Эта статья является частью нашего академического курса под названием Apache Lucene Fundamentals .
В этом курсе вы познакомитесь с Lucene. Вы поймете, почему такая библиотека важна, а затем узнаете, как работает поиск в Lucene. Кроме того, вы узнаете, как интегрировать Lucene Search в ваши собственные приложения, чтобы обеспечить надежные возможности поиска. Проверьте это здесь !
Содержание
- 1. Введение
-
- 1.1 Что такое полнотекстовый поиск
- 1.2 Зачем нам нужны полнотекстовые поисковые системы
- 1.3 Как работает Lucene
- 1.4 Базовый рабочий процесс Lucene
- 2. Основные компоненты для индексации
-
- 3. Основные компоненты для поиска
-
- 4. Простое приложение для поиска
-
- 4.1 Создание нового проекта Maven с Eclipse
- 4.2 Maven Зависимости
- 4,3. Простой класс-индексатор
- 4.4. Простой поисковый класс
- 4.5 Скачать исходный код
- 5. Заключительные замечания
1. Введение
В этом курсе мы собираемся погрузиться в Apache Lucene. Lucene — это полнофункциональный полнотекстовый поиск с открытым исходным кодом Это означает, что Lucene поможет вам реализовать механизм полнотекстового поиска, адаптированный к потребностям ваших приложений. Мы собираемся разобраться с Java-вкусом Lucene, но имейте в виду, что существуют API-клиенты для различных языков программирования.
1.1 Что такое полнотекстовый поиск
Пользователи часто хотят получить список документов или источников, которые соответствуют определенным критериям. Например, пользователь библиотеки должен быть в состоянии найти все книги, написанные конкретным автором. Или все книги, в названии которых есть определенное слово или фраза. Или все книги, опубликованные в определенный год от конкретного издателя. Вышеуказанные запросы могут быть легко обработаны хорошо известной реляционной базой данных. Если у вас есть таблица, в которой хранятся кортежи (название, автор, издатель, год публикации) , вышеуказанные поиски могут быть эффективно выполнены. Теперь, что если пользователь захочет получить все документы, которые содержат определенное слово или фразу в их фактическом содержании? Если вы попытаетесь использовать традиционную базу данных и сохранить необработанное содержимое всех документов в поле кортежа, поиск займет недопустимо много времени.
Это связано с тем, что при полнотекстовом поиске поисковая система должна сканировать все слова текстового документа или текстового потока в целом и пытаться сопоставить с ним несколько критериев, например, найти определенные слова или фразы в его содержании. Подобные запросы в классической реляционной базе данных были бы безнадежными. Конечно, многие системы баз данных, такие как MySQL и PostgreSQL, поддерживают полнотекстовый поиск, как нативный, так и с использованием внешних библиотек. Но это не эффективно, не достаточно быстро и не настраивается. Но самая большая проблема — это масштабируемость. Они просто не могут обработать объем данных, который могут обработчики полнотекстового поиска.
1.2 Зачем нам нужны полнотекстовые поисковые системы
Процесс генерирования огромных объемов данных является одной из определяющих характеристик нашего времени и главным следствием технологических достижений. Это идет термином информационной перегрузки . При этом сбор и хранение всех этих данных полезны только в том случае, если вы можете извлечь из них полезную информацию, а также сделать их доступными для конечных пользователей вашего приложения. Самым известным и используемым инструментом для достижения этой цели является, конечно же, поиск.
Можно утверждать, что поиск файлов по слову или фразе так же прост, как и последовательное сканирование сверху вниз, как если бы вы использовали команду grep . На самом деле этого может быть достаточно для небольшого количества документов. Но как насчет огромных файловых систем с миллионами файлов, и если это кажется вам необычным, как насчет веб-страниц, баз данных, электронных писем, репозиториев кода, и это лишь некоторые из них, и как насчет всех их вместе взятых. Становится легко понять, что информация, в которой нуждается каждый отдельный пользователь, может находиться в небольшом документе, где-то в огромном океане различных информационных ресурсов. И поиск этого документа должен казаться таким же легким, как дыхание.
Теперь можно понять, почему полностью настроенные приложения, основанные на поиске, привлекают много внимания и внимания. В дополнение к этому, тот факт, что поиск стал настолько важным аспектом работы конечного пользователя, что для современных веб-приложений, начиная от простых блогов и заканчивая большими платформами, такими как Twitter или Facebook и даже приложениями военного уровня, непостижимо, если у них нет средств поиска. И именно поэтому крупные поставщики не хотят рисковать путаницей в своих функциях поиска и хотят сделать их максимально быстрыми и в то же время максимально простыми. Это привело к необходимости обновить поиск с простой функции до полной платформы. Платформа, обладающая мощью, эффективностью, необходимой гибкостью и индивидуальной настройкой. А Apache Lucene обеспечивает, поэтому используется в большинстве вышеупомянутых приложений.
1.3 Как работает Lucene
Итак, вам должно быть интересно, как Lucene может выполнять очень быстрый полнотекстовый поиск. Не удивительно, что ответ заключается в том, что он использует индекс . Индексы Lucene попадают в категорию инвертированных индексов . Вместо классического индекса, где для каждого документа у вас есть полный список слов (или терминов ), которые он содержит, инвертированные индексы делают это наоборот. Для каждого термина (слова) в документах у вас есть список всех документов, которые содержат этот термин. Это намного удобнее при выполнении полнотекстового поиска.
