В этом посте:
- Что такое JLBH
- Почему мы написали JLBH
- Различия между JMH и JLBH
- Краткое руководство
Что такое JLBH?
JLBH — это инструмент, который можно использовать для измерения задержки в программах Java. У этого есть эти особенности:
- Направленный на выполнение кода, который будет больше, чем микро-тест.
- Подходит для программ, использующих асинхронную активность, например, шаблон потребителя производителя.
- Возможность оценки отдельных точек в рамках программы
- Возможность настроить пропускную способность в тесте
- Регулирует скоординированное упущение, т.е. сквозные задержки итераций влияют друг на друга, если они выполняют резервное копирование
- Сообщает и запускает свой собственный поток джиттера
Почему мы написали JLBH?
JLBH был написан потому, что нам нужен был способ сравнения Chronicle-FIX. Мы создали его для оценки и диагностики проблем в нашем программном обеспечении. Он оказался чрезвычайно полезным и теперь доступен в библиотеках с открытым исходным кодом Chronicle.
Chronicle-FIX — это механизм исправлений Java с ультранизкими задержками. Это гарантирует задержки, например, что анализ сообщения NewOrderSingle в объектную модель не будет превышать 6us вплоть до 99,9-го процентиля. На самом деле нам нужно было измерять все время в диапазоне процентилей.
Это тип латентного / процентильного профиля.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
50 -> 1.5us90 -> 2us99 -> 2us99.9 -> 6us99.99 -> 12us99.999 -> 35usWorst -> 500us |
Исправление хроники гарантирует эти задержки с различной пропускной способностью от 10 000 сообщений в секунду до 100 000 сообщений в секунду. Поэтому нам нужен был тестовый комплект, где мы могли бы легко изменять пропускную способность.
Нам также необходимо было учесть согласованное упущение. Другими словами, мы не могли просто проигнорировать эффект медленного прогона на следующем прогоне. Если прогон A был медленным и это вызвало задержку прогона B, даже если прогон B не имел задержки в своем собственном прогоне, тот факт, что он был задержан, все равно должен был быть записан.
Нам нужно было попытаться провести различие между джиттером ОС, джиттером JVM и джиттером, вызванным нашим собственным кодом. По этой причине мы добавили возможность иметь поток джиттера, который не делал ничего, кроме сэмплирования джиттера в JVM. Это может показать комбинацию дрожания ОС, например, планирование потоков и общие прерывания ОС и глобальные события JVM, такие как паузы GC.
Нам нужно было приписать задержки как можно лучше к отдельным подпрограммам или даже строкам кода, поэтому мы также создали возможность добавления пользовательской выборки в программу. Добавление NanoSamplers добавляет очень мало накладных расходов к эталону и позволяет вам наблюдать, где ваша программа вносит задержку.
Это схематическое представление эталонного теста, который мы создали для измерения Chronicle-FIX.
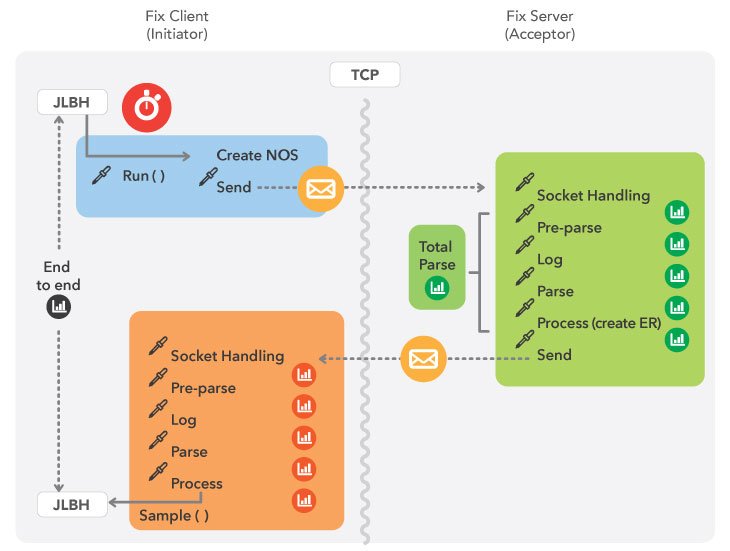
Мы получили такие результаты:
Это был типичный прогон:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
