Эта статья является частью нашего курса Academy под названием Redis — хранилище ключей NoSQL .
Это ускоренный курс по Redis. Вы узнаете, как установить Redis и запустить сервер. Кроме того, вы будете возиться с командной строкой Redis. Далее следуют более сложные темы, такие как репликация, сегментирование и кластеризация, а также объясняется интеграция Redis с Spring Data. Проверьте это здесь !
Содержание
1. Введение
Эта заключительная часть руководства посвящена новейшей и самой крутой, но все еще экспериментальной (не готовой к использованию) функции Redis — кластеризации. Материал этой части в значительной степени основан на разделах документации Redis, http://redis.io/topics/cluster-tutorial и http://redis.io/topics/cluster-spec . Кластеризация Redis (или просто Redis Cluster) — это распределенное развертывание Redis, целью которого является решение следующих основных задач:
- возможность автоматического разделения набора данных между несколькими узлами
- способность обеспечить высокую производительность и линейную масштабируемость
- способность сохранять все записи, исходящие от клиентов, связанных с большинством узлов ( безопасность / согласованность записи )
- способность пережить сетевые разделы, где достижимо большинство мастер-узлов, и есть, по крайней мере, достижимый ведомый для каждого мастер-узла, который более недоступен ( доступность )
Redis Cluster — это альтернативное (но гораздо более продвинутое) решение для разделения (разбиения) данных, которое мы видели в части 4 этого руководства Redis Sharding (но вместо использования сторонних инструментов вся функциональность обеспечивается самой Redis с помощью дополнительная конфигурация). Чтобы обеспечить высокую доступность, Redis Cluster также в значительной степени зависит от репликации «главный — подчиненный», которую мы видели в третьей части руководства « Репликация Redis» .
2. Ограничения кластеризации Redis
Прежде всего, все функции, связанные с Redis Cluster, находятся в экспериментальном режиме, пока не готовы к использованию.
Создать любую высокодоступную распределенную систему очень сложно, но Redis пытается сделать это возможным. Есть несколько ограничений, о которых нужно знать, и некоторые компромиссы, некоторые из которых мы уже упоминали, но стоит повторить их и здесь.
Во-первых, команды, работающие с несколькими ключами, не поддерживаются кластером Redis ( SINTER , SUNION ,…). Такая функциональность потребует перемещения данных между узлами Redis, что приведет к тому, что Redis Cluster не сможет обеспечить приемлемые характеристики и предсказуемое поведение под нагрузкой. В общем случае все операции, когда ключи недоступны в узле Redis, обрабатывающем команду, не реализованы.
Во-вторых, Redis Cluster не поддерживает несколько баз данных, таких как автономная версия Redis. Существует только одна база данных 0, и SELECT не допускается.
В-третьих, узлы в кластере Redis не передают команды прокси правым узлам, хранящим данный ключ, а вместо этого перенаправляют клиентов на нужные узлы, обслуживающие заданный диапазон пространства ключей (гибридная форма так называемой query routing ). В конце концов, клиенты получают актуальное представление топологии кластера и, зная, какой узел обслуживает какое подмножество ключей, могут напрямую связаться с нужными узлами для отправки данной команды (фактически возвращаясь к client side partitioning ).
3. Схема разбиения (разбиения)
Как мы уже знаем из части 4 , Redis Sharding , существует несколько схем разделения (разбиения) данных, используемых для разделения данных с согласованным хешированием, которые являются наиболее продвинутыми и широко используемыми. Redis Cluster не использует согласованное хеширование, а использует другую форму разделения данных, где каждый ключ является частью так называемого hash slot .
В Redis Cluster имеется 16384 hash slots и для вычисления того, что является hash slot данного ключа, вычисляется функция CRC16 ( http://en.wikipedia.org/wiki/Cyclic_redundancy_check ) этого ключа, а затем по модулю 16384 применяется к его результату.
Каждый узел в кластере Redis отвечает за подмножество hash slots . В качестве примера рассмотрим кластер с четырьмя узлами Redis # 1 , # 2 , # 3 и # 4 . Это может дать нам следующее распределение hash slots :
- Узел Redis # 1 содержит
hash slotsот 0 до 4096 - Узел Redis # 2 содержит
hash slotsот 4097 до 8192 - Узел Redis # 3 содержит
hash slotsот 8193 до 12288 - Узел Redis # 4 содержит
hash slotsс 12289 по 16383
Такая схема разделения (разбиения) позволяет легко изменять топологию (добавлять и удалять узлы) кластера. Например, если необходимо добавить новый узел # 5, некоторые hash slots из узлов # 1 , # 2 , # 3 и # 4 должны быть перемещены в узел # 5 . Аналогичным образом, если необходимо удалить узел № 3 из кластера, hash slots обслуживаемые узлом № 3, следует переместить на узлы № 1 и № 2 . Когда узел № 3 станет пустым, он может быть удален из кластера навсегда.
