Итак, как дозирование может волшебным образом уменьшить задержку? Все сводится к тому, какие алгоритмы и структуры данных используются. В распределенной среде нам часто приходится группировать сообщения / события в сетевые пакеты для достижения большей пропускной способности. Мы также используем аналогичные методы в буферизации записи в хранилище, чтобы уменьшить количество операций ввода-вывода в секунду . Это хранилище может быть файловой системой с поддержкой блочных устройств или реляционной базой данных. Большинство устройств ввода-вывода могут обрабатывать лишь небольшое количество операций ввода-вывода в секунду, поэтому лучше выполнять эти операции эффективно. Многие подходы к пакетированию включают ожидание истечения времени ожидания, и это по самой своей природе увеличит задержку. Пакет также может быть заполнен до истечения времени ожидания, что делает задержку еще более непредсказуемой.
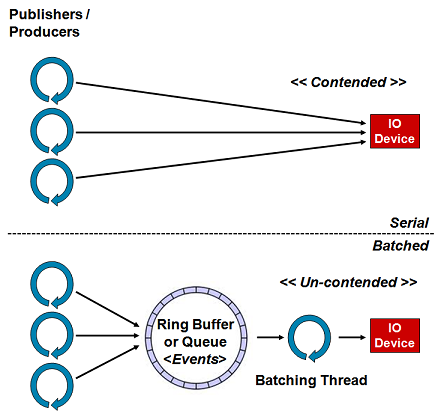
Изображение выше изображает разделение доступа к устройству ввода-вывода и, следовательно, конкуренции за доступ к нему, путем введения структуры, подобной очереди, для подготовки отправляемых сообщений / событий и потока, выполняющего пакетную обработку для записи на устройство.
Алгоритм
Подход к пакетированию использует следующий алгоритм в псевдокоде Java:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
public final class NetworkBatcher implements Runnable{ private final NetworkFacade network; private final Queue<Message> queue; private final ByteBuffer buffer; public NetworkBatcher(final NetworkFacade network, final int maxPacketSize, final Queue<Message> queue) { this.network = network; buffer = ByteBuffer.allocate(maxPacketSize); this.queue = queue; } public void run() { while (!Thread.currentThread().isInterrupted()) { while (null == queue.peek()) { employWaitStrategy(); // block, spin, yield, etc. } Message msg; while (null != (msg = queue.poll())) { if (msg.size() > buffer.remaining()) { sendBuffer(); } buffer.put(msg.getBytes()); } sendBuffer(); } } private void sendBuffer() { buffer.flip(); network.send(buffer); buffer.clear(); }} |
Как правило, подождите, пока данные станут доступными, и сразу же отправьте их прямо сейчас. При отправке предыдущего сообщения или в ожидании новых сообщений может появиться пакет трафика, который может быть отправлен в пакете до размера буфера на базовый ресурс. Этот подход может использовать ConcurrentLinkedQueue, который обеспечивает низкую задержку и избегает блокировок. Однако проблема заключается в том, что он не создает обратного давления для остановки потоков производства / публикации, если они превосходят пакетный механизм, в результате чего очередь может выйти из-под контроля, поскольку она не ограничена. Мне часто приходилось оборачивать ConcurrentLinkedQueue, чтобы отслеживать его размер и, таким образом, создавать обратное давление. Такое отслеживание размера может добавить 50% к стоимости обработки при использовании этой очереди в моем опыте.
Этот алгоритм учитывает принцип единственного устройства записи и часто может использоваться при записи в сеть или на устройство хранения, что позволяет избежать конфликтов блокировок в сторонних библиотеках API. Избегая конфликта, мы избегаем профиля задержки J-Curve, обычно связанного с конфликтом ресурсов, из-за эффекта очереди на блокировках. С этим алгоритмом при увеличении нагрузки задержка остается постоянной до тех пор, пока базовое устройство не будет насыщено трафиком, что приведет к большему профилю «ванны», чем J-кривая.
Давайте возьмем работающий пример обработки 10 сообщений, которые приходят в виде всплеска трафика. В большинстве систем трафик идет пакетами и редко равномерно распределен во времени. Один подход предполагает отсутствие пакетной обработки, и потоки записывают в API устройства напрямую, как показано на рисунке 1. выше. Другой будет использовать структуру данных без блокировки для сбора сообщений плюс один поток, потребляющий сообщения в цикле согласно алгоритму выше. Для примера давайте предположим, что для записи одного буфера на сетевое устройство в качестве синхронной операции требуется 100 мкс, и она будет подтверждена. Размер буфера в идеале должен быть меньше размера MTU сети, когда задержка является критической. Многие сетевые подсистемы являются асинхронными и поддерживают конвейерную обработку, но мы сделаем вышеприведенное предположение, чтобы прояснить пример. Если сетевая операция использует протокол, такой как HTTP, в REST или веб-службах, то это предположение соответствует базовой реализации.
| Лучший (мкс) | Среднее (мкс) | Худший (мкс) | Отправлено пакетов | |
|---|---|---|---|---|
| последовательный | 100 | 500 | 1000 | 10 |
| Smart Batching | 100 | 150 | 200 | 1-2 |
Абсолютная наименьшая задержка будет достигнута, если сообщение будет отправлено из потока, отправляющего данные непосредственно в ресурс, если ресурс не состязался. В приведенной выше таблице показано, что происходит, когда возникает конфликт и возникает эффект очереди. При последовательном подходе нужно будет отправить 10 отдельных пакетов, которые обычно должны стоять в очереди на блокировку, управляющую доступом к ресурсу, поэтому они обрабатываются последовательно. Приведенные выше цифры предполагают, что стратегия блокировки работает идеально без ощутимых накладных расходов, что маловероятно в реальном приложении.
