Продолжая серию статей о предлагаемых практиках при работе с языком программирования Java, мы собираемся выполнить сравнение производительности между тремя, вероятно, наиболее используемыми классами реализации Collection . Чтобы сделать вещи более реалистичными, мы собираемся протестировать многопоточную среду, чтобы обсудить и продемонстрировать, как использовать Vector , ArrayList и / или HashSet для высокопроизводительных приложений.
Все обсуждаемые темы основаны на сценариях использования, полученных в результате разработки критически важных, высокопроизводительных производственных систем для телекоммуникационной отрасли.
Перед прочтением каждого раздела этой статьи настоятельно рекомендуется ознакомиться с соответствующей документацией по Java API для получения подробной информации и примеров кода.
Все тесты выполняются на Sony Vaio со следующими характеристиками:
- Система: openSUSE 11.1 (x86_64)
- Процессор (ЦП): Процессор Intel® Core ™ 2 Duo T6670 с частотой 2,20 ГГц
- Скорость процессора: 1200,00 МГц
- Общий объем памяти (ОЗУ): 2,8 ГБ
- Java: OpenJDK 1.6.0_0 64-битная
Применяется следующая тестовая конфигурация:
- Одновременный рабочий поток: 50
- Тест повторений на одного работника Тема: 100
- Всего тестовых прогонов: 100
Вектор против ArrayList против HashSet
Одна из наиболее распространенных задач, которую должен реализовать разработчик Java, — хранение и извлечение объектов из коллекций . Язык программирования Java предоставляет несколько классов реализации Collection с перекрывающимися и уникальными характеристиками. Vector , ArrayList и HashSet , вероятно, наиболее часто используемые.
Тем не менее, работа с классами реализации Collection , особенно в многопоточной среде, может быть сложной. Большинство из них не обеспечивает синхронизированный доступ по умолчанию. Как следствие, одновременное изменение внутренней структуры Коллекции (вставка или удаление элементов) может привести к ошибкам.
Сценарий случая, который будет обсуждаться здесь, имеет несколько потоков, вставляющих, убирающих и повторяющих элементы каждого класса реализации Collection, упомянутого выше. Мы собираемся продемонстрировать, как правильно использовать вышеупомянутые классы реализации коллекций в многопоточной среде и предоставить соответствующие диаграммы сравнения производительности, чтобы показать, какой из них работает лучше в каждом тестовом примере.
Для сравнения тарифов мы будем предполагать, что элементы NULL не допускаются и что мы не обращаем внимания на порядок элементов в коллекциях . Кроме того, поскольку Vector является единственным классом реализации Collection в нашей тестовой группе, который обеспечивает синхронизированный доступ по умолчанию, синхронизация для классов реализации ArrayList и HashSet Collection будет осуществляться с использованием статических методов Collections.synchronizedList и Collections.synchronizedSet . Эти методы предоставляют «обернутый» синхронизированный экземпляр назначенного класса реализации Collection, как показано ниже:
- List syncList = Collections.synchronizedList (new ArrayList ());
- Установите syncSet = Collections.synchronizedSet (new HashSet ());
Контрольный пример № 1 — Добавление элементов в коллекцию
Для первого теста мы будем иметь несколько потоков, добавляющих элементы String в каждый класс реализации Collection . Чтобы сохранить уникальность среди элементов String, мы построим их, как показано ниже:
- Статическая первая часть, например, «helloWorld»
- Идентификатор рабочего потока, помните, что у нас одновременно работает 50 рабочих потоков
- Номер повторения теста рабочего потока, помните, что каждый рабочий поток выполняет 100 повторений теста для каждого запуска теста
Для каждого запуска теста каждый рабочий поток будет вставлять 100 элементов String, как показано ниже:
- Для первого теста повторите
- Рабочий поток № 1 вставит элемент String: «helloWorld-1-1»
- Рабочий поток № 2 вставит элемент String: «helloWorld-2-1»
- Рабочий поток № 3 вставит элемент String: «helloWorld-3-1» и т. Д.
