обзор
Главный вопрос, касающийся использования Lambdas в Java и Low Latency: Они производят мусор, и вы можете что-нибудь с этим сделать?
Фон
Я работаю над библиотекой, которая поддерживает различные проводные протоколы. Идея состоит в том, что вы можете описать данные, которые вы хотите записать / прочитать, и проводной протокол определяет, использует ли он текст с полями, такими как JSon или YAML, текст с номерами полей, например, FIX, двоичный файл с именами полей, например, BSON, или двоичную форму YAML. , двоичный файл с именем поля, номерами поля или мета поля вообще. Значения могут быть фиксированной длины, переменной длины и / или типа данных с самоописанием.
Идея заключается в том, что он может обрабатывать различные изменения схемы или, если вы можете определить, что схема одинакова, например, в сеансе TCP, вы можете пропустить все это и просто отправить данные.
Другая важная идея — использовать лямбды для поддержки этого.
В чем проблема с лямбдами
Основной проблемой является необходимость избежать значительного мусора в приложениях с низкой задержкой. Условно, каждый раз, когда вы видите лямбда-код, это новый объект.
К счастью, Java 8 значительно улучшила Escape-анализ . Escape Analysis позволяет JVM заменять новый объект, распаковывая его в стек, эффективно давая вам распределение стека. Эта функция была доступна в Java 7, однако редко исключала объекты. Примечание: когда вы используете профилировщик, это препятствует работе Escape Analysis, поэтому вы не можете доверять профилировщикам, которые используют внедрение кода, поскольку профилировщик может сказать, что объект создается, когда без профилировщика он не создает объект. Регистратор полетов, кажется, связывается с Escape Analysis.
У Escape Analysis всегда были свои причуды, и похоже, что он все еще есть. Например, если у вас есть IntConsumer или любой другой примитивный потребитель, выделение лямбды может быть устранено в обновлении 20 Java 8 — обновление 40. Однако исключение является логическим, когда это, как кажется, не происходит. Надеюсь, это будет исправлено в следующей версии.
Еще одна странность заключается в том, что размер (после встраивания) метода, в котором происходит удаление объекта, имеет значение, и в относительно скромных методах анализ побега может сдаться.
Особый случай
В моем случае у меня есть метод чтения, который выглядит следующим образом:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
public void readMarshallable(Wire wire) throws StreamCorruptedException { wire.read(Fields.I).int32(this::i) .read(Fields.J).int32(this::j) .read(Fields.K).int32(this::k) .read(Fields.L).int32(this::l) .read(Fields.M).int32(this::m) .read(Fields.N).int32(this::n) .read(Fields.O).int32(this::o) .read(Fields.P).int32(this::p) .read(Fields.Q).int32(this::q) .read(Fields.R).int32(this::r) .read(Fields.S).int32(this::s) .read(Fields.T).int32(this::t) .read(Fields.U).int32(this::u) .read(Fields.V).int32(this::v) .read(Fields.W).int32(this::w) .read(Fields.X).int32(this::x) ;} |
Я использую лямбды для установки полей, которые фреймворк может обрабатывать необязательные, отсутствующие или неупорядоченные поля. В оптимальном случае поля доступны в указанном порядке. В случае изменения схемы порядок может быть другим или иметь другой набор полей. Использование лямбда-выражения позволяет платформе по-разному обрабатывать поля порядка и не по порядку.
Используя этот код, я провел тестирование, сериализацию и десериализацию объекта 10 миллионов раз. Я настроил JVM, чтобы иметь размер eden 10 МБ с -Xmn14m -XX:SurvivorRatio=5 Пространство Eden в 5 раз больше двух оставшихся в живых пространств с соотношением 5: 2. Пространство Эдема составляет 5/7 от всего молодого поколения, т.е. 10 МБ.
Имея размер Eden в 10 МБ и 10 миллионов тестов, я могу оценить созданный мусор, подсчитав количество GC, напечатанных с помощью -verbose:gc Для каждого полученного мной GC в среднем был упакован один байт на тест. Когда я изменил количество сериализованных и десериализованных полей, я получил следующий результат на Intel i7-3970X.
