1. Введение
В этой статье мы покажем, как использовать возможности одного из самых популярных инструментов ORM (объектно-реляционного отображения), Hibernate, который облегчает преобразование объектно-ориентированной модели предметной области в традиционную реляционную базу данных. Hibernate — одна из самых популярных платформ Java. По этой причине мы предоставили множество учебников здесь, на Java Code Geeks, большинство из которых можно найти здесь .
На этом уроке мы создадим простое приложение на основе Spring Boot, которое будет использовать всю мощь конфигурации Hibernate вместе с Spring Data JPA. Мы будем использовать базу данных H2 в памяти. Выбор базы данных не должен влиять на определения Spring Data, которые мы создадим, поскольку это является основным преимуществом Hibernate & Spring Data JPA. Это позволяет нам полностью отделить запросы к базе данных от логики приложения.
2. Создание проекта Spring Boot
Мы будем использовать один из самых популярных веб-инструментов для создания примера проекта на этом уроке и не будем делать это из командной строки, мы будем использовать Spring Initializr . Просто откройте ссылку в вашем браузере и изучите все вокруг. Для настройки нашего проекта мы использовали следующую конфигурацию:
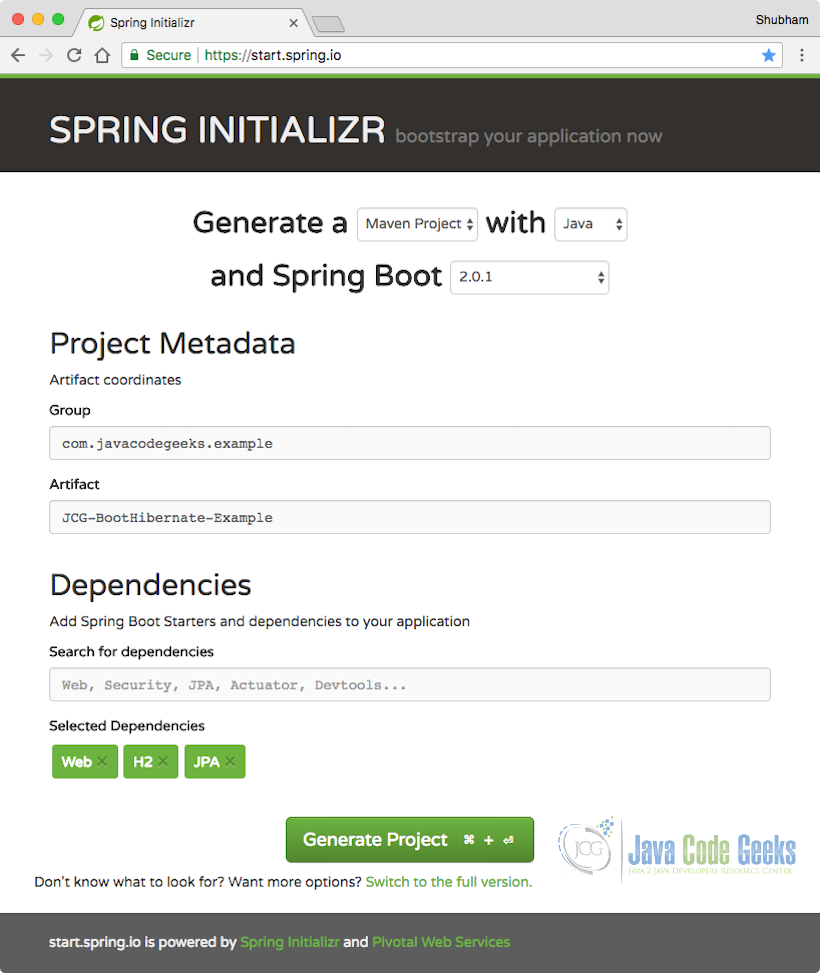
Конфигурация Spring Initializr
Мы добавили три зависимости в этом инструменте:
- Web : это базовая зависимость Spring, которая собирает связанные с конфигурацией и основные аннотации в проекте.
- H2 : поскольку мы используем базу данных в памяти, эта зависимость обязательна.
