HashMap<K, V> — это быстрая, универсальная и вездесущая структура данных в каждой Java-программе. Сначала немного основ. Как вы, вероятно, знаете, он использует методы ключей hashCode() и equals() для разделения значений между сегментами. Количество сегментов (корзин) должно быть немного больше, чем количество записей в карте, чтобы в каждом блоке содержалось лишь небольшое (предпочтительно одно) значение. При поиске по ключу мы очень быстро определяем bucket (используя hashCode() по модулю number_of_buckets ), и наш элемент доступен в постоянное время.
Это должно было быть уже известно вам. Вы, вероятно, также знаете, что коллизии хэшей имеют катастрофические последствия для производительности HashMap . Когда несколько значений hashCode() оказываются в одном сегменте, они помещаются в специальный связанный список. В худшем случае, когда все ключи сопоставлены одному и тому же сегменту, вырождается хеш-карта в связанный список — от O (1) до O (n) времени поиска. Давайте сначала HashMap поведение HashMap в обычных условиях в Java 7 (1.7.0_40) и Java 8 (1.8.0-b132). Чтобы иметь полный контроль над поведением hashCode() мы определяем наш пользовательский класс Key :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
class Key implements Comparable<Key> { private final int value; Key(int value) { this.value = value; } @Override public int compareTo(Key o) { return Integer.compare(this.value, o.value); } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Key key = (Key) o; return value == key.value; } @Override public int hashCode() { return value; }} |
