Билл Гейтс однажды сказал: «Я выбираю ленивого человека для выполнения сложной работы, потому что ленивый человек найдет легкий способ сделать это». Ничто не может быть более правдивым, когда дело доходит до потоков. В этой статье вы узнаете, как Stream избегает ненужной работы, не выполняя каких-либо вычислений над исходными элементами до вызова операции терминала, и как источник генерирует только минимальное количество элементов.
Эта статья является третьей из пяти, дополненных репозиторием GitHub, содержащим инструкции и упражнения для каждого модуля.
Часть 1. Создание потоков
Часть 2: Промежуточные операции
Часть 3: Терминальные операции
Часть 4. Потоки базы данных
Часть 5: Создание приложения базы данных с использованием потоков
Терминальные операции
Теперь, когда мы знакомы с инициацией и созданием конвейера Stream, нам нужен способ обработки вывода. Терминальные операции позволяют это, производя результат от оставшихся элементов (таких как
count() ) или побочный эффект (такой как
forEach(Consumer) ).
Поток не будет выполнять какие-либо вычисления над элементами источника, пока не начнется работа терминала. Это означает, что исходные элементы потребляются только по мере необходимости — разумный способ избежать ненужной работы. Это также означает, что после применения операции терминала поток используется и дальнейшие операции не могут быть добавлены.
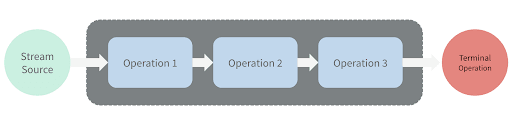
Давайте посмотрим, какие терминальные операции мы можем применить к концу потока Stream:
ForEach и ForEachOrdered
Возможный вариант использования потока может состоять в том, чтобы обновить свойство некоторых или всех элементов или почему бы просто не распечатать их для целей отладки. В любом случае, мы не заинтересованы в сборе или подсчете результата, а скорее в создании побочного эффекта без возврата значения.
Это цель
forEach() или
forEachOrdered() . Они оба принимают
Consumer и прекращает поток, не возвращая ничего. Разница между этими операциями просто в том, что
forEachOrdered() обещает вызвать предоставленного forEachOrdered() в порядке появления элементов в потоке, тогда как
forEach() только обещает вызвать Потребителя, но в любом порядке. Последний вариант полезен для параллельных потоков.
В простом случае, приведенном ниже, мы распечатываем каждый элемент потока в одну строку.
|
1
2
3
4
|
Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", “Lion”) .forEachOrdered(System.out::print); |
Это даст следующий результат:
|
1
|
MonkeyLionGiraffeLemurLion |
|
1
|
<br> |
Сбор элементов
Обычное использование потоков — это создание «корзины» элементов или, более конкретно, создание структур данных, содержащих конкретную коллекцию элементов. Это можно сделать, вызвав операцию терминала
collect() в конце потока, таким образом, попросив его собрать элементы в заданную структуру данных. Мы можем предоставить то, что называется
Collector
Операция collect() и есть несколько различных предопределенных типов, которые можно использовать в зависимости от проблемы. Вот несколько очень полезных опций:
Собрать, чтобы установить
Мы можем собрать все элементы в
Set просто, собирая элементы потока с коллектором
toSet() .
|
1
2
3
4
|
Set<String> collectToSet = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion") .collect(Collectors.toSet()); |
|
1
|
toSet: [Monkey, Lion, Giraffe, Lemur] |
Собрать в список
Точно так же элементы могут быть собраны в
List с использованием
toList() .
|
1
2
3
4
|
List<String> collectToList = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion") .collect(Collectors.toList()); |
|
1
|
collectToList: [Monkey, Lion, Giraffe, Lemur, Lion] |
Собрать в общие коллекции
В более общем случае можно собрать элементы потока в любой
Collection , просто предоставив конструктор для желаемого
Тип Collection . Пример конструкторов
LinkedList::new ,
LinkedHashSet::new и
PriorityQueue::new
|
1
2
3
4
|
LinkedList<String> collectToCollection = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion") .collect(Collectors.toCollection(LinkedList::new)); |
|
1
|
collectToCollection: [Monkey, Lion, Giraffe, Lemur, Lion] |
Собрать в массив
Поскольку массив является контейнером фиксированного размера, а не гибким
Collection , есть веские причины для специальной операции терминала,
toArray() , чтобы создать и сохранить элементы в массиве. Обратите внимание, что простой вызов toArray() приведет к Array Objects поскольку у метода нет способа самостоятельно создать типизированный массив. Ниже мы покажем, как конструктор массива String можно использовать для получения типизированного массива String[] .