- Данные JPA : мы будем использовать Spring Data JPA для нашего уровня доступа к данным.
Затем распакуйте загруженный zip-проект и импортируйте его в свою любимую среду IDE.
3. Maven Зависимости
Для начала нам нужно посмотреть, какие зависимости Maven были добавлены в наш проект инструментом, а какие нужны другие. У нас будет следующая зависимость от нашего файла pom.xml :
pom.xml
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
<dependencies><dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId></dependency><dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId></dependency><dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-search-orm</artifactId> <version>5.6.1.Final</version></dependency><dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-entitymanager</artifactId></dependency><dependency> <groupId>com.h2database</groupId> <artifactId>h2</artifactId> <scope>runtime</scope></dependency><dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope></dependency></dependencies> |
Найдите последние связанные с Spring зависимости здесь . Мы добавили зависимости, которые также необходимы для поиска в Hibernate.
Обратите внимание, что мы также добавили сюда зависимость базы данных H2, а также ее область действия и время выполнения, поскольку данные H2 смываются сразу после остановки приложения. В этом уроке мы не будем фокусироваться на том, как на самом деле работает H2, а ограничимся конфигурацией Hibernate. Вы также можете увидеть, как мы можем настроить встроенную консоль H2 с приложением Spring .
Наконец, чтобы понять все JAR-файлы, которые добавляются в проект при добавлении этой зависимости, мы можем запустить простую команду Maven, которая позволяет нам видеть полное дерево зависимостей для проекта, когда мы добавляем в него некоторые зависимости. Вот команда, которую мы можем использовать:
Проверьте дерево зависимостей
|
1
|
mvn dependency:tree |
Когда мы запустим эту команду, она покажет нам следующее дерево зависимостей:
Дерево зависимостей
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
|
[INFO] --------< com.javacodegeeks.example:JCG-BootHibernate-Example >---------[INFO] Building JCG-BootHibernate-Example 1.0-SNAPSHOT[INFO] --------------------------------[ jar ]---------------------------------[INFO][INFO] --- maven-dependency-plugin:2.10:tree (default-cli) @ JCG-BootHibernate-Example ---[INFO] com.javacodegeeks.example:JCG-BootHibernate-Example:jar:1.0-SNAPSHOT[INFO] +- org.springframework.boot:spring-boot-starter-data-jpa:jar:1.5.6.RELEASE:compile[INFO] | +- org.springframework.boot:spring-boot-starter:jar:1.5.6.RELEASE:compile[INFO] | | +- org.springframework.boot:spring-boot:jar:1.5.6.RELEASE:compile[INFO] | | +- org.springframework.boot:spring-boot-autoconfigure:jar:1.5.6.RELEASE:compile[INFO] | | +- org.springframework.boot:spring-boot-starter-logging:jar:1.5.6.RELEASE:compile[INFO] | | | +- ch.qos.logback:logback-classic:jar:1.1.11:compile[INFO] | | | | \- ch.qos.logback:logback-core:jar:1.1.11:compile[INFO] | | | +- org.slf4j:jul-to-slf4j:jar:1.7.25:compile[INFO] | | | \- org.slf4j:log4j-over-slf4j:jar:1.7.25:compile[INFO] | | \- org.yaml:snakeyaml:jar:1.17:runtime[INFO] | +- org.springframework.boot