На данный момент JDK 7 находится в руках разработчиков, и большинство людей слышали о ForkJoin, но не у многих есть время или шанс в повседневной работе попробовать его.
Это вызвало и, вероятно, все еще вызывает некоторую путаницу в том, чем он отличается от обычного пула потоков. [1]
Моя цель в этой статье — представить более сложный, но все же простой пример использования ForkJoin через пример кода.
Я измеряю производительность последовательного и потокового пула в сравнении с подходом ForkJoin .
Вот предварительная версия github: https://github.com/fbunau/javaadvent-forkjoin
Практическая проблема
Представьте, что в нашей системе есть какой-то компонент, который сохраняет последнюю цену акции за каждую миллисекунду.
Это может храниться в памяти как массив целых чисел. (если мы посчитаем в бит / с)
Клиенты этого компонента задают такие вопросы: каков момент времени между временем1 и временем2, когда цена была самой низкой?
Это может быть либо автоматический алгоритм, либо просто кто-то в графическом интерфейсе, делающий выбор прямоугольника.
![]()
7 запросов в примере изображения
Давайте также представим, что мы получаем много таких запросов от клиента, объединенного в задачу.
Они могут быть сгруппированы для уменьшения сетевого трафика и времени прохождения туда-обратно.
У нас есть различные размеры задач, которые может получить компонент, до 10 запросов (кто-то с графическим интерфейсом), до 100, … до 1 000 0000 (некоторый автоматизированный алгоритм). У нас много таких клиентов для компонента, каждый из которых производит задачи разных размеров. Смотрите Task.TaskType
Основная проблема и решение
Проблема, которую мы должны решить, — это проблема RMQ . Вот Википедия [2] :
«Учитывая массив объектов, взятых из упорядоченного набора (например, чисел), минимальный запрос диапазона (или RMQ) от i до j запрашивает позицию минимального элемента в подмассиве A[i, j] «.
«Например, A = [0, 5, 2, 5, 4, 3, 1, 6, 3] когда, тогда ответ на минимальный диапазон запроса для A[3, 8] = [2, 5, 4, 3, 1, 6] равно 7 , так как A[7] = 1 «.
Существует эффективная структура данных для решения этой проблемы, которая называется «Дерево сегментов».
Я не буду вдаваться в подробности этого, так как он великолепно освещен в этой классической статье Topcoder [3] . Само по себе это не важно для этого примера ForkJoin, я выбрал это, потому что это более интересно, чем простая сумма, и его сущность в некотором роде в духе fork-join. Он делит задачу, которую нужно вычислить, а затем объединяет результаты!
Структура данных имеет время инициализации O(n) и время запроса O(log N) , где N — количество элементов в нашем массиве значений цены за единицу времени.
Таким образом, задача T содержит M таких запросов, которые необходимо выполнить.
При академическом подходе в области компьютерных наук вы бы просто сказали, что мы выполним каждую задачу с этой эффективной структурой данных, и сложность будет:
![]()
Вы не можете стать более эффективным, чем это!? Да, в теоретической машине фон Неймана, но вы можете на практике.
Легкая путаница состоит в том, что, поскольку O(n/4) == O(n) , то при написании программы постоянные факторы не учитываются, а учитываются!
Остановись и подумай, стоит ли ждать 10 или 40 минут / часов / лет?
Идти параллельно
Размышляя над проблемой, которую нужно решить, как мы можем сделать это быстрее? Поскольку каждое вычислительное устройство теперь имеет больше ядер для вычислений, давайте использовать их с пользой и делать больше вещей одновременно.
Мы можем легко сделать это, используя инфраструктуру Fork Join.
Сначала я испытал желание изменить структуру данных RMQ и выполнить ее операции параллельно. Я атаковал что-то, что уже было журналом N. Но это был большой провал, слишком много накладных расходов, чтобы планировщик мог управлять такой кратковременной логикой.
Ответ был в конце концов напасть на постоянный множитель M_i .
Пул потоков
Прежде чем представить, как можно применить решение ForkJoin, давайте представим, как мы можем применить пул потоков. Смотрите: TaskProcessorPool.java
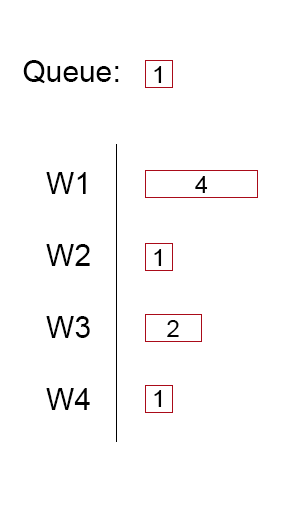
У нас может быть пул из 4 работников, когда у нас есть Задача, мы добавляем ее в очередь. Как только рабочий становится доступным, он извлекает из головы очереди ожидающую задачу и выполняет ее.
Хотя это подходит для задач одинакового размера, а размер относительно средний и предсказуемый, возникают проблемы, когда выполняемые задачи имеют разные размеры. Один рабочий может быть захлебнут долгим заданием, а остальные сидят, ничего не делая.
