Хотя сама Hadoop Framework создается с использованием Java, задания MapReduce могут быть написаны на разных языках. В этой статье я покажу, как создать задание MapReduce в Java на основе проекта Maven, как и любой другой проект Java.
- Подготовьте пример ввода
Давайте начнем с вымышленного бизнес-кейса. В этом случае нам нужен CSV-файл с английскими словами из словаря и всеми переводами на других языках, которые разделены символом «|». условное обозначение. Я основал этот пример на этом посте . Таким образом, задание будет читать словари разных языков и сопоставлять каждое английское слово с переводом на другой язык. Входные словари для работы взяты отсюда . Я скачал несколько файлов на разных языках и соединил их в один файл (Hadoop лучше обрабатывать один большой файл, чем несколько маленьких). Мой пример файла можно найти здесь .
- Создайте проект Java MapReduce
Следующим шагом является создание кода Java для задания MapReduce. Как я уже говорил, прежде чем использовать для этого проект Maven, я создал новый пустой проект Maven в своей среде IDE, IntelliJ. Я изменил pom по умолчанию, чтобы добавить необходимые плагины и зависимости:
Зависимость, которую я добавил:
|
1
2
3
4
5
6
|
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-core</artifactId> <version>1.2.0</version> <scope>provided</scope></dependency> |
Зависимость Hadoop необходима для использования классов Hadoop в моей работе MapReduce. Поскольку я хочу выполнить задание в AWS EMR, я должен убедиться, что у меня есть соответствующая версия Hadoop. Кроме того, область действия может быть установлена как «предоставленная», поскольку среда Hadoop будет доступна в кластере Hadoop.
Помимо зависимости я добавил следующие два плагина в pom.xml:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
|
<plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-jar-plugin</artifactId> <configuration> <archive> <manifest> <addClasspath>true</addClasspath> <mainClass>net.pascalalma.hadoop.Dictionary</mainClass> </manifest> </archive> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>1.6</source> <target>1.6</target> </configuration> </plugin></plugins> |
Первый плагин используется для создания исполняемого фляги нашего проекта. Это облегчает работу JAR в кластере Hadoop, поскольку нам не нужно указывать основной класс.
Второй плагин необходим для обеспечения совместимости созданного JAR с экземплярами кластера EMS AWS . Этот кластер AWS поставляется с JDK 1.6. Если вы пропустите это, кластер потерпит неудачу (я получил сообщение «Unsupported major.minor version 51.0»). Позже я покажу в другом посте, как настроить этот кластер AWS EMR.
Это основной проект, как обычный проект Java. Давайте реализуем задания MapReduce дальше.
- Реализуйте классы MapReduce
Я описал функциональность, которую мы хотим выполнить на первом этапе. Для этого я создал три Java-класса в своем проекте Hadoop. Первый класс — Mapper :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
package net.pascalalma.hadoop;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;import java.util.StringTokenizer;/** * Created with IntelliJ IDEA. * User: pascal * Date: 16-07-13 * Time: 12:07 */public class WordMapper extends Mapper<Text,Text,Text,Text> { private Text word = new Text(); public void map(Text key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString(),","); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(key, word); } }} |
Этот класс не очень сложен. Он просто получает строку из входного файла и создает ее карту, в которой каждый ключ будет иметь одно значение (и на этом этапе допускается несколько ключей).
Следующим классом является ‘ Reducer ‘, который сводит карту к требуемому результату:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
package net.pascalalma.hadoop;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/** * Created with IntelliJ IDEA. * User: pascal * Date: 17-07-13 * Time: 19:50 */public class AllTranslationsReducer extends Reducer<Text, Text, Text, Text> { private Text result = new Text(); @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { String translations = ""; for (Text val : values) { translations += "|" + val.toString(); } result.set(translations); context.write(key, result); }} |
Эта команда Reduce собирает все значения для данного ключа и помещает их после друг друга, разделяя их знаком «|». условное обозначение.
