1. Обзор
В этом учебном пособии мы будем создавать приложение, которое принимает HTML в качестве входных данных и создает книгу Microsoft Excel с представлением RichText HTML-кода, который был предоставлен. Для создания книги Microsoft Excel мы будем использовать Apache POI . Для анализа HTML мы будем использовать Иерихон.
Полный исходный код этого руководства доступен на Github .
2. Что такое Иерихон?
Jericho — это java-библиотека, которая позволяет анализировать и манипулировать частями HTML-документа, в том числе серверными тегами, дословно воспроизводя любой нераспознанный или недействительный HTML-код. Он также предоставляет высокоуровневые функции для работы с HTML-формами. Это библиотека с открытым исходным кодом, выпущенная под следующими лицензиями: Eclipse Public License (EPL) , GNU Lesser General Public License (LGPL) и Apache License .
Я обнаружил, что Jericho очень прост в использовании для достижения цели преобразования HTML в RichText.
3. pom.xml
Вот необходимые зависимости для приложения, которое мы создаем. Обратите внимание, что для этого приложения мы должны использовать Java 9 . Это из-за метода java.util.regex appendReplacement, который мы используем, который был доступен только с Java 9.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>1.5.9.RELEASE</version> <relativePath /> <!-- lookup parent from repository --></parent><properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <java.version>9</java.version></properties><dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-batch</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-thymeleaf</artifactId> </dependency> <dependency> <groupId>com.h2database</groupId> <artifactId>h2</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-lang3</artifactId> <version>3.7</version> </dependency> <dependency> <groupId>org.springframework.batch</groupId> <artifactId>spring-batch-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi</artifactId> <version>3.15</version> </dependency> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi-ooxml</artifactId> <version>3.15</version> </dependency> <dependency> <groupId>net.htmlparser.jericho</groupId> <artifactId>jericho-html</artifactId> <version>3.4</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-configuration-processor</artifactId> <optional>true</optional> </dependency> <!-- legacy html allow --> <dependency> <groupId>net.sourceforge.nekohtml</groupId> <artifactId>nekohtml</artifactId> </dependency></dependencies> |
4. Веб-страница — тимелист
Мы используем Thymeleaf для создания базовой веб-страницы, которая имеет форму с текстовой областью. Исходный код страницы Thymeleaf доступен здесь, на Github . Эта текстовая область может быть заменена RichText Editor, если мы захотим, например CKEditor. Мы просто должны помнить, что данные AJAX должны быть правильными, используя соответствующий метод setData . В Spring Boot есть предыдущий учебник о CKeditor под названием AJAX с CKEditor .
5. Контроллер
В нашем контроллере мы используем Autowire JobLauncher и Spring Batch job, который мы собираемся создать, с именем GenerateExcel . Автоматическое подключение этих двух классов позволяет нам запускать Spring Batch Job GenerateExcel по требованию, когда запрос POST отправляется в «/ export» .
Следует также отметить, что для обеспечения того, чтобы задание Spring Batch запускалось несколько раз, мы включаем в этот код уникальные параметры: addLong («уникальность», System.nanoTime ()). ToJobParameters () . Ошибка может произойти, если мы не включим уникальные параметры, потому что только уникальные JobInstances могут быть созданы и выполнены, и Spring Batch не может отличить первый и второй JobInstance в противном случае.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
@Controllerpublic class WebController { private String currentContent; @Autowired JobLauncher jobLauncher; @Autowired GenerateExcel exceljob; @GetMapping("/") public ModelAndView getHome() { ModelAndView modelAndView = new ModelAndView("index"); return modelAndView; } @PostMapping("/export") public String postTheFile(@RequestBody String body, RedirectAttributes redirectAttributes, Model model) throws IOException, JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException, JobParametersInvalidException { setCurrentContent(body); Job job = exceljob.ExcelGenerator(); jobLauncher.run(job, new JobParametersBuilder().addLong("uniqueness", System.nanoTime()).toJobParameters() ); return "redirect:/"; } //standard getters and setters} |
6. Пакетная работа
На шаге 1 нашего пакетного задания мы вызываем метод getCurrentContent (), чтобы получить содержимое, переданное в форму Thymeleaf, создаем новую XSSFWorkbook, указываем произвольное имя вкладки Microsoft Excel Sheet, а затем передаем все три переменные в метод createWorksheet. что мы будем делать на следующем шаге нашего урока:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
@Configuration@EnableBatchProcessing@Lazypublic class GenerateExcel { List<String> docIds = new ArrayList<String>(); @Autowired private JobBuilderFactory jobBuilderFactory; @Autowired private StepBuilderFactory stepBuilderFactory; @Autowired WebController webcontroller; @Autowired CreateWorksheet createexcel; @Bean public Step step1() { return stepBuilderFactory.get("step1") .tasklet(new Tasklet() { @Override public RepeatStatus execute(StepContribution stepContribution, ChunkContext chunkContext) throws Exception, JSONException { String content = webcontroller.getCurrentContent(); System.out.println("content is ::" + content); Workbook wb = new XSSFWorkbook(); String tabName = "some"; createexcel.createWorkSheet(wb, content, tabName); return RepeatStatus.FINISHED; } }) .build(); } @Bean public Job ExcelGenerator() { return jobBuilderFactory.get("ExcelGenerator") .start(step1()) .build(); }} |
Мы рассмотрели Spring Batch в других руководствах, таких как Преобразование XML в JSON + Spring Batch и Spring Batch CSV Processing .
