обзор
Темы, которые мы будем обсуждать, включают в себя основные концепции пакетной обработки в Spring Batch и способы импорта данных из CSV в базу данных.
0 — пример приложения Spring Batch CSV Processing
Мы создаем приложение, которое демонстрирует основы Spring Batch для обработки файлов CSV. Наше демонстрационное приложение позволит нам обрабатывать CSV-файл, содержащий сотни записей названий японских аниме.
0.1 — CSV
Я скачал CSV, который мы будем использовать из этого репозитория Github , и он содержит довольно полный список аниме.
Вот скриншот CSV, открытого в Microsoft Excel

Посмотреть и скачать код с Github
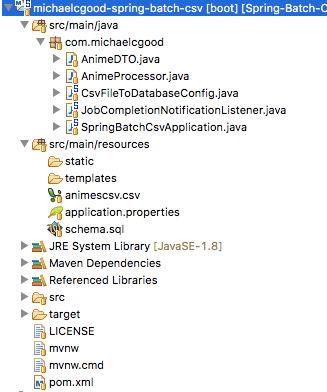
1 — Структура проекта
2 — Зависимости проекта
Помимо типичных зависимостей Spring Boot, мы включили spring-boot-starter-batch, которая является зависимостью для Spring Batch, как следует из названия, и hsqldb для базы данных в памяти. Мы также включаем commons-lang3 для ToStringBuilder.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" <modelVersion>4.0.0</modelVersion> <groupId>com.michaelcgood</groupId> <artifactId>michaelcgood-spring-batch-csv</artifactId> <version>0.0.1</version> <packaging>jar</packaging> <name>michaelcgood-spring-batch-csv</name> <description>Michael C Good - Spring Batch CSV Example Application</description> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>1.5.7.RELEASE</version> <relativePath /> <!-- lookup parent from repository --> </parent> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-batch</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.hsqldb</groupId> <artifactId>hsqldb</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-lang3</artifactId> <version>3.6</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build></project> |
3 — Модель
Это POJO, который моделирует поля аниме. Поля:
- МНЕ БЫ. Для простоты мы рассматриваем идентификатор как строку. Однако это можно изменить на другой тип данных, например, Integer или Long.
- Заглавие. Это название аниме, и оно подходит для строки.
- Описание. Это описание аниме, которое длиннее заголовка, и его также можно рассматривать как строку.
Важно отметить, что наш конструктор класса для трех полей: общедоступный AnimeDTO (идентификатор строки, заголовок строки, описание строки). Это будет использовано в нашем приложении. Также, как обычно, нам нужно сделать конструктор по умолчанию без параметров, иначе Java выдаст ошибку.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
package com.michaelcgood;import org.apache.commons.lang3.builder.ToStringBuilder;/** * Contains the information of a single anime * * @author Michael C Good michaelcgood.com */public class AnimeDTO { public String getId() { return id; } public void setId(String id) { this.id = id; } public String getTitle() { return title; } public void setTitle(String title) { this.title = title; } public String getDescription() { return description; } public void setDescription(String description) { this.description = description; } private String id; private String title; private String description; public AnimeDTO(){ } public AnimeDTO(String id, String title, String description){ this.id = id; this.title = title; this.description = title; } @Override public String toString() { return new ToStringBuilder(this) .append("id", this.id) .append("title", this.title) .append("description", this.description) .toString(); }} |
4 — Конфигурация файла CSV в базу данных
В этом классе много чего происходит, и не все написано сразу, поэтому мы собираемся пройтись по коду поэтапно. Посетите Github, чтобы увидеть код в полном объеме.
4.1 — Читатель
Как говорится в документации Spring Batch, FlatFileIteamReader будет «читать строки данных из плоского файла, которые обычно описывают записи с полями данных, которые определены фиксированными позициями в файле или разделены каким-либо специальным символом (например, запятой)».
Мы имеем дело с CSV, поэтому, конечно, данные разделяются запятой, что делает их идеальными для использования с нашим файлом.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
@Bean public FlatFileItemReader<AnimeDTO> csvAnimeReader(){ FlatFileItemReader<AnimeDTO> reader = new FlatFileItemReader<AnimeDTO>(); reader.setResource(new ClassPathResource("animescsv.csv")); reader.setLineMapper(new DefaultLineMapper<AnimeDTO>() {{ setLineTokenizer(new DelimitedLineTokenizer() {{ setNames(new String[] { "id", "title", "description" }); }}); setFieldSetMapper(new BeanWrapperFieldSetMapper<AnimeDTO>() {{ setTargetType(AnimeDTO.class); }}); }}); return reader; } |
Важные точки:
-
- FlatFileItemReader параметризован с моделью. В нашем случае это AnimeDTO.