:spring-boot-starter-aop:jar:1.5.6.RELEASE:compile[INFO] | | +- org.springframework:spring-aop:jar:4.3.10.RELEASE:compile[INFO] | | \- org.aspectj:aspectjweaver:jar:1.8.10:compile[INFO] | +- org.springframework.boot:spring-boot-starter-jdbc:jar:1.5.6.RELEASE:compile[INFO] | | +- org.apache.tomcat:tomcat-jdbc:jar:8.5.16:compile[INFO] | | | \- org.apache.tomcat:tomcat-juli:jar:8.5.16:compile[INFO] | | \- org.springframework:spring-jdbc:jar:4.3.10.RELEASE:compile[INFO] | +- org.hibernate:hibernate-core:jar:5.0.12.Final:compile[INFO] | | +- antlr:antlr:jar:2.7.7:compile[INFO] | | \- org.jboss:jandex:jar:2.0.0.Final:compile[INFO] | +- javax.transaction:javax.transaction-api:jar:1.2:compile[INFO] | +- org.springframework.data:spring-data-jpa:jar:1.11.6.RELEASE:compile[INFO] | | +- org.springframework.data:spring-data-commons:jar:1.13.6.RELEASE:compile[INFO] | | +- org.springframework:spring-orm:jar:4.3.10.RELEASE:compile[INFO] | | +- org.springframework:spring-context:jar:4.3.10.RELEASE:compile[INFO] | | +- org.springframework:spring-tx:jar:4.3.10.RELEASE:compile[INFO] | | +- org.springframework:spring-beans:jar:4.3.10.RELEASE:compile[INFO] | | +- org.slf4j:slf4j-api:jar:1.7.25:compile[INFO] | | \- org.slf4j:jcl-over-slf4j:jar:1.7.25:compile[INFO] | \- org.springframework:spring-aspects:jar:4.3.10.RELEASE:compile[INFO] +- org.springframework.boot:spring-boot-starter-web:jar:1.5.6.RELEASE:compile[INFO] | +- org.springframework.boot:spring-boot-starter-tomcat:jar:1.5.6.RELEASE:compile[INFO] | | +- org.apache.tomcat.embed:tomcat-embed-core:jar:8.5.16:compile[INFO] | | +- org.apache.tomcat.embed:tomcat-embed-el:jar:8.5.16:compile[INFO] | | \- org.apache.tomcat.embed:tomcat-embed-websocket:jar:8.5.16:compile[INFO] | +- org.hibernate:hibernate-validator:jar:5.3.5.Final:compile[INFO] | | +- javax.validation:validation-api:jar:1.1.0.Final:compile[INFO] | | \- com.fasterxml:classmate:jar:1.3.3:compile[INFO] | +- com.fasterxml.jackson.core:jackson-databind:jar:2.8.9:compile[INFO] | | +- com.fasterxml.jackson.core:jackson-annotations:jar:2.8.0:compile[INFO] | | \- com.fasterxml.jackson.core:jackson-core:jar:2.8.9:compile[INFO] | +- org.springframework:spring-web:jar:4.3.10.RELEASE:compile[INFO] | \- org.springframework:spring-webmvc:jar:4.3.10.RELEASE:compile[INFO] | \- org.springframework:spring-expression:jar:4.3.10.RELEASE:compile[INFO] +- org.hibernate:hibernate-search-orm:jar:5.6.1.Final:compile[INFO] | \- org.hibernate:hibernate-search-engine:jar:5.6.1.Final:compile[INFO] | +- org.apache.lucene:lucene-core:jar:5.5.4:compile[INFO] | +- org.apache.lucene:lucene-misc:jar:5.5.4:compile[INFO] | +- org.apache.lucene:lucene-analyzers-common:jar:5.5.4:compile[INFO] | \- org.apache.lucene:lucene-facet:jar:5.5.4:compile[INFO] | \- org.apache.lucene:lucene-queries:jar:5.5.4:compile[INFO] +- org.hibernate:hibernate-entitymanager:jar:5.0.12.Final:compile[INFO] | +- org.jboss.logging:jboss-logging:jar:3.3.1.Final:compile[INFO] | +- dom4j:dom4j:jar:1.6.1:compile[INFO] | +- org.hibernate.common:hibernate-commons-annotations:jar:5.0.1.Final:compile[INFO] | +- org.hibernate.javax.persistence:hibernate-jpa-2.1-api:jar:1.0.0.Final:compile[INFO] | +- org.javassist:javassist:jar:3.21.0-GA:compile[INFO] | \- org.apache.geronimo.specs:geronimo-jta_1.1_spec:jar:1.1.1:compile[INFO] +- com.h2database:h2:jar:1.4.196:runtime[INFO] \- org.springframework.boot:spring-boot-starter-test:jar:1.5.6.RELEASE:test[INFO] +- org.springframework.boot:spring-boot-test:jar:1.5.6.RELEASE:test[INFO] +- org.springframework.boot:spring-boot-test-autoconfigure:jar:1.5.6.RELEASE:test[INFO] +- com.jayway.jsonpath:json-path:jar:2.2.0:test[INFO] | \- net.minidev:json-smart:jar:2.2.1:test[INFO] | \- net.minidev:accessors-smart:jar:1.1:test[INFO] | \- org.ow2.asm:asm:jar:5.0.3:test[INFO] +- junit:junit:jar:4.12:test[INFO] +- org.assertj:assertj-core:jar:2.6.0:test[INFO] +- org.mockito:mockito-core:jar:1.10.19:test[INFO] | \- org.objenesis:objenesis:jar:2.1:test[INFO] +- org.hamcrest:hamcrest-core:jar:1.3:test[INFO] +- org.hamcrest:hamcrest-library:jar:1.3:test[INFO] +- org.skyscreamer:jsonassert:jar:1.4.0:test[INFO] | \- com.vaadin.external.google:android-json:jar:0.0.20131108.vaadin1:test[INFO] +- org.springframework:spring-core:jar:4.3.10.RELEASE:compile[INFO] \- org.springframework:spring-test:jar:4.3.10.RELEASE:test[INFO] ------------------------------------------------------------------------[INFO] BUILD SUCCESS[INFO] ------------------------------------------------------------------------ |
Заметили что-то? Так много зависимостей было добавлено, просто добавив четыре зависимости в проект. Spring Boot собирает все связанные зависимости и ничего не оставляет для нас в этом вопросе. Самым большим преимуществом является то, что все эти зависимости гарантированно совместимы друг с другом.
4. Структура проекта
Прежде чем мы продолжим работу и начнем работать над кодом для проекта, давайте представим здесь структуру проекта, которая будет у нас после завершения добавления всего кода в проект:
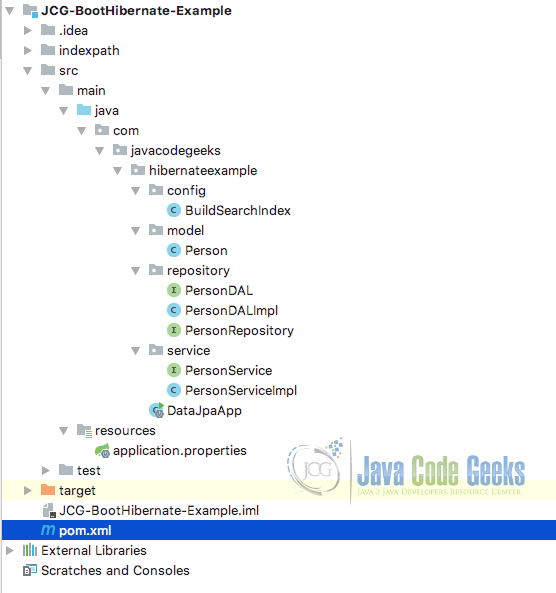
Структура проекта Hibernate
Мы разделили проект на несколько пакетов, чтобы следовать принципу разделения интересов, а код оставался модульным.
Обратите внимание, что каталог indexpath был создан Hibernate для хранения индексов (обсуждается далее в уроке), и он не будет существовать при импорте проекта в вашу среду IDE.
5. Определение спящих диалектов
В файле application.properties мы определяем два свойства, которые используются Spring Data JPA, который присутствует в пути к классам проекта. Spring Boot использует Hibernate в качестве реализации JPA по умолчанию.
application.properties
|
1
2
3
4
5
6
|
## Hibernate Properties# The SQL dialect makes Hibernate generate better SQL for the chosen databasespring.jpa.properties.hibernate.dialect = org.hibernate.dialect.MySQL5InnoDBDialect# Hibernate DDL auto (create, create-drop, validate, update)spring.jpa.hibernate.ddl-auto = update |
Здесь spring.jpa.hibernate.ddl-auto свойство spring.jpa.hibernate.ddl-auto . Благодаря этому Spring Data автоматически создает таблицы базы данных на основе сущностей, которые мы определили в нашем проекте, а столбцы будут создаваться из полей сущностей. Поскольку мы установили свойство для update , всякий раз, когда мы обновляем поле в нашем классе Entity, оно автоматически обновляется в БД, как только мы повторно запускаем проект.