7. Служба создания Excel
Мы используем различные классы для создания нашего файла Microsoft Excel. Порядок имеет значение при конвертации HTML в RichText, так что это будет в центре внимания.
7.1 RichTextDetails
Класс с двумя параметрами: строка, которая будет иметь наше содержимое, которое станет RichText, и карта шрифтов.
|
01
02
03
04
05
06
07
08
09
10
|
public class RichTextDetails { private String richText; private Map<Integer, Font> fontMap; //standard getters and setters @Override public int hashCode() { // The goal is to have a more efficient hashcode than standard one. return richText.hashCode(); } |
7.2 RichTextInfo
POJO, который будет отслеживать местоположение RichText, а что нет:
|
1
2
3
4
5
6
|
public class RichTextInfo { private int startIndex; private int endIndex; private STYLES fontStyle; private String fontValue; // standard getters and setters, and the like |
7.3 Стили
Перечисление, содержащее теги HTML, которые мы хотим обработать. Мы можем добавить к этому по мере необходимости:
|
01
02
03
04
05
06
07
08
09
10
11
|
public enum STYLES { BOLD("b"), EM("em"), STRONG("strong"), COLOR("color"), UNDERLINE("u"), SPAN("span"), ITALLICS("i"), UNKNOWN("unknown"), PRE("pre"); // standard getters and setters |
7.4 TagInfo
POJO для отслеживания информации тега:
|
1
2
3
4
5
|
public class TagInfo { private String tagName; private String style; private int tagType; // standard getters and setters |
7.5 HTML в RichText
Это не маленький класс, поэтому давайте разберем его по методам.
По сути, мы окружаем любой произвольный HTML тегом div , поэтому мы знаем, что ищем. Затем мы ищем все элементы в теге div , добавляем каждый в ArrayList из RichTextDetails, а затем передаем весь ArrayList в метод mergeTextDetails. mergeTextDetails возвращает RichtextString, что необходимо для установки значения ячейки:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
public RichTextString fromHtmlToCellValue(String html, Workbook workBook){ Config.IsHTMLEmptyElementTagRecognised = true; Matcher m = HEAVY_REGEX.matcher(html); String replacedhtml = m.replaceAll(""); StringBuilder sb = new StringBuilder(); sb.insert(0, "<div>"); sb.append(replacedhtml); sb.append("</div>"); String newhtml = sb.toString(); Source source = new Source(newhtml); List<RichTextDetails> cellValues = new ArrayList<RichTextDetails>(); for(Element el : source.getAllElements("div")){ cellValues.add(createCellValue(el.toString(), workBook)); } RichTextString cellValue = mergeTextDetails(cellValues); return cellValue; } |
Как мы видели выше, мы передаем ArrayList RichTextDetails в этом методе. Иерихон имеет параметр, который принимает логическое значение для распознавания пустых элементов тега, таких как
: Config.IsHTMLEmptyElementTagRecognised. Это может быть важно при работе с онлайн-редакторами форматированного текста, поэтому мы установили для него значение true. Поскольку нам нужно отслеживать порядок элементов, мы используем LinkedHashMap вместо HashMap.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
private static RichTextString mergeTextDetails(List<RichTextDetails> cellValues) { Config.IsHTMLEmptyElementTagRecognised = true; StringBuilder textBuffer = new StringBuilder(); Map<Integer, Font> mergedMap = new LinkedHashMap<Integer, Font>(550, .95f); int currentIndex = 0; for (RichTextDetails richTextDetail : cellValues) { //textBuffer.append(BULLET_CHARACTER + " "); currentIndex = textBuffer.length(); for (Entry<Integer, Font> entry : richTextDetail.getFontMap() .entrySet()) { mergedMap.put(entry.getKey() + currentIndex, entry.getValue()); } textBuffer.append(richTextDetail.getRichText()) .append(NEW_LINE); } RichTextString richText = new XSSFRichTextString(textBuffer.toString()); for (int i = 0; i < textBuffer.length(); i++) { Font currentFont = mergedMap.get(i); if (currentFont != null) { richText.applyFont(i, i + 1, currentFont); } } return richText; } |
Как упоминалось выше, мы используем Java 9 для использования StringBuilder с java.util.regex.Matcher.appendReplacement . Почему? Ну, это потому, что StringBuffer медленнее, чем StringBuilder для операций. Функции StringBuffer синхронизируются для безопасности потока и, следовательно, медленнее.
