обзор
Зачем конвертировать XML в JSON для необработанного использования в MongoDB?
Поскольку MongoDB использует документы JSON для хранения записей, так же как таблицы и строки хранят записи в реляционной базе данных, нам, естественно, необходимо преобразовать наш XML в JSON.
Некоторым приложениям может потребоваться хранить необработанный (неизмененный) JSON, поскольку существует неопределенность в отношении структуры данных.
Существуют сотни стандартов на основе XML . Если приложение должно обрабатывать XML-файлы, которые не соответствуют одному и тому же стандарту, существует неопределенность в отношении структуры данных.
Зачем использовать Spring Batch?
Spring Batch предоставляет многократно используемые функции, которые необходимы для обработки больших объемов записей, и другие функции, которые позволяют выполнять объемные и высокопроизводительные пакетные задания. Сайт Spring хорошо документировал Spring Batch .
Для другого учебника по Spring Batch см. Мой предыдущий пост по обработке CSV с помощью Spring Batch .
0 — преобразование XML в JSON для использования в MongoDB с примером приложения Spring Batch
Пример приложения преобразует документ XML, который является «политикой» для настройки списка воспроизведения музыки. Эта политика предназначена для напоминания реальных документов конфигурации кибербезопасности. Это короткий документ, но иллюстрирующий, как вы будете искать сложные XML-документы.
Подход, который мы будем использовать в нашем руководстве, предназначен для обработки XML-файлов различного стиля. Мы хотим быть в состоянии справиться с неожиданным. Вот почему мы храним данные «сырыми».
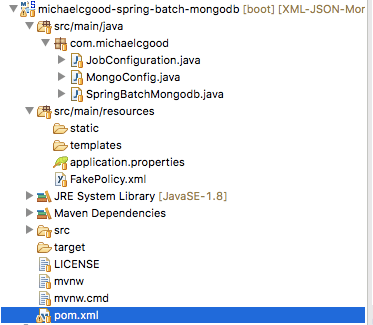
1 — Структура проекта
Это типичная Maven структура. У нас есть один пакет для этого примера приложения. Файл XML находится в src / main / resources .
2 — Зависимости проекта
Помимо наших типичных зависимостей Spring Boot, мы включаем зависимости для встроенной базы данных MongoDB и для обработки JSON.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" <modelVersion>4.0.0</modelVersion> <groupId>com.michaelcgood</groupId> <artifactId>michaelcgood-spring-batch-mongodb</artifactId> <version>0.0.1</version> <packaging>jar</packaging> <name>michaelcgood-spring-batch-mongodb</name> <description>Michael C Good - XML to JSON + MongoDB + Spring Batch Example</description> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>1.5.7.RELEASE</version> <relativePath /> <!-- lookup parent from repository --> </parent> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-batch</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>de.flapdoodle.embed</groupId> <artifactId>de.flapdoodle.embed.mongo</artifactId> <version>1.50.5</version> </dependency> <dependency> <groupId>cz.jirutka.spring</groupId> <artifactId>embedmongo-spring</artifactId> <version>RELEASE</version> </dependency> <dependency> <groupId>org.json</groupId> <artifactId>json</artifactId> <version>20170516</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-mongodb</artifactId> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build></project> |
3 — XML-документ
Это пример документа политики, созданного для этого урока. Его структура основана на реальных документах политики кибербезопасности.
- Обратите внимание, что родительским документом является тег Policy.
- Важная информация находится в теге Group.
- Посмотрите на значения, которые находятся внутри тегов, такие как идентификатор в политике или дата в статусе.