6. Определение сущности
Мы начнем с добавления в наш проект очень простой модели Person . Его определение будет очень стандартным, как:
Person.java
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
|
@Entity@Indexedpublic class Person { @Id @GeneratedValue private Long id; @Field(termVector = TermVector.YES) private String name; @Field private int age; // standard getters and setters @Override public String toString() { return String.format("Person{id=%d, name='%s', age=%d}", id, name, age); }} |
Для краткости мы опускаем стандартные методы получения и установки, но их необходимо создавать, поскольку Джексон использует их во время сериализации и десериализации объекта.
Аннотация @Entity помечает этот POJO как объект, который будет управляться API-интерфейсами Spring Data, а его поля будут обрабатываться как столбцы таблицы (если не помечены как временные), а @Field отмечают, что это поле должно быть проиндексировано Hibernate, чтобы мы могли Запустите запрос полнотекстового поиска по этим полям.
Наконец, мы добавили пользовательскую реализацию для метода toString() чтобы мы могли печатать связанные данные при тестировании нашего приложения.
7. Создание сервисного интерфейса
В этом разделе мы определим интерфейс службы, который будет выступать в качестве контракта для реализации и представлять все действия, которые наша служба должна поддерживать. Эти действия будут связаны с созданием нового пользователя и получением информации, связанной с объектами в базе данных.
Вот определение контракта, которое мы будем использовать:
PersonService.java
|
01
02
03
04
05
06
07
08
09
10
11
12
|
public interface PersonService { Person createPerson(Person person); Person getPerson(Long id); Person editPerson(Person person); void deletePerson(Person person); void deletePerson(Long id); List<Person> getAllPersons(int pageNumber, int pageSize); List<Person> getAllPersons(); long countPersons(); List<Person> fuzzySearchPerson(String term); List<Person> wildCardSearchPerson(String term);} |
Обратите внимание, что в конце контракта также предусмотрено два метода для поддержки поиска в Hibernate.
8. Внедрение Сервиса
Мы будем использовать приведенное выше определение интерфейса для обеспечения его реализации, чтобы мы могли выполнять операции CRUD, связанные с Person мы определили ранее. Мы сделаем это здесь:
PersonServiceImpl.java
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
@Servicepublic class PersonServiceImpl implements PersonService { private final PersonRepository personRepository; private final PersonDAL personDAL; @Autowired public PersonServiceImpl(PersonRepository personRepository, PersonDAL personDAL) { this.personRepository = personRepository; this.personDAL = personDAL; } @Override public Person createPerson(Person person) { return personRepository.save(person); } @Override public Person getPerson(Long id) { return personRepository.findOne(id); } @Override public Person editPerson(Person person) { return personRepository.save(person); } @Override public void deletePerson(Person person) { personRepository.delete(person); } @Override public void deletePerson(Long id) { personRepository.delete(id); } @Override public List<Person> getAllPersons(int pageNumber, int pageSize) { return personRepository.findAll(new PageRequest(pageNumber, pageSize)).getContent(); } @Override public List<Person> getAllPersons() { return personRepository.findAll(); } @Override public long countPersons() { return personRepository.count(); } @Override @Transactional(readOnly = true) public List<Person> fuzzySearchPerson(String term) { return personDAL.fuzzySearchPerson(term); } @Override @Transactional(readOnly = true) public List<Person> wildCardSearchPerson(String term) { return personDAL.wildCardSearchPerson(term); }} |
Мы просто использовали бин DAL для доступа к методам, которые мы определили выше. Мы также использовали @Transactional(readOnly = true) чтобы нам не нужно было открывать сеанс Hibernate, который необходим при выполнении некоторых операций записи, но, поскольку нам нужно только выполнить поиск, мы можем с уверенностью упомянуть свойство readOnly для true .