Причину того, что инвертированные индексы работают так хорошо, можно увидеть на следующих диаграммах. Представьте, что у вас есть 3 очень больших документа. Классический указатель у вас в форме:
Классический указатель:
|
1
2
3
|
Document1 -> { going, to, dive, into, Apache, Lucene, rich, open, source, full, text, search,... }Document2 -> { so, must, wonder, Lucene, can, achieve, very, fast, full, text, search, not,... }Document3 -> { reason, that, inverted, index, work, good ,can, be, seen, following, diagrams,... } |
Для каждого документа у вас есть огромный список всех терминов, которые он содержит. Чтобы найти, содержит ли документ определенный термин, вы должны сканировать, вероятно, последовательно эти обширные списки.
С другой стороны, инвертированный индекс будет иметь такую форму:
Инвертированный индекс:
|
1
2
3
4
5
6
7
|
reason -> { (3,0} }Lucene -> { (1,6), (2,4) }full -> { (1,10),(2,9) }going -> { (1,0) }index -> { (3,3) }search -> { (1,11), (2,10)}... |
Для каждого термина мы поддерживаем список всех документов, содержащих этот термин, после чего указывается позиция термина внутри документа (конечно, дополнительная информация может храниться). Теперь, когда пользователь ищет термин «Lucene», мы можем сразу же ответить, что термин «Lucene» находится внутри Document1 в позиции 6 и внутри Document2 в позиции 4. Подводя итог, инвертированные индексы используют очень большое число очень небольшие списки, которые можно искать мгновенно. В отличие от классического индекса использовалось бы небольшое количество чрезвычайно больших списков, которые невозможно быстро найти.
1.4 Базовый рабочий процесс Lucene
Итак, Lucene нужно сделать некоторую работу до фактического поиска. И, вероятно, это создать индекс. Основной рабочий процесс процесса индексации изображен ниже:
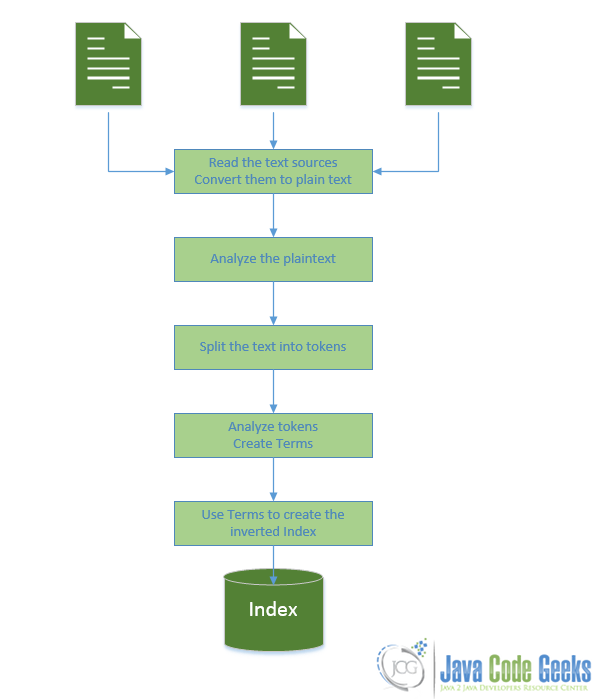
Как вы можете видеть на диаграмме выше:
- Вы кормите его текстовыми документами / источниками
- Для каждого документа он анализирует текст и разбивает его на термины (слова). Между тем он может выполнять все виды анализа в виде простого текста. Вы можете настроить этот шаг в соответствии с потребностями вашего собственного приложения.
- Для каждого срока документов он создает ранее описанные инвертированные списки.
- Теперь индекс готов к поиску. Вы можете писать запросы в разных форматах, и в результате вы получите список всех документов, которые соответствуют критериям, указанным в запросе.
Пока что Lucene кажется очень мощным инструментом, поскольку он может анализировать текст, создавать индексы и выполнять запросы к индексу. Но вы должны выполнить некоторую работу самостоятельно, например, выбрать документы для индексации, организовать и управлять всем процессом и несколькими его аспектами, а также в конечном итоге получить поисковые запросы от пользователей и представить им любые возможные результаты.
2. Основные компоненты для индексации
В этом разделе мы собираемся описать основные компоненты и базовые классы Lucene, используемые для создания индексов.
2.1 Каталоги
Индекс Lucene размещается просто в обычном месте файловой системы или в памяти, когда требуется дополнительная производительность, и вы не хотите, чтобы она постоянно сохранялась на вашем диске. Вы даже можете сохранить свой индекс в базе данных через JDBC. Реализации вышеупомянутых опций расширяют абстрактный класс Directory .
Для простоты давайте просто скажем, что он использует каталог в вашей файловой системе, хотя при использовании памяти или баз данных не так много различий, но обычный каталог, на мой взгляд, более интуитивно понятен. Lucene будет использовать этот каталог для хранения всего, что необходимо для индекса. Вы можете работать с таким каталогом, используя класс FSDirectory , FSDirectory ему произвольный путь вашей файловой системы (при работе с памятью вы используете RAMDirectory ). Класс FSDirectory — это просто абстракция над обычными классами манипулирования Java-файлами.