Мы используем Deque вместо Stack, потому что интерфейс Deque обеспечивает более полный и согласованный набор операций стека LIFO:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
static RichTextDetails createCellValue(String html, Workbook workBook) { Config.IsHTMLEmptyElementTagRecognised = true; Source source = new Source(html); Map<String, TagInfo> tagMap = new LinkedHashMap<String, TagInfo>(550, .95f); for (Element e : source.getChildElements()) { getInfo(e, tagMap); } StringBuilder sbPatt = new StringBuilder(); sbPatt.append("(").append(StringUtils.join(tagMap.keySet(), "|")).append(")"); String patternString = sbPatt.toString(); Pattern pattern = Pattern.compile(patternString); Matcher matcher = pattern.matcher(html); StringBuilder textBuffer = new StringBuilder(); List<RichTextInfo> textInfos = new ArrayList<RichTextInfo>(); ArrayDeque<RichTextInfo> richTextBuffer = new ArrayDeque<RichTextInfo>(); while (matcher.find()) { matcher.appendReplacement(textBuffer, ""); TagInfo currentTag = tagMap.get(matcher.group(1)); if (START_TAG == currentTag.getTagType()) { richTextBuffer.push(getRichTextInfo(currentTag, textBuffer.length(), workBook)); } else { if (!richTextBuffer.isEmpty()) { RichTextInfo info = richTextBuffer.pop(); if (info != null) { info.setEndIndex(textBuffer.length()); textInfos.add(info); } } } } matcher.appendTail(textBuffer); Map<Integer, Font> fontMap = buildFontMap(textInfos, workBook); return new RichTextDetails(textBuffer.toString(), fontMap); } |
Мы можем видеть, где RichTextInfo приходит использовать здесь:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
private static Map<Integer, Font> buildFontMap(List<RichTextInfo> textInfos, Workbook workBook) { Map<Integer, Font> fontMap = new LinkedHashMap<Integer, Font>(550, .95f); for (RichTextInfo richTextInfo : textInfos) { if (richTextInfo.isValid()) { for (int i = richTextInfo.getStartIndex(); i < richTextInfo.getEndIndex(); i++) { fontMap.put(i, mergeFont(fontMap.get(i), richTextInfo.getFontStyle(), richTextInfo.getFontValue(), workBook)); } } } return fontMap; } |
Где мы используем перечисление STYLES:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
private static Font mergeFont(Font font, STYLES fontStyle, String fontValue, Workbook workBook) { if (font == null) { font = workBook.createFont(); } switch (fontStyle) { case BOLD: case EM: case STRONG: font.setBoldweight(Font.BOLDWEIGHT_BOLD); break; case UNDERLINE: font.setUnderline(Font.U_SINGLE); break; case ITALLICS: font.setItalic(true); break; case PRE: font.setFontName("Courier New"); case COLOR: if (!isEmpty(fontValue)) { font.setColor(IndexedColors.BLACK.getIndex()); } break; default: break; } return font; } |
Мы используем класс TagInfo для отслеживания текущего тега:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
|
private static RichTextInfo getRichTextInfo(TagInfo currentTag, int startIndex, Workbook workBook) { RichTextInfo info = null; switch (STYLES.fromValue(currentTag.getTagName())) { case SPAN: if (!isEmpty(currentTag.getStyle())) { for (String style : currentTag.getStyle() .split(";")) { String[] styleDetails = style.split(":"); if (styleDetails != null && styleDetails.length > 1) { if ("COLOR".equalsIgnoreCase(styleDetails[0].trim())) { info = new RichTextInfo(startIndex, -1, STYLES.COLOR, styleDetails[1]); } } } } break; default: info = new RichTextInfo(startIndex, -1, STYLES.fromValue(currentTag.getTagName())); break; } return info; } |
Мы обрабатываем теги HTML:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
private static void getInfo(Element e, Map<String, TagInfo> tagMap) { tagMap.put(e.getStartTag() .toString(), new TagInfo(e.getStartTag() .getName(), e.getAttributeValue("style"), START_TAG)); if (e.getChildElements() .size() > 0) { List<Element> children = e.getChildElements(); for (Element child : children) { getInfo(child, tagMap); } } if (e.getEndTag() != null) { tagMap.put(e.getEndTag() .toString(), new TagInfo(e.getEndTag() .getName(), END_TAG)); } else { // Handling self closing tags tagMap.put(e.getStartTag() .toString(), new TagInfo(e.getStartTag() .getName(), END_TAG)); } } |
7.6 Создать рабочий лист
Используя StringBuilder, я создаю строку, которая будет записана в FileOutPutStream. В реальном приложении это должно быть определено пользователем. Я добавил путь к папке и имя файла в двух разных строках. Пожалуйста, измените путь к файлу на свой.