|
1
2
3
4
|
String[] toArray = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion") .toArray(String[]::new); |
|
1
|
toArray: [Monkey, Lion, Giraffe, Lemur, Lion] |
Собрать на карту
Возможно, мы захотим извлечь информацию из элементов и предоставить результат в виде Map . Для этого мы используем сборщик toMap() который занимает два
Functions соответствующие преобразователю ключей и преобразователю значений.
В примере показано, как разные животные могут быть связаны с количеством различных символов в их именах. Мы используем промежуточную операцию distinct() чтобы гарантировать, что мы добавляем только уникальные ключи в Map (если ключи не различаются, мы должны предоставить вариант toMap() где должен быть предоставлен распознаватель, который используется для объединения результаты из ключей, которые равны).
|
1
2
3
4
5
6
7
8
|
Map<String, Integer> toMap = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion") .distinct() .collect(Collectors.toMap( Function.identity(), //Function<String, K> keyMapper s -> (int) s.chars().distinct().count()// Function<String, V> valueMapper )); |
|
1
|
toMap: {Monkey=6, Lion=4, Lemur=5, Giraffe=6} (*) |
(*) Обратите внимание, что порядок ключей не определен.
Собрать группировку
Придерживаясь аналогии с ведром, мы можем одновременно обрабатывать более одного ведра. Есть очень полезный Collector имени
groupingBy() которая делит элементы на различные группы в зависимости от некоторого свойства, посредством чего свойство извлекается чем-то, называемым «классификатором». Результатом такой операции является Map . Ниже мы покажем, как животные группируются по первой букве их имени.
|
1
2
3
4
5
6
|
Map<Character, List<String>> groupingByList = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion") .collect(Collectors.groupingBy( s -> s.charAt(0) // Function<String, K> classifier )); |
|
1
|
groupingByList: {G=[Giraffe], L=[Lion, Lemur, Lion], M=[Monkey]} |
Сбор GroupingBy с использованием нисходящего коллектора
В предыдущем примере для значений в Map по умолчанию применялся toList() «нижестоящий коллектор» , собирая элементы каждого сегмента в List . Существует перегруженная версия groupingBy() которая позволяет использовать пользовательский «нисходящий коллектор» для лучшего контроля над получающейся Map . Ниже приведен пример того, как специальный коллектор downstream counting() применяется для подсчета, а не сбора элементов каждого сегмента.
|
1
2
3
4
5
6
7
|
Map<Character, Long> groupingByCounting = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion") .collect(Collectors.groupingBy( s -> s.charAt(0), // Function<String, K> classifier counting() // Downstream collector )); |
|
1
|
groupingByCounting: {G=1, L=3, M=1} |
Вот иллюстрация процесса:
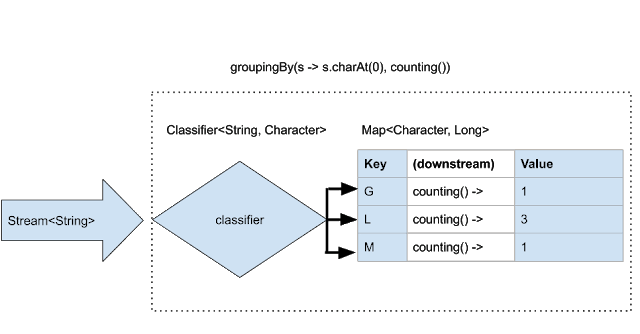
Любой коллектор может быть использован в качестве нижестоящего коллектора. В частности, стоит отметить, что коллектор groupingBy() может принимать нисходящий коллектор, который также является коллектором groupingBy() , что позволяет производить вторичную группировку результата первой операции группировки. В нашем случае с животными, возможно, мы могли бы создать Map<Character, Map<Character, Long>> где первая карта содержит ключи с первым символом, а вторичные карты содержат второй символ в качестве ключей и количество вхождений в качестве значений.
