Продолжая серию статей о предлагаемых практиках при работе с языком программирования Java, мы поговорим о настройке производительности String. Особенно мы сосредоточимся на том, как эффективно обрабатывать преобразования символов в байты и байты в символы при использовании кодировки по умолчанию. Эта статья завершается сравнением производительности между двумя предложенными пользовательскими подходами и двумя классическими (« String.getBytes () » и NIO ByteBuffer ) для преобразования символов в байты и наоборот.
Все обсуждаемые темы основаны на сценариях использования, полученных в результате разработки критически важных, высокопроизводительных производственных систем для телекоммуникационной отрасли.
Перед прочтением каждого раздела этой статьи настоятельно рекомендуется ознакомиться с соответствующей документацией по Java API для получения подробной информации и примеров кода.
Все тесты выполняются на Sony Vaio со следующими характеристиками:
- Система: openSUSE 11.1 (x86_64)
- Процессор (ЦП): Процессор Intel® Core ™ 2 Duo T6670 с частотой 2,20 ГГц
- Скорость процессора: 1200,00 МГц
- Общий объем памяти (ОЗУ): 2,8 ГБ
- Java: OpenJDK 1.6.0_0 64-битная
Применяется следующая тестовая конфигурация:
- Одновременный рабочий Темы: 1
- Тест повторений на одного работника Тема: 1000000
- Всего тестовых прогонов: 100
Преобразование символов в байты и байты в символы
Преобразование между байтами и байтами в символы считается распространенной задачей среди разработчиков Java, которые программируют в сетевой среде, манипулируют потоками байтовых данных, сериализуют объекты String , реализуют протоколы связи и т. Д. По этой причине Java предоставляет несколько утилит, которые позволяют Разработчик для преобразования String (или символьного массива) в его байтовый массив, эквивалентный и наоборот.
Операция « getBytes (charsetName) » класса String, вероятно, является наиболее часто используемым методом для преобразования строки в ее эквивалент байтового массива. Поскольку каждый символ может быть представлен по-разному в соответствии с используемой схемой кодирования, неудивительно, что вышеупомянутая операция требует « charsetName » для правильного преобразования символов String . Если « charsetName » не указано, операция кодирует строку в последовательность байтов, используя набор символов платформы по умолчанию.
Другой «классический» подход для преобразования символьного массива в эквивалент байтового массива — использование класса ByteBuffer пакета NIO. Пример фрагмента кода для конкретного подхода будет представлен позже.
Оба вышеупомянутые подходы, хотя очень популярны и неоспоримо проста в использовании и просто очень не хватает в производительности по сравнению с более мелкозернистый методами. Имейте в виду, что мы не конвертируем кодировки символов . Для преобразования между кодировками символов вы должны придерживаться «классических» подходов, используя либо « String.getBytes (charsetName) », либо методы и утилиты инфраструктуры NIO .
Когда все символы для преобразования являются символами ASCII, предложенный метод преобразования показан ниже:
|
1
2
3
4
5
6
7
8
|
public static byte[] stringToBytesASCII(String str) { char[] buffer = str.toCharArray(); byte[] b = new byte[buffer.length]; for (int i = 0; i < b.length; i++) { b[i] = (byte) buffer[i]; } return b;} |
Полученный байтовый массив создается путем приведения каждого символьного значения к его байтовому эквиваленту, поскольку мы знаем, что все символы находятся в диапазоне ASCII (0–127), поэтому могут занимать только один Байт в размере.
Используя полученный байтовый массив, мы можем преобразовать обратно в исходную строку , используя «классический» конструктор строки « новая строка (байт []) »
Для кодировки символов по умолчанию мы можем использовать методы, показанные ниже, чтобы преобразовать строку в байтовый массив и наоборот:
|
01
02
03
04
05
06
07
08
09
10
|
public static byte[] stringToBytesUTFCustom(String str) { char[] buffer = str.toCharArray(); byte[] b = new byte[buffer.length << 1]; for(int i = 0; i < buffer.length; i++) { int bpos = i << 1; b[bpos] = (byte) ((buffer[i]&0xFF00)>>8); b[bpos + 1] = (byte) (buffer[i]&0x00FF); } return b;} |
Каждый тип символов в Java занимает 2 байта в размере. Для преобразования строки в ее эквивалент байтового массива мы конвертируем каждый символ строки в его 2-байтовое представление.
