Недавно на работе возник вопрос о тестах между Java и Scala. Может быть, вы наткнулись на мой пост в блоге, потому что вы тоже хотите знать, что быстрее, Java или Scala. Что ж, мне жаль это говорить, но если это вы, вы задаете не тот вопрос. В этом посте я покажу вам, что Scala быстрее, чем Java. После этого я покажу вам, почему вопрос был неправильным и почему мои результаты следует игнорировать. Тогда я объясню, какой вопрос вы должны были задать.
Эталон
Сегодня мы собираемся выбрать очень простой алгоритм для сравнения, алгоритм быстрой сортировки. Я предоставлю реализации как в Scala, так и на Java. Затем с каждым я отсортирую список из 100000 элементов 100 раз и посмотрю, сколько времени потребуется каждой реализации для его сортировки. Итак, начнем с Java:
public static void quickSort(int[] array, int left, int right) {
if (right <= left) {
return;
}
int pivot = array[right];
int p = left;
int i = left;
while (i < right) {
if (array[i] < pivot) {
if (p != i) {
int tmp = array[p];
array[p] = array[i];
array[i] = tmp;
}
p += 1;
}
i += 1;
}
array[right] = array[p];
array[p] = pivot;
quickSort(array, left, p - 1);
quickSort(array, p + 1, right);
}
Сроки этого, сортируя список из 100000 элементов 100 раз на моем MacBook Pro 2012 с Retina Display, занимает 852 мс. Теперь реализация Scala:
def sortArray(array: Array[Int], left: Int, right: Int) {
if (right <= left) {
return
}
val pivot = array(right)
var p = left
var i = left
while (i < right) {
if (array(i) < pivot) {
if (p != i) {
val tmp = array(p)
array(p) = array(i)
array(i) = tmp
}
p += 1
}
i += 1
}
array(right) = array(p)
array(p) = pivot
sortArray(array, left, p - 1)
sortArray(array, p + 1, right)
}
Это выглядит очень похоже на реализацию Java, немного отличается синтаксис, но в целом, тот же. И время для того же эталона? 695ms. Ни один тест не обходится без графика, поэтому давайте посмотрим, как это выглядит визуально:
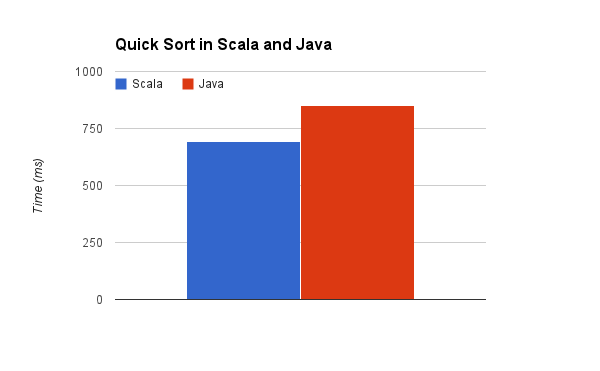
Так что у вас есть это. Scala примерно на 20% быстрее, чем Java. КЭД и все такое.
Неправильный вопрос
Однако это не полная история. Никаких микро-эталонов никогда не бывает. Итак, давайте начнем с ответа на вопрос, почему в этом случае Scala быстрее, чем Java. Теперь Scala и Java работают на JVM. Их исходный код компилируется в байт-код, и с точки зрения JVM он не знает, является ли он Scala или Java, это всего лишь байт-код для JVM. Если мы посмотрим на байт-код скомпилированного кода Scala и Java выше, мы заметим одну ключевую вещь: в коде Java есть два рекурсивных вызова процедуры quickSort, в то время как в Scala есть только один. Почему это? Компилятор Scala поддерживает оптимизацию, называемую рекурсией хвостового вызова, где, если последний оператор в методе является рекурсивным вызовом, он может избавиться от этого вызова и заменить его итерационным решением. Так что’Почему код Scala намного быстрее, чем код Java, именно эта оптимизация рекурсии хвостового вызова. Вы можете отключить эту оптимизацию при компиляции кода Scala, когда я делаю это, теперь она занимает 827 мс, все еще немного быстрее, но не намного. Я не знаю, почему Scala все еще быстрее без рекурсии хвостового вызова.
Это подводит меня к следующему пункту, за исключением нескольких дополнительных нишевых оптимизаций, подобных этой, Scala и Java компилируются в байт-код и, следовательно, имеют практически идентичные характеристики производительности для сопоставимого кода. Фактически, при написании кода Scala вы склонны использовать множество абсолютно одинаковых библиотек между Java и Scala, потому что для JVM это всего лишь байт-код. Вот почему сравнение Scala с Java — неправильный вопрос.