Run time: 100.001sCorrecting for co-ordinated:trueTarget throughput:50000/s = 1 message every 20usEnd to End: (5,000,000) 50/90 99/99.9 99.99/99.999 - worst was 11 / 15 17 / 20 121 / 385 - 541Acceptor:1 init2AcceptNetwork (4,998,804) 50/90 99/99.9 99.99/99.999 - worst was 9.0 / 13 15 / 17 21 / 96 - 541Acceptor:1.1 init2AcceptorNetwork(M) (1,196) 50/90 99/99.9 99.99 - worst was 22 / 113 385 / 401 401 - 401Acceptor:2 socket->parse (4,998,875) 50/90 99/99.9 99.99/99.999 - worst was 0.078 / 0.090 0.11 / 0.17 1.8 / 2.1 - 13Acceptor:2.0 remaining after read (20,649,126) 50/90 99/99.9 99.99/99.999 99.9999/worst was 0.001 / 0.001 0.001 / 0.001 0.001 / 1,800 3,600 / 4,590Acceptor:2.1 parse initial (5,000,100) 50/90 99/99.9 99.99/99.999 - worst was 0.057 / 0.061 0.074 / 0.094 1.0 / 1.9 - 4.7Acceptor:2.5 write To Queue (5,000,100) 50/90 99/99.9 99.99/99.999 - worst was 0.39 / 0.49 0.69 / 2.1 2.5 / 3.4 - 418Acceptor:2.9 end of inital parse (5,000,000) 50/90 99/99.9 99.99/99.999 - worst was 0.17 / 0.20 0.22 / 0.91 2.0 / 2.2 - 7.6Acceptor:2.95 on mid (5,000,000) 50/90 99/99.9 99.99/99.999 - worst was 0.086 / 0.10 0.11 / 0.13 1.4 / 2.0 - 84Acceptor:3 parse NOS (5,000,000) 50/90 99/99.9 99.99/99.999 - worst was 0.33 / 0.38 0.41 / 2.0 2.2 / 2.6 - 5.5Acceptor:3.5 total parse (5,000,000) 50/90 99/99.9 99.99/99.999 - worst was 1.1 / 1.2 1.8 / 3.0 3.5 / 5.8 - 418Acceptor:3.6 time on server (4,998,804) 50/90 99/99.9 99.99/99.999 - worst was 1.1 / 1.2 1.8 / 3.1 3.8 / 6.0 - 418Acceptor:4 NOS processed (5,000,000) 50/90 99/99.9 99.99/99.999 - worst was 0.21 / 0.23 0.34 / 1.9 2.1 / 2.8 - 121Jitter (5,000,000) 50/90 99/99.9 99.99/99.999 - worst was 0.035 / 0.035 0.035 / 0.037 0.75 / 1.1 - 3.3OS Jitter (108,141) 50/90 99/99.9 99.99 - worst was 1.2 / 1.4 2.5 / 4.5 209 - 217 |
Все образцы суммированы по прогонам в конце теста здесь пара:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
-------------------------------- SUMMARY (Acceptor:2.95 on mid)----------------------Percentile run1 run2 run3 run4 run5 % Variation var(log)50: 0.09 0.09 0.09 0.09 0.09 0.00 3.3290: 0.10 0.10 0.10 0.10 0.10 0.00 3.5899: 0.11 0.11 0.11 0.11 0.11 2.45 3.6999.9: 0.13 0.13 0.62 0.78 0.13 76.71 6.0199.99: 1.50 1.38 1.82 1.89 1.70 19.88 9.30worst: 1.95 2.02 2.11 2.24 2.24 6.90 9.90--------------------------------------------------------------------------------------------------------------------- SUMMARY (Acceptor:3 parse NOS)----------------------Percentile run1 run2 run3 run4 run5 % Variation var(log)50: 0.33 0.33 0.34 0.36 0.36 6.11 5.7590: 0.38 0.38 0.46 0.46 0.46 12.42 6.2499: 0.41 0.41 0.50 0.53 0.50 16.39 6.4799.9: 2.11 2.02 2.11 2.11 2.11 3.08 9.7699.99: 2.37 2.24 2.37 2.37 2.37 3.67 10.05worst: 2.88 2.62 3.14 3.14 2.88 11.51 10.67------------------------------------------------------------------------------------- |
Используя JLBH, мы смогли сравнить наше приложение с критериями в спецификации, а также диагностировать некоторые пики задержки.
Изменяя пропускную способность и время выполнения эталонного теста и особенно добавляя выборку к различным точкам в шаблонах кода, начали появляться, что привело нас к источнику задержки. Конкретным примером этого была проблема с DateTimeFormatter, приводящая к отсутствию кэша TLB, но это будет темой другого поста.