- Для второго теста повторите
- Рабочий поток № 1 вставит элемент String: «helloWorld-1-2»
- Рабочий поток № 2 вставит элемент String: «helloWorld-2-2»
- Рабочий поток № 3 вставит элемент String: «helloWorld-3-2» и т. Д.
- и т.д …
В конце каждого запуска теста каждый класс реализации Collection будет заполнен 5000 различными элементами String.
Ниже мы представляем диаграмму сравнения производительности между тремя вышеупомянутыми классами реализации Collection.

Горизонтальная ось представляет количество тестовых прогонов, а вертикальная ось — среднее количество транзакций в секунду (TPS) для каждого тестового прогона. Таким образом, чем выше значения, тем лучше. Как видите, классы реализации Vector и ArrayList Collection при добавлении к ним элементов выполняются практически одинаково. С другой стороны, класс реализации HashSet Collection продемонстрировал немного худшую производительность, в основном из-за более сложной внутренней структуры и механизма генерации хеша.
Контрольный пример № 2 — удаление элементов из коллекции
Во втором тестовом примере мы будем иметь несколько потоков, удаляющих элементы String из каждого класса реализации Collection . Все классы реализации коллекции будут предварительно заполнены элементами String из предыдущего контрольного примера. Для удаления элементов мы будем использовать общий экземпляр Iterator среди всех рабочих потоков для каждого класса реализации Collection . Синхронизированный доступ к экземпляру Iterator также будет реализован. Каждый рабочий поток будет удалять следующий доступный элемент класса реализации Collection , выполняя операции итератора «next ()» и «remove ()» (чтобы избежать исключения ConcurrentModificationException ). Ниже приведена таблица сравнения производительности для вышеупомянутого теста.

Горизонтальная ось представляет количество тестовых прогонов, а вертикальная ось — среднее количество транзакций в секунду (TPS) для каждого тестового прогона. Таким образом, чем выше значения, тем лучше. И снова классы реализации Vector и ArrayList Collection при удалении из них элементов String выполнялись практически одинаково. С другой стороны, класс реализации HashSet Collection значительно превзошел Vector и ArrayList , что в среднем составило 678000 TPS.
На данный момент мы должны точно определить, что с помощью метода «remove (0)» классов реализации Vector и ArrayList Collection для удаления элементов String мы достигли несколько лучших результатов в производительности по сравнению с использованием синхронизированного общего экземпляра Iterator . Причина, по которой мы продемонстрировали подход к операциям синхронизированного общего экземпляра Iterator «next ()» и «remove ()», заключается в том, чтобы поддерживать сравнение тарифов между тремя классами реализации Collection .
ВАЖНОЕ ЗАМЕЧАНИЕ
Наш тестовый сценарий требует, чтобы мы удаляли первый элемент из каждого класса реализации Collection . Тем не менее, мы должны точно указать, что это применимо как наихудший сценарий для классов реализации Vector и ArrayList Collection . Как один из наших читателей, Джеймс Уотсон, успешно прокомментировал соответствующий пост от TheServerSide
« Причина в том, что в ArrayList и Vecrtor метод remove () приведет к вызову System.arraycopy (), если какой-либо элемент, кроме последнего, будет удален (последний элемент является элементом с index: size — 1). Удаление первого элемента означает, что копируется весь остаток массива, что является операцией O (n). Поскольку тест удаляет все элементы в списке, полный тест становится O (n ^ 2) (медленно.)
Удаление HashSet не делает никаких таких копий массива, поэтому его удаление равно O (1) или постоянному времени. Для полного теста это тогда O (n) (быстро.). Если бы тесты были переписаны для удаления последнего элемента из ArrayList и Vector, вы, скорее всего, сравняли бы производительность с HashSet. »
По этой причине мы проведем этот тест снова, удалив последний элемент из классов реализации Коллекции Vector и ArrayList, поскольку предполагаем, что порядок элементов в Коллекциях не имеет значения. Результаты производительности показаны ниже.