- FlatFileItemReader должен установить ресурс. Он использует метод setResource . Здесь мы устанавливаем ресурс animescsv.csv
- Метод setLineMapper преобразует строки в объекты, представляющие элемент. Наша строка будет аниме-записью, состоящей из идентификатора, заголовка и описания. Эта строка превращается в объект. Обратите внимание, что DefaultLineMapper параметризован с нашей моделью, AnimeDTO.
- Тем не менее, LineMapper получает необработанную строку, что означает, что есть работа, которая должна быть выполнена для правильного отображения полей. Строка должна быть размечена в FieldSet, о котором заботится DelimitedLineTokenizer. DelimitedLineTokenizer возвращает FieldSet.
- Теперь, когда у нас есть FieldSet, нам нужно отобразить его. setFieldSetMapper используется для получения объекта FieldSet и отображения его содержимого в DTO, в нашем случае это AnimeDTO.
4.2 — Процессор
Если мы хотим преобразовать данные перед записью их в базу данных, необходим ItemProcessor. Наш код фактически не применяет какую-либо бизнес-логику для преобразования данных, но мы допускаем такую возможность.
4.2.1 — Процессор в CsvFileToDatabaseConfig.Java
csvAnimeProcessor возвращает новый экземпляр объекта AnimeProcessor, который мы рассмотрим ниже.
|
1
2
3
4
|
@Bean ItemProcessor<AnimeDTO, AnimeDTO> csvAnimeProcessor() { return new AnimeProcessor(); } |
4.2.2 — AnimeProcessor.Java
Если мы хотим применить бизнес-логику перед записью в базу данных, вы можете манипулировать строками перед записью в базу данных. Например, вы можете добавить toUpperCase () после getTitle, чтобы заглавные буквы заголовка перед записью в базу данных. Однако я решил не делать этого и не применять какую-либо другую бизнес-логику для этого примера процессора, поэтому никаких манипуляций не производится. Процессор здесь просто для демонстрации.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
package com.michaelcgood;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.batch.item.ItemProcessor;public class AnimeProcessor implements ItemProcessor<AnimeDTO, AnimeDTO> { private static final Logger log = LoggerFactory.getLogger(AnimeProcessor.class); @Override public AnimeDTO process(final AnimeDTO AnimeDTO) throws Exception { final String id = AnimeDTO.getId(); final String title = AnimeDTO.getTitle(); final String description = AnimeDTO.getDescription(); final AnimeDTO transformedAnimeDTO = new AnimeDTO(id, title, description); log.info("Converting (" + AnimeDTO + ") into (" + transformedAnimeDTO + ")"); return transformedAnimeDTO; }} |
4.3 — Писатель
Метод csvAnimeWriter отвечает за фактическую запись значений в нашу базу данных. Наша база данных является HSQLDB в памяти, однако это приложение позволяет нам легко заменять одну базу данных на другую. Источник данных автоматически подключен.
|
1
2
3
4
5
6
7
8
|
@Bean public JdbcBatchItemWriter<AnimeDTO> csvAnimeWriter() { JdbcBatchItemWriter<AnimeDTO> excelAnimeWriter = new JdbcBatchItemWriter<AnimeDTO>(); excelAnimeWriter.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<AnimeDTO>()); excelAnimeWriter.setSql("INSERT INTO animes (id, title, description) VALUES (:id, :title, :description)"); excelAnimeWriter.setDataSource(dataSource); return excelAnimeWriter; } |
4.4 — Шаг
Шаг — это объект домена, который содержит независимую, последовательную фазу пакетного задания и содержит всю информацию, необходимую для определения и управления фактической пакетной обработкой.
Теперь, когда мы создали ридер и процессор для данных, нам нужно их записать. Для чтения мы использовали чанк-ориентированную обработку, то есть мы считывали данные по одному. Обработка чанков также включает в себя создание «чанков», которые будут записаны в пределах границ транзакции. Для обработки, ориентированной на фрагменты, вы устанавливаете интервал фиксации, и как только число прочитанных элементов становится равным установленному интервалу фиксации, весь фрагмент записывается через ItemWriter, и транзакция фиксируется. Мы устанавливаем размер интервала чанка в 1.
Я предлагаю прочитать документацию Spring Batch о чан-ориентированной обработке .