Последний оставшийся класс — это тот, который собирает все вместе, чтобы сделать его работоспособным:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
package net.pascalalma.hadoop;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;/** * Created with IntelliJ IDEA. * User: pascal * Date: 16-07-13 * Time: 12:07 */public class Dictionary { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = new Job(conf, "dictionary"); job.setJarByClass(Dictionary.class); job.setMapperClass(WordMapper.class); job.setReducerClass(AllTranslationsReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setInputFormatClass(KeyValueTextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); }} |
В этом основном методе мы собираем задание и запускаем его. Обратите внимание, что я просто ожидаю, что args [0] и args [1] будут именем входного файла и выходного каталога (не существует). Я не добавил никакой проверки для этого. Вот моя «Run Configuration» в IntelliJ:
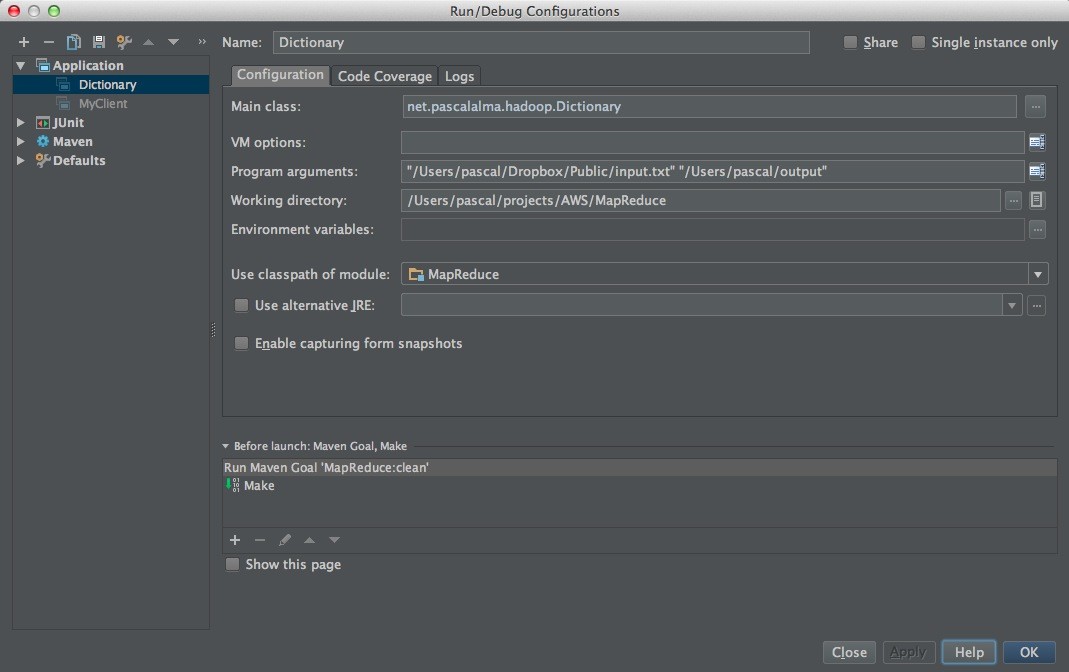
Просто убедитесь, что выходной каталог не существует во время запуска класса. Вывод журнала, созданный заданием, выглядит следующим образом:
|
001
002
003
004
005
006
007
008
009
010
011
012
013
014
015
016
017
018
019
020
021
022
023
024
025
026
027
028
029
030
031
032
033
034
035
036
037
038
039
040
041
042
043
044
045
046
047
048
049
050
051
052
053
054
055
056
057
058
059
060
061
062
063
064
065
066
067
068
069
070
071
072
073
074
075
076
077
078
079
080
081
082
083
084
085
086
087
088
089
090
091
092
093
094
095
096
097
098
099
100
101
102
103
104
105
106
107
|
2013-08-15 21:37:00.595 java[73982:1c03] Unable to load realm info from SCDynamicStoreaug 15, 2013 9:37:01 PM org.apache.hadoop.util.NativeCodeLoader <clinit>WARNING: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableaug 15, 2013 9:37:01 PM org.apache.hadoop.mapred.JobClient copyAndConfigureFilesWARNING: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.aug 15, 2013 9:37:01 PM org.apache.hadoop.mapred.JobClient copyAndConfigureFilesWARNING: No job jar file set. User classes may not be found. See JobConf(Class) or JobConf#setJar(String).aug 15, 2013 9:37:01 PM org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatusINFO: Total input paths to process : 1aug 15, 2013 9:37:01 PM org.apache.hadoop.io.compress.snappy.LoadSnappy <clinit>WARNING: Snappy native library not loadedaug 15, 2013 9:37:01 PM org.apache.hadoop.mapred.JobClient monitorAndPrintJobINFO: Running job: job_local_0001aug 15, 2013 9:37:01 PM org.apache.hadoop.mapred.Task initializeINFO: Using ResourceCalculatorPlugin : nullaug 15, 2013 9:37:01 PM org.apache.hadoop.mapred.MapTask$MapOutputBuffer <init>INFO: io.sort.mb = 100aug 15, 2013 9:37:01 PM org.apache.hadoop.mapred.MapTask$MapOutputBuffer <init>INFO: data buffer = 79691776/99614720aug 15, 2013 9:37:01 PM org.apache.hadoop.mapred.MapTask$MapOutputBuffer <init>INFO: record buffer = 262144/327680aug 15, 2013 9:37:02 PM org.apache.hadoop.mapred.MapTask$MapOutputBuffer flushINFO: Starting flush of map outputaug 15, 2013 9:37:02 PM org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpillINFO: Finished spill 0aug 15, 2013 9:37:02 PM org.apache.hadoop.mapred.Task doneINFO: Task:attempt_local_0001_m_000000_0 is done. And is in the process of commitingaug 15, 2013 9:37:02 PM org.apache.hadoop.mapred.JobClient monitorAndPrintJobINFO: map 0% reduce 0%aug 15, 2013 9:37:04 PM org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdateINFO: aug 15, 2013 9:37:04 PM org.apache.hadoop.mapred.Task sendDoneINFO: Task 'attempt_local_0001_m_000000_0' done.aug 15, 2013 9:37:04 PM org.apache.hadoop.mapred.Task initializeINFO: Using ResourceCalculatorPlugin : nullaug 15, 