Что такое параллельный поток базы данных?
Прочтите этот пост и узнайте, как вы можете обрабатывать данные из базы данных параллельно, используя параллельные потоки и ускорение. Параллельные потоки при многих обстоятельствах могут быть значительно быстрее, чем обычные последовательные потоки.
С появлением Java 8 мы получили долгожданную библиотеку Stream . Одним из преимуществ потоков является то, что очень легко сделать потоки параллельными. По сути, мы можем взять любой поток, а затем просто применить метод parallel() и мы получим параллельный поток вместо последовательного. По умолчанию параллельные потоки выполняются общим ForkJoinPool .

Шпиль и герцог работают параллельно
Итак, если у нас есть рабочие элементы, которые относительно интенсивно используют вычислительные ресурсы, тогда параллельные потоки часто имеют смысл. Параллельные потоки хороши, если рабочие элементы, которые должны выполняться в параллельных потоковых конвейерах, в основном не связаны и когда усилия по разделению работы в несколько потоков относительно мало. Точно так же усилия объединения параллельных результатов также должны быть относительно низкими.
Speedment — это поток ORM Java Toolkit с открытым исходным кодом и инструмент RuntimeJava, который оборачивает существующую базу данных и ее таблицы в потоки Java 8. Мы можем использовать существующую базу данных и запустить инструмент Speedment, и он сгенерирует классы POJO, которые соответствуют таблицам, которые мы выбрали с помощью инструмента.
Одна из замечательных особенностей Speedment заключается в том, что потоки базы данных поддерживают параллелизм с использованием стандартной семантики потока. Таким образом, мы можем легко работать с содержимым базы данных параллельно и получать результаты намного быстрее, чем если бы мы обрабатывали потоки последовательно!
Начало работы со скоростью
Посетите open-souce Speedment на GitHub и узнайте, как начать работу с проектом Speedment. Должно быть очень легко подключить инструмент к существующей базе данных.
В этом посте следующая таблица MySQL используется для приведенных ниже примеров.
|
1
2
3
4
5
6
|
CREATE TABLE `prime_candidate` ( `id` int(11) NOT NULL AUTO_INCREMENT, `value` bigint(20) NOT NULL, `prime` bit(1) DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB; |
Идея состоит в том, что люди могут вставлять значения в эту таблицу, и тогда мы напишем приложение, которое вычисляет, являются ли вставленные значения простыми числами или нет. В реальном случае мы могли бы использовать любую таблицу в базе данных MySQL, PostgreSQL или MariaDB.
Написание последовательного потокового решения
Во-первых, нам нужен метод, который возвращает значение, если значение является простым числом. Вот простой способ сделать это. Обратите внимание, что алгоритм специально сделан медленным, поэтому мы можем ясно видеть влияние параллельных потоков на дорогостоящую операцию.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
public class PrimeUtil { /** * Returns if the given parameter is a prime number. * * @param n the given prime number candidate * @return if the given parameter is a prime number */ static boolean isPrime(long n) { // primes are equal or greater than 2 if (n < 2) { return false; } // check if n is even if (n % 2 == 0) { // 2 is the only even prime // all other even n:s are not return n == 2; } // if odd, then just check the odds // up to the square root of n // for (int i = 3; i * i <= n; i += 2) { // // Make the methods purposely slow by // checking all the way up to n for (int i = 3; i <= n; i += 2) { if (n % i == 0) { return false; } } return true; }} |
Опять же, цель этого поста — не разработать эффективный метод определения простых чисел.
Учитывая этот простой метод простых чисел, теперь мы можем легко написать приложение Speedment, которое будет сканировать таблицу базы данных на предмет неопределенных кандидатов на простые числа, а затем определит, являются ли они простыми числами или нет, и соответствующим образом обновит таблицу. Вот как это может выглядеть:
|
01
02
03
04
05
06
07
08
09
10
11
|
final JavapotApplication app = new JavapotApplicationBuilder() .withPassword("javapot") // Replace with the real password .withLogging(LogType.STREAM) .build(); final Manager<PrimeCandidate> candidates = app.getOrThrow(PrimeCandidateManager.class); candidates.stream() .filter(PrimeCandidate.PRIME.isNull()) // Filter out undetermined primes .map(pc -> pc.setPrime(PrimeUtil.isPrime(pc.getValue()))) // Sets if it is a prime or not .forEach(candidates.updater()); // Applies the Manager's updater |
Последняя часть содержит интересные вещи. Во-первых, мы создаем поток по всем кандидатам, где столбец «премьер»
null с использованием метода stream().filter(PrimeCandidate.PRIME.isNull()) . Важно понимать, что реализация потока ускорения распознает предикат фильтра и сможет использовать его для уменьшения количества кандидатов, которые фактически извлекаются из базы данных (например, «SELECT * FROM кандидата, ГДЕ простое число IS NULL» будет использоваться).