Но это еще не полная картина. Моя реализация быстрой сортировки в Scala не была тем, что мы бы назвали идиоматическим кодом Scala. Он реализован в обязательном порядке, очень ориентирован на производительность — как и должно быть, будучи кодом, который используется для оценки производительности. Но это написано не в стиле, который разработчик Scala писал бы изо дня в день. Вот реализация быстрой сортировки в этом идиоматическом стиле Scala:
def sortList(list: List[Int]): List[Int] = list match {
case Nil => Nil
case head :: tail => sortList(tail.filter(_ < head)) ::: head :: sortList(tail.filter(_ >= head))
}
Если вы не знакомы со Scala, поначалу этот код может показаться излишним, но, поверьте мне, после нескольких недель изучения языка вам будет вполне комфортно читать его, и он окажется гораздо понятнее и проще в обслуживании, чем предыдущее решение. Так как же работает этот код? Ну, ответ ужасный, это занимает 13951 мс, в 20 раз больше, чем другой код Scala. Обязательный график:
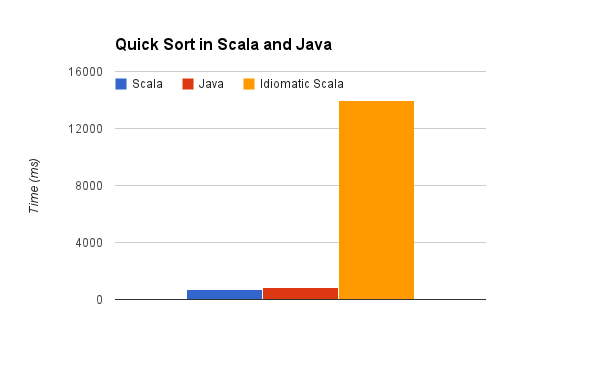
Итак, я говорю, что когда вы пишете Scala «обычным» способом, производительность вашего кода всегда будет ужасной? Ну, это не совсем , как разработчики Scala написать код все время , они не тупые, они знают последствия исполнения своего кода.
Важно помнить, что большинство проблем, которые решают разработчики, не являются быстрой сортировкой, они не являются сложными вычислительными задачами. Например, типичное веб- приложение занимается перемещением данных, а не выполнением сложных алгоритмов. Объем вычислений, который часть кода Java, которую веб-разработчик может написать для обработки веб-запроса, может занять 1 микросекунду из всего запроса, то есть одну миллионную долю секунды. Если эквивалентный код Scala занимает 20 микросекунд, это все равно всего одна пятьдесят тысячная секунды. Весь запрос может занять 20 миллисекунд, включая несколько раз обращение к базе данных. Поэтому использование идиоматического кода Scala увеличит время отклика на 0,1%, что практически ничего.
Таким образом, разработчики Scala, когда они пишут код, будут писать его идиоматическим способом. Как вы можете видеть выше, идиоматический способ ясен и лаконичен. Это легко поддерживать, гораздо проще, чем Java. Однако, когда они сталкиваются с проблемой, которая, по их мнению, требует больших вычислительных ресурсов, они возвращаются к написанию в стиле, больше похожем на Java. Таким образом, они имеют лучшее из обоих миров, с простым в обслуживании идиоматическим кодом Scala для большей части своей кодовой базы и хорошо работающим Java-подобным кодом, где важна производительность.
Правильный вопрос
Так какой вопрос вы должны задавать, сравнивая Scala с Java в области производительности? Ответ во имя Скалы. Скала была построена, чтобы быть » Scala ble language «. Как мы уже видели, эта масштабируемость не входит в микро-тесты. Так где же она будет? Это будет темой будущего поста в блоге, который я напишу, где я покажу некоторые ближе к реальным тестам веб-приложения Scala и веб-приложения Java, но чтобы дать вам представление, ответ заключается в том, как синтаксис и библиотеки Scala, предоставляемые экосистемой Scala, удачно подходят для парадигм программирования, необходимых для написания масштабируемых отказоустойчивых систем. Точный эквивалентный байт-код мог бы быть реализован в Java, но это было бы чудовищным кошмаром невозможности следовать за анонимными внутренними классами, с постоянным страхом случайного изменения неправильного общего состояния и хорошей дозой условий гонки и проблем с видимостью памяти.
Короче говоря, вопрос, который вы должны задать: «Как Scala поможет мне, когда мои серверы упадут из-за непредвиденной нагрузки?» Это вопрос реального мира, на который, я уверен, любой специалист в области ИТ, имеющий опыт работы в реальном мире, хотел бы получить ответ. Оставайтесь с нами для моего следующего сообщения в блоге.