В этом небольшом документе содержится много информации, которую следует рассмотреть. Например, есть также пространство имен XML (xmlns). Мы не будем касаться этого в оставшейся части учебника, но в зависимости от ваших целей это может быть чем-то, что может добавить логику.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
<?xml version="1.0"?> <status date="2017-10-18">draft</status> <title xmlns:xhtml="http://www.w3.org/1999/xhtml">Guide to the Configuration of Music Playlist</title> configuration settings for a playlist that I listen to while I work on software development. Providing myself with such guidance reminds me how to efficiently configure my playlist. Lorem ipsum <html:i xmlns:html="http://www.w3.org/1999/xhtml">Lorem ipsum,</html:i> and Lorem ipsum. Some example </description> <Group id="remediation_functions"> <title xmlns:xhtml="http://www.w3.org/1999/xhtml" >Remediation functions used by the SCAP Security Guide Project</title> <description xmlns:xhtml="http://www.w3.org/1999/xhtml" >XCCDF form of the various remediation functions as used by remediation scripts from the SCAP Security Guide Project</description> <Value id="is_the_music_good" prohibitChanges="true" > Lorem ipsum Lorem ipsum Lorem ipsum Lorem ipsum Lorem ipsum Lorem ipsum Lorem ipsum Lorem ipsum </description> <value> function fix_bad_playlist { # Load function arguments into local variables Lorem ipsum Lorem ipsum Lorem ipsum # Check sanity of the input if [ $# Lorem ipsum ] then echo "Usage: Lorem ipsum" echo "Aborting." exit 1 fi } </value> </Value> </Group> </Policy> |
4 — Конфигурация MongoDB
Ниже мы указываем, что мы используем встроенную базу данных MongoDB, делаем ее обнаруживаемой для сканирования компонентов, которая включена в удобную аннотацию @SpringBootApplication , и указываем, что mongoTemplate будет bean-компонентом.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
package com.michaelcgood;import java.io.IOException;import cz.jirutka.spring.embedmongo.EmbeddedMongoFactoryBean;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.data.mongodb.core.*;import com.mongodb.MongoClient; @Configurationpublic class MongoConfig { private static final String MONGO_DB_URL = "localhost"; private static final String MONGO_DB_NAME = "embeded_db"; @Bean public MongoTemplate mongoTemplate() throws IOException { EmbeddedMongoFactoryBean mongo = new EmbeddedMongoFactoryBean(); mongo.setBindIp(MONGO_DB_URL); MongoClient mongoClient = mongo.getObject(); MongoTemplate mongoTemplate = new MongoTemplate(mongoClient, MONGO_DB_NAME); return mongoTemplate; }} |
5 — Обработка XML в JSON
step1 () нашего Spring Batch Job содержит три метода, помогающих обработать XML в JSON. Мы рассмотрим каждый в отдельности.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
@Bean public Step step1() { return stepBuilderFactory.get("step1") .tasklet(new Tasklet() { @Override public RepeatStatus execute(StepContribution stepContribution, ChunkContext chunkContext) throws Exception { // get path of file in src/main/resources Path xmlDocPath = Paths.get(getFilePath()); // process the file to json String json = processXML2JSON(xmlDocPath); // insert json into mongodb insertToMongo(json); return RepeatStatus.FINISHED; } }).build(); } |
5.1 — getFilePath ()
Этот метод просто получает путь к файлу, который передается в качестве параметра методу processXML2JSON .
Замечания:
- ClassLoader помогает нам найти файл XML в нашей папке ресурсов.
|
01
02
03
04
05
06
07
08
09
10
|
// no parameter method for creating the path to our xml file private String getFilePath(){ String fileName = "FakePolicy.xml"; ClassLoader classLoader = getClass().getClassLoader(); File file = new File(classLoader.getResource(fileName).getFile()); String xmlFilePath = file.getAbsolutePath(); return xmlFilePath; } |
5.2 — processXML2JSON (xmlDocPath)
Строка, возвращаемая getFilePath , передается в этот метод в качестве параметра. JSONOBject создается из строки XML-файла.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
// takes a parameter of xml path and returns json as a string private String processXML2JSON(Path xmlDocPath) throws JSONException { String XML_STRING = null; try { XML_STRING = Files.lines(xmlDocPath).collect(Collectors.joining("\n")); } catch (IOException e) { e.printStackTrace(); } JSONObject xmlJSONObj = XML.toJSONObject(XML_STRING); String jsonPrettyPrintString = xmlJSONObj.toString(PRETTY_PRINT_INDENT_FACTOR); System.out.println("PRINTING STRING :::::::::::::::::::::" + jsonPrettyPrintString); return jsonPrettyPrintString; } |
5.3 — insertToMongo (json)
Мы вставляем проанализированный JSON в документ MongoDB. Затем мы вставляем этот документ с помощью @Autowired mongoTemplate в коллекцию с именем «foo».
|
1
2
3
4
5
|
// inserts to our mongodb private void insertToMongo(String jsonString){ Document doc = Document.parse(jsonString); mongoTemplate.insert(doc, "foo"); } |
6 — Запрос MongoDB
step2 () нашего Spring Batch Job содержит наши запросы MongoDB.
- mongoTemplate.collectionExists возвращает логическое значение, основанное на существовании коллекции.
- mongoTemplate.getCollection («foo»). find () возвращает все документы в коллекции.
- alldocs.toArray () возвращает массив объектов DBObject.