Теперь лучшая часть: поскольку перемещение hash slots от одного узла к другому не требует остановки текущих операций, добавление и удаление узлов (или изменение процента hash slots удерживаемых узлами) не требует никакого простоя.
Позже в этом руководстве мы вернемся к этому примеру и создадим фактический кластер с тремя главными узлами Redis (каждый из которых поддерживается одним подчиненным). Пока Redis Cluster работает, мы добавим и удалим некоторые узлы, чтобы посмотреть, как можно перераспределить hash slots реальном времени.
3.1 Ключи хеш-тегов
Очень интересная особенность, поддерживаемая схемой разбиения (разбиения) Redis, — это так называемые ключевые hash tags . Hash tags — это метод, обеспечивающий выделение двух (или более) ключей в одном и том же hash slot .
Чтобы поддерживать hash tags , hash slot вычисляется другим способом. Если ключ содержит шаблон « {…} », то hash slot хэшируется только подстрока между « { » и « } », чтобы получить hash slot (в случае множественных вхождений « { « или »« } »в имя, некоторые правила имеют место и описаны на http://redis.io/topics/cluster-spec ).
Twemproxy ( nutcracker ), с которым мы играли в части 4 , Redis Sharding , также позволяет настроить hash tags которые будут использоваться для хеширования ключей, следуя тому же набору правил.
4. Redis кластеризация в двух словах
В кластере Redis все узлы содержат некоторую часть глобального набора ключей (сегмента или раздела). Кроме того, каждый узел содержит состояние кластера, включая сопоставления hash slots чтобы перенаправить клиентов на правильный узел для данного ключа. Все узлы в Redis Cluster также могут автоматически обнаруживать другие узлы, обнаруживать узлы, которые недоступны или не работают должным образом, и выполнять подчиненные узлы для управления выборами при необходимости.
Что касается подробностей реализации, описанных по адресу http://redis.io/topics/cluster-spec , все узлы в кластере подключены с использованием протокола TCP с двоичным протоколом ( cluster bus ), так что каждый узел подключен к каждому другому узлу в кластер, использующий cluster bus (это означает, что в кластере Redis из N узлов каждый узел имеет N — 1 исходящих TCP-соединений и N — 1 входящих TCP-соединений). Эти TCP-соединения поддерживаются постоянно. Узлы используют протокол сплетен ( http://en.wikipedia.org/wiki/Gossip_protocol ) для распространения состояния кластера, обнаружения новых узлов, проверки правильности работы всех узлов и распространения сообщений публикации / подписки по всему кластеру. ,
Каждый узел в кластере Redis имеет уникальный идентификатор (имя). Идентификатор узла (имя) представляет собой шестнадцатеричное представление 160-битного случайного числа, полученного при первом запуске узла. Узел сохранит свой идентификатор (имя) в файле конфигурации узла (по умолчанию, nodes.conf ) и будет использовать один и тот же идентификатор (имя) навсегда (или, по крайней мере, до тех пор, пока файл конфигурации узла не будет удален).
Идентификатор узла (имя) используется для идентификации каждого узла во всем кластере Redis. Для данного узла возможно изменить свой IP-адрес без необходимости также изменять свой идентификатор (имя). Кластер также может обнаруживать изменения в IP-адресе и / или порте и передавать эту информацию, используя протокол сплетни, работающий по cluster bus . Кроме того, с каждым узлом связана некоторая другая информация, которую должны знать все остальные узлы в кластере Redis:
- IP-адрес и порт TCP, где расположен узел
- набор флагов (мастер, раб,…)
- набор
hash slotsобслуживаемых узлом (см., пожалуйста, схему Sharding (Partitioning) ) - последний раз пакет ping был отправлен с использованием кластерной шины
- в последний раз пакет понг был получен в ответ
- время, когда узел был помечен как сбойный
- количество рабов этого узла
- идентификатор (имя) главного узла, если этот узел является подчиненным (или обнуляется, если это главный узел)
Часть этой информации доступна с помощью команды CLUSTER NODES (см. Раздел « Команды Redis Cluster» ).
5. Согласованность, доступность и масштабируемость
Redis Cluster — это распределенная система. Хорошие распределенные системы масштабируемы и способны обеспечить лучшую производительность в масштабе. Но, тем не менее, в любой распределенной системе любой компонент может выйти из строя в любое время, и система должна предоставить некоторые гарантии в случае возникновения таких сбоев (особенно если это хранилище данных). В этом разделе мы просто кратко рассмотрим некоторые компромиссы высокого уровня, которые Redis делает в отношении согласованности, доступности и масштабируемости. Более глубокое понимание и подробности можно найти по адресу http://redis.io/topics/cluster-spec и http://redis.io/topics/cluster-tutorial . Обратите внимание, что Redis Cluster развивается очень быстро, и некоторые гарантии, обсуждаемые в этом разделе, могут больше не действовать.