Key класс хорошо себя ведет: он переопределяет equals() и предоставляет приличный hashCode() . Чтобы избежать чрезмерного GC, я кэширую неизменные экземпляры Key а не создаю их с нуля снова и снова:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
public class Keys { public static final int MAX_KEY = 10_000_000; private static final Key[] KEYS_CACHE = new Key[MAX_KEY]; static { for (int i = 0; i < MAX_KEY; ++i) { KEYS_CACHE[i] = new Key(i); } } public static Key of(int value) { return KEYS_CACHE[value]; } } |
Теперь мы готовы немного поэкспериментировать. Наш бенчмарк просто создаст HashMap разных размеров (степени 10, от 1 до 1 миллиона), используя непрерывное пространство клавиш. В самом бенчмарке мы будем искать значения по ключам и измерять, сколько времени это займет, в зависимости от размера HashMap :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
import com.google.caliper.Param;import com.google.caliper.Runner;import com.google.caliper.SimpleBenchmark; public class MapBenchmark extends SimpleBenchmark { private HashMap<Key, Integer> map; @Param private int mapSize; @Override protected void setUp() throws Exception { map = new HashMap<>(mapSize); for (int i = 0; i < mapSize; ++i) { map.put(Keys.of(i), i); } } public void timeMapGet(int reps) { for (int i = 0; i < reps; i++) { map.get(Keys.of(i % mapSize)); } } } |
Результаты подтверждают, что HashMap.get() действительно является O (1):
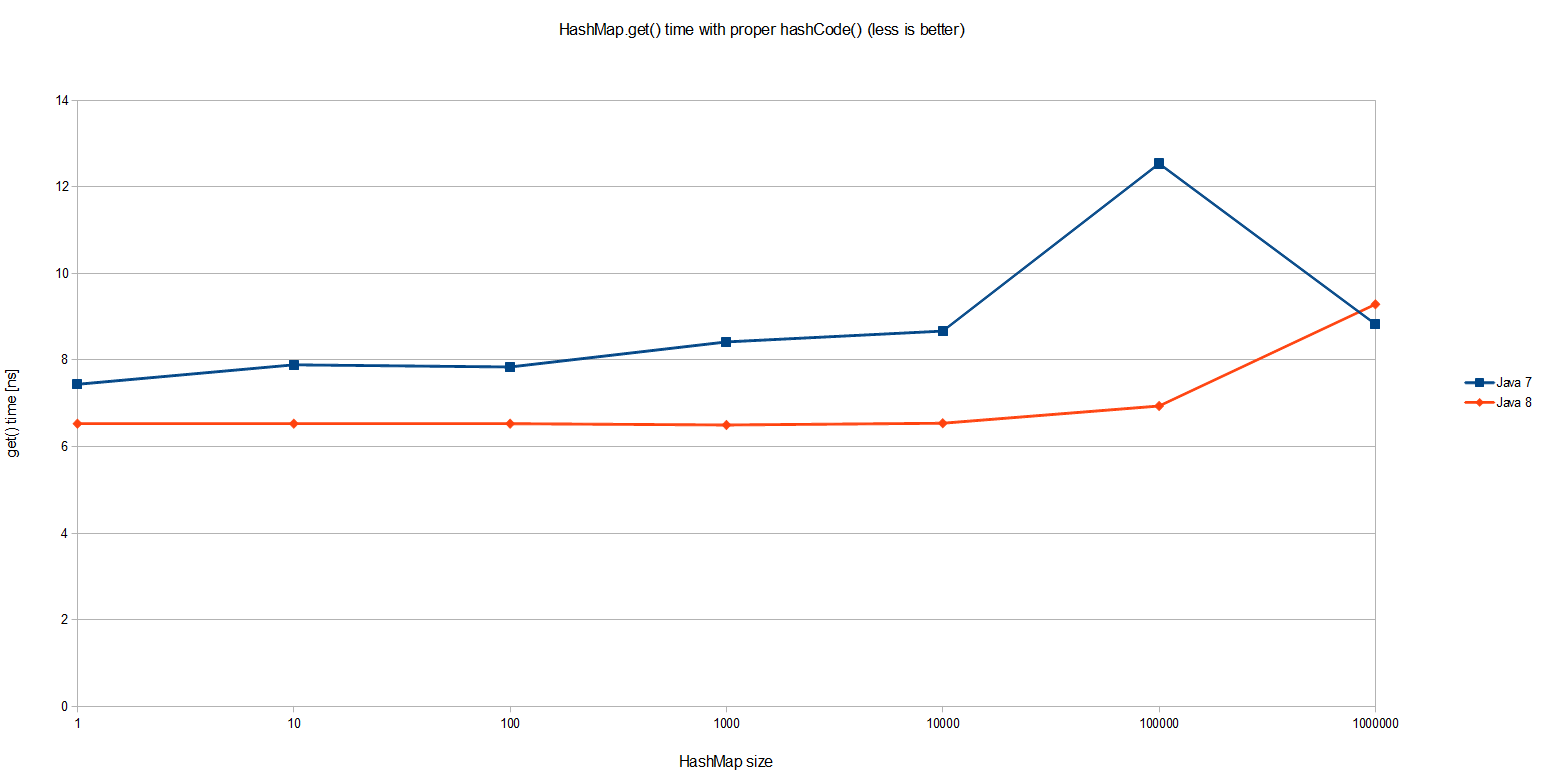
Интересно, что Java 8 в среднем на 20% быстрее, чем Java 7 в простом HashMap.get() . Общая производительность не менее интересна: даже с одним миллионом записей в HashMap один просмотр занял менее 10 наносекунд, что означает около 20 циклов ЦП на моей машине * . Очень впечатляет! Но это не то, что мы собирались измерять.
