Во многих рабочих нагрузках, требующих интенсивной записи, в хранилищах Innodb / XtraDB вы можете увидеть скрытый и опасный «долг», накопленный — «историю» не очищенной транзакции, которая, если ее не контролировать со временем, приведет к снижению производительности или займет все свободное пространство и приведет к отключение электричества. Давайте поговорим о том, откуда оно и что вы можете сделать, чтобы избежать неприятностей.
Техническая информация: InnoDB — это механизм MVCC, который означает, что он хранит несколько версий строк в базе данных, и когда строки удаляются или обновляются, они не сразу удаляются из базы данных, но сохраняются в течение некоторого времени — до тех пор, пока они не будут удалены. Для большинства рабочих нагрузок OLTP их можно удалить через несколько секунд после фактического изменения. В некоторых случаях, хотя их может потребоваться хранить в течение длительного периода времени — если в системе выполняются некоторые старые транзакции, возможно, все же потребуется просмотреть старое состояние базы данных. Начиная с MySQL 5.6 Innodb имеет один или несколько «потоков очистки», которые удаляют старые данные, которые можно удалить, хотя они могут делать это недостаточно быстро для рабочих нагрузок с очень интенсивной записью.
Это действительно происходит? Я начал изучать эту проблему, основываясь на некоторых проблемах клиентов, и, к своему удивлению, я мог очень легко добиться быстрого роста истории, используя базовую рабочую нагрузку sysbench «update». Это особенно легко с настройкой по умолчанию innodb_purge_threads = 1, но даже с innodb_purge_threads = 8 она растет довольно быстро.
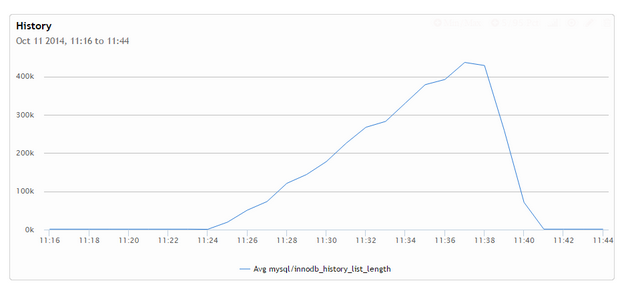
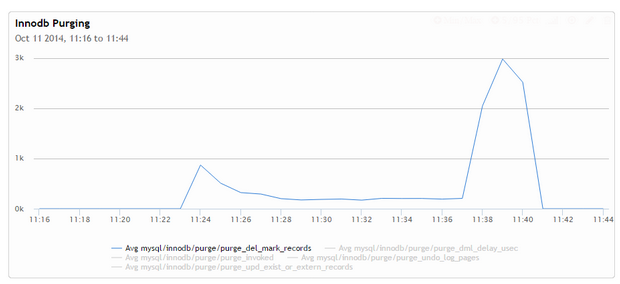
Если мы посмотрим на скорость очистки (которая исходит из таблицы innodb-метрик), то увидим, что очистка очень сильно истощается активным параллельным процессом sysbench и значительно ускоряется после его завершения:
Now to be frank this is not an easy situation to get in the majority of workloads with short transactions when the undo space is kept in memory purge and is able to keep up. If Undo space however happens to be gone from buffer pool the purge speed can slow down drastically and the system might not be able to keep up anymore. How it could happen? There are 2 common variants….
Long Running Transaction: If you’re having some long running transaction, for example mysqldump, on the larger table the purging has to pause while that transaction is running and a lot of history will be accumulated. If there is enough IO pressure a portion of undo space will be removed from the buffer pool.
MySQL Restart: Even with modest history length restarting MySQL will wash away from memory and will cause purge to be IO bound. This is of course if you’re not using InnoDB Buffer Pool save and reload.
How do you check if your UNDO space is well cached? In Percona Server I can use those commands:
mysql>select sum(curr_size)*16/1024undo_space_MB from XTRADB_RSEG; +---------------+ |undo_space_MB| +---------------+ | 1688.4531| +---------------+ 1row inset(0.00sec) mysql>select count(*)cnt,count(*)*16/1024size_MB,page_type from INNODB_BUFFER_PAGE group by page_type; +--------+-----------+-------------------+ |cnt|size_MB |page_type | +--------+-----------+-------------------+ | 55|0.8594|EXTENT_DESCRIPTOR| |2|0.0313|FILE_SPACE_HEADER| |108|1.6875|IBUF_BITMAP | |17186|268.5313|IBUF_INDEX| |352671|5510.4844|INDEX | | 69|1.0781|INODE | |128|2.0000|SYSTEM| |1|0.0156|TRX_SYSTEM| | 6029| 94.2031|UNDO_LOG| |16959|264.9844|UNKNOWN | +--------+-----------+-------------------+ 10rows inset(1.65sec)
This shows what the total undo space size is now, 1.7GB, with less than 100MB cached in the buffer pool size….
