Параллельные потоки базы данных
В моем предыдущем посте я писал о параллельной обработке содержимого базы данных с использованием параллельных потоков и ускорения. Параллельные потоки могут, во многих случаях, быть значительно быстрее, чем обычные последовательные потоки базы данных.

Пул потоков
Speedment — это инструмент потока ORM Java Toolkit и Java времени выполнения с открытым исходным кодом, который оборачивает существующую базу данных и ее таблицы в потоки Java 8. Мы можем использовать существующую базу данных и запустить инструмент Speedment, и он сгенерирует классы POJO, которые соответствуют таблицам, которые мы выбрали с помощью инструмента. Отличительной особенностью Speedment является то, что он поддерживает параллельные потоки базы данных и может использовать различные параллельные стратегии для дальнейшей оптимизации производительности. По умолчанию параллельные потоки выполняются в общем ForkJoinPool где они потенциально могут конкурировать с другими задачами. В этом посте мы узнаем, как мы можем выполнять потоки баз данных Parallell по своему усмотрению.
ForkJoinPool, позволяющий намного лучше контролировать нашу среду исполнения.
Начало работы со скоростью
Отправляйтесь на Open-Souce Speedment на GitHub и узнайте, как начать работу с проектом Speedment. Подключить инструмент к существующей базе данных очень просто. Читай мой
предыдущий пост для получения дополнительной информации о том, как таблица базы данных и класс PrimeUtil выглядят для примеров ниже.
Выполнение по умолчанию ForkJoinPool
Вот приложение, о котором я говорил в моем предыдущем посте, которое будет параллельно сканировать таблицу базы данных на предмет неопределенных кандидатов на простые числа, а затем определит, являются ли они простыми числами или нет, и соответствующим образом обновит таблицу. Вот как это выглядит:
|
1
2
3
4
5
6
7
8
9
|
Manager<PrimeCandidate> candidatesHigh = app.configure(PrimeCandidateManager.class) .withParallelStrategy(ParallelStrategy.computeIntensityHigh()) .build(); candidatesHigh.stream() .parallel() // Use a parallel stream .filter(PrimeCandidate.PRIME.isNull()) // Only consider nondetermined prime candidates .map(pc -> pc.setPrime(PrimeUtil.isPrime(pc.getValue()))) // Sets if it is a prime or not .forEach(candidatesHigh.updater()); // Apply the Manager's updater |
Сначала мы создаем поток по всем кандидатам (используя параллельную стратегию с именем ParallelStrategy.computeIntensityHigh ()), где столбец ‘prime’ равен null используя метод stream().filter(PrimeCandidate.PRIME.isNull()) . Затем для каждого такого первичного кандидата в pc мы устанавливаем для столбца ‘prime’ значение true если pc.getValue() является простым, или false если pc.getValue() не является простым. Интересно, что pc.setPrime() возвращает сам ПК сущности, что позволяет нам легко помечать несколько потоковых операций. В последней строке мы обновляем базу данных с результатом нашей проверки, применяя функцию candidatesHigh.updater() .
Опять же, не забудьте проверить мой предыдущий пост о деталях и преимуществах параллельных стратегий. Короче говоря, параллельная стратегия Java по умолчанию хорошо работает для низких вычислительных требований, потому что она помещает большое количество начальных рабочих элементов в каждый поток. Параллельные стратегии Speedment работают намного лучше для средних и высоких вычислительных требований, когда небольшое количество рабочих элементов размещается в участвующих потоках.
Поток будет определять простые числа полностью параллельно, и потоки выполнения будут использовать общий ForkJoinPool как видно на этом рисунке (мой ноутбук имеет 4 ядра ЦП и 8 потоков ЦП):
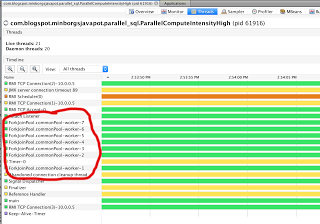
Использовать пользовательскую службу исполнителя
Как мы узнали в начале этого поста, параллельные потоки выполняются общим
ForkJoinPool по умолчанию. Но иногда мы хотим использовать нашего собственного исполнителя, возможно, потому что мы боимся наводнения общего
ForkJoinPool , чтобы другие задачи не могли работать должным образом. Определение нашего собственного исполнителя может быть легко выполнено для Speedment (и других потоковых библиотек) следующим образом:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
final ForkJoinPool forkJoinPool = new ForkJoinPool(3); forkJoinPool.submit(() -> candidatesHigh.stream() .parallel() .filter(PrimeCandidate.PRIME.isNull()) .map(pc -> pc.setPrime(PrimeUtil.isPrime(pc.getValue()))) .forEach(candidatesHigh.updater()); ); try { forkJoinPool.shutdown(); forkJoinPool.awaitTermination(1, TimeUnit.HOURS); } catch (InterruptedException ie) { ie.printStackTrace(); } |
Код приложения не изменен, но заключен в пользовательский ForkJoinPool которым мы можем управлять сами. В приведенном выше примере мы настроили пул потоков только с тремя рабочими потоками. Рабочие потоки не используются совместно с потоками в общем ForkJoinPool .
Вот как выглядят потоки при использовании пользовательского сервиса executor:
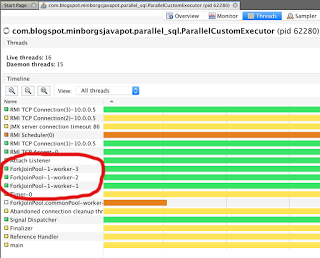
Таким образом, мы можем управлять как самим ThreadPool так и точно, как рабочие элементы размещаются в этом пуле, используя параллельную стратегию!
Поддерживайте тепло в своих бассейнах!
| Ссылка: | Работайте с параллельными потоками базы данных, используя пользовательские пулы потоков от нашего партнера JCG Per Minborg в блоге Minborg о Java Pot . |