- Затем мы вызываем три метода, которые мы рассмотрим индивидуально ниже.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
|
public Step step2(){ return stepBuilderFactory.get("step2") .tasklet(new Tasklet(){ @Override public RepeatStatus execute(StepContribution stepContribution, ChunkContext chunkContext) throws Exception{ // all printing out to console removed for post's brevity // checks if our collection exists Boolean doesexist = mongoTemplate.collectionExists("foo"); // show all DBObjects in foo collection DBCursor alldocs = mongoTemplate.getCollection("foo").find(); List<DBObject> dbarray = alldocs.toArray(); // execute the three methods we defined for querying the foo collection String result = doCollect(); String resultTwo = doCollectTwo(); String resultThree = doCollectThree(); return RepeatStatus.FINISHED; } }).build(); } |
6.1 — Первый запрос
Цель этого запроса — найти документ, в котором style = ”STY_1.1 ″ . Для этого нам нужно запомнить, где находится стиль в документе. Это дитя политики; поэтому мы рассматриваем это в критериях как Policy.style .
Другая цель этого запроса — вернуть только поле id Политики. Это также просто ребенок политики.
Результат возвращается с помощью вызова этого метода: mongoTemplate.findOne (query, String.class, «foo»); , Выходные данные являются String, поэтому вторым параметром является String.class . Третий параметр — это название нашей коллекции.
|
1
2
3
4
5
6
|
public String doCollect(){ Query query = new Query(); query.addCriteria(Criteria.where("Policy.style").is("STY_1.1")).fields().include("Policy.id"); String result = mongoTemplate.findOne(query, String.class, "foo"); return result; } |
6.2 — Второй запрос
Разница между вторым запросом и первым запросом заключается в возвращаемых полях. Во втором запросе мы возвращаем Value, который является дочерним по отношению к Policy и Group.
|
1
2
3
4
5
6
7
|
public String doCollectTwo(){ Query query = new Query(); query.addCriteria(Criteria.where("Policy.style").is("STY_1.1")).fields().include("Policy.Group.Value"); String result = mongoTemplate.findOne(query, String.class, "foo"); return result; } |
6.3 — Третий запрос
Критерии для третьего запроса разные. Мы только хотим вернуть документ с идентификатором «NRD-1» и датой статуса «2017-10-18» . Мы хотим вернуть только два поля: заголовок и описание, которые оба являются потомками Value.
Обратитесь к документу XML или напечатанному JSON в демонстрационном примере ниже для дальнейшего разъяснения запросов.
|
1
2
3
4
5
6
7
|
public String doCollectThree(){ Query query = new Query(); query.addCriteria(Criteria.where("Policy.id").is("NRD-1").and("Policy.status.date").is("2017-10-18")).fields().include("Policy.Group.Value.title").include("Policy.Group.Value.description"); String result = mongoTemplate.findOne(query, String.class, "foo"); return result; } |
7 — Весеннее пакетное задание
Задание начинается с шага 1 и затем вызывает шаг 2.
|
1
2
3
4
5
6
7
|
@Bean public Job xmlToJsonToMongo() { return jobBuilderFactory.get("XML_Processor") .start(step1()) .next(step2()) .build(); } |
8 — @SpringBootApplication
Это стандартный класс со статическим void main и @SpringBootApplication .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
package com.michaelcgood;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.EnableAutoConfiguration;import org.springframework.boot.autoconfigure.SpringBootApplication;import org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration;@SpringBootApplication@EnableAutoConfiguration(exclude={DataSourceAutoConfiguration.class})public class SpringBatchMongodb { public static void main(String[] args) { SpringApplication.run(SpringBatchMongodb.class, args); }} |
9 — Демо
9.1 — шаг1
JSON печатается в виде строки. Я сократил выходное описание ниже, потому что оно длинное.
|
1
2
3
4
5
6
|
Executing step: [step1]PRINTING STRING :::::::::::::::::::::{"Policy": { "Group": { "Value": { "prohibitChanges": true, "description": { |
9.2 — шаг2
Я сократил результаты, чтобы отформатировать вывод для записи в блоге.
|
1
|
Executing step: [step2] |
Проверка существования коллекции
|
1
|
Status of collection returns :::::::::::::::::::::true |
Показать все объекты
|
1
|
list of db objects returns:::::::::::::::::::::[{ "_id" : { "$oid" : "59e7c0324ad9510acf5773c0"} , [..] |
Просто верните идентификатор политики
|
1
|
RESULT:::::::::::::::::::::{ "_id" : { "$oid" : "59e7c0324ad9510acf5773c0"} , "Policy" : { "id" : "NRD-1"}} |
Чтобы увидеть другие результаты, выведенные на консоль, раскройте / загрузите код с Github и запустите приложение.
10 — Вывод
Мы рассмотрели, как преобразовать XML в JSON, сохранить JSON в MongoDB и как запросить базу данных для конкретных результатов.
Дальнейшее чтение:
Исходный код есть на Github
| Опубликовано на Java Code Geeks с разрешения Майкла Гуда, партнера нашей программы JCG . Смотрите оригинальную статью здесь: Преобразование XML в JSON + Raw в MongoDB + Spring Batch
Мнения, высказанные участниками Java Code Geeks, являются их собственными. |