Here are a few graphs from Running Heavy concurrent query during lighter workload where purging could keep up. In this case I used the “injection” benchmark in sysbench setting –trx-rate to 50% of what the system shown as peak.
mysql>select count(distinctk+length(pad))from sbtest1; +--------------------------------+ |count(distinctk+length(pad))| +--------------------------------+ | 30916851| +--------------------------------+ 1row inset(28min32.38sec)
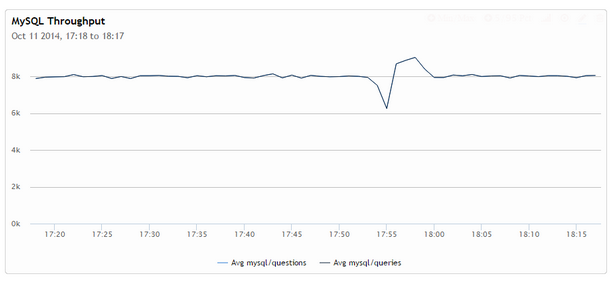
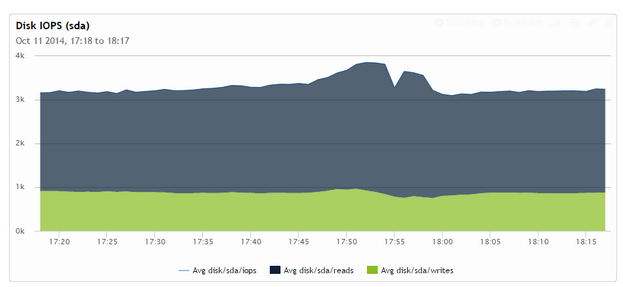
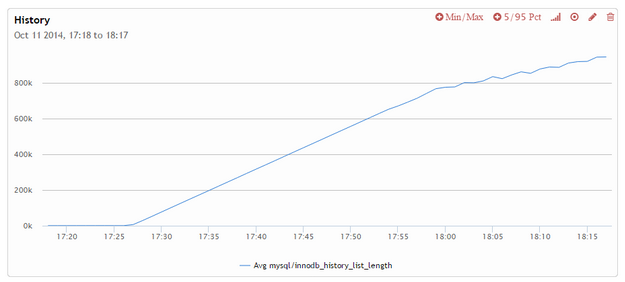
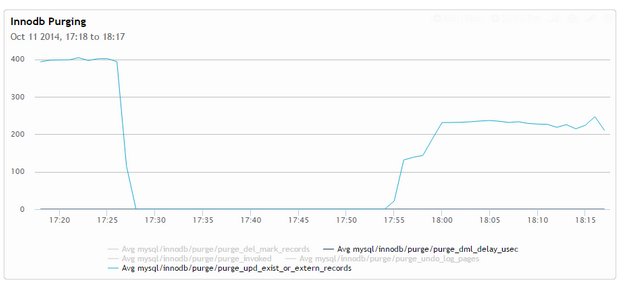
What we can see from those graphs is that InnoDB purging initially is progressing at a speed fast enough to keep up with inflow of transactions,
however as we kick up the complicated query, purging is stopped and when the query is done the purge speed settles on the new much lower level where it is not able to keep up with the workload anymore.
Now, there is recognition of this problem and there are options with innodb_max_purge_lag and innodb_max_purge_lag_delay to set the maximum length of the history after reaching which delay will be injected for DML statements up to a specified amount of microseconds.
Unfortunately it is not designed very well to use with real applications. The problems I see with its design are two fold….
Looking at Total History: If you think about it there are 2 kinds of records within the history – there are records that can be purged and there are ones which can’t be purged because they are needed by some active transaction. It is perfectly fine to have a lot of records in history if some long transaction is running – it is not the cause of the problem or overload, while we expect what “purgable history” should be low most of the time.
Looking at the Size rather than Rate of Change: Even worse, the history blowout prevention is looking at the current value to inject a delay and not at whenever it is that’s growing or already shrinking.