Вот как вы можете создать FSDirectory :
|
1
|
Directory directory = FSDirectory.open( new File("C:/Users/nikos/Index")); |
RAMDirectory как вы можете создать RAMDirectory :
|
1
|
Directory ramDirectory = new RAMDirectory(); |
2.2 Документы
Как вы помните, мы сказали, что вы несете ответственность за выбор документов (текстовые файлы, PDF-файлы, документы Word и т. Д.) И любых текстовых источников, которые вы хотите сделать доступными для поиска и, таким образом, проиндексированными. Для каждого документа, который вы хотите проиндексировать, вы должны создать один объект Document который его представляет. На этом этапе важно понимать, что документы являются компонентами индексации, а не фактическими источниками текста. Естественно, поскольку Document представляет собой отдельный физический источник текста, он является структурной единицей индекса. После создания такого документа вы должны добавить его в указатель. Позже, при отправке поиска, в результате вы получите список объектов Document которые удовлетворяют вашему запросу.
Вот как вы можете создать новый пустой Document :
|
1
|
Document doc = new Document(); |
Теперь пришло время заполнить документ Fields .
2.3 Поля
Объекты Document заполняются коллекцией Fields . Field — это просто пара элементов (имя, значение) . Таким образом, при создании нового объекта Document необходимо заполнить его такими парами. Field может быть сохранено в индексе, и в этом случае и имя, и значение поля буквально сохраняются в индексе. Кроме того, Field может быть проиндексировано или, если быть более точным, инвертировано , в этом случае значение поля анализируется и токенизируется в Terms и становится доступным для поиска. Term представляет собой слово из текста значения Field . Field может быть сохранено и проиндексировано / инвертировано , но вам не нужно сохранять поле, чтобы сделать его индексированным / инвертированным. Сохранение поля и индексация / инвертирование поля — это две разные, независимые вещи.
Как я упоминал ранее, при развертывании поиска вы получите список объектов Document (представляющих физические текстовые источники), которые удовлетворяют вашему запросу. Если вы хотите иметь доступ к фактическому значению Field , вы должны объявить это Field сохраненным. Обычно это полезно, когда вы хотите сохранить имя файла, который представляет этот Document , дату последнего изменения, полный путь к файлу или любую дополнительную информацию об источнике текста, к которому вы хотите иметь доступ. Например, если источником текста, который вы индексируете, является электронная почта, ваш объект Document , представляющий эту электронную почту, может иметь следующие поля:
Пример документа, представляющего электронную почту:
|
поле |
Хранится |
индексированный |
|
|
название |
Значение |
||
|
заглавие |
Электронная почта из примера |
да |
нет |
|
Место нахождения |
местонахождение электронного письма |
да |
нет |
|
От |
example@javacodegeeks.com |
да |
нет |
|
к |
foo@example.com |
да |
нет |
|
Тема |
связь |
да |
нет |
|
тело |
Всем привет ! Приятно познакомиться … |
нет |
да |
В приведенном выше документе я решил индексировать / инвертировать тело письма, но не хранить его. Это означает, что тело письма будет проанализировано и разбито на токены для поиска, но оно не будет буквально сохранено в индексе. Вы можете следовать этой тактике, когда объем содержимого вашего текстового источника очень велик и вы хотите сэкономить место. С другой стороны, я решил сохранить, но не индексировать все остальные поля. Когда я выполняю поиск, поиск выполняется только по телу , а все остальные поля не учитываются при поиске, поскольку они не индексируются.
Если вышеупомянутые токенизированные термины органа удовлетворяют запросу, этот Document будет включен в результаты. Теперь, когда вы получаете доступ к этому извлеченному Document , вы можете просматривать только его сохраненные Fields и их значения. Таким образом, фактическое тело файла не будет доступно вам через объект Document , несмотря на возможность поиска. Вы можете видеть только Fields « Заголовок», «Местоположение», «От», «К теме» . Хранение местоположения этого электронного письма поможет мне получить доступ к его текущему содержанию. Конечно, вы можете также сохранить тело письма, если хотите извлечь его через объект Document и таким образом сделать его доступным для поиска и хранения (то же самое относится и к другим полям).
Итак, давайте посмотрим, как бы вы создали вышеупомянутый Document . Для создания сохраненных полей мы будем использовать класс StoredField . И чтобы создать несохраненное и проиндексированное тело текста, мы будем использовать класс TextField .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
Document doc = new Document();Field title = new StoredField("fileName", "Email from example");doc.add(title);Field location = new StoredField("location", "C:/users/nikos/savedEmail");doc.add(location);Field from = new StoredField("from", "example@javacodegeks.com");doc.add(from);Field to = new StoredField("to", "foo@example.com");doc.add(to);Field body = new TextField("body", new FileReader(new File("C:/users/nikos/savedEmail")));doc.add(body); |
Как видите, мы указали FileReader в качестве значения поля "body" . Этот FileReader будет использоваться на этапе анализа для извлечения простого текста из этого источника. После извлечения простого текста из файла специальные компоненты Lucene проанализируют его и разделят на проиндексированные термины.