Используя полученный байтовый массив, мы можем преобразовать обратно в исходную строку , используя метод, представленный ниже:
|
1
2
3
4
5
6
7
8
9
|
public static String bytesToStringUTFCustom(byte[] bytes) { char[] buffer = new char[bytes.length >> 1]; for(int i = 0; i < buffer.length; i++) { int bpos = i << 1; char c = (char)(((bytes[bpos]&0x00FF)<<8) + (bytes[bpos+1]&0x00FF)); buffer[i] = c; } return new String(buffer);} |
Мы строим каждый символ String из его 2-байтового представления. Используя полученный массив символов, мы можем преобразовать обратно в исходную строку , используя «классический» конструктор строки « новая строка (char []) »
Наконец, что не менее важно, мы предоставляем два примера методов, использующих пакет NIO, чтобы преобразовать строку в ее эквивалент байтового массива и наоборот:
|
1
2
3
4
5
6
7
8
|
public static byte[] stringToBytesUTFNIO(String str) { char[] buffer = str.toCharArray(); byte[] b = new byte[buffer.length << 1]; CharBuffer cBuffer = ByteBuffer.wrap(b).asCharBuffer(); for(int i = 0; i < buffer.length; i++) cBuffer.put(buffer[i]); return b;} |
|
1
2
3
4
|
public static String bytesToStringUTFNIO(byte[] bytes) { CharBuffer cBuffer = ByteBuffer.wrap(bytes).asCharBuffer(); return cBuffer.toString();} |
В заключительной части этой статьи мы предоставляем графики сравнения производительности для вышеупомянутых подходов преобразования строки в байтовый массив и байтового массива в строку . Мы протестировали все методы, используя входную строку « тестовая строка ».
Сначала сравнительная таблица производительности преобразования массива строк в байты:
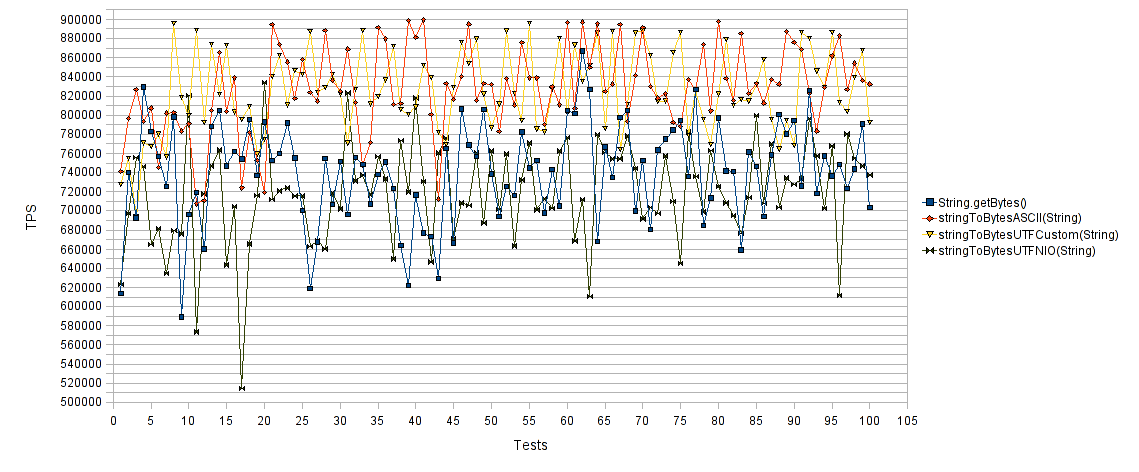
Горизонтальная ось представляет количество тестовых прогонов, а вертикальная ось — среднее количество транзакций в секунду (TPS) для каждого тестового прогона. Таким образом, чем выше значения, тем лучше. Как и ожидалось, подходы « String.getBytes () » и « stringToBytesUTFNIO (String) » работали плохо по сравнению с предлагаемыми подходами « stringToBytesASCII (String) » и « stringToBytesUTFCustom (String) ». Как видите, наши предлагаемые методы достигают почти 30% увеличения TPS по сравнению с «классическими» методами.