Затем для каждого такого первичного кандидата в pc мы устанавливаем для столбца ‘prime’ значение true если pc.getValue() является простым, или false если pc.getValue() не является простым. Интересно, что pc.setPrime() возвращает сам ПК сущности, что позволяет нам легко помечать несколько потоковых операций. В последней строке мы обновляем базу данных с результатом нашей проверки, применяя функцию candidates.updater() . Таким образом, основная функциональность этого приложения действительно однострочная (разбита на пять строк для улучшения читабельности).
Теперь, прежде чем мы сможем протестировать наше приложение, нам нужно сгенерировать некоторый ввод тестовых данных. Вот пример того, как это можно сделать с помощью Speedment:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
final JavapotApplication app = new JavapotApplicationBuilder() .withPassword("javapot") // Replace with the real password .build(); final Manager<PrimeCandidate> candidates = app.getOrThrow(PrimeCandidateManager.class); final Random random = new SecureRandom(); // Create a bunch of new prime candidates random.longs(1_100, 0, Integer.MAX_VALUE) .mapToObj(new PrimeCandidateImpl()::setValue) // Sets the random value .forEach(candidates.persister()); // Applies the Manager's persister function |
Опять же, мы можем выполнить нашу задачу с помощью нескольких строк кода.
Попробуйте параллельный поток по умолчанию
Если мы хотим распараллелить наш поток, нам просто нужно добавить один единственный метод к нашему предыдущему решению:
|
1
2
3
4
5
|
candidates.stream() .parallel() // Now indicates a parallel stream .filter(PrimeCandidate.PRIME.isNull()) .map(pc -> pc.setPrime(PrimeUtil.isPrime(pc.getValue()))) .forEach(candidates.updater()); // Applies the Manager's updater |
И мы параллельны! Однако по умолчанию Speedment использует поведение параллелизации Java по умолчанию (как определено в Spliterators::spliteratorUnknownSize ), которое оптимизировано для операций, не Spliterators::spliteratorUnknownSize вычислений. Если мы проанализируем поведение параллелизации Java по умолчанию, мы определим, что он будет использовать первый поток для первых 1024 рабочих элементов, второй поток для следующих 2 * 1024 = 2048 рабочих элементов, а затем 3 * 1024 = 3072 рабочих элементов для третьего нить и тд.
Это плохо для нашего приложения, где стоимость каждой операции очень высока. Если мы вычисляем 1100 простых кандидатов, мы будем использовать только два потока, потому что первый поток будет принимать первые 1024 элемента, а второй поток — остальные 76. Современные серверы имеют гораздо больше потоков, чем это. Прочтите следующий раздел, чтобы узнать, как мы можем решить эту проблему.
Встроенные стратегии распараллеливания
У Speedment есть несколько встроенных стратегий распараллеливания, которые мы можем выбрать в зависимости от ожидаемых вычислительных требований рабочего элемента. Это улучшение по сравнению с Java 8, которая имеет только одну стратегию по умолчанию. Встроенные параллельные стратегии:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