2.4 Условия
Термин представляет собой слово из текста. Термины извлекаются из анализа и токенизации значений Поля, поэтому Term является единицей поиска. Термины состоят из двух элементов: фактического текстового слова (это может быть что угодно, от буквального слова до адреса электронной почты, дат и т. Д.) И названия поля, в котором появилось это слово.
Нет необходимости в токенизации и анализе поля для извлечения терминов из него. В предыдущем примере, если вы хотите проиндексировать Field From , вам не нужно его токенизировать. Адрес электронной почты example@javacodegeeks.com может служить термином .
2.5 Анализаторы
Analyzer является одним из важнейших компонентов процесса индексации и поиска. Он несет ответственность за принятие простого текста и преобразование его в условия поиска. Теперь важно понимать, что анализаторы работают с вводом простого текста. Ответственность за обеспечение синтаксического анализатора, способного преобразовывать текстовый источник, такой как страница HTML или файл из вашей файловой системы, в обычный текст, лежит на программисте. Этот парсер обычно является Reader. Например, в случае файлов это может быть FileReader.
Анализатор, внутренне использует токенизатор . Tokenizer может взять в качестве входных данных вышеупомянутый Reader и использовать его для извлечения простого текста из определенного источника (например, из файла). После получения простого текста токенизатор просто разбивает текст на слова. Но анализатор может сделать гораздо больше, чем просто разделение текста. Он может выполнять несколько видов анализа текста и слов, таких как:
- Основа: замена слов их основами. Например, в английском языке стебель «апельсины» — «апельсин». Поэтому, если конечный пользователь ищет «оранжевый», будут получены документы, содержащие «апельсины» и «оранжевый».
- Остановить фильтрацию слов: Слова типа «the», «and» и «a» не представляют особого интереса при выполнении поиска, и их можно также считать «шумом». Удаление их приведет к лучшей производительности и более точным результатам.
- Нормализация текста: удаляет акценты и другие маркировки символов.
- Расширение синонимов: добавляет синонимы в той же позиции токена, что и текущее слово.
Это только некоторые инструменты анализа, встроенные в классы Lucenes Analyzer. Наиболее часто используемый встроенный анализатор — это StandardAnalyzer, который может удалять стоп-слова, преобразовывать слова в нижний регистр, а также выполнять поиск по словам. Как вы знаете, разные языки имеют разные правила грамматики. Сообщество Lucene пытается внедрить как можно больше грамматик для разных языков. Но, тем не менее, если ни один из встроенных анализаторов Lucene не подходит для вашего приложения, вы можете создать свой собственный.
2.6 Взаимодействие с индексом
До сих пор мы видели, как создать Directory индексов, создать Document и добавить в него Fields . Теперь нам нужно записать Document в Directory и, таким образом, добавить его в индекс. Это также шаг, на котором Analyzers и Tokenizers играют свою роль.
Как и следовало ожидать, в Lucene нет специального класса с именем Index (или что-то в этом роде). Взаимодействие с индексом осуществляется с помощью IndexWriter , когда вы хотите IndexWriter содержимое в свой индекс (и обычно манипулировать им), IndexReader, когда вы хотите читать из вашего индекса, и IndexSearcher , когда вы хотите искать в индексе курс.
Теперь давайте посмотрим, как мы можем создать IndexWriter мы хотим:
|
1
2
3
4
5
6
7
|
Directory directory = FSDirectory.open( new File("C:/Users/nikos/Index"));Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_46);IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_46, analyzer);IndexWriter indexWriter = new IndexWriter(directory , config); |
Для этого мы решили использовать экземпляр StandardAnalyzer . Его конструктор принимает Version.LUCENE_46 в качестве аргумента. Это полезно для обнаружения зависимостей совместимости между несколькими выпусками Lucene. Имейте в виду, что StandardAnalyzer внутренне использует StandardTokenizer . Затем мы создаем экземпляр IndexWriterConfig . Это вспомогательный класс, который может содержать все параметры конфигурации для IndexWriter . Как видите, мы указали, что мы хотим, чтобы наш IndexWriter использовал ранее созданный analyzer и для него была установлена соответствующая версия. Наконец, мы создаем экземпляр IndexWriter . В аргументах конструктора мы даем экземпляр FSDirectory и ранее созданные параметры конфигурации.
Теперь вы можете добавить ранее созданный Document в индекс, используя вышеупомянутый IndexWriter :
|
1
|
indexWriter.addDocument(doc); |
Вот и все. Теперь, когда addDocument , addDocument все ранее описанные операции:
-
TokenizerиспользуетFileReaderдля чтения файла и преобразует его в обычный текст. Затем он разбивает его на токены. - Между тем,
Analyzerможет выполнять все виды синтаксического и грамматического анализа простого текста, а затем отдельных токенов. - Из анализа токенов создаются
Termsкоторые используются для создания инвертированного индекса. - Наконец, все необходимые файлы, содержащие всю информацию для
Documentи индекса, записываются по указанному пути:"C:/Users/nikos/Index".
Наш документ теперь проиндексирован. Тот же процесс выполняется для каждого Document вы добавляете в индекс.
