SQL всегда был декларативным языком, тогда как Java долгое время была обязательной. Потоки Java изменили игру. Кодируйте свой путь через эту практическую лабораторную статью и узнайте, как потоки Java могут использоваться для выполнения декларативных запросов к базе данных RDBMS, без написания одной строки кода SQL. Вы обнаружите, что существует замечательное сходство между глаголами потоков Java и командами SQL.
Эта статья является четвертой из пяти, дополненных репозиторием GitHub, содержащим инструкции и упражнения для каждого модуля.
Часть 1. Создание потоков
Часть 2: Промежуточные операции
Часть 3: Терминальные операции
Часть 4. Потоки базы данных
Часть 5: Создание приложения базы данных с использованием потоков
Потоки базы данных
Когда вы ознакомились с операциями Streams, вы, возможно, заметили сходство с конструкциями SQL. Некоторые из них имеют более или менее прямое отображение операций Stream, например LIMIT и COUNT . Это сходство используется проектом с открытым исходным кодом Speedment для обеспечения безопасного доступа к любой реляционной базе данных с использованием чистой Java.

Мы участвуем в проекте с открытым исходным кодом Speedment и опишем, как Speedment позволяет нам использовать базу данных в качестве источника потока и снабжать конвейер строками из любой из таблиц базы данных.
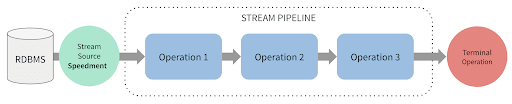
Как показано на приведенной выше визуализации, Speedment установит соединение с базой данных и затем сможет передавать данные в приложение. Нет необходимости писать какой-либо код для записей базы данных, поскольку Speedment анализирует базовую базу данных и автоматически генерирует все необходимые классы сущностей для модели домена. Это экономит много времени, когда вам не нужно писать и поддерживать классы сущностей вручную для каждой таблицы, которую вы хотите использовать.
База данных Сакила
Для этой статьи, а также для упражнений мы используем пример базы данных MySQL Sakila в качестве источника данных. База данных Sakila моделирует старомодный бизнес по прокату фильмов и поэтому содержит таблицы, такие как «Фильм» и «Актер». Экземпляр базы данных развернут в облаке и открыт для общего доступа.
Менеджер скорости
В Speedment дескриптор таблицы базы данных называется
Manager Менеджеры являются частью автоматически сгенерированного кода.
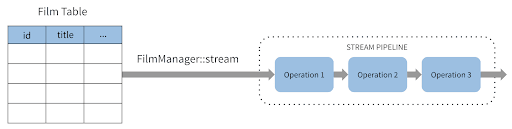
Manager действует как дескриптор таблицы базы данных и может выступать в качестве источника потока. В этом случае каждая строка соответствует экземпляру фильма.
Manager в Speedment создается по телефону:
|
1
|
FilmManager films = speedment.getOrThrow(FilmManager.class); |
Примечание: speedment — это экземпляр, который можно получить из ApplicationBuilder (подробнее об этом в следующей статье).
Если вызывается FilmManager::stream , результатом будет Stream к которому мы можем применить любые промежуточные или терминальные операции. Для начала мы собираем все строки в списке.
|
1
|
List<Film> allFilms = films.stream().collect(toList()); |
|
1
2
3
4
|
FilmImpl { filmId = 1, title = ACADEMY DINOSAUR, …FilmImpl { filmId = 2, title = ACE GOLDFINGER, …FilmImpl { filmId = 3, title = ADAPTATION HOLES, …… |
Фильтрация и подсчет
Давайте рассмотрим простой пример, который выводит количество фильмов, имеющих рейтинг «PG-13». Как и в обычном Stream , мы можем отфильтровать фильмы с правильным рейтингом, а затем посчитать эти записи.
|
1
2
3
|
long pg13FilmCount = films.stream() .filter(Film.RATING.equal("PG-13")) .count(); |
|
1
|
pg13FilmCount: 195 |
Одно важное свойство, которое следует за пользовательской реализацией потоков в Speedment, заключается в том, что потоки могут оптимизировать свой собственный конвейер путем самоанализа. Может показаться, что Stream будет перебирать все строки таблицы, но это не так. Вместо этого Speedment может преобразовать конвейер в оптимизированный SQL-запрос, который передается в базу данных. Это означает, что в поток добавляются только соответствующие записи базы данных. Таким образом, в приведенном выше примере поток будет автоматически отображаться на SQL, аналогично «SELECT… FROM film WHERE rating = ‘PG-13′»
Этот самоанализ требует, чтобы любое использование анонимных лямбд (которые не содержат метаданных, относящихся к целевому столбцу) было заменено предикатами из полей ускорения. В этом случае Film.RATING.equal(“PG-13”) возвращает Predicate который будет проверен на каждом фильме, и возвращает значение true, если и только если этот фильм имеет рейтинг PG-13.
Хотя это не мешает нам выражать предикат как:
|
1
|
.filter(f -> f.getRating().equals(“PG-13”)) |
но это заставит Speedment выбрать все строки в таблице и затем применить предикат, поэтому это не рекомендуется.
В поисках самого длинного фильма
Вот пример, который находит самый длинный фильм в базе данных, используя оператор max с Field Film.LENGTH :
|
1
2
|
Optional<Film> longestFilm = films.stream() .max(Film.LENGTH); |
|
1
2
|
longestFilm: Optional[FilmImpl {filmId = 141, title = CHICAGO NORTH, length = 185, ...}] |
В поисках трех короткометражных фильмов
Чтобы найти три коротких фильма (мы определили короткий как <= 50 минут), можно отфильтровать все фильмы, которые на 50 минут или меньше, и выбрать три первых результата. Предикат в этом примере просматривает значение столбца «длина» и определяет, меньше или равно 50.
|
1
2
3
4
|
List<Film> threeShortFilms = films.stream() .filter(Film.LENGTH.lessOrEqual(50)) .limit(3) .collect(toList()); |
|
1
2
3
4
|
threeShortFilms: [ FilmImpl { filmId = 2, length = 48,..}, FilmImpl { filmId = 3, length = 50, … }, FilmImpl { filmId = 15, length = 46, ...}] |
Нумерация страниц с сортировкой
Если бы мы отображали все фильмы на веб-сайте или в приложении, мы бы предпочли разбивать элементы на страницы, а не загружать (возможно) тысячи записей одновременно. Это может быть достигнуто путем объединения операций skip () и limit() . В приведенном ниже примере мы собираем содержимое второй страницы, предполагая, что каждая «страница» содержит 25 записей. Напомним, что потоки не гарантируют определенный порядок элементов, а это означает, что нам нужно определить порядок с оператором sorted, чтобы это работало как задумано.
|
1
2
3
4
5
|
List<Film> filmsSortedByLengthPage2 = films.stream() .sorted(Film.LENGTH) .skip(25 * 1) .limit(25) .collect(toList()); |
|
1
2
|
filmsSortedByLengthPage2: [FilmImpl { filmId = 430, length = 49, …}, …] |
Примечание. Поиск содержимого n-й страницы выполняется путем пропуска (25 * (n-1)).
Примечание 2: Этот поток будет автоматически отображаться в формате «ВЫБРАТЬ… ИЗ ПЛЕНКИ ПО ЗАКАЗУ ПО ДЛИНЕ АСК»? OFFSET?, Значения: [25, 25] ”
Фильмы, начинающиеся с буквы «А», отсортированные по длине
Мы можем легко найти любые фильмы, начинающиеся с заглавной буквы «А», и отсортировать их по длине (сначала с самым коротким фильмом) следующим образом:
|
1
2
3
4
|
List<Film> filmsTitleStartsWithA = films.stream() .filter(Film.TITLE.startsWith("A")) .sorted(Film.LENGTH) .collect(Collectors.toList()); |
|
1
2
3
4
|
filmsTitleStartsWithA: [ FilmImpl { filmId=15, title=ALIEN CENTER, …, rating=NC-17, length = 46, FilmImpl { filmId=2, title=ACE GOLDFINGER, …, rating=G, length = 48,… ] |
Расчет частотных таблиц длины пленки
Мы также можем использовать оператор groupingBy для сортировки пленок в ведрах в зависимости от их длины и подсчета общего количества пленок в каждом ведре. Это создаст так называемую частотную таблицу длины пленки.
|
1
2
3
4
5
|
Map<Short, Long> frequencyTableOfLength = films.stream() .collect(Collectors.groupingBy( Film.LENGTH.asShort(), counting() )); |
|
1
|
frequencyTableOfLength: {46=5, 47=7, 48=11, 49=5, … } |
упражнения
Для упражнений этой недели вам не нужно беспокоиться о подключении собственной базы данных. Вместо этого мы уже предоставили соединение с экземпляром базы данных Sakila в облаке. Как обычно, упражнения можно разместить в этом репозитории GitHub. Содержание этой статьи достаточно, чтобы решить четвертый блок, который называется MyUnit4Database . Соответствующий
Интерфейс Unit4Database содержит JavaDocs, которые описывают предполагаемую реализацию методов в MyUnit4Database .
|
1
2
3
4
5
6
7
8
9
|
public interface Unit4Database { /** * Returns the total number of films in the database. * * @param films manager of film entities * @return the total number of films in the database */ long countAllFilms(FilmManager films); |
Предоставленные тесты (например, Unit4MyDatabaseTests ) будут действовать как инструмент автоматической оценки, сообщая вам, было ли ваше решение правильным или нет.
Следующая статья
Пока что мы только очистили поверхность от потоков базы данных. Следующая статья позволит вам писать автономные приложения баз данных на чистом Java. Удачного кодирования!
Авторы
Пер Минборг
Юлия Густафссон
Ресурсы
GitHub Opensource Project ускорение
Speedment Stream ORM инициализатор
GitHub Repository «hol-streams»
Статья часть 1: Создание потоков
Статья Часть 2. Промежуточные операции
Статья Часть 3: Терминальные Операции
|
Смотрите оригинальную статью здесь: Станьте Мастером Java Streams — Часть 4: Потоки БД Мнения, высказанные участниками Java Code Geeks, являются их собственными. |