5.1 Согласованность
Redis Cluster не может гарантировать строгую согласованность, но он старается сохранить все записи, которые выполняются клиентами. К сожалению, это не всегда возможно. Поскольку Redis Cluster использует асинхронную репликацию между главным и подчиненным узлами, всегда есть временные окна, когда можно потерять записи во время сетевых разделов. Если главный узел умирает без записи, достигающей подчиненных узлов, запись теряется навсегда (в случае, если ведущий недоступен в течение длительного периода времени, и один из его ведомых повышается, чтобы стать ведущим).
5.2 Доступность
Redis Cluster недоступен на стороне меньшинства сетевого раздела. На большей части сетевого раздела, при условии, что есть хотя бы большинство мастеров и ведомое устройство для каждого недоступного мастера, кластер Redis все еще доступен. Это означает, что Redis Cluster может пережить сбои нескольких узлов в кластере, но не может пережить большие сетевые разделы. В качестве примера рассмотрим кластер Redis с N главными узлами ( M1 , M2 , M3 ) и N подчиненными узлами ( S1 , S2 , S3 , причем каждый мастер имеет ровно один подчиненный узел). Если какой-либо один главный узел становится недоступным (допустим, что это M2 ) из-за сетевого раздела, большая часть кластера все равно останется доступной (и S2 будет повышен до уровня главного). Позже, если любой другой главный или подчиненный узел станет недоступным (кроме S2 ), кластер все еще будет доступен. Тем не менее, обратите внимание, что если по какой-либо причине происходит сбой узла S2 , Redis Cluster больше не может продолжать работу (поскольку недоступны как главный M2 и подчиненный S2 ).
5.3 Масштабируемость
Из раздела Схема разбиения (разбиения) мы уже знаем, что узлы Redis Cluster не перенаправляют команды на нужный узел для данного ключа, а перенаправляют клиентов. В конечном итоге клиенты получают полное отображение, какие узлы обслуживают, какое подмножество ключей и могут напрямую связываться с нужными узлами. По этой причине Redis Cluster может линейно масштабироваться (добавление большего количества узлов приводит к повышению производительности), поскольку все поддерживаемые операции обрабатываются точно так же, как и в случае одного экземпляра Redis без дополнительных затрат.
6. Установка Redis с поддержкой кластеров
Redis Cluster в настоящее время доступен только в нестабильных выпусках. Последняя нестабильная версия на момент написания этой статьи — 3.0.0-beta1 которую можно загрузить с http://redis.io/download . Обратите внимание, что предоставляются только дистрибутивы Linux, порт Windows пока недоступен.
Установка дистрибутива Redis с кластеризацией не отличается от обычной установки Redis, описанной в части 1 руководства «Установка Redis», и выполняет те же шаги:
|
1
2
3
4
5
6
|
wget https://github.com/antirez/redis/archive/3.0.0-beta1.tar.gztar xf 3.0.0-beta1.tar.gzcd redis-3.0.0-beta1/makemake testsudo make install |
После последнего шага обычные исполняемые файлы Redis будут установлены в папку /usr/local/bin .
7. Настройка Redis Cluster
Redis Cluster не может быть создан с использованием обычных экземпляров Redis и обычной конфигурации. Вместо этого пара пустых экземпляров Redis должна быть запущена в специальном режиме кластера. Для этого необходимо запустить экземпляр с конфигурацией, специфичной для cluster-enabled директивы cluster-enabled должно быть указано « да » в файле конфигурации), чтобы включить функции и команды, специфичные для кластера.
Минимальный набор параметров, необходимых для запуска некоторого экземпляра Redis с поддержкой режима кластера, включает следующие.
-
cluster-enabledда (по умолчанию: нет )
Включает режим кластера Redis для этого экземпляра -
cluster-config-file nodes.conf(по умолчанию: node.conf )
Путь к файлу, в котором хранится конфигурация этого экземпляра. Этот файл никогда не следует трогать, он просто создается при запуске экземплярами Redis Cluster и обновляется каждый раз, когда это необходимо (см. Раздел « Кластеризация Redis в Nutshell» ). -
cluster-node-timeout5000
Тайм-аут (в миллисекундах), после которого неотвечающий экземпляр считается сбойным алгоритмом обнаружения сбоя. Как мы упоминаем в разделе Схема разбиения (разбиения) , мы собираемся настроить и запустить работающий кластер Redis с тремя главными узлами Redis (master1,master2,master3), каждый из которых поддерживается подчиненным узлом Redis (slave1,slave2,slave3), как показано на картинка ниже.