Теперь, когда все стало понятнее, давайте посмотрим на процесс индексации с классами, которые мы использовали на диаграмме:
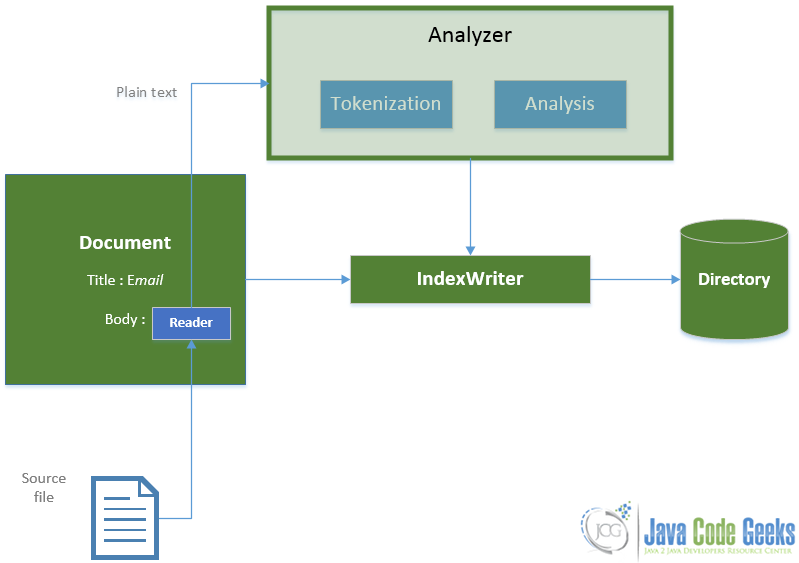
Как вы видете:
- Мы передаем объект
DocumentвIndexWriter. - Он использует
Analyzerдля генерацииTermsиз простого текста, полученногоReader. - Затем он пишет все, что необходимо для обновления индекса в
Directory.
Индексирование — сложная задача при создании поисковой системы, потому что вы должны:
- Выберите документы и источники текста, которые вы хотите проиндексировать.
- Предоставьте классы Reader, которые читают текстовые источники и преобразуют их в обычный текст. Существует множество встроенных классов (или внешних библиотек), которые могут читать большое количество форматов документов. Но если ни один из них не подходит для ваших документов, вам придется написать свой собственный Reader, который будет анализировать их и преобразовывать в простой текст.
- Выберите политику токенизации и анализа, которая соответствует потребностям вашего приложения. Подавляющее большинство приложений будет отлично работать с StandardAnalyzer и StandardTokenizer. Но возможно, что вы захотите настроить шаг анализа немного дальше, и для этого потребуется проделать определенную работу.
- Решите, какие поля использовать и какие из них хранить и / или индексировать.
3. Основные компоненты для поиска
В этом разделе мы опишем основные компоненты и базовые классы Lucene, используемые для выполнения поиска. Поиск является целью таких платформ, как Lucene, поэтому он должен быть максимально гибким и простым.
3.1 QueryBuilder и Query
В Lucene каждый запрос, передаваемый в индекс, является объектом запроса. Поэтому, прежде чем фактически взаимодействовать с Индексом для выполнения поиска, вы должны создать такие объекты.
Все начинается со строки запроса. Это может быть как строки запроса, которые вы ставите на хорошо известные поисковые системы, такие как Google. Это может быть произвольная или более структурированная фраза, как мы увидим в следующем уроке. Но было бы бесполезно просто посылать эту необработанную строку для поиска в индексе. Вы должны обработать это, как вы сделали с индексированным простым текстом. Вы должны разбить строку запроса на слова и создать условия поиска. Предположительно, это можно сделать с помощью анализатора.
Примечание. Важно отметить, что вы должны использовать тот же подкласс Analyzer, чтобы исследовать запрос, что и тот, который вы использовали в процессе индексирования, чтобы исследовать простой текст.
Вот как вы можете создать простой запрос, обработанный с помощью StandardAnalyzer:
|
1
2
3
4
5
|
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_46);QueryBuilder builder = new QueryBuilder(analyzer);Query query = builder.createBooleanQuery("content", queryStr); |
Мы связываем объект QueryBuilder с экземпляром StandarAnalyzer. Теперь вы можете использовать этот экземпляр QueryBuilder для создания объектов Query.
Запрос является абстрактным классом, и доступно много конкретных подклассов, например:
-
TermQueryкоторый ищет документы, содержащие определенный термин. -
BooleanQueryкоторый создает логические комбинации других запросов -
WildcardQueryдля реализации поиска по шаблону, например, для строк запроса, таких как «* abc *«. -
PhraseQueryдля поиска целых фраз, а не только для отдельных терминов. -
PrefixQueryпоиск по терминам с предопределенным префиксом.
Все эти различные Query будут определять характер поиска, который будет выполняться по вашему индексу. И каждый из них может быть получен через этот экземпляр QueryBuilder . В нашем примере мы решили использовать метод createBooleanQuery . Требуется два аргумента. Первым является имя Field чье (обязательно индексированное и, вероятно, токенизированное) значение будет подвергаться поиску. И вторая строка запроса, которая будет проанализирована с помощью StandardAnalyzer . createBooleanQuery может возвращать TermQuery или BooleanQuery зависимости от синтаксиса строки запроса.