9. Определение репозитория JPA
Поскольку большинство операций выполняется самим репозиторием JPA, давайте определим это здесь:
PersonRepository.java
|
1
2
3
|
@Repositorypublic interface PersonRepository extends JpaRepository<Person, Long> {} |
Хотя приведенное выше определение интерфейса пустое, у нас все же есть некоторые моменты, которые нам нужно понять:
- Аннотация
@Repositoryпомечает этот интерфейс как Spring Bean, который инициализируется при запуске приложения. С этой аннотацией Spring позаботится о том, чтобы корректно управлять бросками взаимодействия с базой данных - Мы использовали
Personв качестве параметра, чтобы показать, что этот интерфейс JPA будет управлять Person Entity - Наконец, мы также передали тип данных
Longв качестве параметра. Это означает, что сущностьPersonсодержит уникальный идентификатор типа Long
10. Определение интерфейса уровня доступа к данным (DAL)
Хотя мы определили репозиторий JPA, который выполняет все операции CRUD, мы все равно будем создавать слой DAL, который определяет запросы для поиска в произвольном тексте Hibernate. Давайте посмотрим на контракт, который мы определяем:
PersonDAL.java
|
1
2
3
4
|
public interface PersonDAL { List<Person> fuzzySearchPerson(String term); List<Person> wildCardSearchPerson(String term);} |
11. Реализация интерфейса DAL
В интерфейсе DAL, который мы определили, мы будем реализовывать два различных типа поиска в свободном тексте:
- Нечеткий поиск: Нечеткий поиск применим, когда мы хотим найти термины, которые находятся на расстоянии от поискового запроса. Чтобы понять разрыв, давайте рассмотрим пример. Термины
HibernateиHibernatимеют пробел 1 из-за пропускаeв более позднем слове, терминыHibernateиHibernaweтакже имеют пробел 1 как один символ в более позднейHibernawewможет быть заменен для формирования прежней строки. - Поиск с подстановочными знаками: они похожи на операторы SQL, которые имеют подходящую фразу. Как и соответствующие фразы для
Hibernateмогут бытьHiber,bernateи т. Д.
Давайте реализуем оба из них на нашем уровне DAL.
11.1 Определение нечеткого запроса
Мы начнем с реализации нечеткого поиска. Это очень интеллектуальный и сложный поиск, так как для этого требуется токенизация каждого термина, сохраненного в индексах базы данных. Узнайте больше о том, как Lucene делает это здесь .
Давайте реализуем этот поисковый запрос здесь:
Нечеткий запрос
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
@PersistenceContextprivate EntityManager entityManager;@Overridepublic List<Person> fuzzySearchPerson(String term) { FullTextEntityManager fullTextEntityManager = org.hibernate.search.jpa.Search. getFullTextEntityManager(entityManager); QueryBuilder queryBuilder = fullTextEntityManager.getSearchFactory() .buildQueryBuilder().forEntity(Person.class).get(); Query fuzzyQuery = queryBuilder .keyword() .fuzzy() .withEditDistanceUpTo(2) .withPrefixLength(0) .onField("name") .matching(term) .createQuery(); FullTextQuery jpaQuery = fullTextEntityManager.createFullTextQuery(fuzzyQuery, Person.class); return jpaQuery.getResultList();} |
Мы просто использовали расстояние редактирования 2. Это максимальный разрыв, который поддерживается Hibernate и движком Lucene.
11.2 Определение подстановочного запроса
Подстановочный запрос легко понять и реализовать. Это работает так же, как операторы SQL LIKE:
Подстановочный запрос
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
@Overridepublic List<Person> wildCardSearchPerson(String term) { FullTextEntityManager fullTextEntityManager = org.hibernate.search.jpa.Search. getFullTextEntityManager(entityManager); QueryBuilder queryBuilder = fullTextEntityManager.getSearchFactory() .buildQueryBuilder().forEntity(Person.class).get(); Query wildcardQuery = queryBuilder .keyword() .wildcard() .onField("name") .matching("*" + term + "*") .createQuery(); FullTextQuery jpaQuery = fullTextEntityManager.createFullTextQuery(wildcardQuery, Person.class); return jpaQuery.getResultList();} |
Мы применили * к передней и задней части термина, чтобы LIKE мог работать в обоих направлениях.