Различия между JMH и JLBH
Я ожидаю, что большинство из тех, кто читает эту статью, знакомы с JMH (Java MicroBenchmarking Harness), это отличный инструмент для микропроцессоров, и если вы его еще не использовали, это полезный инструмент, который должен быть у каждого разработчика Java в своем шкафчике. Особенно те, которые связаны с измерением задержек.
Как вы увидите из дизайна JLBH, большая часть его была вдохновлена JMH.
Итак, если JMH настолько хорош, почему мы должны были создать еще один тестовый жгут?
Я думаю, на высоком уровне ответ находится в названии. J M H прямо нацелен на микропроцессоры, в то время как JLBH находится там, чтобы найти задержки в больших программах.
Но это не только это. Прочитав последний раздел, вы увидите, что есть ряд причин, по которым вы можете выбрать JLBH вместо JMH для определенного класса проблем.
Между тем, хотя вы всегда можете использовать JLBH вместо JMH, если у вас есть подлинный микро-эталон, который вы хотите измерить как можно точнее и точнее, я бы всегда рекомендовал вам использовать JMH вместо JLBH. JMH — чрезвычайно сложный инструмент, который делает то, что действительно хорошо, например, JMH разветвляет JVM для каждого прогона, чего в настоящее время нет в JLBH.
Когда вы будете использовать JLBH над JMH:
- Если вы хотите, чтобы ваш код работал в контексте. Природа JMH состоит в том, чтобы взять очень маленький образец вашего кода, скажем, в случае с движком FIX, только для синтаксического анализа и выделить его в отдельности. В наших тестах один и тот же синтаксический анализ исправления занимал в два раза больше времени при запуске в контексте, т.е. как часть механизма исправления, так же, как и при запуске вне контекста, например, в микро-тесте. У меня есть хороший пример этого в моем примере проектов Latecy DateSerialise, где я демонстрирую, что сериализация объекта Date может занять в два раза больше времени при выполнении внутри вызова TCP. Причиной этого является все, что связано с кэшем ЦП и тем, к чему мы вернемся в следующем блоге.
- Если вы хотите принять во внимание согласованное упущение. В JMH, по замыслу, все итерации не зависят друг от друга, поэтому, если одна итерация кода медленная, она не будет влиять на следующую. Хороший пример этого мы видим в моих примерах Latecy SimpleSpike, где мы видим огромный эффект, который может оказать учет скоординированного пропуска. Примеры реального мира почти всегда должны измеряться при учете согласованного упущения.
Например, давайте представим, что вы ждете поезд и задерживаетесь на станции на час, потому что поезд перед вами опаздывает. Тогда давайте представим, что вы садитесь в поезд на час позже, а поезду обычно требуется полчаса, чтобы добраться до пункта назначения. Если вы не учитываете согласованное упущение, вы не будете считать, что перенесли какую-либо задержку, поскольку ваше путешествие заняло ровно столько времени, сколько вы ожидали на станции в течение часа перед отправлением! - Если вы хотите изменить пропускную способность в вашем тесте . JLBH позволяет вам установить пропускную способность в качестве параметра для вашего теста. Правда в том, что задержка не имеет смысла без определенной пропускной способности, поэтому крайне важно, чтобы вы могли видеть результаты изменения пропускной способности в своем профиле задержки. JMH не позволяет вам устанавливать пропускную способность. (Фактически это идет рука об руку с тем фактом, что JMH не учитывает скоординированное упущение.)
- Вы хотите иметь возможность выбирать различные точки в вашем коде. Конечное время ожидания прекрасно для начала, но что тогда? Вы должны быть в состоянии записать профиль задержки для многих точек в коде. С JLBH вы можете добавлять зонды в свои коды, где бы вы ни выбрали, с очень небольшими накладными расходами на программу. JMH разработан таким образом, что вы измеряете только от начала вашего метода (@Benchmark) до конца.
- Вы хотите измерить глобальные задержки ОС и JVM. JLBH запускает отдельный поток джиттера. Он работает параллельно с вашей программой и выполняет только выборку задержки, многократно вызывая System.nanoTime (). Хотя это само по себе не говорит вам все о многом, это может указывать на то, что происходит на стороне вашей JVM во время теста. Кроме того, вы можете добавить зонд, который ничего не делает (это будет объяснено позже), где вы можете сэмплировать задержку внутри потока, который выполняет код, который вы тестируете. JMH не имеет такой функциональности.