3.2 IndexReader
Предположительно, чтобы выполнить поиск в индексе, сначала вы должны открыть его. Вы можете использовать IndexReader, чтобы открыть и получить к нему доступ. Все процессы, которым необходимо извлечь данные из индекса, проходят через этот абстрактный класс.
Открыть индекс с помощью IndexReader очень просто:
|
1
2
3
|
Directory directory = FSDirectory.open(new File("C:/Users/nikos/Index"))IndexReader indexReader = DirectoryReader.open(directory); |
Как вы видите, мы используем DirectoryReader, чтобы открыть каталог, в котором хранится индекс. DirectoryReader возвращает дескриптор для индекса, и это то, что IndexReader .
3.3 IndexSearcher
IndexSearcher — это класс, который вы используете для поиска по одному индексу. Это связано с IndexReader .
Вот как вы можете его создать:
|
1
2
3
|
IndexReader indexReader = DirectoryReader.open(directory);IndexSearcher searcher = new IndexSearcher(indexReader); |
Вы используете IndexSearcher для передачи объектов Query в IndexReader . Вот как:
|
1
2
3
|
Query query = builder.createBooleanQuery("content", queryStr);TopDocs topDocs =searcher.search(query, maxHits); |
Для public TopDocs search(Query query, int n) мы использовали public TopDocs search(Query query, int n) IndexSearcher . Этот метод принимает два аргумента. Первый объект Query . Второе — это целое число, которое устанавливает ограничение на количество возвращаемых результатов поиска. Например, если у вас есть 10000 документов, удовлетворяющих вашему запросу, вы можете не захотеть возвращать их все. Вы можете заявить, что хотите только первые n результатов. Наконец, этот метод возвращает экземпляр TopDocs .
3.4 TopDocs
Класс TopDocs представляет обращения, которые удовлетворяют вашему запросу. TopDocs имеет public ScoreDoc[] класса public ScoreDoc[] .
3.5 ScoreDoc
SocreDoc представляет собой хит для запроса. Это состоит из :
-
public int docполеpublic int doc, то есть идентификаторDocumentкоторый удовлетворил запрос. - И
public float scoreполе сpublic float score, то есть результат, достигнутыйDocumentв запросе.
Формула оценки является очень важной и сложной частью любой поисковой платформы, и именно это делает Lucene такой хорошей работой. Эта формула используется для предоставления показателя релевантности для извлеченного документа. Чем выше оценка, тем больше релевантности этого документа к вашему запросу. Это помогает характеризовать «хорошие» и «плохие» документы и гарантирует, что вам будут предоставлены высококачественные результаты, максимально приближенные к тем документам, которые вам действительно нужны. Вы можете найти некоторую полезную информацию о выигрыше в документации по классу подобия текущей версии, а также в более старой версии, а также в этой статье по поиску информации .
4. Простое приложение для поиска
Мы собираемся создать простое поисковое приложение, которое продемонстрирует основные этапы индексации и поиска. В этом приложении мы будем использовать входную папку, которая содержит кучу исходных файлов Java. Каждый файл в этом документе будет обработан и добавлен в индекс. Затем мы собираемся выполнить простые запросы по этому индексу, чтобы увидеть, как он работает.
Мы собираемся использовать:
- Затмение Kepler 4.3 в качестве нашей IDE.
- JDK 1.7.
- Maven 3, чтобы построить наш проект.
- Lucene 4.6.0, последняя версия Lucene.
Прежде всего, давайте создадим наш проект Maven с Eclipse.
4.1 Создание нового проекта Maven с Eclipse
Откройте Eclipse и перейдите в Файл -> Создать -> Другое -> Maven -> Проект Maven и нажмите Далее
В следующем окне выберите опцию «Создать простой проект (пропустить выбор архетипа)» и нажмите «Далее»:

В следующем окне заполните Group Id и Artifact Id, как показано на рисунке ниже, и нажмите Finish:
Будет создан новый проект Maven со следующей структурой:
4.2 Maven Зависимости
Откройте pom.xml и добавьте зависимости, необходимые для использования библиотек Lucene:
pom.xml:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" <modelVersion>4.0.0</modelVersion> <groupId>com.javacodegeeks.enterprise.lucene.index</groupId> <artifactId>LuceneHelloWorld</artifactId> <version>0.0.1-SNAPSHOT</version> <dependencies> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>4.6.0</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-common</artifactId> <version>4.6.0</version> </dependency> </dependencies></project> |
Как видите, мы импортируем lucene-core-4.6.0.jar который предоставляет все основные классы, и lucene-analyzers-common-4.6.0.jar , который предоставляет все классы, необходимые для анализа текста.
4,3. Простой класс-индексатор
Чтобы создать этот класс, перейдите в Package Explorer из Eclipse. Под src/java/main создайте новый пакет с именем com.javacodegeeks.enterprise.lucene.index . Под вновь созданным пакетом создайте новый класс с именем SimpleIndexer .