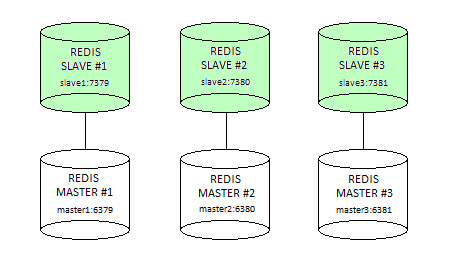
Рисунок 1. Топология кластера Redis
По пути мы рассмотрим большинство возможностей кластера Redis, но перед этим давайте начнем с настройки для мастеров и рабов. Чтобы сохранить конфигурацию достаточно простой, мы начнем с минимальных настроек, необходимых для нормальной работы кластера.
7.1 Настройка главных узлов Redis Cluster
Минимальная конфигурация для основных узлов Redis выглядит следующим образом:
- Узел Redis
master1(redis-master1.conf)12345port 6379cluster-enabledyescluster-config-filenodes.confcluster-node-timeout 5000appendonlyyes - Узел Redis
master2(redis-master2.conf)12345port 6380cluster-enabledyescluster-config-filenodes.confcluster-node-timeout 5000appendonlyyes - Узел Redis
master3(redis-master3.conf)12345port 6381cluster-enabledyescluster-config-filenodes.confcluster-node-timeout 5000appendonlyyes
Подготовив файлы конфигурации, мы можем запустить наши главные узлы Redis один за другим, указав конфигурацию в качестве параметра командной строки.
- redis-сервер redis-master1.conf

Рисунок 2. Узел Redis master1 работает в режиме кластера
- redis-сервер redis-master2.conf

Рисунок 3. Узел Redis master2 работает в режиме кластера
- redis-сервер redis-master3.conf

Рисунок 4. Узел Redis master3 работает в режиме кластера
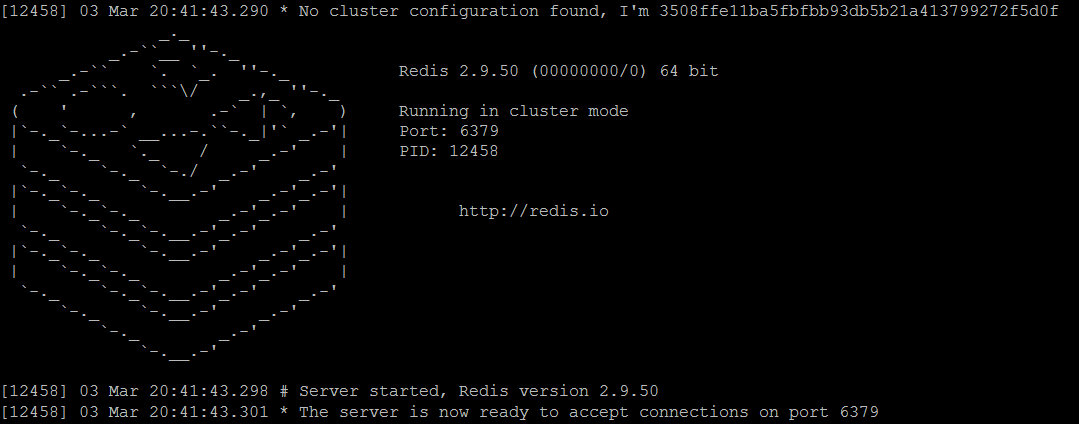
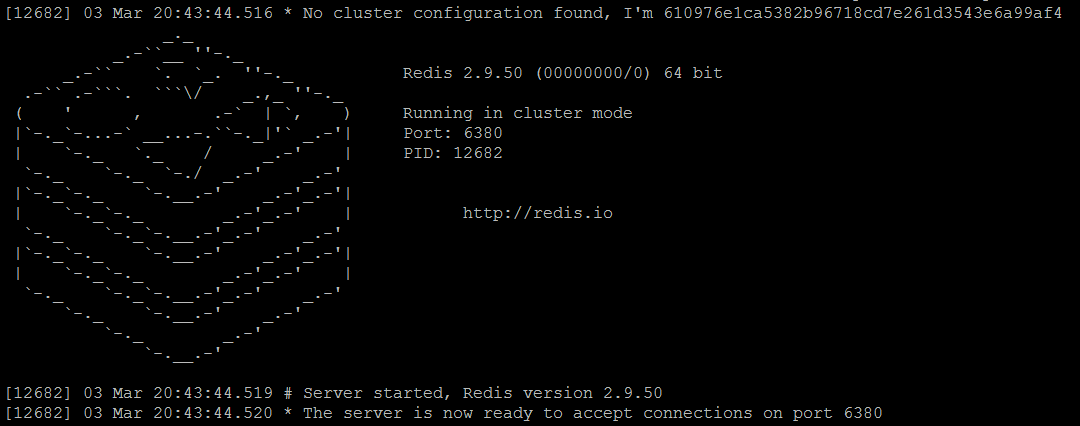
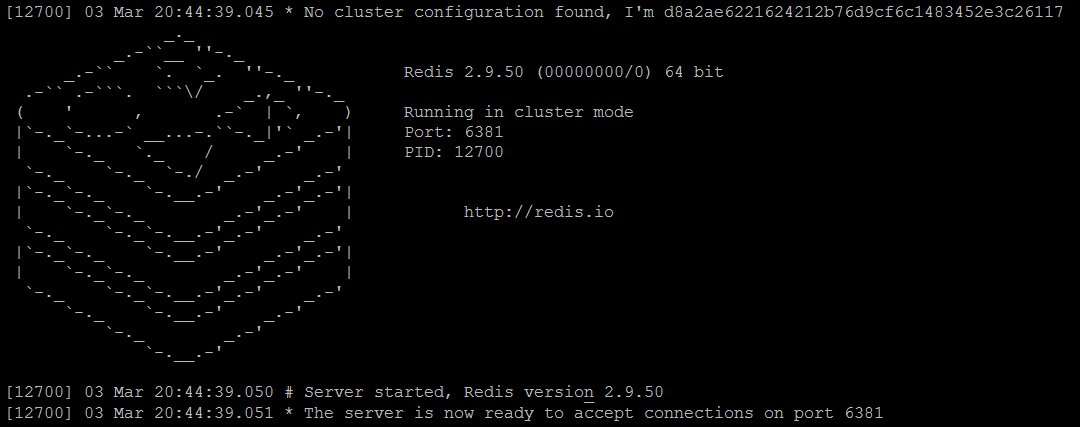
По сравнению с консольным выводом автономных экземпляров Redis, есть несколько заметных отличий:
- при запуске каждый узел генерирует свой
unique ID( имя ), как мы обсуждали в Redis Clustering в Nutshell , обратите внимание, что это значение будет сгенерировано только при первом запуске, а затем повторно использовано - каждый экземпляр работает в