На этом изображении пул потоков будет выполнять только 9 из 16 возможных единиц работы за 4 единицы времени (эффективность 56%), если больше задач не будет добавлено в очередь
Форк Присоединиться
Форк-соединение полезно, когда вы находитесь в проблемной области, где вы можете разбить решаемую задачу на более мелкие.
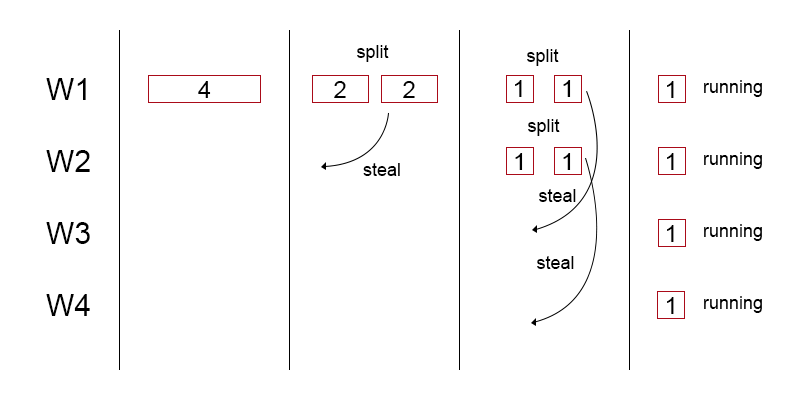
Что особенного в пуле fork-join, так это то, что это пул потоков для кражи работы.
Каждый рабочий поток поддерживает локальную очередь задач. Принимая новое задание для выполнения, оно может либо:
- разбить задачу на более мелкие
- выполнить задачу, если она достаточно мала
Когда у потока нет локальных потоков в очереди, он «крадет», извлекает задачи из задней части очереди другого случайного потока и помещает его в свой собственный. Существует высокая вероятность того, что эта задача еще не разделена. Так что у него будет довольно много работы на руках.
По сравнению с пулом потоков, вместо других потоков, ожидающих какую-то новую работу, они могли бы разделить существующую задачу на более мелкие и помочь другому потоку с этой большой задачей.
Вот оригинальная статья Дуга Ли для более подробного объяснения: http://gee.cs.oswego.edu/dl/papers/fj.pdf
Возвращаясь к нашему примеру, большой пакет операций может быть разбит на несколько пакетов меньшего числа операций. Смотрите: TaskProcessorFJ.java
У большинства задач есть линейный ряд операций, подобных этой, это не должно быть специальной параллельной задачей, для которой нам нужно применить специализированный параллельный алгоритм, чтобы использовать ядра, имеющиеся у нас на процессоре.
Сколько ты разделил? Вы разделяете задачу до тех пор, пока не достигнете порогового значения, при котором обычно деление больше не имеет смысла. Пример: (разделение + поток, получающий работу + переключение контекста — это больше, чем фактическое выполнение задачи как есть)
Для большой XXL задачи нам нужно выполнить 1000000 операций с запросами. Мы могли бы разделить это на 2 500 000 рабочих задач и сделать это параллельно. 500000 все еще большой? Да, мы можем разделить это больше. Я выбрал группу из 10000 операций в качестве порогового значения, при котором разделение бесполезно, и мы можем просто выполнить их в текущем потоке.
Соединение с помощью Fork не разделяет все задачи заранее, а скорее работает через него.
Результаты производительности
Я выполнил 4 итерации для каждой реализации процессора на моем процессоре i5-2500 с частотой 3,30 ГГц, который имеет 4 ядра / 4 потока, после чистой перезагрузки
Вот результаты:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
Doing 4 runs for each of the 3 processors. Pls wait ...TaskProcessorSimple: 7963TaskProcessorSimple: 7757TaskProcessorSimple: 7748TaskProcessorSimple: 7744TaskProcessorPool: 3933TaskProcessorPool: 2906TaskProcessorPool: 4477TaskProcessorPool: 4160TaskProcessorFJ: 2498TaskProcessorFJ: 2498TaskProcessorFJ: 2524TaskProcessorFJ: 2511Test completed. |
Выводы
Даже если вы выбрали правильную оптимальную структуру данных, это не быстро, пока вы не используете все имеющиеся у вас ресурсы. то есть используя все ядра
ForkJoin определенно является улучшением по сравнению с пулом потоков в определенных проблемных областях, и его стоит изучить, где его можно применить, и мы увидим все больше и больше параллельного кода.
Это тот тип процессора, который вы можете купить сегодня на 12 ядер / 24 потока. Теперь нам просто нужно написать программное обеспечение, чтобы использовать классное оборудование, которое у нас есть и будет в будущем.
Код здесь: https://github.com/fbunau/javaadvent-forkjoin, если вы хотите поиграть с ним
Спасибо за ваше время, оставьте несколько комментариев, если вы видите какие-либо ошибки или есть что добавить.