Давайте посмотрим код этого класса, который будет выполнять индексацию:
SimpleIndexer.java:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
package com.javacodegeeks.enterprise.lucene.index;import java.io.File;import java.io.FileReader;import java.io.IOException;import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.document.StoredField;import org.apache.lucene.document.TextField;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.index.IndexWriterConfig;import org.apache.lucene.store.FSDirectory;import org.apache.lucene.util.Version;public class SimpleIndexer { private static final String indexDirectory = "C:/Users/nikos/Desktop/LuceneFolders/LuceneHelloWorld/Index"; private static final String dirToBeIndexed = "C:/Users/nikos/Desktop/LuceneFolders/LuceneHelloWorld/SourceFiles"; public static void main(String[] args) throws Exception { File indexDir = new File(indexDirectory); File dataDir = new File(dirToBeIndexed); SimpleIndexer indexer = new SimpleIndexer(); int numIndexed = indexer.index(indexDir, dataDir); System.out.println("Total files indexed " + numIndexed); } private int index(File indexDir, File dataDir) throws IOException { Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_46); IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_46, analyzer); IndexWriter indexWriter = new IndexWriter(FSDirectory.open(indexDir), config); File[] files = dataDir.listFiles(); for (File f : files) { System.out.println("Indexing file " + f.getCanonicalPath()); Document doc = new Document(); doc.add(new TextField("content", new FileReader(f))); doc.add(new StoredField("fileName", f.getCanonicalPath())); indexWriter.addDocument(doc); } int numIndexed = indexWriter.maxDoc(); indexWriter.close(); return numIndexed; }} |
В приведенном выше классе мы указали нашу входную папку, в которую помещаются текстовые файлы в C:/Users/nikos/Desktop/LuceneFolders/LuceneHelloWorld/SourceFiles , а также папку, в которой будет сохранен индекс, в C:/Users/nikos/Desktop/LuceneFolders/LuceneHelloWorld/Index .
В методе index сначала мы создаем новый экземпляр StandardAnalyzer и новый экземпляр IndexWriter . IndexeWriter будет использовать StrandardAnalyzer для анализа текста и сохранит индекс в FSDirectory указывающем на вышеупомянутый путь индекса.
Интересный момент в цикле for . Для каждого файла в исходном каталоге:
- Мы создаем новый экземпляр
Document. - Мы добавляем новый
Filed, точнееTextField, который представляет содержимое файла. Помните, чтоTextFieldиспользуется для создания поля, в котором его значение будет размечено и проиндексировано, но не сохранено . - Мы добавляем еще одно
Field, на этот разStoredFiled, которое содержит имя файла. Помните, чтоStoredFieldпредназначен для полей, которые просто хранятся , не индексируются и не маркируются . Поскольку мы сохраняем имя файла как его полный путь, мы можем позже использовать его для доступа, представления и проверки его содержимого. - Затем мы просто добавляем
Documentв индекс.
После цикла:
- Мы вызываем
maxDoc()IndexWriterкоторый возвращает количество проиндексированныхDocuments. - Мы закрываем
IndexWriter, потому что он нам больше не нужен, и поэтому система может вернуть свои ресурсы.
Когда я запускаю этот код, вот результат, который он производит:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
Indexing file C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\Cart.javaIndexing file C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\CartBean.javaIndexing file C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\MyServlet.javaIndexing file C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\Passivation.javaIndexing file C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\PassivationBean.javaIndexing file C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\Product.javaIndexing file C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\PropertyObject.java<Indexing file C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\SecondInterceptor.javaIndexing file C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\ShoppingCartServlet.javaIndexing file C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\SimpleEJB.javaIndexing file C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\SimpleIndexer.javaIndexing file C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\SimpleInterceptor.javaIndexing file C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\SimpleSearcher.javaIndexing file C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\TestSerlvet.javaTotal files indexed 14 |
Вот папка индекса в моей системе. Как видите, создано несколько специальных файлов (подробнее об этом на следующих уроках):

Теперь давайте поищем этот индекс.
4.4. Простой поисковый класс
Чтобы создать этот класс, перейдите в Package Explorer из Eclipse. Под src/java/main создайте новый пакет с именем com.javacodegeeks.enterprise.lucene.search . Под вновь созданным пакетом создайте новый класс с именем SimpleSearcher .