cluster mode - Кроме того, для каждого работающего экземпляра существует файл
nodes.confсозданный с текущимnode ID( именем ) и некоторой дополнительной информацией.
На данный момент у нас есть три мастер-узла Redis, работающие в режиме кластера, но фактически еще не формирующие кластер (каждый мастер-узел Redis видит только себя, но не других). Чтобы убедиться в этом, мы можем запустить команду CLUSTER NODES (см. Раздел « Команды Redis Cluster ») для каждого экземпляра в отдельности и убедиться, что это действительно так.

Рисунок 5. Каждый главный узел Redis видит только себя, но не других
Чтобы сформировать кластер, узлы Redis (работающие в режиме кластера) должны быть соединены вместе командой CLUSTER MEET (см. Раздел « Команды Redis Cluster »). К сожалению, команда принимает только IP-адреса, но не имена хостов. В нашей топологии master1 имеет IP-адрес 192.168.1.105 , master2 имеет 192.168.2.105 и master3 имеет 192.168.3.105 . Имея IP-адреса, давайте master1 узла master1 .

Рисунок 6. Формирование кластера Redis с помощью команды CLUSTER MEET
Теперь, если мы повторно CLUSTER NODES команду CLUSTER NODES , результат должен быть совсем другим.

Рисунок 7а. Повторный CLUSTER NODES на каждом главном узле Redis подтверждает, что каждый узел видит все другие узлы (эффективно формируя кластер).

Рисунок 7б. Повторный CLUSTER NODES на каждом главном узле Redis подтверждает, что каждый узел видит все другие узлы (эффективно формируя кластер).

Рисунок 7с. Повторный CLUSTER NODES на каждом главном узле Redis подтверждает, что каждый узел видит все другие узлы (эффективно формируя кластер).
Вывод команды CLUSTER NODES выглядит несколько загадочно и требует некоторого объяснения того, что означает каждый столбец.