@FunctionalInterfacepublic interface ParallelStrategy { /** * A Parallel Strategy that is Java's default <code>Iterator</code> to * <code>Spliterator</code> converter. It favors relatively large sets (in * the ten thousands or more) with low computational overhead. * * @return a ParallelStrategy */ static ParallelStrategy computeIntensityDefault() {...} /** * A Parallel Strategy that favors relatively small to medium sets with * medium computational overhead. * * @return a ParallelStrategy */ static ParallelStrategy computeIntensityMedium() {...} /** * A Parallel Strategy that favors relatively small to medium sets with high * computational overhead. * * @return a ParallelStrategy */ static ParallelStrategy computeIntensityHigh() {...} /** * A Parallel Strategy that favors small sets with extremely high * computational overhead. The set will be split up in solitary elements * that are executed separately in their own thread. * * @return a ParallelStrategy */ static ParallelStrategy computeIntensityExtreme() {...} <T> Spliterator<T> spliteratorUnknownSize(Iterator<? extends T> iterator, int characteristics); static ParallelStrategy of(final int... batchSizes) { return new ParallelStrategy() { @Override public <T> Spliterator<T> spliteratorUnknownSize(Iterator<? extends T> iterator, int characteristics) { return ConfigurableIteratorSpliterator.of(iterator, characteristics, batchSizes); } }; } |
Применение параллельной стратегии
Единственное, что нам нужно сделать, это настроить стратегию распараллеливания для такого менеджера, и мы готовы идти дальше:
|
1
2
3
4
5
6
7
8
9
|
Manager<PrimeCandidate> candidatesHigh = app.configure(PrimeCandidateManager.class) .withParallelStrategy(ParallelStrategy.computeIntensityHigh()) .build(); candidatesHigh.stream() // Better parallel performance for our case! .parallel() .filter(PrimeCandidate.PRIME.isNull()) .map(pc -> pc.setPrime(PrimeUtil.isPrime(pc.getValue()))) .forEach(candidatesHigh.updater()); |
Стратегия ParallelStrategy.computeIntensityHigh() разбивает рабочие элементы на гораздо более мелкие фрагменты. Это даст нам значительно лучшую производительность, так как теперь мы собираемся использовать все доступные потоки. Если мы посмотрим под капот, то увидим, что стратегия определяется следующим образом:
|
1
2
3
4
|
private final static int[] BATCH_SIZES = IntStream.range(0, 8) .map(ComputeIntensityUtil::toThePowerOfTwo) .flatMap(ComputeIntensityUtil::repeatOnHalfAvailableProcessors) .toArray(); |
Это означает, что на компьютере с 8 потоками он поместит один элемент в поток 1-4, два элемента в поток 5-8, и когда задачи будут выполнены, в следующих четырех доступных потоках будет четыре элемента, затем восемь элементов и так до тех пор, пока мы не достигнем 256, что является максимальным количеством элементов, помещаемых в любой поток. Очевидно, что эта стратегия намного лучше, чем стандартная стратегия Java для этой конкретной проблемы.