Предположим, что у нас очень плохой ключ карты, который всегда возвращает одно и то же значение. Это наихудший сценарий, который полностью отвергает цель использования HashMap :
|
1
2
3
4
5
6
7
8
9
|
class Key implements Comparable<Key> { //... @Override public int hashCode() { return 0; }} |
Я использовал точно такой же эталонный тест, чтобы увидеть, как он ведет себя при различных размерах карты (обратите внимание, что это лог-лог масштаб):
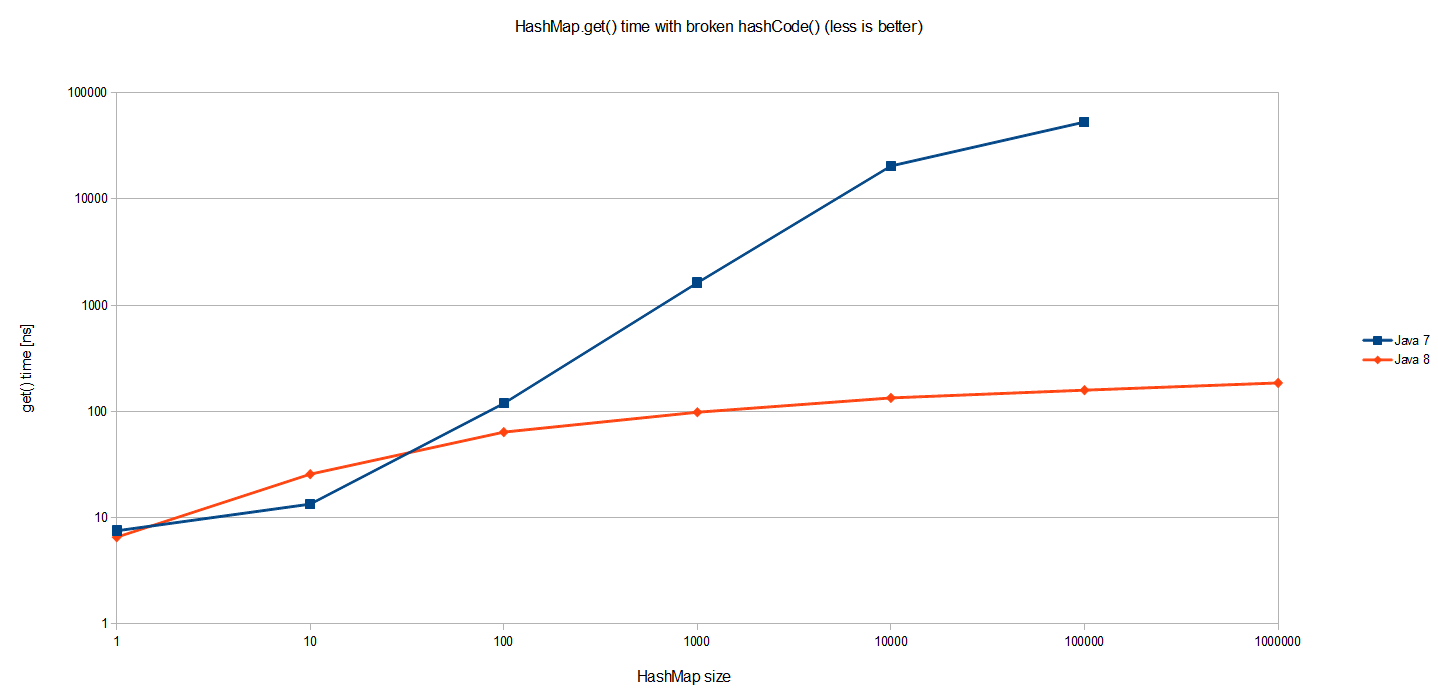
Ожидается результатов для Java 7. Стоимость HashMap.get() растет пропорционально размеру самого HashMap . Поскольку все записи находятся в одном и том же сегменте в одном огромном связанном списке, поиск одного требует в среднем обхода половины такого списка (размера n). Таким образом, O (n) сложность, как показано на графике.