| Колонка 1 | Node ID (имя) |
| Колонка 2 | IP:port узла |
| Колонка 3 | Флаги: хозяин , раб , я , неудачник ,… |
| Колонка 4 | Если это подчиненный, Node ID (имя) мастера |
| Колонка 5 | Время последнего ожидающего пинга еще ждет ответа |
| Колонка 6 | Время последнего получения PONG |
| Колонка 7 | Эпоха настройки для этого узла (см. Пожалуйста http://redis.io/topics/cluster-spec ) |
| Колонка 8 | Статус ссылки на этот узел |
| Колонка 9 | Hash slots обслуживаются |
Таблица 1
Последний столбец, обслуживаемые Hash Slots , не задан в выходных данных, и есть причина, почему: мы еще не назначили hash slot главным узлам, и это то, что мы собираемся сделать сейчас. Hash slots могут быть назначены узлам с помощью команды CLUSTER ADDSLOTS (см., Пожалуйста, Redis Cluster Commands ) на конкретном узле кластера (и не назначены с помощью CLUSTER DELSLOTS соответственно). К сожалению, невозможно назначить диапазоны hash slot (например, 0-5400), но вместо этого каждый hash slot (из общего числа 16384 ) должен назначаться индивидуально. Один из самых простых способов преодолеть это ограничение — использовать немного сценариев оболочки. Поскольку у нас есть только три мастер-узла Redis в кластере, диапазон 16384 hash slots может быть разделен следующим образом:
- Узел Redis
master1содержитhash slots0 — 54001forslotin{0..5400};doredis-cli -h master1 -p 6379 CLUSTER ADDSLOTS $slot;done; - Узел Redis
master2содержитhash slots5401 — 108001forslotin{5400..10800};doredis-cli -h master2 -p 6380 CLUSTER ADDSLOTS $slot;done; - Узел Redis
master3содержитhash slots10801 — 163831forslotin{10801..16383};doredis-cli -h master3 -p 6381 CLUSTER ADDSLOTS $slot;done;
Если мы повторно CLUSTER NODES команду CLUSTER NODES еще раз, последний столбец будет заполнен соответствующими hash slots обслуживаемыми каждым главным узлом (точно совпадающими с диапазонами hash slot мы назначили узлам ранее).

Рисунок 8. CLUSTER NODES показывает hash slots обслуживаемые каждым главным узлом
7.2 Настройка подчиненных узлов Redis Cluster и репликации
Чтобы завершить кластер Redis, нам нужно добавить к каждому работающему главному узлу Redis ровно один подчиненный узел. Хотя часть 3 этого руководства, Redis Replication, достаточно хорошо описывает конфигурацию репликации, кластер Redis делает это по-другому. С самого начала процедура запуска и настройки ведомых устройств ничем не отличается от основной (единственное отличие — номер порта).
- Узел Redis
slave1(redis- slave1.conf)12345port 7379cluster-enabledyescluster-config-filenodes.confcluster-node-timeout 5000appendonlyyes - Узел Redis
slave2(redis-slave2.conf)12345port 7380cluster-enabledyescluster-config-filenodes.confcluster-node-timeout 5000appendonlyyes - Узел Redis
slave3(redis-slave3.conf)12345port 7381cluster-enabledyescluster-config-filenodes.confcluster-node-timeout 5000appendonlyyes
Давайте запустим все три подчиненных экземпляра, а затем команду CLUSTER MEET чтобы каждый узел присоединился к нашему работающему кластеру Redis.
|
1
2
3
|
redis-server redis-slave1.confredis-server redis-slave2.confredis-server redis-slave3.conf |
Поскольку CLUSTER MEET требует IP-адрес, у нашего slave1 есть IP-адрес 192.168.4.105 , slave2 имеет 192.168.5.105, а slave3 имеет 192.168.6.105 .
|
1
2
3
|
redis-cli -h master1 -p 6379 CLUSTER MEET 192.168.4.105 7379redis-cli -h master1 -p 6379 CLUSTER MEET 192.168.5.105 7380redis-cli -h master1 -p 6379 CLUSTER MEET 192.168.6.105 7381 |
Как всегда, используя команду CLUSTER NODES мы можем видеть текущие узлы в кластере Redis (всего шесть). Выходные данные показывают все узлы как мастера.

Рисунок 9. Узлы CLUSTER NODES показывает все шесть узлов как мастера
Чтобы настроить репликацию, необходимо выполнить новую команду CLUSTER REPLICATE на каждом подчиненном устройстве Redis, Node ID главного Node ID (имя). В следующих таблицах обобщены все необходимые части для репликации (см. Результат вывода команды CLUSTER NODES ).
| Мастер Хост | master1 |
| ID главного узла | 3508ffe11ba5fbfbb93db5b21a413799272f5d0f |
| Подчиненный узел | slave1 |
| redis-cli -h slave1 -p 7379 REPLICATE CLUSTER 3508ffe11ba5fbfbb93db5b21a413799272f5d0f | |
Таблица 2
| Мастер Хост | master2 |
| ID главного узла | 610976e1ca5382b96718cd7e261d3543e6a99af4 |
| Подчиненный узел | slave2 |
| redis-cli -h slave2 -p 7380 REPLICATE CLUSTER 610976e1ca5382b96718cd7e261d3543e6a99af4 | |
Таблица 3
| Мастер Хост | master3 |
| ID главного узла | d8a2ae6221624212b76d9cf6c1483452e3c26117 |
| Подчиненный узел | slave3 |
| redis-cli -h slave3 -p 7381 REPLICATE КЛАСТЕРА d8a2ae6221624212b76d9cf6c1483452e3c26117 | |
Таблица 5
На этом этапе наш кластер Redis настроен правильно и имеет топологию, которую мы намеревались создать. Команда CLUSTER NODES показывает все подчиненные устройства, подключенные к мастерам.

