Функция «Вы имели в виду» от Google
После введения в Lucene в предыдущем посте , теперь пришло время заняться этим и создать более сложное приложение. Вы наверняка знакомы с функцией «Вы имели в виду» от Google (это поддерживают и другие поисковые системы). Вот пример этого:

Lucene SpellChecker Подпроект
Эта функция может быть реализована в Java с использованием проекта Lucene, и этот урок покажет вам, как это сделать. Реализация будет основана на одном из подпроектов Lucene, названном SpellChecker (см. API проверки орфографии ). Вдохновением для этого поста стала недавняя статья, которую я прочитал в InfoQ под названием « Внедрение в Google функции« Вы имели в виду »в Java ». Автор кратко описывает используемые алгоритмы редактирования расстояния , а затем приводит простой пример кода. Я также нашел похожую статью под названием « Вы имели в виду: Lucene? », Но это было написано еще в 2005 году, так что я думаю, что сейчас оно сильно устарело. Это хорошая идея, сначала взглянуть на них, а затем вернуться к некоторым действиям.
Нахождение базового словаря
Для целей данного руководства будет использоваться текстовый файл словаря английского языка. Вы можете выполнить простой поиск для этого или вы можете напрямую скачать этот заархивированный файл . Файл очень прост и содержит слова, разделенные строками. Извлеченный файл называется «fulldictionary00.txt».
Использование Lucene SpellChecker API
Давайте начнем с создания нового проекта Eclipse, возможно, под названием «LuceneSuggestionsProject», и импортируем необходимые файлы JAR. За исключением основного JAR-файла lucene-core-3.0.1.jar, нам также понадобится lucene-spellchecker-3.0.1.jar. Это можно найти в распакованном архиве в папке «lucene-3.0.1 \ contrib \ spellchecker». Если вы не знаете, как найти дистрибутив и начать работу с проектом, проверьте мой предыдущий пост ( Введение в Apache Lucene для полнотекстового поиска ). Создайте новый класс с именем «SimpleSuggestionService» и убедитесь, что включен основной метод. Исходный код этого класса следующий:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
package com.javacodegeeks.lucene.spellcheck;import java.io.File;import org.apache.lucene.search.spell.PlainTextDictionary;import org.apache.lucene.search.spell.SpellChecker;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;public class SimpleSuggestionService { public static void main(String[] args) throws Exception { File dir = new File("c:/spellchecker/"); Directory directory = FSDirectory.open(dir); SpellChecker spellChecker = new SpellChecker(directory); spellChecker.indexDictionary( new PlainTextDictionary(new File("c:/fulldictionary00.txt"))); String wordForSuggestions = "hwllo"; int suggestionsNumber = 5; String[] suggestions = spellChecker. suggestSimilar(wordForSuggestions, suggestionsNumber); if (suggestions!=null && suggestions.length>0) { for (String word : suggestions) { System.out.println("Did you mean:" + word); } } else { System.out.println("No suggestions found for word:"+wordForSuggestions); } }} |
Да, это так просто. Если вы запустите приложение (используя «hwllo» в качестве входного слова), произойдет следующий вывод:
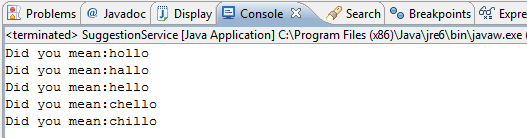
Объяснение API SpellChecker
Код очень прост, но я остановлюсь на некоторых классах. Для начала вам нужен каталог , который представляет собой плоский список файлов. Этот класс является абстрактным, поэтому мы используем FSDirectory в качестве фактической реализации. FSDirectory хранит индексные файлы в файловой системе (для более быстрого доступа следует оценить RAMDirectory , которая является реализацией резидентной памяти). Следующим шагом является создание экземпляра SpellChecker , который является сердцем нашего приложения. Обратите внимание, что StringDistance по умолчанию является LevensteinDistance . Если вы хотите использовать другой алгоритм ( JaroWinklerDistance или NGramDistance ), вы можете использовать метод setStringDistance . Затем мы создаем экземпляр PlainTextDictionary , который указывает на загруженный текстовый файл. Словарь индексируется, а затем объект SpellChecker используется для извлечения предложенных слов для слова с ошибкой.
Я думаю, вы теперь готовы создать следующую большую поисковую систему. Вы можете найти соответствующий проект Eclipse здесь .
Наслаждайтесь!