В этом уроке я бы хотел немного рассказать об Apache Lucene . Lucene — это проект с открытым исходным кодом, который предоставляет технологии индексации и поиска на основе Java. Используя его API, легко реализовать полнотекстовый поиск . Я буду иметь дело с версией Java Lucene , но имейте в виду, что есть также порт .NET под названием Lucene.NET , а также несколько полезных подпроектов.
Недавно я прочитал отличное руководство по этому проекту, но никакого реального кода не было представлено. Поэтому я решил предоставить пример кода, который поможет вам начать работу с Lucene. Приложение, которое мы создадим, позволит вам индексировать ваши собственные файлы исходного кода и искать конкретные ключевые слова.
Прежде всего, давайте загрузим последнюю стабильную версию с одного из загрузочных зеркал Apache. Я буду использовать версию 3.0.1, поэтому я скачал пакет lucene-3.0.1.tar.gz (обратите внимание, что версии .tar.gz значительно меньше, чем соответствующие версии .zip). Распакуйте архив и найдите файл lucene-core-3.0.1.jar, который будет использоваться позже. Кроме того, убедитесь, что страница JavaDoc API Lucene открыта в вашем браузере (документы также включены в tarball для автономного использования). Затем настройте новый проект Eclipse, скажем, с именем «LuceneIntroProject» и убедитесь, что вышеупомянутый JAR включен в путь к классам проекта.
Прежде чем мы начнем выполнять поисковые запросы, нам нужно создать индекс, по которому будут выполняться запросы. Это будет сделано с помощью класса IndexWriter , который создает и поддерживает индекс. IndexWriter получает Document s в качестве входных данных, где документы являются единицей индексации и поиска. Каждый документ на самом деле представляет собой набор полей, и каждое поле имеет имя и текстовое значение. Для создания IndexWriter требуется анализатор . Этот класс является абстрактным, и конкретной реализацией, которую мы будем использовать, является SimpleAnalyzer .
Уже достаточно разговоров, давайте создадим класс с именем «SimpleFileIndexer» и убедимся, что основной метод включен. Вот исходный код для этого класса:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
|
package com.javacodegeeks.lucene;import java.io.File;import java.io.FileReader;import java.io.IOException;import org.apache.lucene.analysis.SimpleAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.document.Field;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.store.FSDirectory;public class SimpleFileIndexer { public static void main(String[] args) throws Exception { File indexDir = new File("C:/index/"); File dataDir = new File("C:/programs/eclipse/workspace/"); String suffix = "java"; SimpleFileIndexer indexer = new SimpleFileIndexer(); int numIndex = indexer.index(indexDir, dataDir, suffix); System.out.println("Total files indexed " + numIndex); } private int index(File indexDir, File dataDir, String suffix) throws Exception { IndexWriter indexWriter = new IndexWriter( FSDirectory.open(indexDir), new SimpleAnalyzer(), true, IndexWriter.MaxFieldLength.LIMITED); indexWriter.setUseCompoundFile(false); indexDirectory(indexWriter, dataDir, suffix); int numIndexed = indexWriter.maxDoc(); indexWriter.optimize(); indexWriter.close(); return numIndexed; } private void indexDirectory(IndexWriter indexWriter, File dataDir, String suffix) throws IOException { File[] files = dataDir.listFiles(); for (int i = 0; i < files.length; i++) { File f = files[i]; if (f.isDirectory()) { indexDirectory(indexWriter, f, suffix); } else { indexFileWithIndexWriter(indexWriter, f, suffix); } } } private void indexFileWithIndexWriter(IndexWriter indexWriter, File f, String suffix) throws IOException { if (f.isHidden() || f.isDirectory() || !f.canRead() || !f.exists()) { return; } if (suffix!=null && !f.getName().endsWith(suffix)) { return; } System.out.println("Indexing file " + f.getCanonicalPath()); Document doc = new Document(); doc.add(new Field("contents", new FileReader(f))); doc.add(new Field("filename", f.getCanonicalPath(), Field.Store.YES, Field.Index.ANALYZED)); indexWriter.addDocument(doc); }} |
Давайте немного поговорим об этом классе. Мы указываем местоположение индекса, т.е. где данные индекса будут сохранены на диске («c: / index /»). Затем мы предоставляем каталог данных, то есть каталог, который будет рекурсивно сканироваться на наличие входных файлов. Для этого я выбрал всю свою рабочую область Eclipse («C: / Programs / Eclipse / Workspace /»). Поскольку мы хотим индексировать только файлы исходного кода Java, я также добавил поле суффикса. Очевидно, вы можете настроить эти значения в соответствии с вашими потребностями поиска. Метод «index» учитывает предыдущие параметры и использует новый экземпляр IndexWriter для индексации каталога. Метод indexDirectory использует простой алгоритм рекурсии для сканирования всех каталогов на наличие файлов с суффиксом .java. Для каждого файла, который соответствует критериям, новый документ создается в «indexFileWithIndexWriter», и