Рисунок 10. CLUSTER NODES показывает главный и подчиненный узлы, соединенные вместе
Как мы видим, все узлы исправны, подключены и имеют правильные роли (хозяева и подчиненные).
7.3 Проверка правильности работы Redis Cluster
Как всегда в случае с Redis, лучший способ убедиться, что кластер Redis работает redis-cli некоторые команды, используя redis-cli . Обратите внимание: поскольку узлы в кластере не выполняют прокси-команды, а перенаправляют клиентов (см., Пожалуйста, схему Sharding (Partitioning) ), клиент должен поддерживать такой протокол, и поэтому redis-cli следует запускать с параметром командной строки -c ( с поддержкой кластера):
|
1
|
redis-cli -h master1 -p 6379 -c |
Попробуем установить сохраненные ключи (используя команду SET ) и запросить их позже (используя команду GET ). Поскольку мы распределили hash slots между тремя узлами, ключи также будут распределены по всем этим узлам. Первый ключ с именем some-key хранится на master1 узле master1 , к которому мы подключены.

Рисунок 11. Установка ключа some-key который будет храниться на master1
Но если мы попытаемся сохранить ключ с именем some-another-key , произойдет интересная вещь: redis-cli сообщает нам, что значение будет сохранено на узле с IP-адресом 192.168.3.105 ( master3 ), который содержит hash slot принадлежит этот ключ

Рисунок 12. Установка ключа some-another-key, который будет храниться на master3
Обратите внимание, что после выполнения команды redis-cli автоматически перенаправляется на узел 192.168.3.105 ( master3 ). Как только мы окажемся на узле кластера 192.168.3.105 ( master3 ), мы можем проверить, что hash slot действительно содержит ключ some-another-key, CLUSTER GETKEYSINSLOT команду CLUSTER GETKEYSINSLOT .
Рисунок 13. Проверка того, что hash slot 15929 содержит ключ some-another-key
Мы также можем проверить, что подчиненный узел Redis slave3 реплицировал ключ some-another-key с главного устройства ( master3 ) и возвращает его значение.
Рисунок 14. Раб Redis ( slave3 ) реплицировал ключи от мастера ( master3 )
7.4 Добавление и удаление узлов в работающем кластере Redis
В разделе Схема разбиения (разбиения) мы уже упоминали, что кластер Redis может быть перенастроен без простоя и обычно включает миграцию hash slots . Давайте добавим еще один мастер-узел master4 (с IP-адресом 192.168.7.105 ) в кластер и перенесем слот 15929 из узла master3 в master4 (это hash slot содержащий ключ some-another-key ). Ее конфигурация узла Redis master4 ( redis- master4.conf ):
|
1
2
3
4
5
|
port 6384cluster-enabled yescluster-config-file nodes.confcluster-node-timeout 5000appendonly yes |
|
1
|
redis-server redis-master4.conf |
|
1
|
redis-cli -h master1 -p 6379 CLUSTER MEET 192.168.7.105 6384 |

Рисунок 15. Redis master4 присоединился к кластеру
Процедура миграции hash slots включает в себя следующие этапы:
- На узле кластера, которому принадлежит определенный
hash slot(master3), должна быть выполнена командаCLUSTER SETSLOT slot MIGRATING, где находитсяNode IDузла нового узлаmaster4(который является d8095be33a2b9d06affcb5583f7150b1341f4c96).12redis-cli -h master3 -p 6381 CLUSTER SETSLOT 15929 MIGRATINGd8095be33a2b9d06affcb5583f7150b1341f4c96Когда слот помечен как
MIGRATING, узел будет принимать все запросы на запросы,MIGRATINGк этомуhash slot, но только если данный ключ существует, в противном случае запрос перенаправляется на узел, который является целью миграции. - На узле кластера, который должен стать новым владельцем определенного
hash slot(master4), командаCLUSTER SETSLOT slot IMPORTING, где находитсяNode IDтекущего владельцаmaster3(который является d8a2ae6221624212b76d9cf6c1483452e3c26117).12redis-cli -h master4 -p 6384 CLUSTER SETSLOT 15929 IMPORTINGd8a2ae6221624212b76d9cf6c1483452e3c26117 - На этом этапе все ключи из
hash slotдолжны быть перенесены сMIGRATEкомандыMIGRATE(см.MIGRATE) с текущего владельцаmaster3на нового владельцаmaster4. Поскольку у нас есть только один ключ, это легко.1redis-cli -h master3 -p 6381 MIGRATE master4 6384 some-another-key 0 0 - Наконец, когда
hash slotстановится пустым (что можно проверить сCLUSTER GETKEYSINSLOTкомандыCLUSTER GETKEYSINSLOT), его можно назначить новому узлу (master4).12redis-cli -h master3 -p 6381 CLUSTER SETSLOT 15929 NODEd8095be33a2b9d06affcb5583f7150b1341f4c96
Хотя очень полезно иметь представление о том, что происходит в деталях, выполнение такой процедуры вручную сложно и подвержено ошибкам. Но пакет Redis Cluster предоставляет redis-trib утилиту под названием redis-trib находится в папке src дистрибутива Redis. Он написан на Ruby и может быть очень полезным, упрощая управление вашим кластером Redis (см. Пожалуйста http://redis.io/topics/cluster-tutorial для более подробной информации).
