Большинство проблем с производительностью можно решить несколькими различными способами. Многие из применимых решений понятны и знакомы большинству из вас. Некоторые решения, такие как удаление определенных структур данных из кучи, управляемой JVM, являются более сложными. Поэтому, если вы не знакомы с этой концепцией, я могу порекомендовать вам узнать, как недавно мы сократили как задержку наших приложений, так и сокращение счета Amazon AWS вдвое.
Я начну с объяснения контекста, в котором было необходимо решение. Как вы, наверное, знаете, Plumbr следит за каждым взаимодействием пользователей. Это делается с помощью агентов, развернутых рядом с узлами приложения, обрабатывающими взаимодействия.
При этом агенты Plumbr фиксируют различные события из таких узлов. Все события отправляются на центральный сервер и состоят из того, что мы называем транзакциями. Транзакции содержат несколько атрибутов, в том числе:
- время начала и окончания транзакции;
- личность пользователя, выполняющего транзакцию;
- выполненная операция (добавить товар в корзину, создать новый счет и т. д.);
- приложение, которому принадлежит операция;
В контексте конкретной проблемы, с которой мы столкнулись, важно подчеркнуть, что в качестве атрибута транзакции сохраняется только ссылка на фактическое значение. Например, вместо сохранения действительной личности пользователя (будь то электронная почта, имя пользователя или номер социального страхования), ссылка на такую личность сохраняется рядом с самой транзакцией. Таким образом, сами транзакции могут выглядеть следующим образом:
| МНЕ БЫ | Начало | Конец | заявка | операция | пользователь |
|---|---|---|---|---|---|
| # 1 | 12:03:40 | 12:05:25 | # 11 | # 222 | # 3333 |
| # 2 | 12:04:10 | 12:06:00 | # 11 | # 223 | # 3334 |
Эти ссылки сопоставлены с соответствующими удобочитаемыми значениями. Таким образом, поддерживается сопоставление значения ключа для каждого атрибута, так что пользователи с идентификаторами # 3333 и # 3334 могут быть определены как Джон Смит и Джейн Доу соответственно.
Эти сопоставления используются во время выполнения, когда запросы, обращающиеся к транзакциям, заменят ссылки на удобочитаемые справочные данные:
| МНЕ БЫ | Начало | Конец | заявка | операция | пользователь |
|---|---|---|---|---|---|
| # 1 | 12:03:40 | 12:05:25 | www.example.com | /авторизоваться | Джон Смит |
| # 2 | 12:04:10 | 12:06:00 | www.example.com | /купить | Джейн Доу |
Наивное решение
Держу пари, любой из наших читателей может предложить простое решение для такого требования с закрытыми глазами. Выберите реализацию java.util.Map по своему вкусу, загрузите пары ключ-значение на карту и найдите ссылочные значения во время запроса.
То, что казалось легким, оказалось тривиальным, когда мы обнаружили, что наша инфраструктура выбора (хранилище Druid с поисковыми данными, находящимися в темах Kafka) уже поддерживает такие Карты из коробки через поиск Kafka .
Проблема
Наивный подход служил нам хорошо в течение некоторого времени. Через некоторое время, когда размер поисковых карт увеличился, запросы, требующие значений поиска, начали занимать все больше и больше времени.
Мы заметили это, когда ели нашу собачью еду и использовали Plumbr для мониторинга самого Plumbr. Мы начали видеть, что паузы GC становятся все более частыми и продолжительными на узлах Druid Historical, обслуживающих запросы и разрешающих поиск.
По-видимому, некоторые из наиболее проблемных запросов должны были искать более 100 000 различных значений из карты. При этом запросы были прерваны GC, включившим и превысившим длительность запроса до 100 мс до 10+ секунд.
При поиске основной причины у нас был Plumbr, предоставляющий снимки кучи из таких проблемных узлов, подтверждая, что около 70% использованной кучи после долгих пауз GC было использовано именно картой поиска.