Чтобы получить более четкое представление об окончательной структуре проекта, взгляните на изображение ниже:
Давайте посмотрим код этого класса, который будет выполнять поиск:
SimpleSearcher.java:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
package com.javacodegeeks.enterprise.lucene.search;import java.io.File;import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.index.DirectoryReader;import org.apache.lucene.index.IndexReader;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TopDocs;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.apache.lucene.util.QueryBuilder;import org.apache.lucene.util.Version;public class SimpleSearcher { private static final String indexDirectory = "C:/Users/nikos/Desktop/LuceneFolders/LuceneHelloWorld/Index"; private static final String queryString = "private static final String"; private static final int maxHits = 100; public static void main(String[] args) throws Exception { File indexDir = new File(indexDirectory); SimpleSearcher searcher = new SimpleSearcher(); searcher.searchIndex(indexDir, queryString); } private void searchIndex(File indexDir, String queryStr) throws Exception { Directory directory = FSDirectory.open(indexDir); IndexReader indexReader = DirectoryReader.open(directory); IndexSearcher searcher = new IndexSearcher(indexReader); Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_46); QueryBuilder builder = new QueryBuilder(analyzer); Query query = builder.createPhraseQuery("content", queryStr); TopDocs topDocs =searcher.search(query, maxHits); ScoreDoc[] hits = topDocs.scoreDocs; for (int i = 0; i < hits.length; i++) { int docId = hits[i].doc; Document d = searcher.doc(docId); System.out.println(d.get("fileName") + " Score :"+hits[i].score); } System.out.println("Found " + hits.length); }} |
В методе searchIndex мы передаем каталог индекса и строку запроса в качестве аргументов. Поэтому я собираюсь искать «приватную статическую финальную строку». Помните, что файлы, которые я проиндексировал, были исходными файлами Java,
Код довольно понятен:
- Мы открываем каталог index и получаем
IndexReaderиIndexSearcher. - Затем мы используем
QueryBuilder, предоставленныйStrandardAnalyzer, для создания нашего объектаQuery. Мы использовалиcreateBooleanQueryдля получения объектаQuery. Наша строка запроса не имеет логического формата (как мы увидим в следующем уроке), поэтому метод создастTermQueriesдля проанализированных и токенизированных терминов строки запроса. - Затем мы используем метод поиска
IndexSearcherдля выполнения фактического поиска. - Мы получаем
ScoreDocsкоторый удовлетворил запрос изTopDocsвозвращенного методомsearch. Для каждого идентификатора в этом массивеScoreDocsмы получаем соответствующийDocumentизIndexSearcher. - Из этого
Document, используя методget, мы получаем имя файла, которое хранится в значении поля «fileName». - Наконец мы печатаем имя файла и результат, которого он достиг.
Давайте запустим программу и посмотрим, что получится :
|
01
02
03
04
05
06
07
08
09
10
11
|
C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\Product.java Score :0.6318474C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\PropertyObject.java Score :0.58126664C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\SimpleSearcher.java Score :0.50096965C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\SimpleIndexer.java Score :0.31737804C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\ShoppingCartServlet.java Score :0.3093049C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\TestSerlvet.java Score :0.2769966C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\MyServlet.java Score :0.25359935C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\SimpleEJB.java Score :0.05496885C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\PassivationBean.java Score :0.03272106C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\CartBean.java Score :0.028630929Found 10 |
Важно понимать, что эти файлы не обязательно содержат целую фразу "private static final String" . Интуитивно понятно, что документы с более высоким баллом содержат большинство слов этого предложения и чаще, чем документы с меньшим количеством баллов. Конечно, формула выигрыша гораздо сложнее, как мы уже говорили ранее.
Например, если вы измените:
|
1
|
Query query = builder.createBooleanQuery("content", queryStr); |
в
|
1
|
Query query = builder.createPhraseQuery("content", queryStr); |
вся фраза будет найдена. Будут возвращены только документы, содержащие всю фразу. Когда вы запускаете код с этим незначительным изменением, вот вывод :
|
1
2
3
4
5
|
C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\Product.java Score :0.9122286C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\SimpleSearcher.java Score :0.7980338C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\SimpleIndexer.java Score :0.4561143C:\\Users\\nikos\\Desktop\\LuceneFolders\\LuceneHelloWorld\\SourceFiles\\ShoppingCartServlet.java Score :0.36859602Found 4 |
Эти файлы содержат всю строку запроса "private static final String" в своем содержимом.
4.5 Скачать исходный код
Вы можете скачать проект Eclipse этого примера здесь: LuceneHelloWorld.zip
5. Заключительные замечания
Важно отметить, что IndexReader считывает «изображение», которое имеет индекс в тот момент, когда он его открывает. Итак, если ваше приложение имеет дело с текстовыми источниками, которые меняются за короткие промежутки времени, возможно, вам придется повторно индексировать эти файлы во время выполнения. Но вы хотите быть уверены, что изменения отражаются при поиске по индексу, когда ваше приложение все еще работает и вы уже открыли IndexReader (который сейчас устарел). В этом случае вам необходимо получить обновленный IndexReader например:
|
1
2
|
//indexReader is the old IndexReaderIndexReader updatedIndexReader = DirectoryReader.openIfChanged(indexReader); |
Это гарантирует, что вы получите новый более обновленный IndexReader , но только если индекс изменился. Кроме того, если вы хотите выполнять быстрый поиск в режиме реального времени (например, для потоковых данных), вы можете получить свой IndexReader следующим образом:
|
1
2
|
//indexWriter is your IndexWriterIndexReader nearRealTimeIndexReader = DirectoryReader.open(indexWriter,true); |
По соображениям производительности IndexWriter не IndexWriter изменения индекса немедленно на диск.Вместо этого он использует буферы и сохраняет изменения асинхронно. Открыв IndexReaderподобное в приведенном выше фрагменте, IndexWriterон получает немедленный доступ к буферам записи , и, таким образом, он получает мгновенный доступ к обновлениям индекса.
Наконец, стоит упомянуть, что IndexWriterон потокобезопасен, поэтому вы можете использовать один и тот же экземпляр во многих потоках, чтобы добавить Documentsодин конкретный индекс. То же самое относится к IndexReaderи IndexSearcher. Многие потоки могут использовать один и тот же экземпляр этих классов для одновременного чтения или поиска по одному и тому же индексу.