В моем предыдущем посте я показал, как настроить полный проект на основе Maven для создания задания Hadoop в Java. Конечно, это не было завершено, потому что в нем отсутствует часть модульного тестирования. В этом посте я покажу, как добавить модульные тесты MapReduce в проект, который я начал ранее. Для модульного теста я использую фреймворк MRUnit .
- Добавьте необходимую зависимость в пом
Добавьте следующую зависимость в pom:
|
1
2
3
4
5
6
7
|
<dependency> <groupId>org.apache.mrunit</groupId> <artifactId>mrunit</artifactId> <version>1.0.0</version> <classifier>hadoop1</classifier> <scope>test</scope></dependency> |
Это сделало структуру MRunit доступной для проекта.
- Добавьте модульные тесты для тестирования логики Map Reduce
Использование этой структуры довольно просто, особенно в нашем случае. Поэтому я просто покажу код модульного теста и несколько комментариев, если это необходимо, но я думаю, что совершенно очевидно, как его использовать. Модульный тест для Mapper ‘MapperTest’:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
package net.pascalalma.hadoop;import org.apache.hadoop.io.Text;import org.apache.hadoop.mrunit.mapreduce.MapDriver;import org.junit.Before;import org.junit.Test;import java.io.IOException;/** * Created with IntelliJ IDEA. * User: pascal */public class MapperTest { MapDriver<Text, Text, Text, Text> mapDriver; @Before public void setUp() { WordMapper mapper = new WordMapper(); mapDriver = MapDriver.newMapDriver(mapper); } @Test public void testMapper() throws IOException { mapDriver.withInput(new Text("a"), new Text("ein")); mapDriver.withInput(new Text("a"), new Text("zwei")); mapDriver.withInput(new Text("c"), new Text("drei")); mapDriver.withOutput(new Text("a"), new Text("ein")); mapDriver.withOutput(new Text("a"), new Text("zwei")); mapDriver.withOutput(new Text("c"), new Text("drei")); mapDriver.runTest(); }} |
Этот тестовый класс на самом деле даже проще, чем сама реализация Mapper. Вы просто определяете входные данные маппера и ожидаемый выходной сигнал, а затем позволяете настроенному MapDriver запустить тест. В нашем случае Mapper не делает ничего конкретного, но вы видите, как легко настроить тестовый сценарий. Для полноты вот тестовый класс Редуктора:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
package net.pascalalma.hadoop;import org.apache.hadoop.io.Text;import org.apache.hadoop.mrunit.mapreduce.ReduceDriver;import org.junit.Before;import org.junit.Test;import java.io.IOException;import java.util.ArrayList;import java.util.List;/** * Created with IntelliJ IDEA. * User: pascal */public class ReducerTest { ReduceDriver<Text, Text, Text, Text> reduceDriver; @Before public void setUp() { AllTranslationsReducer reducer = new AllTranslationsReducer(); reduceDriver = ReduceDriver.newReduceDriver(reducer); } @Test public void testReducer() throws IOException { List<Text> values = new ArrayList<Text>(); values.add(new Text("ein")); values.add(new Text("zwei")); reduceDriver.withInput(new Text("a"), values); reduceDriver.withOutput(new Text("a"), new Text("|ein|zwei")); reduceDriver.runTest(); }} |
- Запустите юнит-тесты
С помощью команды Maven «mvn clean test» мы можем запустить тесты:
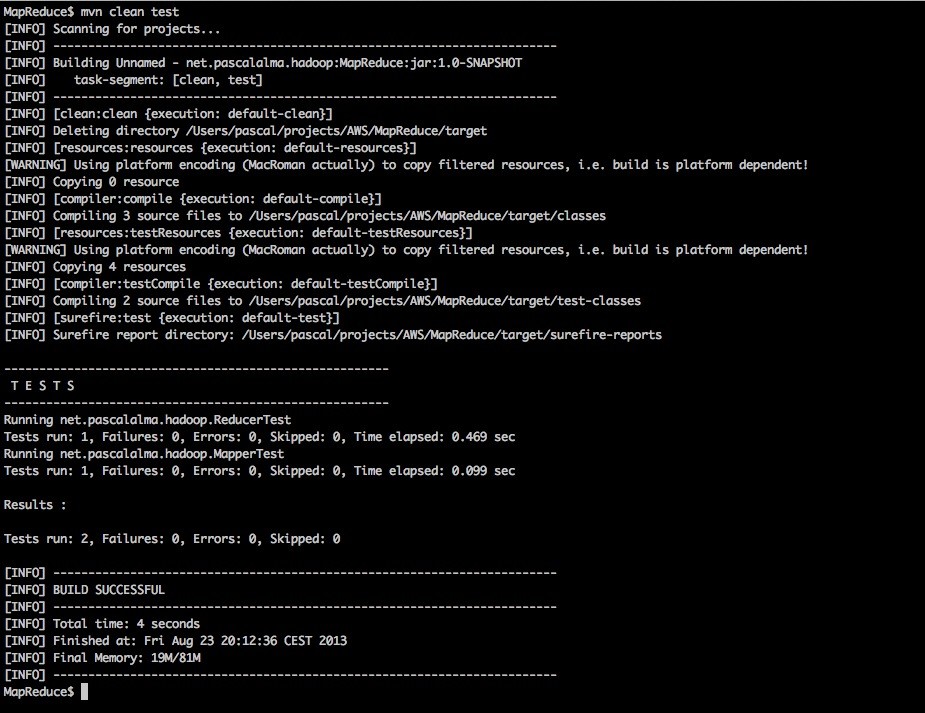
С проведением модульных тестов я бы сказал, что мы готовы построить проект и развернуть его в кластере Hadoop, который я опишу в следующем посте.