с заданным параметром. Также возможны структурированные запросы, в этом случае добавление lessThan . Это вернет все блюда, цена которых ниже указанной. Последний метод использует другой подход. Он не следует соглашению об именах, но вместо этого использует аннотацию Query . Конечно, этот запрос также может содержать заполнители для параметров.
В заключение, Spring Data Elasticsearch — интересная абстракция поверх стандартного клиента. Это несколько связано с определенной версией эластичного поиска, в текущем выпуске используется версия 2.2. Есть планы сделать его совместимым с 5.x, но это может занять некоторое время. Существует пул-запрос, который использует Jest для связи, но неясно, когда и когда это будет объединено. К сожалению, в проекте не так много активности.
Вывод
Мы рассмотрели три клиента Java и высокоуровневую абстракцию Spring Data Elasticsearch. Каждый из них имеет свои плюсы и минусы, и нет никаких советов, чтобы использовать один во всех случаях. Транспортный клиент имеет полную поддержку API, но связан с зависимостью эластичного поиска. RestClient — это будущее, которое однажды заменит транспортного клиента. Функционально это в настоящее время очень низкий уровень. У Jest более богатый API, но он разрабатывается извне, и компания, стоящая за ним, кажется, больше не существует, хотя в проекте участвуют коммитеры. Spring Data Elasticsearch лучше подходит для разработчиков, уже использующих Spring Data и не желающих напрямую связываться с API эластичного поиска. В настоящее время он привязан к версии стандартного клиента, активность разработки довольно низкая.
| Ссылка: | Java-клиенты для Elasticsearch Transcript от нашего партнера JCG Флориана Хопфа в блоге Dev Time . |