12. Построение поискового индекса в Hibernate
Прежде чем Hibernate сможет начать сохранять данные индекса, мы должны убедиться, что индекс поиска действительно существует. Это можно сделать, создав его, как только приложение запустится:
BuildSearchIndex.java
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
|
@Componentpublic class BuildSearchIndex implements ApplicationListener<ApplicationReadyEvent> { @PersistenceContext private EntityManager entityManager; @Override public void onApplicationEvent(ApplicationReadyEvent applicationReadyEvent) { try { FullTextEntityManager fullTextEntityManager = Search.getFullTextEntityManager(entityManager); fullTextEntityManager.createIndexer().startAndWait(); } catch (InterruptedException e) { System.out.println( "An error occurred trying to build the serach index: " + e.toString()); } return; }} |
Хотя мы создали поисковый индекс в Hibernate, но где будут храниться индексированные данные. Мы настроим это дальше.
13. Хранение данных индекса
Поскольку Hibernate должен хранить данные индекса, чтобы ему не приходилось перестраивать их при каждом выполнении операции, мы предоставим Hibernate каталог файловой системы, в котором он может хранить эти данные:
application.properties
|
1
2
3
4
5
6
|
# Specify the Lucene Directoryspring.jpa.properties.hibernate.search.default.directory_provider = filesystem# Using the filesystem DirectoryProvider you also have to specify the default# base directory for all indexesspring.jpa.properties.hibernate.search.default.indexBase = indexpath |
directory_provider просто предоставляет тип системы, в которой будут храниться данные, поскольку мы можем даже хранить данные индексации в облаке.
14. Создание Runner из командной строки
Теперь мы готовы запустить наш проект. Чтобы вставить данные образца в
DataJpaApp.java
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
@SpringBootApplicationpublic class DataJpaApp implements CommandLineRunner { private static final Logger LOG = LoggerFactory.getLogger("JCG"); @Autowired private PersonService service; public static void main(String[] args) { SpringApplication.run(DataJpaApp.class, args); } @Override public void run(String... strings) { LOG.info("Current objects in DB: {}", service.countPersons()); Person person = service.createPerson(new Person("Shubham", 23)); LOG.info("Person created in DB : {}", person); LOG.info("Current objects in DB: {}", service.countPersons()); List<Person> fuzzySearchedPersons = service.fuzzySearchPerson("Shubha"); LOG.info("Founds objects in fuzzy search: {}", fuzzySearchedPersons.get(0)); List<Person> wildSearchedPersons = service.wildCardSearchPerson("hub"); LOG.info("Founds objects in wildcard search: {}", wildSearchedPersons.get(0)); person.setName("Programmer"); Person editedPerson = service.editPerson(person); LOG.info("Person edited in DB : {}", person); service.deletePerson(person); LOG.info("After deletion, count: {}", service.countPersons()); }} |
15. Запуск проекта с Maven
С приложением maven легко запустить приложение, просто используйте следующую команду:
Запуск приложения
|
1
|
mvn spring-boot:run |
Как только мы запустим проект, мы увидим следующий результат:

Запустить проект Hibernate
Как и ожидалось, мы сначала создали несколько примеров данных и подтвердили их, вызвав вызов метода count() . Наконец, вызваны методы поиска для получения ожидаемых результатов.
16. Вывод
На этом уроке мы изучили, как мы можем использовать Hibernate для настройки API-интерфейсов Spring Data и как он может помочь нам автоматически создавать таблицы в нашей базе данных, просто определяя классы POJO для наших сущностей. Даже когда мы обновляем наши объекты, нам не нужно беспокоиться о внесении изменений в базу данных!
Мы также запустили примеры с поиском Hibernate, который наш движок Lucene использует для индексации, а Hibernate предоставляет нам полезную оболочку для функций Lucene.
17. Скачать исходный код
Это был пример со Spring Boot и Hibernate ORM Framework.