Появление стихий
filter() промежуточной операции filter() — отличный способ удалить элементы, которые не соответствуют данному предикату. Хотя в некоторых случаях мы просто хотим знать, существует ли хотя бы один элемент, который удовлетворяет предикату. Если это так, удобнее и эффективнее использовать anyMatch() . Здесь мы ищем вхождение числа 2:
|
1
|
boolean containsTwo = IntStream.of(1, 2, 3).anyMatch(i -> i == 2); |
|
1
|
containsTwo: true |
Операции для расчета
Несколько операций терминала выводят результат вычисления. Самым простым вычислением, которое мы можем выполнить, является count() который можно применить к любому
Stream. Его можно, например, использовать для подсчета количества животных:
|
1
2
3
4
|
long nrOfAnimals = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur") .count(); |
|
1
|
nrOfAnimals: 4 |
Хотя некоторые терминальные операции доступны только для специальных реализаций Stream, которые мы упоминали в первой статье; IntStream ,
LongStream и LongStream . Имея доступ к потоку такого типа, мы можем просто суммировать все элементы следующим образом:
|
1
|
int sum = IntStream.of(1, 2, 3).sum(); |
|
1
|
sum: 6 |
Или почему бы не вычислить среднее значение целых чисел с помощью .average() :
|
1
|
OptionalDouble average = IntStream.of(1, 2, 3).average(); |
|
1
|
average: OptionalDouble[2.0] |
Или получить максимальное значение с помощью .max() .
|
1
|
int max = IntStream.of(1, 2, 3).max().orElse(0); |
|
1
|
max: 3 |
Как и average() , результат оператора max() является Optional , поэтому, указав .orElse(0) мы автоматически получаем значение, если оно присутствует или возвращается к 0 в качестве значения по умолчанию. То же самое решение может быть применено к усредненному примеру, если мы скорее имеем дело с примитивным типом возврата.
В случае, если нас интересует вся эта статистика, довольно сложно создать несколько одинаковых потоков и применить разные операции с терминалами для каждого из них. К счастью, есть удобная операция под названием summaryStatistics() которая позволяет объединить несколько общих статистических свойств в
SummaryStatistics объекта.
|
1
|
IntSummaryStatistics statistics = IntStream.of(1, 2, 3).summaryStatistics(); |
|
1
|
statistics: IntSummaryStatistics{count=3, sum=6, min=1, average=2.000000, max=3} |
упражнения
Надеюсь, вы знакомы с форматом предоставленных упражнений на данный момент. Если вы только что обнаружили сериал или вам стало немного лень в последнее время (возможно, у вас тоже были свои причины), мы рекомендуем вам клонировать репозиторий GitHub и начать использовать последующие материалы. Содержание этой статьи достаточно, чтобы решить третий блок, который называется MyUnit3Terminal . Соответствующий интерфейс Unit3Terminal содержит JavaDocs, которые описывают предполагаемую реализацию методов в MyUnit3Terminal .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
public interface Unit3Terminal { /** * Adds each element in the provided Stream * to the provided Set. * * An input stream of ["A", "B", "C"] and an * empty input Set will modify the input Set * to contain : ["A", "B", "C"] * * @param stream with input elements * @param set to add elements to */void addToSet(Stream stream, Set set); |
|
1
|
<br> |
Предоставленные тесты (например, Unit3MyTerminalTest) будут действовать как инструмент автоматической оценки, сообщая вам, было ли ваше решение правильным или нет.
Следующая статья
Следующая статья покажет, как все накопленные нами знания могут быть применены к запросам к базе данных.
Подсказка: Прощай, SQL, Hello Streams … До тех пор — удачного кодирования!
Авторы
Пер Минборг
Юлия Густафссон
|
Посмотрите оригинальную статью здесь: Станьте Мастером Java Streams — Часть 3: Операции с терминалами Мнения, высказанные участниками Java Code Geeks, являются их собственными. |