2013 9:37:04 PM org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdateINFO: aug 15, 2013 9:37:04 PM org.apache.hadoop.mapred.Merger$MergeQueue mergeINFO: Merging 1 sorted segmentsaug 15, 2013 9:37:04 PM org.apache.hadoop.mapred.Merger$MergeQueue mergeINFO: Down to the last merge-pass, with 1 segments left of total size: 524410 bytesaug 15, 2013 9:37:04 PM org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdateINFO: aug 15, 2013 9:37:05 PM org.apache.hadoop.mapred.Task doneINFO: Task:attempt_local_0001_r_000000_0 is done. And is in the process of commitingaug 15, 2013 9:37:05 PM org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdateINFO: aug 15, 2013 9:37:05 PM org.apache.hadoop.mapred.Task commitINFO: Task attempt_local_0001_r_000000_0 is allowed to commit nowaug 15, 2013 9:37:05 PM org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTaskINFO: Saved output of task 'attempt_local_0001_r_000000_0' to /Users/pascal/outputaug 15, 2013 9:37:05 PM org.apache.hadoop.mapred.JobClient monitorAndPrintJobINFO: map 100% reduce 0%aug 15, 2013 9:37:07 PM org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdateINFO: reduce > reduceaug 15, 2013 9:37:07 PM org.apache.hadoop.mapred.Task sendDoneINFO: Task 'attempt_local_0001_r_000000_0' done.aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.JobClient monitorAndPrintJobINFO: map 100% reduce 100%aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.JobClient monitorAndPrintJobINFO: Job complete: job_local_0001aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Counters: 17aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: File Output Format Counters aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Bytes Written=423039aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: FileSystemCountersaug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: FILE_BYTES_READ=1464626aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: FILE_BYTES_WRITTEN=1537251aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: File Input Format Counters aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Bytes Read=469941aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Map-Reduce Frameworkaug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Reduce input groups=11820aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Map output materialized bytes=524414aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Combine output records=0aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Map input records=20487aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Reduce shuffle bytes=0aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Reduce output records=11820aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Spilled Records=43234aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Map output bytes=481174aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Total committed heap usage (bytes)=362676224aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Combine input records=0aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Map output records=21617aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: SPLIT_RAW_BYTES=108aug 15, 2013 9:37:08 PM org.apache.hadoop.mapred.Counters logINFO: Reduce input records=21617Process finished with exit code 0 |
Выходной файл, созданный этим заданием, можно найти в прилагаемом выходном каталоге, как показано на следующем снимке экрана:
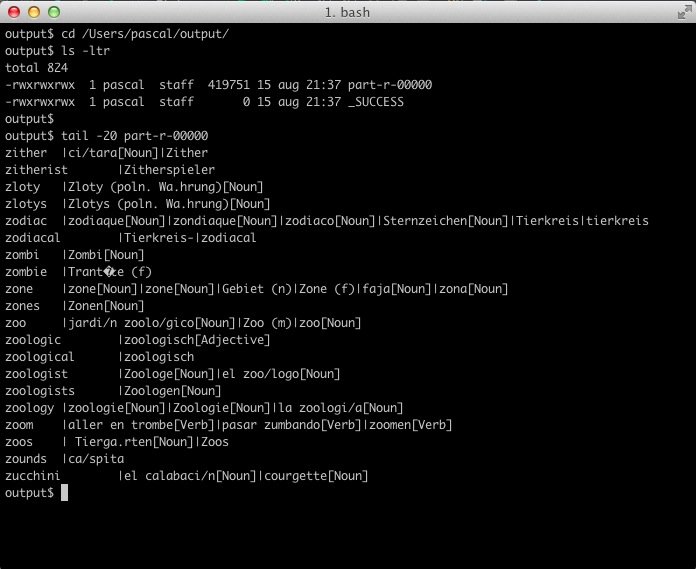
Как вы уже видели, мы можем запустить этот основной метод в IDE (или из командной строки), но я хотел бы увидеть некоторые модульные тесты, выполненные на Mapper и Reducer, прежде чем мы перейдем туда. Я покажу это в другом посте, как это сделать.