Стало также очевидным, что проблема имеет другое измерение для рассмотрения. Наш уровень хранения основан на кластере узлов, где каждая машина в кластере, обслуживающая запросы, запускает несколько процессов JVM, причем каждому процессу требуются одинаковые справочные данные.

Теперь, учитывая, что рассматриваемые JVM работали с кучей 16G и эффективно дублировали всю карту поиска, это также становилось проблемой при планировании емкости. Размеры экземпляров, необходимые для поддержки больших и больших куч, начали сказываться на нашем счете EC2.
Поэтому нам пришлось придумать другое решение, уменьшающее нагрузку на сборку мусора и находящее способ сдерживать расходы на Amazon AWS.
Решение: Хроника Карта
Решение, которое мы внедрили, было построено поверх Chronicle Map . Карта хроники находится вне кучи в хранилище значений ключей памяти. Как показали наши тесты, задержка в магазине также была отличной. Но главным преимуществом, почему мы выбрали Chronicle Map, была возможность обмена данными между несколькими процессами. Таким образом, вместо загрузки значений поиска в каждую кучу JVM, мы можем использовать только одну копию карты, к которой обращаются разные узлы в кластере:
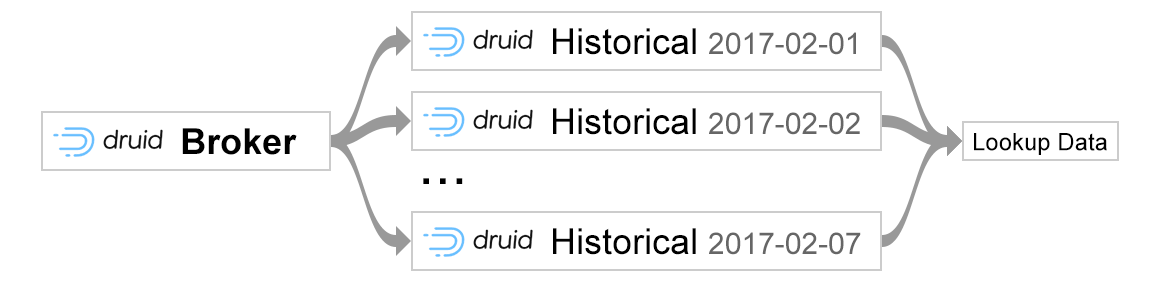
Прежде чем переходить к деталям, позвольте мне дать вам общий обзор функциональности Chronicle Map, который мы считаем особенно полезным. В Chronicle Map данные могут быть сохранены в файловой системе и затем доступны любому параллельному процессу в режиме «просмотра».
Таким образом, наша цель состояла в том, чтобы создать микросервис, который будет выполнять роль «писателя», то есть он будет сохранять все необходимые данные в реальном времени в файловой системе и роли «читателя» — нашего хранилища данных Druid. Поскольку Druid не поддерживает Chronicle Map из коробки, мы внедрили наше собственное расширение Druid, которое может считывать уже сохраненные файлы данных Chronicle и заменять идентификаторы понятными для человека именами во время запроса. Код ниже дает пример того, как можно инициализировать Chronicle Map:
|
1
2
3
4
5
|
ChronicleMap.of(String.class, String.class).averageValueSize(lookup.averageValueSize).averageKeySize(lookup.averageKeySize).entries(entrySize).createOrRecoverPersistedTo(chronicleDataFile); |
Эта конфигурация требуется на этапе инициализации, чтобы убедиться, что Chronicle Map выделяет виртуальную память в соответствии с предельными значениями, которые вы прогнозируете. Предварительное выделение виртуальной памяти — не единственная сделанная оптимизация. Если вы сохраняете данные в файловой системе, как мы, вы заметите, что созданные файлы данных Chronicle на самом деле являются разреженными файлами . Но это будет история для совершенно другого поста, поэтому я не буду вдаваться в подробности.
В конфигурации вам нужно указать тип ключа и значения для карты хроники, которую вы пытаетесь создать. В нашем случае все справочные данные представлены в текстовом формате, поэтому для ключа и значения указан тип String .