Горизонтальная ось представляет количество тестовых прогонов, а вертикальная ось — среднее количество транзакций в секунду (TPS) для каждого тестового прогона. Таким образом, чем выше значения, тем лучше. Как и ожидалось, все классы реализации Collection выполнялись почти одинаково при удалении из них элементов String.
Тест № 3 — Итераторы
В третьем тестовом примере мы будем иметь несколько рабочих потоков, перебирающих элементы каждого класса реализации Collection . Каждый рабочий поток будет использовать операцию Collection «iterator ()», чтобы извлечь ссылку на экземпляр Iterator и выполнить итерацию по всем доступным элементам Collection с помощью операции Iterator «next ()». Все классы реализации Collection будут предварительно заполнены значениями String из первого контрольного примера. Ниже приведена таблица сравнения производительности для вышеупомянутого теста.

Горизонтальная ось представляет количество тестовых прогонов, а вертикальная ось — среднее количество транзакций в секунду (TPS) для каждого тестового прогона. Таким образом, чем выше значения, тем лучше. Классы реализации и Vector, и HashSet Collection работают плохо по сравнению с классом реализации ArrayList Collection . Вектор набрал в среднем 68 TPS, в то время как HashSet набрал в среднем 9200 TPS. С другой стороны, ArrayList значительно превзошел Vector и HashSet , что в среднем составило 421000 TPS.
Контрольный пример № 4 — Добавление и удаление элементов
В нашем последнем тестовом примере мы собираемся реализовать комбинацию сценариев тестового примера 1 и 2. Одна группа рабочих потоков собирается вставить элементы String в каждый класс реализации Collection , тогда как другая группа рабочих потоков собирается извлечь из них элементы String.
В комбинированной операции (добавление и удаление элементов) нельзя использовать подход синхронизированного общего экземпляра Iterator для удаления элементов. Одновременное добавление и удаление элементов из одной коллекции исключает использование общего экземпляра итератора из-за того, что внутренняя структура коллекции постоянно меняется. Для классов реализации Vector и ArrayList Collection вышеупомянутое ограничение можно обойти, используя операцию «remove (0)», которая возвращает первый элемент из внутреннего хранилища Collection . К сожалению, класс реализации HashSet Collection не предоставляет такой функциональности. Предлагаемый нами способ достижения максимальных результатов производительности для комбинированной операции с использованием класса реализации HashSet Collection заключается в следующем:
- Используйте два разных HashSets, один для добавления элементов, а другой для отвода
- Реализуйте поток «контроллера», который будет менять содержимое вышеупомянутых классов HashSet, когда «убирающийся» HashSet пуст. Поток «контроллера» может быть реализован как обычный TimerTask, который может проверять содержимое «втягивающегося» HashSet через регулярные промежутки времени и выполнять своп при необходимости
- Общий экземпляр Iterator для «втягивающегося» HashSet должен быть создан после замены двух HashSet.
- Все рабочие потоки, которые убирают элементы, должны ждать, пока «убирающийся» HashSet будет заполнен элементами, и будут уведомлены после замены
Далее следует фрагмент кода, отображающий предлагаемую реализацию:
Глобальные декларации:
|
1
2
3
4
5
|
Set<string> s = new HashSet<string>(); // The HashSet for retracting elementsIterator<string> sIt = s.iterator(); // The shared Iterator for retracting elementsSet<string> sAdd = new HashSet<string>(); // The HashSet for adding new elementsBoolean read = Boolean.FALSE; // Helper Object for external synchronization and wait – notify functionality when retracting elements from the “s” HashSetBoolean write = Boolean.FALSE; // Helper Object for external synchronization when writing elements to the “sAdd” HashSet |
Код для добавления элементов в «sAdd» HashSet :
|
1
2
3
|
synchronized(write) { sAdd.add(“helloWorld” + "-" + threadId + "-" + count);} |
Код для отвода элементов из «S» HashSet :
|
01
02
03
04
05
06
07
08
09
10
11
|
while (true) { synchronized (read) { try { sIt.next(); sIt.remove(); break; } catch (NoSuchElementException e) { read.wait(); } }} |
Код класса «контроллер»:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
public class Controller extends TimerTask { public void run() { try { performSwap(); } catch (Exception ex) { ex.printStackTrace(); } } private void performSwap() throws Exception { synchronized(read) { if(s.isEmpty()) { synchronized(write) { if(!sAdd.isEmpty()) { Set<string> tmpSet; tmpSet = s; s = sAdd; sAdd = tmpSet; sIt = s.iterator(); read.notifyAll(); } } } } }} |
Наконец, код для планирования «контроллера» TimerTask
|
1
2
|
Timer timer = new Timer();timer.scheduleAtFixedRate(new Controller(), 0, 1); |
Мы должны запустить задачу «контроллер» перед запуском рабочих потоков, которые записывают и читают из соответствующих HashSets.
