Это пятая статья в серии об интеграции клиентов синхронизации с асинхронными системами ( 1, 2, 3, 4 ). Здесь мы увидим, как управлять жизненным циклом актера, чтобы наш сервис мог эффективно использовать доступные ресурсы.
Жизненный цикл
Актеры, потоки, объекты, ресурсы … Все они имеют различные состояния в течение своей жизни. Некоторые из этих состояний являются внутренними, и они формируют поведение объекта при получении внешнего стимула. Однако существуют переходы состояний, которые должны обрабатываться внешними объектами: создание, восстановление после ошибок и удаление.
Актер Бассейны
Давным-давно внедрение зависимостей показало нам, что объект не должен отвечать за создание своих зависимостей. Передача этих проблем в фабрику делает код более тестируемым, слабо связанным и читаемым. Нам потребуются разные стратегии создания, независимо от использования DI-структур или внедрения зависимости от бедного человека. Guice Scopes — хороший пример того, как создать один экземпляр для приложения (@Singleton) или один для области (@SessionScoped и @RequestScoped).
Часто системные ресурсы ограничены, дороги в создании или находятся под большой нагрузкой. Это означает, что мы не можем позволить себе ни синглтон, ни неограниченную стратегию создания, такую как Prototype весной . Хороший пример — пулы потоков .
Использование рабочих потоков минимизирует накладные расходы из-за создания потоков. Объекты потока используют значительный объем памяти, и в крупномасштабном приложении выделение и освобождение многих объектов потока создает значительные накладные расходы на управление памятью.
Актеры Akka очень легкие. Мы могли бы позволить себе создать миллионы из них, если бы знали, что они будут быстро уничтожены. Однако это не относится к нашему варианту использования:
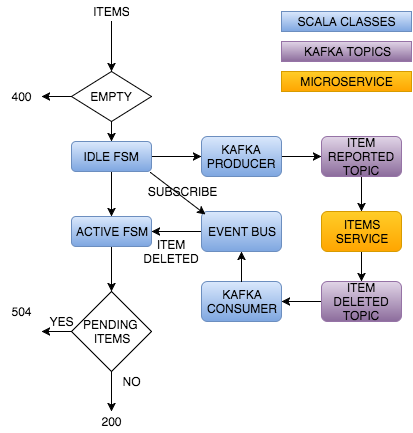
Как вы можете видеть, актеры конечного автомата (FSM) будут ждать, пока служба Предметов не завершит удаление элементов. Важно отметить, что актер ждет, но не блокирует. Актеры прикреплены к Диспетчерам, которые имеют Пул потоков внутри. Эти пулы потоков имеют ограниченное количество потоков; блокирование одного из актеров означало бы довольно быстрое истощение потоков. В этом конкретном примере мы хотим ограничить количество действующих лиц, а не потоков. Может быть, это излишне, но смысл этой серии в основном образовательный. Давайте посмотрим на диаграмму нашего сервиса с должным уровнем абстракции.
Акка HTTP
Akka HTTP — это библиотека, основанная на Spray, для создания слоев интеграции HTTP. Akka HTTP предлагает очень мощный и удобный для чтения маршрутный DSL, как вы можете видеть в нашем коде:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
val deleteItem = get { path("item" / JavaUUID) { itemId => onComplete(deleteItem(itemId)) { case Success(Result(Right(_))) => complete(StatusCodes.OK) case Success(Result(Left(Timeout(errorMessage)))) => complete(StatusCodes.GatewayTimeout) // many other cases we won't cover here } } } private def deleteItem(itemId: UUID)= itemCoordinator ask ItemReported(itemId) |
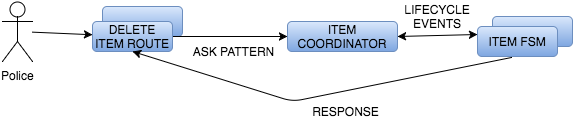
В этом фрагменте я бы хотел подчеркнуть шаблон «спроси, скажи» . Просто чтобы прояснить, это паттерны Акки, ничего общего с удивительным принципом «Говори, не спрашивай» . Шаблон рассылки включает в себя создание сообщения и забывание об ответе. При таком подходе информация движется в одном направлении. Однако для нашего сценария нас интересует шаблон Ask . Когда мы отправляем сообщение актеру через шаблон запроса, создается будущее с ответом, ограниченным тайм-аутом. Как сказано в документации:
Использование ask отправит сообщение получающему актеру так же, как и Tell, и получающий актер должен ответить с помощью sender ()! ответ, чтобы завершить возвращенное будущее значением. Операция ask включает в себя создание внутреннего субъекта для обработки этого ответа, который должен иметь тайм-аут, после которого он уничтожается, чтобы не пропускать ресурсы; смотрите больше ниже.