Но Java 8 работает намного лучше! Это логарифмическая шкала, поэтому мы на самом деле говорим на несколько порядков лучше. Тот же самый тест, выполненный в JDK 8, дает O (logn) производительность в наихудшем случае в случае катастрофических коллизий хэшей, как показано на рисунке лучше, если JDK 8 визуализируется отдельно в логарифмическом масштабе:
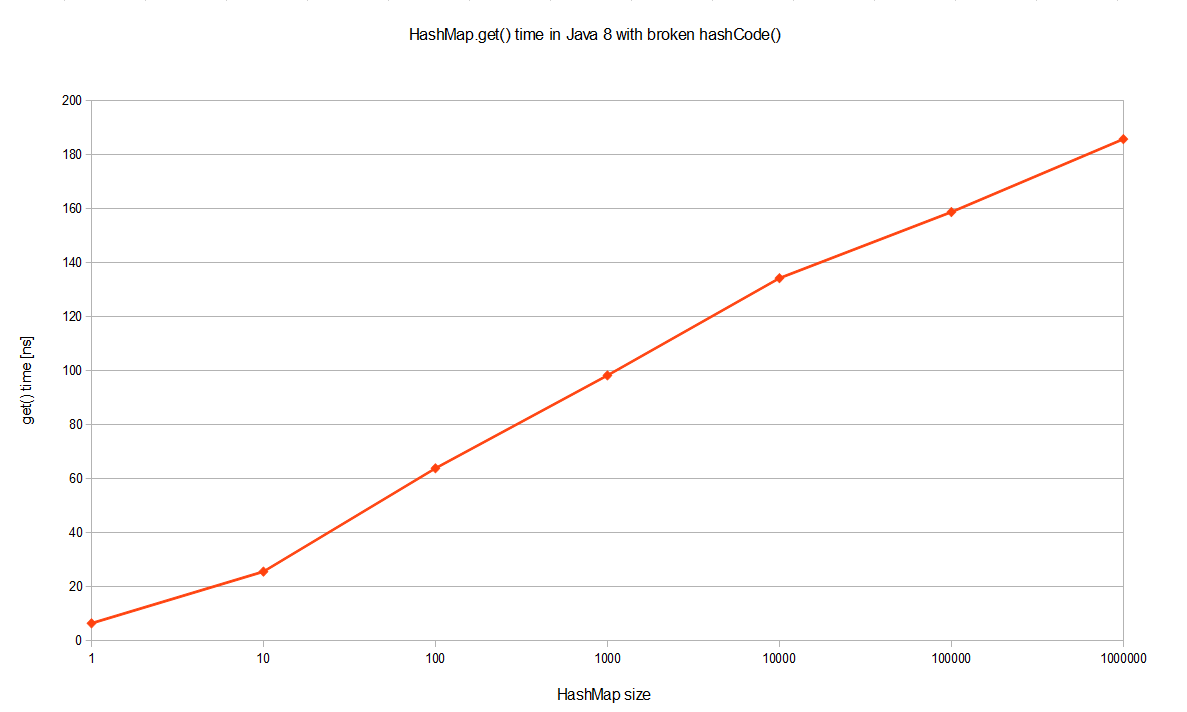
В чем причина такого огромного улучшения производительности, даже с точки зрения обозначения Big-O? Ну, эта оптимизация описана в JEP-180 . В основном, когда TREEIFY_THRESHOLD = 8 становится слишком большой (в настоящее время: TREEIFY_THRESHOLD = 8 ), HashMap динамически заменяет ее специальной реализацией древовидной карты. Таким образом, вместо пессимистического O (n) мы получаем намного лучше O (logn). Как это работает? Что ж, ранее записи с конфликтующими ключами просто добавлялись в связанный список, который позже нужно было просмотреть. Теперь HashMap преобразует список в двоичное дерево, используя хеш-код в качестве переменной ветвления. Если два хэша различны, но попали в одно и то же ведро, один считается больше и идет вправо. Если хэши равны (как в нашем случае), HashMap надеется, что ключи Comparable , чтобы он мог установить некоторый порядок. Это не требование ключей HashMap , но, видимо, хорошая практика. Если ключи несопоставимы, не ожидайте каких-либо улучшений производительности в случае сильных коллизий хешей.
Почему все это так важно? Вредоносное ПО, осведомленное о алгоритме хэширования, которое мы используем, может обработать пару тысяч запросов, что приведет к массовым коллизиям хешей. Постоянный доступ к таким ключам значительно повлияет на производительность сервера, что приведет к атаке типа «отказ в обслуживании». В JDK 8 удивительный переход от O (n) к O (logn) предотвратит такой вектор атаки, а также сделает производительность более предсказуемой. Я надеюсь, что это наконец убедит вашего босса в обновлении.
* Тесты производительности выполняются на Intel Core i7-3635QM с частотой 2,4 ГГц, 8 ГБ ОЗУ и SSD-накопителем, в 64-разрядной версии Windows 8.1 и настройках JVM по умолчанию.
| Ссылка: | Улучшения производительности HashMap в Java 8 от нашего партнера JCG Томаша Нуркевича из блога Java и соседей . |