После указания типов ключа и значения есть более интересная часть, уникальная для инициализации Chronicle Map. Как следует из названий методов, для AverageValueSize и averageKeySize программист должен указать средний ключ и размер значения, которые, как ожидается, будут храниться в экземпляре Chronicle Map.
С помощью записей метода вы указываете Chronicle Map ожидаемое общее количество данных, которые можно сохранить в экземпляре. Можно задаться вопросом, что произойдет, если со временем количество записей превысит заданный размер? Очевидно, что если вы превысите установленный лимит, вы можете столкнуться с ухудшением производительности в последних введенных запросах.
Еще одна вещь, которую следует учитывать при превышении предопределенного размера записей, — это то, что данные не могут быть восстановлены из файлов Chronicle Map без обновления размера записей. Поскольку Chronicle Map во время инициализации предварительно вычисляет требуемую память для файлов данных, естественно, если размер записей остается неизменным и в действительности файл содержит, скажем, в 4 раза больше записей, данные не поместятся в предварительно вычисленную память, поэтому инициализация Chronicle Map завершится неудачно. Важно помнить об этом, если вы хотите изящно пережить перезапуски. Например, в нашем сценарии при перезапуске микросервиса, в котором сохраняются данные из тем Kafka, перед инициализацией экземпляра Chronicle Map он динамически вычисляет количество записей на основе количества сообщений в теме Kafka. Это позволяет нам в любой момент перезапустить микросервис и восстановить уже сохраненные файлы Chronicle Map с обновленной конфигурацией.
Вынос
Различные оптимизации, позволившие экземпляру Chronicle Map считывать и записывать данные в течение микросекунд, сразу начали давать хороший эффект. Уже через пару дней после выпуска запросов данных на основе Chronicle Map мы смогли увидеть улучшения производительности:
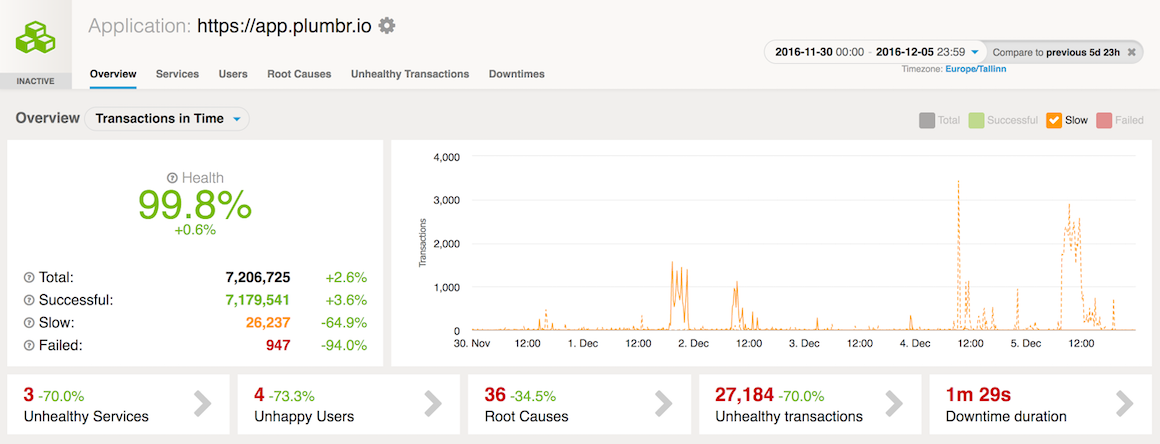
Кроме того, удаление избыточных копий карты поиска из каждой кучи JVM позволило значительно сократить размеры наших экземпляров для узлов хранения, что заметно сказалось на счете Amazon AWS.
| Ссылка: | Выйти в кучу, чтобы улучшить время ожидания и уменьшить счет AWS от нашего партнера JCG Левани Кохреидзе в блоге Plumbr Blog . |