соответствующие поля заполняются. Если вы запустите класс как приложение Java через Eclipse, входной каталог будет проиндексирован, а выходной каталог будет выглядеть так, как показано на следующем рисунке: 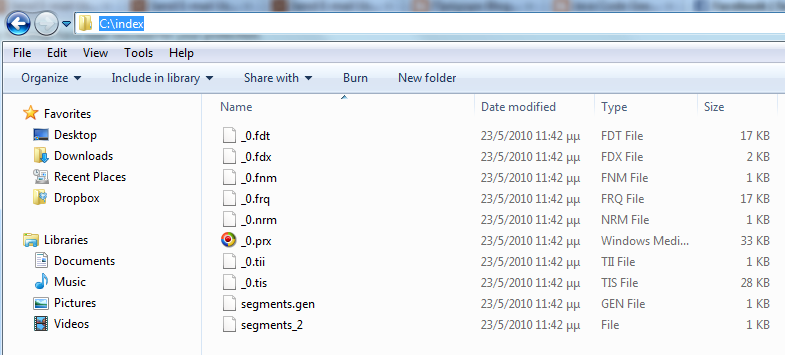 Хорошо, мы закончили с индексацией, давайте перейдем к поисковой части уравнения. Для этого нужен класс IndexSearcher , который реализует основные методы поиска. Для каждого поиска необходим новый объект Query (SQL кто-нибудь?), Который можно получить из экземпляра QueryParser . Обратите внимание, что QueryParser должен быть создан с использованием того же типа Analyzer, с которым был создан индекс, в нашем случае с использованием SimpleAnalyzer. Версия также используется в качестве аргумента конструктора и является классом, который «используется определенными классами для соответствия совместимости версий между выпусками Lucene», согласно JavaDocs. Существование чего-то подобного меня смущает, но что угодно, давайте использовать подходящую версию для нашего приложения ( Lucene_30 ). Когда поиск выполняется IndexSearcher, в результате выполнения возвращается объект TopDocs . Этот класс просто представляет результаты поиска и позволяет нам получать объекты ScoreDoc . Используя ScoreDocs, мы находим Документы, которые соответствуют нашим критериям поиска, и из этих Документов мы получаем требуемую информацию. Давайте посмотрим все это в действии. Создайте класс с именем «SimpleSearcher» и убедитесь, что включен основной метод. Исходный код этого класса следующий:
Хорошо, мы закончили с индексацией, давайте перейдем к поисковой части уравнения. Для этого нужен класс IndexSearcher , который реализует основные методы поиска. Для каждого поиска необходим новый объект Query (SQL кто-нибудь?), Который можно получить из экземпляра QueryParser . Обратите внимание, что QueryParser должен быть создан с использованием того же типа Analyzer, с которым был создан индекс, в нашем случае с использованием SimpleAnalyzer. Версия также используется в качестве аргумента конструктора и является классом, который «используется определенными классами для соответствия совместимости версий между выпусками Lucene», согласно JavaDocs. Существование чего-то подобного меня смущает, но что угодно, давайте использовать подходящую версию для нашего приложения ( Lucene_30 ). Когда поиск выполняется IndexSearcher, в результате выполнения возвращается объект TopDocs . Этот класс просто представляет результаты поиска и позволяет нам получать объекты ScoreDoc . Используя ScoreDocs, мы находим Документы, которые соответствуют нашим критериям поиска, и из этих Документов мы получаем требуемую информацию. Давайте посмотрим все это в действии. Создайте класс с именем «SimpleSearcher» и убедитесь, что включен основной метод. Исходный код этого класса следующий:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
package com.javacodegeeks.lucene;import java.io.File;import org.apache.lucene.analysis.SimpleAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.queryParser.QueryParser;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TopDocs;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.apache.lucene.util.Version;public class SimpleSearcher { public static void main(String[] args) throws Exception { File indexDir = new File("c:/index/"); String query = "lucene"; int hits = 100; SimpleSearcher searcher = new SimpleSearcher(); searcher.searchIndex(indexDir, query, hits); } private void searchIndex(File indexDir, String queryStr, int maxHits) throws Exception { Directory directory = FSDirectory.open(indexDir); IndexSearcher searcher = new IndexSearcher(directory); QueryParser parser = new QueryParser(Version.LUCENE_30, "contents", new SimpleAnalyzer()); Query query = parser.parse(queryStr); TopDocs topDocs = searcher.search(query, maxHits); ScoreDoc[] hits = topDocs.scoreDocs; for (int i = 0; i < hits.length; i++) { int docId = hits[i].doc; Document d = searcher.doc(docId); System.out.println(d.get("filename")); } System.out.println("Found " + hits.length); }} |
Мы предоставляем каталог индекса, строку поискового запроса и максимальное количество обращений, а затем вызываем метод «searchIndex». В этом методе мы создаем IndexSearcher, QueryParser и объект Query. Обратите внимание, что QueryParser использует имя поля, которое мы использовали для создания документов с помощью IndexWriter («содержимое»), и снова, что используется тот же тип анализатора (SimpleAnalyzer). Мы выполняем поиск и для каждого Документа, в котором найдено совпадение, извлекаем значение поля, содержащего имя файла («имя файла»), и печатаем его. Вот и все, давайте выполним фактический поиск. Запустите его как приложение Java, и вы увидите имена файлов, которые содержат указанную вами строку запроса.
Проект Eclipse для этого руководства, включая библиотеку зависимостей, можно скачать здесь .
ОБНОВЛЕНИЕ: Вы также можете проверить наш следующий пост, «Вы имели в виду» функцию Apache Lucene Spell-Checker .
Наслаждайтесь!