sheet.createRow (0) создает строку в самой первой строке, а dataRow.createCell (0) создает ячейку в столбце A строки.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
public void createWorkSheet(Workbook wb, String content, String tabName) { StringBuilder sbFileName = new StringBuilder(); sbFileName.append("/Users/mike/javaSTS/michaelcgood-apache-poi-richtext/"); sbFileName.append("myfile.xlsx"); String fileMacTest = sbFileName.toString(); try { this.fileOut = new FileOutputStream(fileMacTest); } catch (FileNotFoundException ex) { Logger.getLogger(CreateWorksheet.class.getName()) .log(Level.SEVERE, null, ex); } Sheet sheet = wb.createSheet(tabName); // Create new sheet w/ Tab name sheet.setZoom(85); // Set sheet zoom: 85% // content rich text RichTextString contentRich = null; if (content != null) { contentRich = htmlToExcel.fromHtmlToCellValue(content, wb); } // begin insertion of values into cells Row dataRow = sheet.createRow(0); Cell A = dataRow.createCell(0); // Row Number A.setCellValue(contentRich); sheet.autoSizeColumn(0); try { ///////////////////////////////// // Write the output to a file wb.write(fileOut); fileOut.close(); } catch (IOException ex) { Logger.getLogger(CreateWorksheet.class.getName()) .log(Level.SEVERE, null, ex); } } |
8. Демо
Мы посещаем localhost: 8080 .
Мы вводим некоторый текст с некоторым HTML:
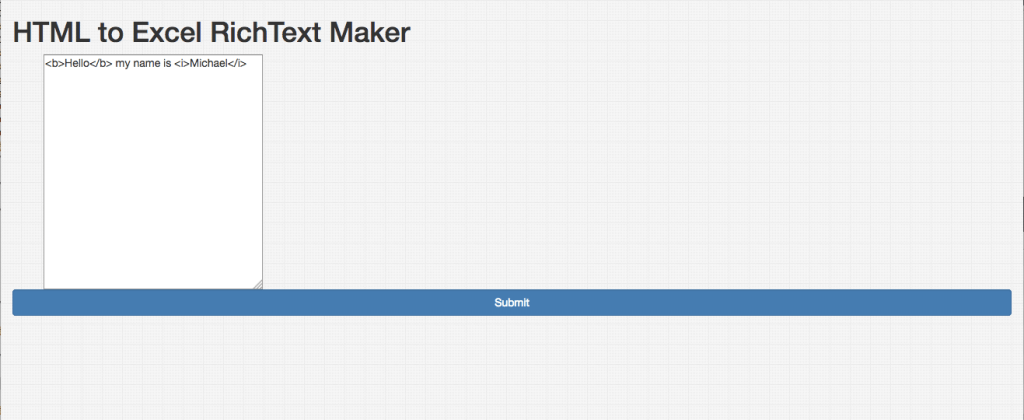
Мы открываем наш файл Excel и видим созданный нами RichText:

9. Вывод
Мы видим, что преобразование HTML в класс RichTextString Apache POI не является тривиальным; однако для бизнес-приложений преобразование HTML в RichTextString может быть важным, поскольку в файлах Microsoft Excel важна читабельность. Вероятно, есть место для улучшения производительности приложения, которое мы создаем, но мы рассмотрели основы создания такого приложения.
Полный исходный код доступен на Github.
| Опубликовано на Java Code Geeks с разрешения Майкла Гуда, партнера нашей программы JCG . Смотрите оригинальную статью здесь: Преобразование HTML в RichTextString для Apache POI
Мнения, высказанные участниками Java Code Geeks, являются их собственными. |