Для пакетного решения вероятно, что все 10 пакетов будут собраны в первом пакете, если параллельная очередь эффективна, что дает сценарий задержки наилучшего случая. В худшем случае в первом пакете отправляется только одно сообщение, а в следующем — девять. Поэтому в худшем случае одно сообщение имеет задержку 100 мкс, а следующие 9 имеют задержку 200 мкс, что дает среднее наихудшее значение 190 мкс, что значительно лучше, чем при последовательном подходе.
Это один хороший пример, когда самое простое решение слишком простое из-за конфликта. Пакетное решение помогает добиться стабильной низкой задержки в пакетных условиях и является лучшим для пропускной способности. Это также имеет хороший эффект по всей сети на принимающей стороне в том, что приемник должен обрабатывать меньше пакетов и, следовательно, делает связь более эффективной с обеих сторон.
Большая часть оборудования обрабатывает данные в буферах до фиксированного размера для повышения эффективности. Для устройства хранения это, как правило, блок 4 КБ. Для сетей это будет MTU и обычно 1500 байт для Ethernet. При пакетной обработке лучше всего понимать базовое оборудование и записывать пакеты в идеальном размере буфера для оптимальной эффективности. Однако имейте в виду, что некоторые устройства должны конвертировать данные, например, заголовки Ethernet и IP для сетевых пакетов, поэтому буфер должен это учитывать.
Всегда будет увеличена задержка от переключения потоков и стоимость обмена через структуру данных. Однако есть ряд очень хороших неблокирующих структур, доступных с использованием методов без блокировки. Для Disruptor этот тип обмена может быть достигнут всего за 50-100 нс, что делает выбор интеллектуального пакетного подхода простым и понятным для распределенных систем с низкой задержкой или высокой пропускной способностью.
Эта техника может быть использована для многих задач, а не только для IO. Ядро Disruptor использует эту технику, чтобы помочь сбалансировать систему, когда издатели разрываются и опережают EventProcessor . Алгоритм можно увидеть внутри BatchEventProcessor .
Примечание. Чтобы этот алгоритм работал, структура очередей должна обрабатывать конфликт лучше, чем базовый ресурс. Многие реализации очереди крайне плохо справляются с конфликтами. Используйте науку и меру, прежде чем прийти к выводу.
Дозирование с помощью Разрушителя
Приведенный ниже код демонстрирует тот же алгоритм в действии, используя механизм Disruptor EventHandler . По моему опыту, это очень эффективный метод для эффективной обработки любого устройства ввода-вывода и поддержания низкой задержки при работе с нагрузкой или пакетным трафиком.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
public final class NetworkBatchHandler implements EventHander<Message>{ private final NetworkFacade network; private final ByteBuffer buffer; public NetworkBatchHandler(final NetworkFacade network, final int maxPacketSize) { this.network = network; buffer = ByteBuffer.allocate(maxPacketSize); } public void onEvent(Message msg, long sequence, boolean endOfBatch) throws Exception { if (msg.size() > buffer.remaining()) { sendBuffer(); } buffer.put(msg.getBytes()); if (endOfBatch) { sendBuffer(); } } private void sendBuffer() { buffer.flip(); network.send(buffer); buffer.clear(); } } |
Параметр endOfBatch значительно упрощает обработку пакета по сравнению с двойным циклом в приведенном выше алгоритме.
Я упростил примеры, чтобы проиллюстрировать алгоритм. Очевидно, что обработка ошибок и другие граничные условия необходимо учитывать.
Отделение ввода-вывода от обработки работы
Есть еще одна очень веская причина отделить IO от потоков, выполняющих работу. Передача ввода-вывода другому потоку означает, что рабочий поток или потоки могут продолжить обработку без блокирования в удобной для кэша форме. Я считаю, что это имеет решающее значение для достижения высокой производительности.
Если базовое устройство или ресурс ввода-вывода ненадолго насыщаются, то сообщения могут быть поставлены в очередь для потока дозатора, что позволяет продолжить обработку потоков работы. Затем пакетный поток передает сообщения на устройство ввода-вывода наиболее эффективным способом, позволяя структуре данных обрабатывать пакет и при полном заполнении прикладывать необходимое обратное давление, обеспечивая тем самым хорошее разделение проблем в рабочем процессе.
Вывод
Так что у вас есть это. Smart Batching может использоваться совместно с соответствующими структурами данных для достижения согласованной низкой задержки и максимальной пропускной способности.
Ссылка: Smart Batching от нашего партнера JCG Мартина Томпсона в блоге Mechanical Sympathy .