Как я упоминал ранее, если вы не хотите использовать одну или несколько из этих функций, чем отдавайте предпочтение JMH, а не JLBH.
Краткое руководство
Код для JLBH можно найти в библиотеке Chronicle-Core, которую можно найти на GitHub здесь .
Для загрузки из Maven-Central включите это в ваш pom.xml (проверьте последнюю версию):
|
1
2
3
4
5
6
7
8
9
|
<dependency> <groupId>net.openhft</groupId> <artifactId>chronicle-core</artifactId> <version>1.4.7</version></dependency> |
Чтобы написать тест, вы реализовали интерфейс JLBHTask :
Он имеет всего два метода, которые вам нужно реализовать:
- init (JLBH jlbh) вы получили ссылку на JLBH, которую вам нужно будет отозвать (jlbh.sampleNanos ()), когда ваш тест будет завершен.
- run (long startTime) код для запуска на каждой итерации. Вам нужно будет сохранить время начала, когда вы определите, сколько времени занял тест, и перезвоните jlbh.sampleNanos (). JLBH подсчитывает, сколько раз вызывается sampleNanos (), и оно должно точно совпадать с количеством вызванных run (). Это не относится к другим зондам, которые вы можете создать.
- Существует третий необязательный метод complete (), который может быть полезен для очистки некоторых тестов.
Все это лучше всего видно на простом примере:
В этом случае мы измеряем, сколько времени потребуется, чтобы поместить элемент в ArrayBlockingQueue и снова снять его.
Мы добавляем пробники, чтобы увидеть, сколько времени займет вызов методов put () и poll ().
Я бы посоветовал вам запустить эту изменяющуюся пропускную способность и размер ArrayBlockingQueue и посмотреть, какая разница.
Вы также можете увидеть разницу, если вы установите accountForCoordinatedOmission в true или false.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
|
package org.latency.prodcon;import net.openhft.chronicle.core.jlbh.JLBH;import net.openhft.chronicle.core.jlbh.JLBHOptions;import net.openhft.chronicle.core.jlbh.JLBHTask;import net.openhft.chronicle.core.util.NanoSampler;import java.util.concurrent.*;/** * Simple test to demonstrate how to use JLBH */public class ProducerConsumerJLBHTask implements JLBHTask { private final BlockingQueue<Long> queue = new ArrayBlockingQueue(2); private NanoSampler putSampler; private NanoSampler pollSampler; private volatile boolean completed; public static void main(String[] args){ //Create the JLBH options you require for the benchmark JLBHOptions lth = new JLBHOptions() .warmUpIterations(40_000) .iterations(100_000) .throughput(40_000) .runs(3) .recordOSJitter(true) .accountForCoordinatedOmmission(true) .jlbhTask(new ProducerConsumerJLBHTask()); new JLBH(lth).start(); } @Override public void run(long startTimeNS) { try { long putSamplerStart = System.nanoTime(); queue.put(startTimeNS); putSampler.sampleNanos(System.nanoTime() - putSamplerStart); } catch (InterruptedException e) { e.printStackTrace(); } } @Override public void init(JLBH lth) { putSampler = lth.addProbe("put operation"); pollSampler = lth.addProbe("poll operation"); ExecutorService executorService = Executors.newSingleThreadExecutor(); executorService.submit(()->{ while(!completed) { long pollSamplerStart = System.nanoTime(); Long iterationStart = queue.poll(1, TimeUnit.SECONDS); pollSampler.sampleNanos(System.nanoTime() - pollSamplerStart); //call back JLBH to signify that the iteration has ended lth.sample(System.nanoTime() - iterationStart); } return null; }); executorService.shutdown(); } @Override public void complete(){ completed = true; }} |
Посмотрите на все опции, с помощью которых вы можете установить свой эталонный тест JLBH, которые содержатся в JLBHOptions .
В следующем посте мы рассмотрим еще несколько примеров тестов JLBH.
Пожалуйста, дайте мне знать, если у вас есть какие-либо отзывы о JLBH — если вы хотите внести свой вклад, не стесняйтесь, чтобы раскошелиться Chronicle-Core и отправить запрос на извлечение!
| Ссылка: | JLBH — знакомство с Java Lactcy Benchmarking Harness от нашего партнера по JCG Дэниела Шая в блоге Rational Java . |