These together means that cases of long running transactions concurrently with OLTP workloads is handled very poorly – as long as history reaches the specified maximum amount the system will kick into overdrive, delaying all statements to the maximum extent possible, until the history falls back below the threshold. Here is how it looks on graphs:
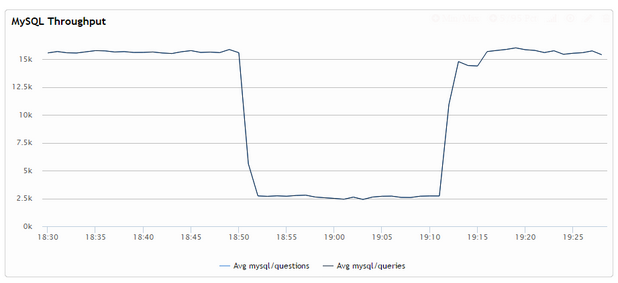
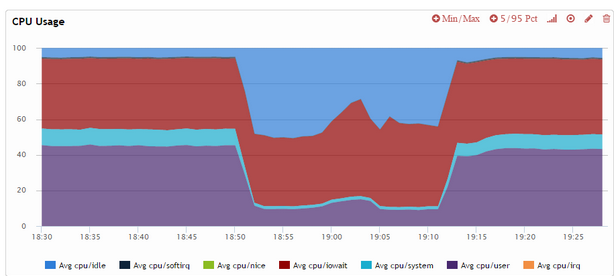
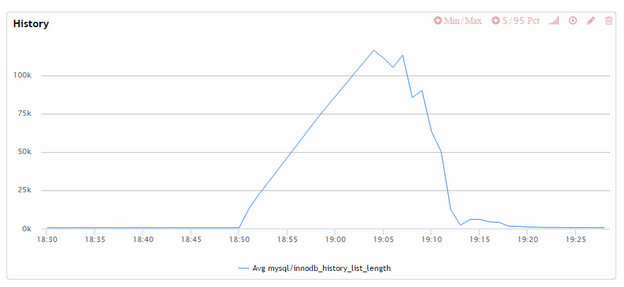
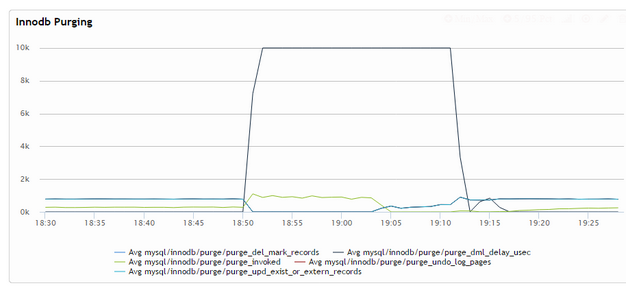
As you see on the last graph, we got the purge_dml_delay_usec spiking to 10000us (the max I set) even as no purging can be done (see the blue line is at zero). It only actually starts to work on the history when the heavy query completes and really releases the breaks when the purge is complete. In this case the throughput of the system reduced more than 5 times when the delay was active – which would not work for most real-world systems.
Design Thoughts: So what would I change in the purging design of the configuration? I would like to see a better default configuration that should include multiple purge threads and purge delay (improved). I would find some way to measure not only history size but purgable history size and base purge delay on it. Also make it based on the change rather than threshold – do just enough delay so the history is gradually shrinking. Also basing it on the undo space size instead of the number of transactions (which can vary in size) might be more practical and easier to auto-tune. We also can probably do better in terms of undo space caching – similar to Insert buffer, I’d like to keep it in memory say until 10% of the buffer pool size as removing from the cache something you know you will need very soon is bad business, as well as consider whether there is some form of read-ahead which can work to pre-read undo space which is needed. Right now I’ve tested and neither linear nor random read-ahead seems to help picking it up from disk with less random IO.
Practical Thoughts: Whatever improvements we’ll get from purging we have MySQL and Percona Server 5.6 systems to run for some years to come. So what are the practical steps we can do to manage purge history better?
Monitor: Make sure you are monitoring and graphing innodb_history_list_length. If you use large transactions, set alerts pretty high but do not leave it unchecked.
Configure Set innodb_purge_threads=8 or some other value if you have write intensive workload. Consider playing with innodb_max_purge_lag and innodb_max_purge_lag_delay but be careful – as currently designed it can really bring the server to its knees. You may consider using it interactively instead, changing them as run-time options if you spot history list growths unchecked, balancing current workload demands with resources allocated to purging.
Let it purge before shutdown: In many cases I find purge performance much worse after I restart MySQL Server because of caching. So the good approach might be just to remove the workload from MySQL server before shutting it down to let the purge of outstanding history complete – and only after that shut it down. If the server has crashed you might consider letting it complete purging before getting traffic routed back to it.
Use Innodb Buffer Pool Preload Use innodb_buffer_pool_dump_at_shutdown=on and innodb_buffer_pool_load_at_startup=on to ensure undo space is preloaded back to the buffer pool on startup.
P.S If you wonder where the graphs I have used came from – it is our Percona Cloud Tools – a very convenient way for analyses like these allowing access to all MySQL status variables, InnoDB metrics, tons of OS metrics and more.