Помните, что для классов реализации Vector и ArrayList Collection мы использовали операцию «remove (0)», чтобы убирать элементы. Ниже приведены фрагменты кода для вышеупомянутых классов реализации Collection :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
while (true) { try { vector.remove(0); break; } catch (ArrayIndexOutOfBoundsException e) { }}while (true) { try { syncList.remove(0); break; } catch (IndexOutOfBoundsException e) { }} |
Ниже приведена таблица сравнения производительности для дополнительной части вышеупомянутого контрольного примера.

Ниже приведена таблица сравнения производительности для части отвода вышеупомянутого контрольного примера.
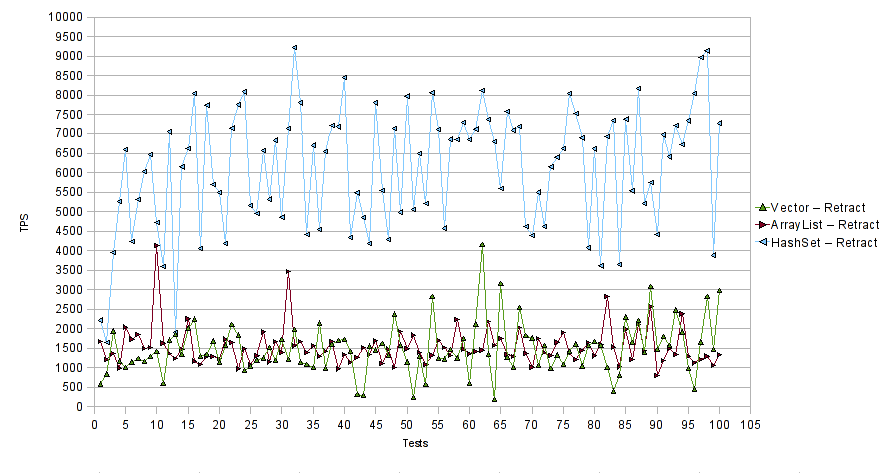
Горизонтальная ось представляет количество тестовых прогонов, а вертикальная ось — среднее количество транзакций в секунду (TPS) для каждого тестового прогона. Таким образом, чем выше значения, тем лучше. Классы реализации Vector и ArrayList Collection работали почти одинаково при добавлении и удалении элементов из них. С другой стороны, для тестового примера сложения элементов предлагаемая нами реализация с «добавлением» и «убиранием» пары HashSet выполнялась несколько хуже по сравнению с реализациями Vector и ArrayList . Тем не менее, в тестовом случае отвода элементов наша реализация «добавление» и «отведение» пары HashSet превзошла реализации Vector и ArrayList, в среднем набрав 6000 TPS.
Удачного кодирования
Джастин
- Лучшие практики Java — DateFormat в многопоточной среде
- Java Best Practices — высокопроизводительная сериализация
- Java Best Practices — строковая производительность и точное совпадение строк
- Лучшие практики Java — битва в очереди и связанный ConcurrentHashMap
- Java Best Practices — Преобразования из Char в Byte и Byte в Char