|
1
2
3
4
5
|
First actor -> val future = myActor.ask("hello")(5 seconds)Second actor -> sender() ! result |
Координирующие актеры
Давайте посмотрим код Item Coordinator :
|
01
02
03
04
05
06
07
08
09
10
11
12
|
override def receive: Receive = { case itemReported: ItemReported => if (actorPool.isEmpty) sender() ! Result(Left("No actors available")) else { actorPool.get() forward ItemReported } case Result(_) => sender() ! FlushItemFSM actorPool.putBack(sender())} |
Метод sender предоставляет ActorRef субъекта, отправившего сообщение. Если пул актеров исчерпан, нам нужно связаться с актером Route, чтобы мы не смогли обработать запрос. В противном случае мы получим одного из участников в пуле и отправим полученное сообщение. Форвард позволяет нам сохранить оригинального отправителя. FSM сообщит результат своей работы субъекту Route, который ожидает, ограниченный шаблоном ask.
ФСМ нужна ссылка на координатора, поскольку он отвечает за управление жизненным циклом ФСМ. Координатор отправляет сообщение в ФСМ с указанием сбросить его внутреннее состояние. В то же время возвращает FSM в пул.
Создание актеров
Вспомните, как FSM уведомляет о завершении своей работы:
|
1
2
3
4
5
|
private def finishWorkWith(message: Any) = { replyTo ! message coordinator ! message goto(Idle)} |
replyTo — это переменная, которая была инициализирована с sender() при получении первого сообщения ItemReported . Помните, что сообщение было переадресовано, поэтому отправителем является участник маршрута. coordinator — это ActorRef, который был введен при создании актера. Для этой цели мы используем инъекцию зависимостей бедного человека. Давайте посмотрим на определение нашей актерской фабрики:
|
1
2
3
4
5
|
lazy val itemFSMFactory: (ActorContext, ActorRef) => ActorRef = (context, self) => { val itemFSM = ItemFSM.props(itemReportedProducer, itemDeletedBus, coordinator = self) context.actorOf(itemFSM) } |
Эта фабрика будет вызываться n раз (в зависимости от размера пула) при создании пула актеров.
Курирующие актеры
Наш координатор отвечает за пул и что делать, когда FSM закончит ожидаемым образом. Однако мы не говорили о том, что происходит, когда наш актер терпит неудачу. Акка имеет встроенный механизм для устранения сбоев, называемый надзором . Существуют разные стратегии восстановления, мы перейдем к стратегии Restart :
|
1
2
3
4
5
6
|
override val supervisorStrategy = OneForOneStrategy(maxNrOfRetries = 3, withinTimeRange = 15 seconds) { case e: Exception => actorPool.putBack(sender()) SupervisorStrategy.Restart } |
Как сказано в документации стратегии Restart :
Удаляет старый экземпляр Actor и заменяет его новым, а затем возобновляет обработку сообщения.
Эта стратегия была определена в координаторе. Как мы можем указать, что этот координатор является родителем ФСМ, который будет контролироваться? Вспомните, как мы создали FSM:
|
1
|
context.actorOf(itemFSM) |
Давайте посмотрим Scaladoc для actorOf :
Создать нового актера в качестве дочернего актера этого контекста
itemFSMFactory вызывается в области действия координатора. Каждый актер имеет контекст, который включает отправителя, самого себя и различные мета-объекты. Создание актера с использованием контекста координатора связывает этих акторов как родитель-потомок.
Резюме
Благодаря конструкциям и шаблонам Akka, а также функциональным и асинхронным возможностям Scala мы могли довольно легко написать координационный код. В следующем посте мы увидим, как проверить Akka.
Часть 1 | Часть 2 | Часть 3 | Часть 4
| Ссылка: | Координация в Akka от нашего партнера JCG Фелипе Фернандеса в блоге Crafted Software . |