Наконец, байтовый массив с таблицей сравнения производительности String :
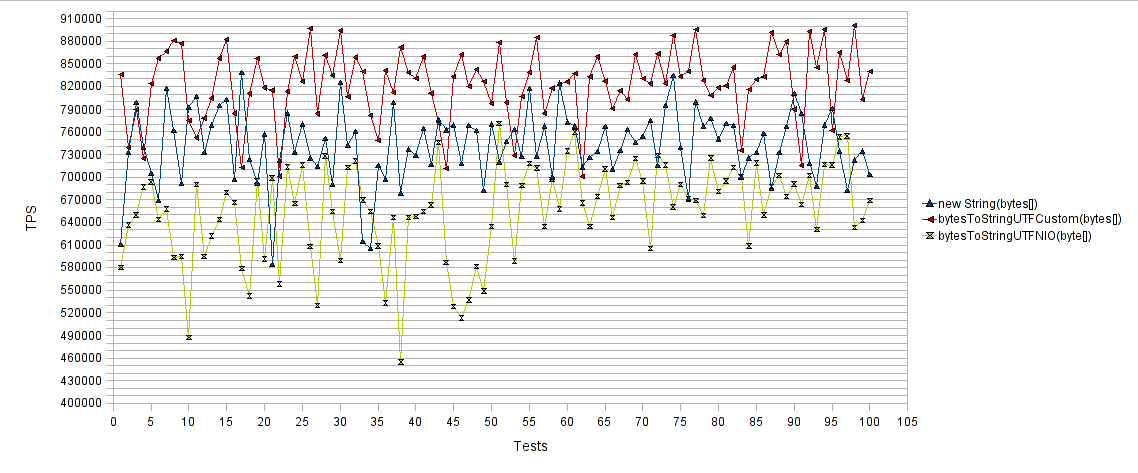
Горизонтальная ось представляет количество тестовых прогонов, а вертикальная ось — среднее количество транзакций в секунду (TPS) для каждого тестового прогона. Таким образом, чем выше значения, тем лучше. Как и ожидалось, подходы « new String (byte []) » и « bytesToStringUTFNIO (byte []) » работали плохо по сравнению с предложенным подходом « bytesToStringUTFCustom (byte []) ». Как вы можете видеть, предлагаемый нами метод достиг почти 15% увеличения TPS по сравнению с методом « new String (byte []) » и почти 30% увеличения TPS по сравнению с методом « bytesToStringUTFNIO (byte []) ».
В заключение, когда вы имеете дело с преобразованиями символов в байты или байтов в символы и не собираетесь изменять используемую кодировку, вы можете добиться превосходной производительности, используя пользовательские — мелкозернистые — методы, а не «классические», предоставляемые класс String и пакет NIO . Наш предлагаемый подход позволил добиться общего повышения производительности на 45% по сравнению с «классическими» подходами при преобразовании тестовой строки в эквивалент байтового массива и наоборот.
Удачного кодирования
Джастин
PS
Приняв во внимание предложение нескольких наших читателей использовать операцию « String.charAt (int) » вместо « String.toCharArray () » для преобразования символов String в байты, я изменил предложенные нами методы и повторно выполнили тесты. Как и ожидалось, дальнейшее повышение производительности будет достигнуто. В частности, дополнительное увеличение среднего значения TPS на 13% было зарегистрировано для метода « stringToBytesASCII (String) », а среднее увеличение показателя TPS на 2% было зафиксировано для « stringToBytesUTFCustom (String) ». Таким образом, вы должны использовать измененные методы, поскольку они работают даже лучше, чем оригинальные. Обновленные методы показаны ниже:
|
1
2
3
4
5
6
7
|
public static byte[] stringToBytesASCII(String str) { byte[] b = new byte[str.length()]; for (int i = 0; i < b.length; i++) { b[i] = (byte) str.charAt(i); } return b;} |
|
01
02
03
04
05
06
07
08
09
10
|
public static byte[] stringToBytesUTFCustom(String str) { byte[] b = new byte[str.length() << 1]; for(int i = 0; i < str.length(); i++) { char strChar = str.charAt(i); int bpos = i << 1; b[bpos] = (byte) ((strChar&0xFF00)>>8); b[bpos + 1] = (byte) (strChar&0x00FF); } return b;} |
- Лучшие практики Java — DateFormat в многопоточной среде
- Java Best Practices — высокопроизводительная сериализация
- Лучшие практики Java — Вектор против ArrayList против HashSet
- Java Best Practices — строковая производительность и точное совпадение строк
- Лучшие практики Java — битва в очереди и связанный ConcurrentHashMap