Это четвертый пост в серии об интеграции клиентов синхронизации с асинхронными системами ( 1, 2, 3 ). Здесь мы попытаемся понять, как работает Kafka , чтобы правильно использовать реализацию публикации и подписки.
Концепции Кафки
Согласно официальной документации :
Kafka — это распределенный, многораздельный, реплицируемый сервис журнала фиксации. Он обеспечивает функциональность системы обмена сообщениями, но с уникальным дизайном.
Кафка работает как кластер, а узлы называются брокерами. Брокеры могут быть лидерами или репликами для обеспечения высокой доступности и отказоустойчивости. Брокеры отвечают за разделы, являясь распределительной единицей, где хранятся сообщения. Эти сообщения упорядочены и доступны по индексу с именем offset. Набор разделов формирует тему, являясь источником сообщений. Раздел может иметь разных потребителей, и они получают доступ к сообщениям, используя свое собственное смещение. Производители публикуют сообщения в темах Кафки. Эта диаграмма из документации Кафки может помочь понять это:
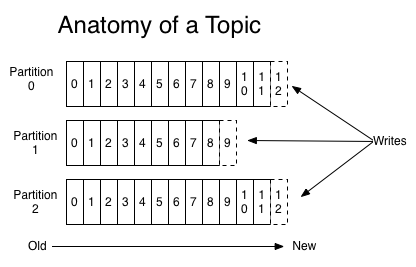
Очереди против публикации-подписки
Группы потребителей — это еще одна ключевая концепция, которая помогает объяснить, почему Kafka является более гибким и мощным, чем другие решения для обмена сообщениями, такие как RabbitMQ . Потребители связаны с группами потребителей. Если каждый потребитель принадлежит к одной и той же группе потребителей, сообщения темы будут равномерно распределены между потребителями; это называется «модель очередей». Напротив, если каждый потребитель принадлежит к другой группе потребителей, все сообщения будут потребляться каждым клиентом; это называется моделью «публикация-подписка».
У вас может быть сочетание обоих подходов с разными логическими группами потребителей для разных нужд и несколькими потребителями внутри каждой группы для увеличения пропускной способности за счет параллелизма. Опять же, другая схема из документации Кафки :
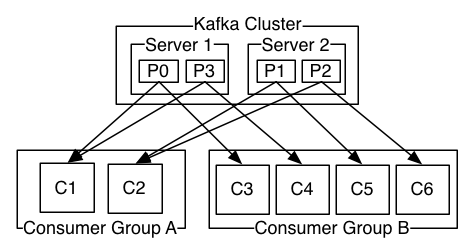
Понимание наших потребностей
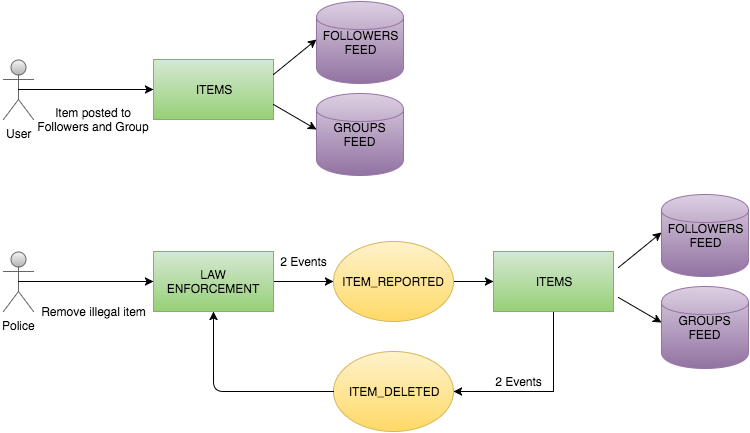
Как мы видели в предыдущих постах ( 1, 2, 3 ), служба Items публикует сообщения в теме Kafka под названием item_deleted . Это сообщение будет жить в одном разделе темы. Чтобы определить, в каком разделе будет находиться сообщение, Kafka предлагает три варианта :
- Если в записи указан раздел, используйте его
- Если раздел не указан, но ключ присутствует, выберите раздел на основе хэша ключа.
- Если раздела или ключа нет, выберите раздел в циклическом порядке.