8. Команды Redis Cluster
Redis Cluster добавляет дополнительный набор команд, предназначенных исключительно для управления кластером, мониторинга и настройки. Эти команды не были описаны во второй части руководства Redis Commands , поскольку они еще не доступны в стабильных выпусках. Кроме того, на веб-сайте Redis недостаточно документации по ним, но, по крайней мере, мы можем кратко описать каждую команду (многие из них вы уже видели в действии).
| команда | CLUSTER SETSLOT NODE слота <идентификатор узла> |
| Описание | Назначает hash slot для узла. Команда должна быть выполнена на узле, владеющем этим hash slot а hash slot не должен содержать ключей (должен быть пустым). |
Таблица 6
| команда | Слот CLUSTER SETSLOT IMPORTING <идентификатор узла> |
| Описание | Помечает hash slot как импортированный из <идентификатор узла> . <Идентификатор узла> должен быть владельцем этого hash slot . |
Таблица 7
| команда | Слот CLUSTER SETSLOT мигрирует <идентификатор узла> |
| Описание | Помечает hash slots как перенесенные в <идентификатор узла>. Команда должна быть выполнена на узле, владеющем этим hash slot . |
Таблица 8
| команда | КЛАСТЕРНЫЕ УЗЛЫ |
| Описание | Показывает текущий набор узлов в кластере Redis. |
Таблица 9
| команда | ADDSLOTS КЛАСТЕРА slot1 [slot2]… [slotN] |
| Описание | Назначает hash slots узлу Redis. |
Таблица 10
| команда | CLUSTER DELSLOTS slot1 [slot2]… [slotN] |
| Описание | Удаляет назначения hash slots из узла Redis. |
Таблица 11
| команда | CLUSTER ВСТРЕЧАЕТ IP-порт |
| Описание | Добавляет узел в кластер Redis. |
Таблица 12
| команда | CLUSTER FORGET <идентификатор узла> |
| Описание | Удаляет узел из кластера Redis. |
Таблица 13
| команда | CLUSTER REPLICATE <главный-идентификатор узла> |
| Описание | Делает этот узел точной копией главного узла <master-node-id> . |
Таблица 14
| команда | CLUSTER GETKEYSINSLOT количество слотов |
| Описание | Возвращает имена ключей из любого конкретного hash slot ограничивая вывод подсчетом количества ключей. Если узел, на котором выполняется эта команда, не является владельцем слота , команда не возвращает результатов. |
Таблица 15
9. Redis Sentinel
Еще одна замечательная, но все же экспериментальная особенность Redis — Redis Sentinel . Это система, предназначенная для управления живыми экземплярами Redis с учетом следующих целей:
- мониторинг : Sentinel постоянно проверяет, работают ли ваши главный и подчиненный экземпляры должным образом
- уведомление : Sentinel может уведомить, если что-то не так с одним из отслеживаемых экземпляров Redis
- автоматическое переключение при сбое : если какой-либо главный узел не работает должным образом, Sentinel может запустить процесс восстановления после сбоя, когда один из его подчиненных назначается ведущим
Redis Sentinel — очень многообещающая функция, но в настоящее время она разрабатывается в нестабильной ветке исходного кода Redis. Это еще не часть дистрибутивов Redis.
Для получения более подробной информации, пожалуйста, посмотрите на http://redis.io/topics/sentinel .
10. Что дальше
В этом разделе мы рассмотрели очень привлекательную и востребованную функцию Redis — кластеризацию. Хотя эта функция все еще находится в разработке, она достаточно стабильна, чтобы начать с ней играть. В следующей, последней части руководства мы рассмотрим программный Java API для доступа к Redis в различных сценариях развертывания.