Вот как выглядят потоки в общем ForkJoinPool на моем 8-поточном ноутбуке:
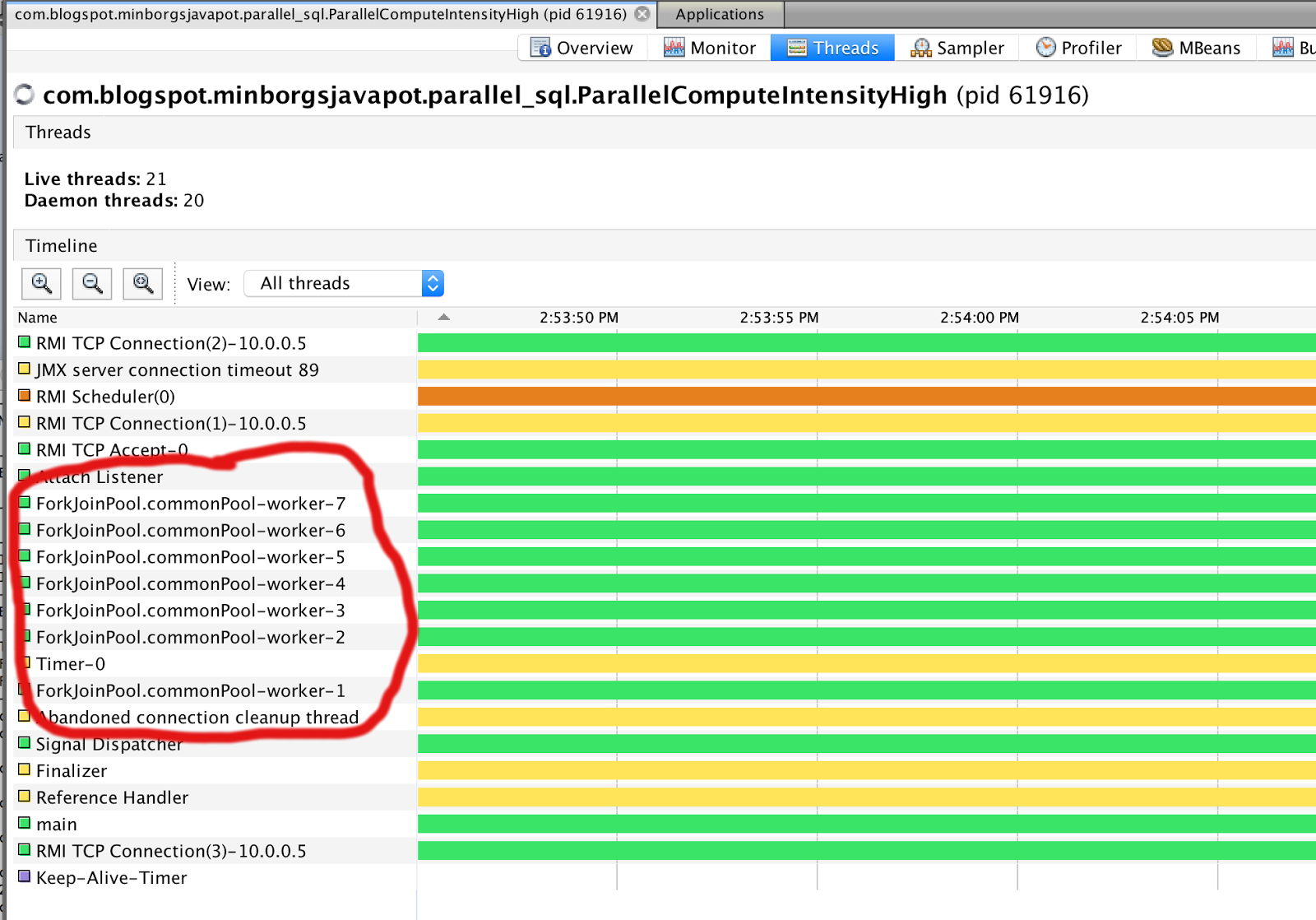
Создайте свою собственную параллельную стратегию
Одна из отличительных особенностей Speedment заключается в том, что мы очень легко можем написать нашу стратегию распараллеливания и просто внедрить ее в наши потоки. Рассмотрим эту пользовательскую стратегию распараллеливания:
|
01
02
03
04
05
06
07
08
09
10
|
public static class MyParallelStrategy implements ParallelStrategy { private final static int[] BATCH_SIZES = {1, 2, 4, 8}; @Override public <T> Spliterator<T> spliteratorUnknownSize(Iterator<? extends T> iterator, int characteristics) { return ConfigurableIteratorSpliterator.of(iterator, characteristics, BATCH_SIZES); } } |
Что, собственно, можно выразить еще короче
|
1
|
ParallelStrategy myParallelStrategy = ParallelStrategy.of(1, 2, 4, 8); |
Эта стратегия помещает один рабочий элемент в первый доступный поток, два — во второй, четыре — в третий, восемь — в четвертый, причем восемь является последней цифрой в нашем массиве. Последняя цифра будет использоваться для всех последующих доступных потоков. Таким образом, ордер действительно становится 1, 2, 4, 8, 8, 8, 8, … Теперь мы можем использовать нашу новую стратегию следующим образом:
|
1
2
3
4
5
6
7
8
9
|
Manager<PrimeCandidate> candidatesCustom = app.configure(PrimeCandidateManager.class) .withParallelStrategy(myParallelStrategy) .build(); candidatesCustom.stream() .parallel() .filter(PrimeCandidate.PRIME.isNull()) .map(pc -> pc.setPrime(PrimeUtil.isPrime(pc.getValue()))) .forEach(candidatesCustom.updater()); |
Вуаля! У нас есть полный контроль над тем, как рабочие элементы размещаются в доступных потоках выполнения.
Ориентиры
Все тесты использовали один и тот же вклад основных кандидатов. Тесты проводились на MacBook Pro, Intel Core i7 с тактовой частотой 2,2 ГГц, 4 физических ядра и 8 потоков.
|
1
2
3
4
5
|
StrategySequential 265 s (One thread processed all 1100 items)Parallel Default Java 8 235 s (Because 1024 items were processed by thread 1 and 76 items by thread 2)Parallel computeIntensityHigh() 69 s (All 4 hardware cores were used) |
Выводы
Speedment поддерживает параллельную обработку содержимого базы данных. Speedment поддерживает множество параллельных стратегий, позволяющих полностью использовать среду исполнения.
Мы можем легко создавать свои собственные параллельные стратегии и использовать их в наших потоках Speedment. Можно значительно повысить производительность, тщательно выбирая параллельную стратегию, а не просто настройку по умолчанию на Java.
| Ссылка: | Работайте с параллельными потоками базы данных, используя Java 8 от нашего партнера JCG Per Minborg в блоге Minborg по Java Pot . |