Мы будем использовать item_id в качестве ключа. Потребители, содержащиеся в разных экземплярах службы обеспечения правопорядка, заинтересованы только в определенных разделах, поскольку они сохраняют внутреннее состояние для некоторых элементов. Давайте проверим различные реализации Kafka для потребителей, чтобы увидеть, какой из них наиболее удобен для нашего варианта использования.
Потребители Кафки
В Кафке три потребителя: потребитель высокого уровня , простой потребитель и новый потребитель
Simple Consumer из трех потребителей работает на самом низком уровне. Он отвечает нашим требованиям, так как позволяет потребителю «использовать только часть разделов в теме процесса». Однако, как сказано в документации:
SimpleConsumer требует значительного объема работы, которая не требуется в группах потребителей:
- Вы должны отслеживать смещения в вашем приложении, чтобы знать, где вы остановились, потребляя
- Вы должны выяснить, какой брокер является ведущим брокером по теме и разделу
- Вы должны справиться с изменениями лидера брокера
Если вы прочитаете код, предложенный для решения этих проблем, вы быстро отговоритесь от использования этого потребителя.
Новый потребитель предлагает правильный уровень абстракции и позволяет нам подписываться на определенные разделы. Они предлагают следующий вариант использования в документации:
Первый случай — если процесс поддерживает какое-то локальное состояние, связанное с этим разделом (например, локальное хранилище значений ключей на диске), и, следовательно, он должен получать записи только для раздела, который он поддерживает на диске.
К сожалению, наша система использует Kafka 0.8, а этот потребитель доступен только с 0.9. У нас нет ресурсов для перехода на эту версию, поэтому нам нужно придерживаться потребителя высокого уровня .
Этот потребитель предлагает хороший API, но он не позволяет нам подписываться на определенные разделы. Это означает, что каждый экземпляр службы охраны правопорядка будет потреблять каждое сообщение, даже не относящееся к делу. Мы можем достичь этого путем определения различных групп потребителей в каждом конкретном случае.
Использование Akka Event Bus
В предыдущем посте мы определили некоторый актер ItemDeleted который ожидает сообщения ItemDeleted .
|
1
2
3
4
5
6
7
8
|
when(Active) { case Event(ItemDeleted(item), currentItemsToBeDeleted@ItemsToBeDeleted(items)) => val newItemsToBeDeleted = items.filterNot(_ == item) newItemsToBeDeleted.size match { case 0 => finishWorkWith(CensorResult(Right())) case _ => stay using currentItemsToBeDeleted.copy(items = newItemsToBeDeleted) } } |
Наш Потребитель Кафки может переслать каждое сообщение этим актерам и позволить им отбросить / отфильтровать ненужные элементы. Однако мы не хотим перегружать наших актеров избыточной и неэффективной работой, поэтому мы добавим слой абстракции, который позволит им отбросить нужные сообщения действительно эффективным способом.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
final case class MsgEnvelope(partitionKey: String, payload: ItemDeleted)class ItemDeletedBus extends EventBus with LookupClassification { override type Event = MsgEnvelope override type Classifier = String override type Subscriber = ActorRef override protected def mapSize(): Int = 128 override protected def publish(event: Event, subscriber: Subscriber): Unit = subscriber ! event.payload override protected def classify(event: Event): Classifier = event.partitionKey override protected def compareSubscribers(a: Subscriber, b: Subscriber): Int = a.compareTo(b)} |
Akka Event Bus предлагает нам подписку по разделам, которая отсутствует в нашем Kafka High Level Consumer. От нашего потребителя Kafka мы опубликуем каждое сообщение в автобусе:
|
1
|
itemDeletedBus.publish(MsgEnvelope(item.partitionKey, ItemDeleted(item))) |
В предыдущем посте мы показали, как подписаться на сообщения с помощью этого ключа раздела:
|
1
|
itemDeletedBus.subscribe(self, item.partitionKey) |
LookupClassification будет фильтровать нежелательные сообщения, поэтому наши актеры не будут перегружены.
Резюме
Благодаря гибкости, которую обеспечивает Kafka, мы смогли разработать нашу систему, понимая различные компромиссы. В следующих статьях мы увидим, как координировать результаты этих автоматов, чтобы предоставить клиенту синхронизирующий ответ.
| Ссылка: | Опубликуйте модель подписки в Kafka от нашего партнера по JCG Фелипе Фернандеса в блоге Crafted Software . |