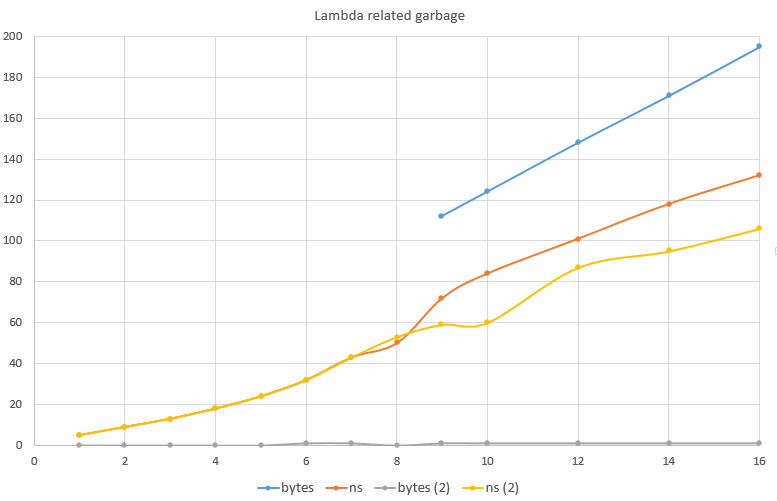
На этой диаграмме вы можете видеть, что для десериализованного от 1 до 8 полей, т.е. до 8 лямбд в одном и том же методе, почти не создается мусор, т.е. не более одного GC. Однако при 9 или более полях или лямбда-кодах анализ сбоя завершается неудачей, и вы получаете создаваемый мусор, линейно увеличивающийся с увеличением числа файлов.
Я бы не хотел, чтобы вы верили, что 8 — это магическое число. Скорее всего, это будет предел размера в байтах метода, хотя я не смог найти такой параметр командной строки. Разница возникает, когда метод вырос до 170 байт.
Есть ли что-нибудь, что можно сделать? Самым простым «исправлением» оказалось разбиение кода на два метода (возможно, больше, если необходимо), десериализовав половину полей в одном методе и половину полей в другом, он смог десериализовать от 9 до 16 полей без мусора. Это результаты «bytes (2)» и «ns (2)». Устраняя мусор, код также работает в среднем быстрее.
Примечание: время сериализации и десериализации объекта с 14 x 32-разрядным целым числом было меньше 100 нс.
Другие заметки:
Когда я использовал профилировщик, в данном случае YourKit, код, который не создавал мусора, начал создавать мусор, так как анализ сбоя завершился неудачей.
Я распечатал метод inlining и обнаружил, что утверждения assert в некоторых ключевых методах препятствуют их вставке, поскольку это делает методы более крупными. Я исправил это, создав подкласс by main class с утверждениями, которые будут создаваться фабричным методом, когда утверждения включены. Класс по умолчанию не имеет утверждений и не влияет на производительность.
До того, как я перенес эти утверждения, я мог десериализовать только 7 полей, не вызывая мусора.
Когда я заменил лямбды анонимными внутренними классами, я увидел аналогичное исключение объектов, хотя в большинстве случаев, если вы можете использовать лямбду, которая является предпочтительной.
Вывод
Java 8 выглядит намного умнее в удалении мусора очень недолговечными объектами. Это означает, что такие методы, как передача лямбды, могут быть опцией в приложениях с низкой задержкой.
РЕДАКТИРОВАТЬ
Я нашел вариант, который помогает в этой ситуации, хотя я еще не уверен, почему.
Если я использую опцию -XX:InlineSmallCode=1000 (по умолчанию) и меняю ее на -XX:InlineSmallCode=5000 то приведенный выше «исправленный» пример начинает создавать мусор, однако если я -XX:InlineSmallCode=500 его до -XX:InlineSmallCode=500 даже код Пример, который я привел, изначально выполняет без производства мусора.
| Ссылка: | Java Lambdas и Low Latency от нашего партнера JCG Питера Лоури из блога Vanilla Java . |