Затем читатель, процессор и писатель вызывают методы, которые мы написали.
|
1
2
3
4
5
6
7
8
9
|
@Bean public Step csvFileToDatabaseStep() { return stepBuilderFactory.get("csvFileToDatabaseStep") .<AnimeDTO, AnimeDTO>chunk(1) .reader(csvAnimeReader()) .processor(csvAnimeProcessor()) .writer(csvAnimeWriter()) .build(); } |
4.5 — Работа
Работа состоит из шагов. Мы передаем параметр в задание ниже, потому что мы хотим отслеживать завершение задания.
|
1
2
3
4
5
6
7
8
9
|
@Bean Job csvFileToDatabaseJob(JobCompletionNotificationListener listener) { return jobBuilderFactory.get("csvFileToDatabaseJob") .incrementer(new RunIdIncrementer()) .listener(listener) .flow(csvFileToDatabaseStep()) .end() .build(); } |
5 — слушатель уведомления о завершении работы
Класс ниже автоматически связывает JdbcTemplate, потому что мы уже установили источник данных и хотим легко выполнить наш запрос. Результатом нашего запроса является список объектов AnimeDTO. Для каждого возвращенного объекта мы создадим сообщение в нашей консоли, чтобы показать, что элемент был записан в базу данных.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
package com.michaelcgood;import java.sql.ResultSet;import java.sql.SQLException;import java.util.List;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.batch.core.BatchStatus;import org.springframework.batch.core.JobExecution;import org.springframework.batch.core.listener.JobExecutionListenerSupport;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.jdbc.core.JdbcTemplate;import org.springframework.jdbc.core.RowMapper;import org.springframework.stereotype.Component;@Componentpublic class JobCompletionNotificationListener extends JobExecutionListenerSupport { private static final Logger log = LoggerFactory.getLogger(JobCompletionNotificationListener.class); private final JdbcTemplate jdbcTemplate; @Autowired public JobCompletionNotificationListener(JdbcTemplate jdbcTemplate) { this.jdbcTemplate = jdbcTemplate; } @Override public void afterJob(JobExecution jobExecution) { if(jobExecution.getStatus() == BatchStatus.COMPLETED) { log.info("============ JOB FINISHED ============ Verifying the results....\n"); List<AnimeDTO> results = jdbcTemplate.query("SELECT id, title, description FROM animes", new RowMapper<AnimeDTO>() { @Override public AnimeDTO mapRow(ResultSet rs, int row) throws SQLException { return new AnimeDTO(rs.getString(1), rs.getString(2), rs.getString(3)); } }); for (AnimeDTO AnimeDTO : results) { log.info("Discovered <" + AnimeDTO + "> in the database."); } } } } |
6 — SQL
Нам нужно создать схему для нашей базы данных. Как уже упоминалось, мы сделали все поля Strings для простоты использования, поэтому мы сделали их типы данных VARCHAR.
|
1
2
3
4
5
6
|
DROP TABLE animes IF EXISTS;CREATE TABLE animes ( id VARCHAR(10), title VARCHAR(400), description VARCHAR(999)); |
6 — Главный
Это стандартный класс с main (). Как говорится в документации Spring, @SpringBootApplication — это удобная аннотация, включающая @Configuration , @EnableAutoConfiguration , @EnableWebMvc и @ComponentScan .
|
01
02
03
04
05
06
07
08
09
10
11
12
|
package com.michaelcgood;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplicationpublic class SpringBatchCsvApplication { public static void main(String[] args) { SpringApplication.run(SpringBatchCsvApplication.class, args); }} |
7 — Демо
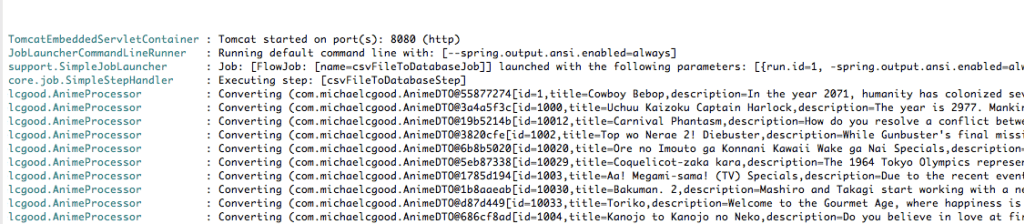
7.1 — Конвертация
FieldSet подается через процессор, и «Converting» выводится на консоль.
7.2 — Обнаружение новых предметов в базе данных
Когда Spring Batch Job завершен, мы выбираем все записи и распечатываем их по отдельности.

7.3 — Пакетный процесс завершен
Когда пакетный процесс завершен, это то, что выводится на консоль.
|
1
2
|
Job: [FlowJob: [name=csvFileToDatabaseJob]] completed with the following parameters: [{run.id=1, -spring.output.ansi.enabled=always}] and the following status: [COMPLETED]Started SpringBatchCsvApplication in 36.0 seconds (JVM running for 46.616) |
8 — Заключение
Spring Batch основывается на подходе разработки на основе POJO и удобстве Spring Framework, что облегчает разработчикам создание пакетной обработки корпоративного уровня.
Исходный код есть на Github
| Опубликовано на Java Code Geeks с разрешения Майкла Гуда, партнера нашей программы JCG . Смотреть оригинальную статью здесь: Spring Batch CSV Processing
Мнения, высказанные участниками Java Code Geeks, являются их собственными. |